LSTM(长短时记忆网络)原理、pytorch实现、参数量分析以及应用场景简单总结
目录
一、LSTM原理
遗忘门
输入门
细胞状态更新
输出门
LSTM数学模型
二、lstm的实现
三 、lstm学习参数总量分析一级pytorch框架下lstm输入总结
1、学习参数总量分析
2、pytorch中lstm模型输入的说明
关于参数量和Layernum和是否双向的关系:
四、lstm简单应用场景的总结
RNN循环神经网络在解决一些时序问题上是很成功的,但是RNN由于在梯度反向传播的时候,每一步都会乘以一个参数W,当传递的步数很长了,就会导致梯度爆炸和梯度消失——也就是长距离依赖问题。为了解决这个问题,基于RNN就提出了LSTM模型。它采用门机制来实现信息的存储,从而解决了长距离依赖问题。至于LSTM具体是如何缓解了梯度消失和梯度爆炸的问题参考知乎文章——LSTM如何解决梯度消失问题和RNN梯度消失和爆炸的原因
一、LSTM原理
首先来看看LSTM的总体结构图: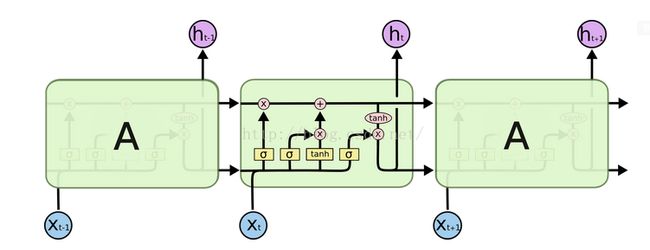
图中一些节点和网络的含义解释如下:
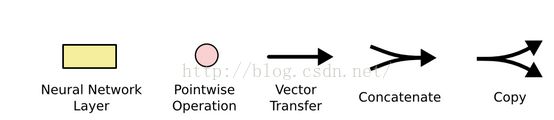
LSTM的核心理念就是采用门控机制来实现信息的长距离传递,从而来削弱梯度消失和梯度爆炸的问题。LSTM主要的是3个门和一个细胞状态来实现它的功能的。
遗忘门
它的作用就是控制是否遗忘的——在LSTM中以一定的概率控制是否遗忘上一层或者上一节点的或者上一时刻的细胞状态。它的结构如下图:
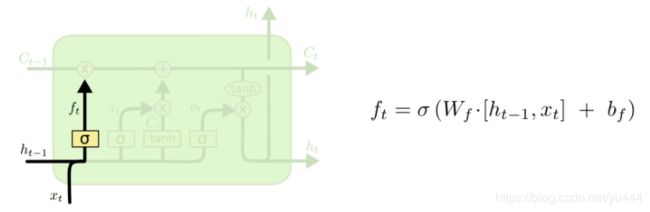
图中的 就是遗忘门。右边的公式就是遗忘门的具体实现,它输出是0和1之间的数字。是上一节点的输出状态,
就是遗忘门。右边的公式就是遗忘门的具体实现,它输出是0和1之间的数字。是上一节点的输出状态, 当前时刻的输入。
当前时刻的输入。 是sigmoid激活函数,
是sigmoid激活函数,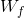 和
和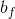 就是学习参数。
就是学习参数。
输入门
当前时刻的输入,对于全局来说怎么样,是否很重要,这个就需要输入门来控制了。输入门的目的就是来判断当前输入对于整个全局来说的重要性。当输入门打开的时候,网络就讲不考虑当前输入,那么当前输入的信息就不会被传递到下一节点或者时刻。只有当输入门关闭的时候,当前输入的信息就会传递到后续的节点或者时刻。结构如下图:
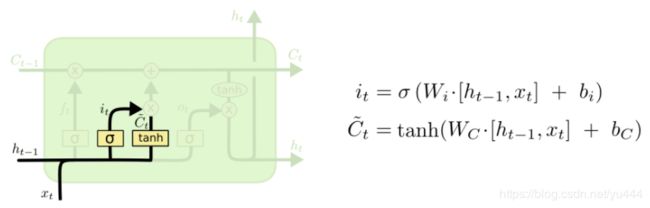
由两部分组成,分别由sigmoid和tanh激活函数来激活。
细胞状态更新
在经过遗忘门和输入门的处理后,会得到一部分的信息,这些信息就会被存储起来,然后传递到后续节点或者时刻。也就是说细胞状态更新的是由遗忘门和输入门的结果联合决定的。看结构原理图:
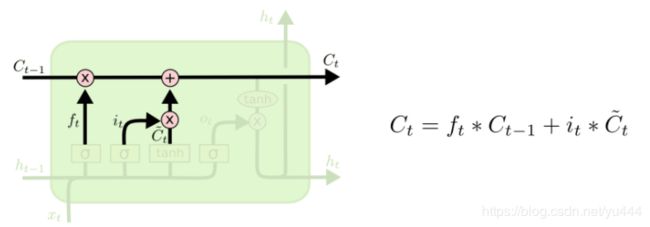
当输入门闭合时它的值是1,遗忘门打开时它的值是0。这里的Ct能够存储以前和当前相关的信息,即使长距离也能够保存,从思想上就能解决长距离依赖问题。Ct得到更新后,然后专递给下一节点或者时刻。
输出门
