人工智能基础 作业6
本次来实现XO图形的识别
数据集
数据集要按照一定比例自行划分好训练集training_set和测试集test_set

代码
import torch
from torch import nn, optim
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, transforms
# 模型构建
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3)
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200)
self.fc2 = nn.Linear(1200, 64)
self.fc3 = nn.Linear(64, 2)
def forward(self, x):
x = self.maxpool(self.relu(self.conv1(x)))
x = self.maxpool(self.relu(self.conv2(x)))
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 数据集加载
data_loader = DataLoader(
dataset=datasets.ImageFolder(
root='training_data_sm',
transform=transforms.Compose([
transforms.Grayscale(),
transforms.ToTensor()
])
),
batch_size=64,
shuffle=True
)
# 实例化模型
model = Net()
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# 参数优化器
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 开始训练
epochs = 10
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(data_loader):
# 获取数据
images, label = data # images.shape = (batch, 1, w, h)
# 推理
out = model(images)
# 计算损失
loss = criterion(out, label)
# 清空梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 计算平均损失
running_loss += loss.item()
if (i + 1) % 10 == 0:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
print('finished train')
# 保存模型
torch.save(model, 'model_name.pth') # 保存的是模型, 不止是w和b权重值
训练
[1 10] loss: 0.069
[1 20] loss: 0.068
[1 30] loss: 0.065
[2 10] loss: 0.057
[2 20] loss: 0.038
[2 30] loss: 0.016
[3 10] loss: 0.009
[3 20] loss: 0.007
[3 30] loss: 0.005
[4 10] loss: 0.037
[4 20] loss: 0.021
[4 30] loss: 0.007
[5 10] loss: 0.003
[5 20] loss: 0.003
[5 30] loss: 0.002
[6 10] loss: 0.002
[6 20] loss: 0.001
[6 30] loss: 0.002
[7 10] loss: 0.001
[7 20] loss: 0.001
[7 30] loss: 0.001
[8 10] loss: 0.000
[8 20] loss: 0.002
[8 30] loss: 0.000
[9 10] loss: 0.000
[9 20] loss: 0.001
[9 30] loss: 0.000
[10 10] loss: 0.000
[10 20] loss: 0.000
[10 30] loss: 0.001
finished train
测试
images, labels = data_loader.__iter__().__next__()
# 读取一张图片 images[0],测试
print("labels[0] truth:\t", labels[0])
x = images[0]
# 读取模型
model_load = torch.load('model_name.pth')
predicted = torch.max(model_load(x), 1)
print("labels[0] predict:\t", predicted.indices)
img = images[0].data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.show()
计算模型的准确率
data_loader_test = DataLoader(
dataset=datasets.ImageFolder(
root='test_data_sm',
transform=transforms.Compose([
transforms.Grayscale(),
transforms.ToTensor()
])
),
batch_size=64,
shuffle=True
)
# 读取模型
model_load = torch.load('model_name.pth')
correct = 0
total = 0
with torch.no_grad(): # 进行评测的时候网络不更新梯度
for data in data_loader_test: # 读取测试集
images, labels = data
outputs = model_load(images)
_, predicted = torch.max(outputs.data, 1) # 取出 最大值的索引 作为 分类结果
total += labels.size(0) # labels 的长度
correct += (predicted == labels).sum().item() # 预测正确的数目
print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))Accuracy of the network on the test images: 99.550000 %
查看训练好的模型特征图
# 看看每层的 卷积核 长相,特征图 长相
# 获取网络结构的特征矩阵并可视化
import torch
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