输出门的作用就是把最后的内容输出。这里输出的内容是来自Ct、ht-1和Xt。这里还有一个过滤机制,Ot来判定Ct那些信息是有用的,那些是无用的,然后把有用的信息输出。结构图:
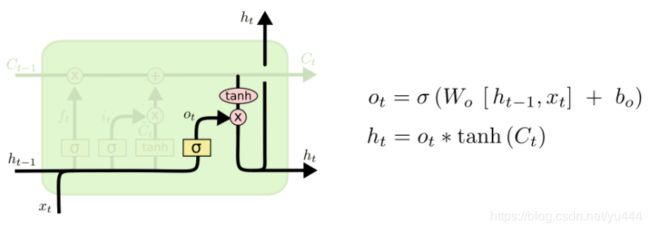
结构图中的数学公式已经很清晰的构建出来LSTM的数学模型,为了进一步理解LSTM模型的参数,构建更加详细的数学模型。
LSTM数学模型
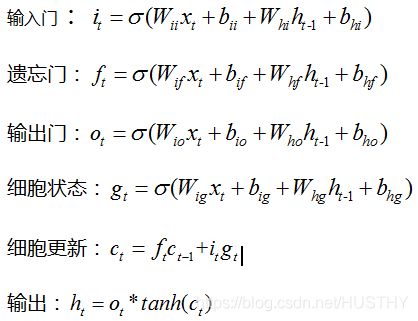
对比pytorch官网实现lstm给出的数学公式:
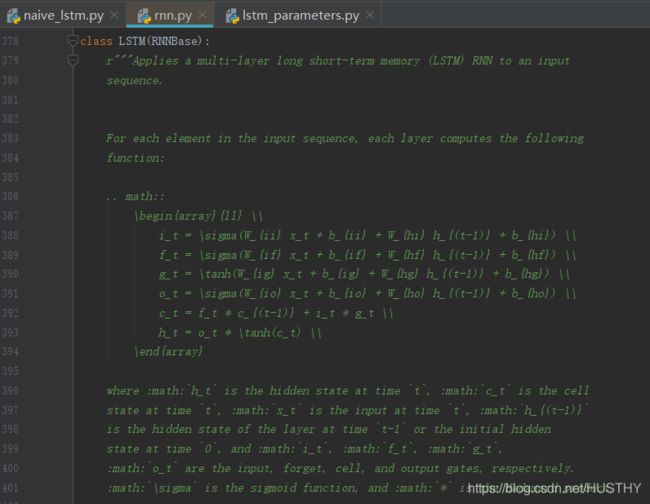
二、lstm的实现
关于lstm的实现,这里直接参考博文——pytorch 学习 | 使用pytorch动手实现LSTM模块;代码中只实现了time-step为1的情况,我这里稍微做了修改,实现了输入序列长度的time-step的sltm。代码如下:
代码段 小部件
然后使用pytorch的LSTM模块儿实现以下LSTM,代码:
lstm = nn.LSTM(10,20,batch_first=True)
reset_weights(lstm)
output, (ht, ct) = lstm(inputs, (h0, c0))
print('nn.LSTM from pytorch:')
print('output:', output)
print('ht:', ht)
print('ct:', ct)
print('output.size():', output.size())
print('ht.size():', ht.size())
print('ct.size():', ct.size())
看看最后他们的输出结果是什么样的,期望应该是一样的,那么证明我们自己实现打lstm并没有错误,结果展示:
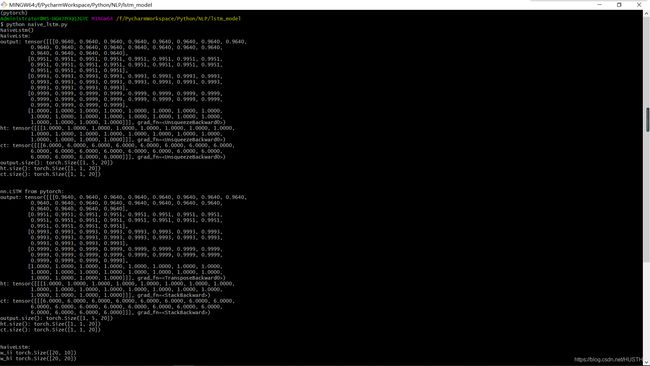
对比发现,给与同样的输入,输出结果完全一样。
三 、lstm学习参数总量分析一级pytorch框架下lstm输入总结
1、学习参数总量分析
直接从数学模型和我们自己实现的lstm模型代码来看,总体的学习参数只有4个部分:它们分别是输入门、遗忘门、输出门和细胞状态对应的学习参数。这4个部分的学习参数数量是一模一样的。对于给定inputsize和hidden_size,得出lstm模型的参数量有:
代码段 小部件
检测一下参数总量(hidden_size = 20;input_size=10),上代码:
print('NaiveLstm:')
for name,param in my_lstm.named_parameters():
print(name,param.size())
print('\n')
print('nn.LSTM from pytorch:')
for name,param in lstm.named_parameters():
print(name,param.size())
上结果图:

我们自己实现的lstm参数量:4*[(10+20+1+1)*20]=2560
pytorch中的lstm模块的参数量:80*32 = 2560
一模一样!说明上面我们自己实现的lstm模型没有问题,并且参数的总量公式也没有问题!
2、pytorch中lstm模型输入的说明
首选看看LSTM模型的构建代码:
self.rnn = nn.LSTM(
input_size = INPUT_SIZE,
hidden_size = HIDDEN_SIZE,
num_layers = LAYERS,
dropout = DROP_RATE,
batch_first = True, # 如果为True,输入输出数据格式是(batch, seq_len, feature)
# 为False,输入输出数据格式是(seq_len, batch, feature)
bidirectional = False #单双向的lstm控制
)
在使用lstm的时候,输入3个变量以及输出结果的shape如下:
output, (ht, ct) = lstm(inputs, (h0, c0))
注意inputs,h0,c0和output, (ht, ct)它们的shape:注意到num_directions就是1和2
1、当batch_first = True时:
inputs:[batch_size,seq_length,input_size]
h0:[batch_size,num_layers*num_directions,hidden_size]
c0:[batch_size,num_layers*num_directions,hidden_size]
output:[batch_size,seq_length,num_directions*hidden_size]
ht:[batch_size,num_layers*num_directions,hidden_size]
ct:[batch_size,num_layers*num_directions,hidden_size]
2、当batch_first = False时:
inputs:[seq_length,batch_size,input_size]
h0:[num_layers*num_directions,batch_size,hidden_size]
c0:[num_layers*num_directions,batch_size,hidden_size]
output:[seq_length,batch_size,num_directions*hidden_size]
ht:[num_layers*num_directions,batch_size,hidden_size]
ct:[num_layers*num_directions,batch_size,hidden_size]补充一下:
值得注意的是,我们的输入inputs:[batch_size,seq_length,input_size]中的input_size在NLP中就相当于每个字、词向量的wordembedding维度,这个input_size也是lstm输入的input_size;另外lstm的hidden_size就是自己定义的,就是想得到的lstm输出是一个什么样的hidden_size,和输入向量X的input_size以及seq_length是没有直接意义上的关联的。
关于参数量和Layernum和是否双向的关系:
对于单向的LSTM,参数空间在layer_num不同情况下就有不同的参数空间:
#num_layers=1,单向
LSTM(10, 20, batch_first=True)
nn.LSTM from pytorch:
weight_ih_l0 torch.Size([80, 10])
weight_hh_l0 torch.Size([80, 20])
bias_ih_l0 torch.Size([80])
bias_hh_l0 torch.Size([80])
params total: 2560
#num_layers=2,单向
LSTM(10, 20, num_layers=2, batch_first=True)
nn.LSTM from pytorch:
weight_ih_l0 torch.Size([80, 10])
weight_hh_l0 torch.Size([80, 20])
bias_ih_l0 torch.Size([80])
bias_hh_l0 torch.Size([80])
weight_ih_l1 torch.Size([80, 20])
weight_hh_l1 torch.Size([80, 20])
bias_ih_l1 torch.Size([80])
bias_hh_l1 torch.Size([80])
params total: 5920
#num_layers = 3,单向
LSTM(10, 20, num_layers=3, batch_first=True)
nn.LSTM from pytorch:
weight_ih_l0 torch.Size([80, 10])
weight_hh_l0 torch.Size([80, 20])
bias_ih_l0 torch.Size([80])
bias_hh_l0 torch.Size([80])
weight_ih_l1 torch.Size([80, 20])
weight_hh_l1 torch.Size([80, 20])
bias_ih_l1 torch.Size([80])
bias_hh_l1 torch.Size([80])
weight_ih_l2 torch.Size([80, 20])
weight_hh_l2 torch.Size([80, 20])
bias_ih_l2 torch.Size([80])
bias_hh_l2 torch.Size([80])
params total: 9280总结:参数总量为:[4*[(input_size+hidden_size)+1+1]*hidden_size]+[4*[(hidden_size+hidden_size)+1+1]*hidden_size]*(layer_num-1)