# 定义图像预处理过程(要与网络模型训练过程中的预处理过程一致)
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'training_data_sm'
data_train = datasets.ImageFolder(path, transform=transforms)
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
for i, data in enumerate(data_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
outputs = []
x = self.conv1(x)
outputs.append(x)
x = self.relu(x)
outputs.append(x)
x = self.maxpool(x)
outputs.append(x)
x = self.conv2(x)
x = self.relu(x)
x = self.maxpool(x)
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return outputs
model1 = torch.load('model_name.pth')
# 打印出模型的结构
print(model1)
x = images[0]
# forward正向传播过程
out_put = model1(x)
for feature_map in out_put:
# [N, C, H, W] -> [C, H, W] 维度变换
im = np.squeeze(feature_map.detach().numpy())
# [C, H, W] -> [H, W, C]
im = np.transpose(im, [1, 2, 0])
print(im.shape)
# show 9 feature maps
plt.figure()
for i in range(9):
ax = plt.subplot(3, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
# [H, W, C]
# 特征矩阵每一个channel对应的是一个二维的特征矩阵,就像灰度图像一样,channel=1
# plt.imshow(im[:, :, i])
plt.imshow(im[:, :, i], cmap='gray')
plt.show()卷积后的特征图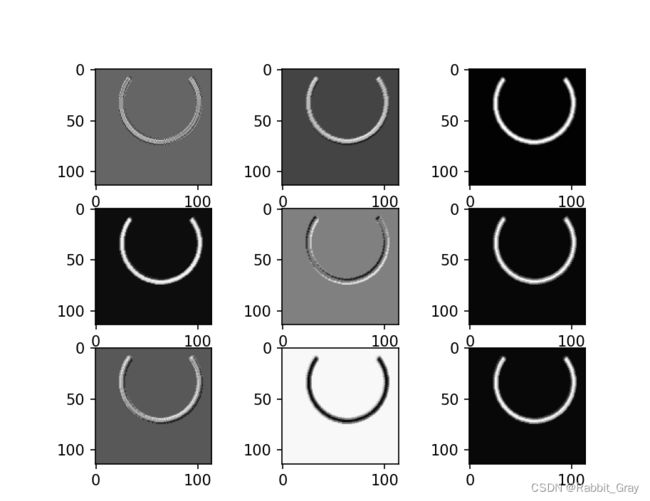
激活后的特征图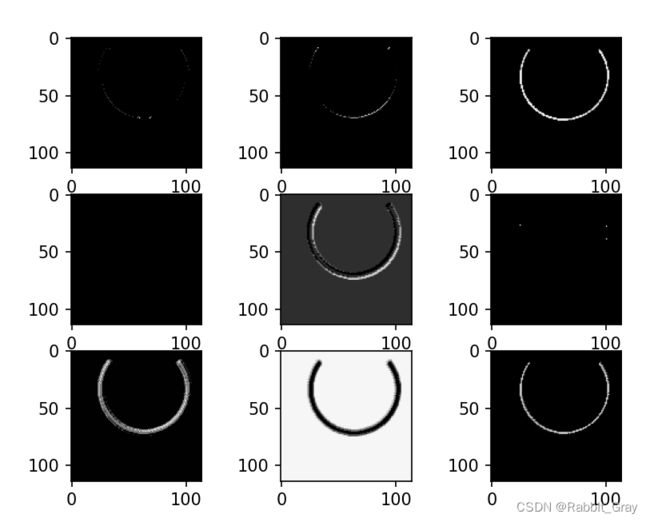
池化后的特征图
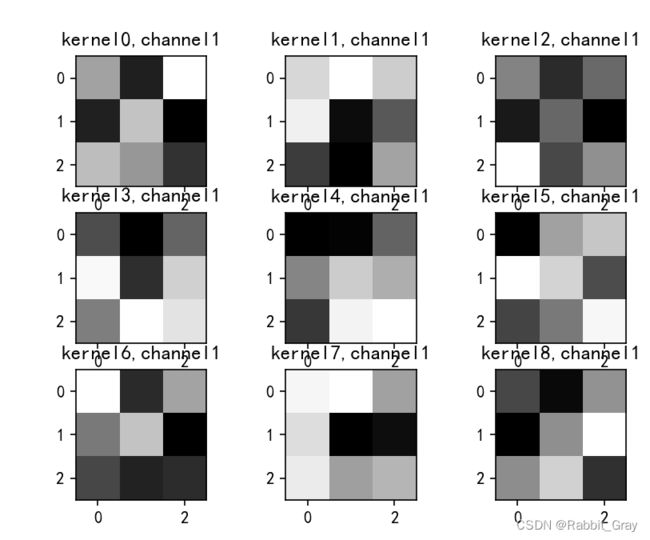
查看训练好的模型的卷积核
# 看看每层的 卷积核 长相,特征图 长相
# 获取网络结构的特征矩阵并可视化
import torch
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 #有中文出现的情况,需要u'内容
# 定义图像预处理过程(要与网络模型训练过程中的预处理过程一致)
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'training_data_sm'
data_train = datasets.ImageFolder(path, transform=transforms)
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
for i, data in enumerate(data_loader):
images, labels = data
# print(images.shape)
# print(labels.shape)
break
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
outputs = []
x = self.maxpool(self.relu(self.conv1(x)))
# outputs.append(x)
x = self.maxpool(self.relu(self.conv2(x)))
outputs.append(x)
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return outputs
model1 = torch.load('model_name.pth')
x = images[0]
# forward正向传播过程
out_put = model1(x)
weights_keys = model1.state_dict().keys()
for key in weights_keys:
print("key :", key)
# 卷积核通道排列顺序 [kernel_number, kernel_channel, kernel_height, kernel_width]
if key == "conv1.weight":
weight_t = model1.state_dict()[key].numpy()
print("weight_t.shape", weight_t.shape)
k = weight_t[:, 0, :, :] # 获取第一个卷积核的信息参数
# show 9 kernel ,1 channel
plt.figure()
for i in range(9):
ax = plt.subplot(3, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
plt.imshow(k[i, :, :], cmap='gray')
title_name = 'kernel' + str(i) + ',channel1'
plt.title(title_name)
plt.show()
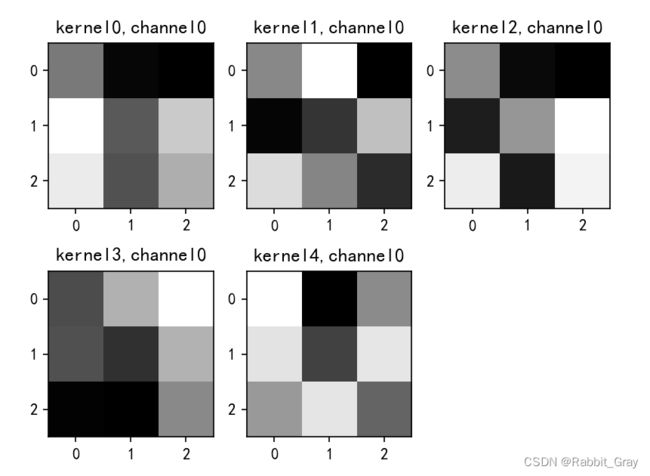
if key == "conv2.weight":
weight_t = model1.state_dict()[key].numpy()
print("weight_t.shape", weight_t.shape)
k = weight_t[:, :, :, :] # 获取第一个卷积核的信息参数
print(k.shape)
print(k)
plt.figure()
for c in range(9):
channel = k[:, c, :, :]
for i in range(5):
ax = plt.subplot(2, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
plt.imshow(channel[i, :, :], cmap='gray')
title_name = 'kernel' + str(i) + ',channel' + str(c)
plt.title(title_name)
plt.show()