当lstm为双向的话:
#layer_num=1,num_direction=2
LSTM(10, 20, batch_first=True, bidirectional=True)
nn.LSTM from pytorch:
weight_ih_l0 torch.Size([80, 10])
weight_hh_l0 torch.Size([80, 20])
bias_ih_l0 torch.Size([80])
bias_hh_l0 torch.Size([80])
weight_ih_l0_reverse torch.Size([80, 10])
weight_hh_l0_reverse torch.Size([80, 20])
bias_ih_l0_reverse torch.Size([80])
bias_hh_l0_reverse torch.Size([80])
params total: 5120
#layer_num=2,num_direction=2
LSTM(10, 20, num_layers=2, batch_first=True, bidirectional=True)
nn.LSTM from pytorch:
weight_ih_l0 torch.Size([80, 10])
weight_hh_l0 torch.Size([80, 20])
bias_ih_l0 torch.Size([80])
bias_hh_l0 torch.Size([80])
weight_ih_l0_reverse torch.Size([80, 10])
weight_hh_l0_reverse torch.Size([80, 20])
bias_ih_l0_reverse torch.Size([80])
bias_hh_l0_reverse torch.Size([80])
weight_ih_l1 torch.Size([80, 40])
weight_hh_l1 torch.Size([80, 20])
bias_ih_l1 torch.Size([80])
bias_hh_l1 torch.Size([80])
weight_ih_l1_reverse torch.Size([80, 40])
weight_hh_l1_reverse torch.Size([80, 20])
bias_ih_l1_reverse torch.Size([80])
bias_hh_l1_reverse torch.Size([80])
15040
#layer_num=3,num_direction=2
LSTM(10, 20, num_layers=3, batch_first=True, bidirectional=True)
nn.LSTM from pytorch:
weight_ih_l0 torch.Size([80, 10])
weight_hh_l0 torch.Size([80, 20])
bias_ih_l0 torch.Size([80])
bias_hh_l0 torch.Size([80])
weight_ih_l0_reverse torch.Size([80, 10])
weight_hh_l0_reverse torch.Size([80, 20])
bias_ih_l0_reverse torch.Size([80])
bias_hh_l0_reverse torch.Size([80])
weight_ih_l1 torch.Size([80, 40])
weight_hh_l1 torch.Size([80, 20])
bias_ih_l1 torch.Size([80])
bias_hh_l1 torch.Size([80])
weight_ih_l1_reverse torch.Size([80, 40])
weight_hh_l1_reverse torch.Size([80, 20])
bias_ih_l1_reverse torch.Size([80])
bias_hh_l1_reverse torch.Size([80])
weight_ih_l2 torch.Size([80, 40])
weight_hh_l2 torch.Size([80, 20])
bias_ih_l2 torch.Size([80])
bias_hh_l2 torch.Size([80])
weight_ih_l2_reverse torch.Size([80, 40])
weight_hh_l2_reverse torch.Size([80, 20])
bias_ih_l2_reverse torch.Size([80])
bias_hh_l2_reverse torch.Size([80])
params total: 24960总结:参数总量为:[4*[(input_size+hidden_size)+1+1]*hidden_size]*num_dirction+[4*[(hidden_size*2+hidden_size)+1+1]*hidden_size]*num_dirction*(layer_num-1)
四、lstm简单应用场景的总结
1、CV和语音识别领域
2、NLP中:文本分类、情感分析、文本生成和命名实体识别——目前比较主流的方法就是lstm+CRF
其实关于应用场景目前我了解的不多,这些场景都是从网上找到的,自己动手实践的场景并没有,接下来想把lstm+CRF给做一做,其实文本分类和情感分析应该有其他更好的算法或者模型可供选择!传统的机器学习算法或者bert模型。
参考文章
LSTM模型介绍——文章中的LSTM结构图直接用的
三次简化一张图:一招理解LSTM/GRU门控机制
pytorch 学习 | 使用pytorch动手实现LSTM模块
总结PYTORCH中nn.lstm(自官方文档整理 包括参数、实例)