PyTorch中的循环神经网络(RNN+LSTM+GRU)
一、RNN网络
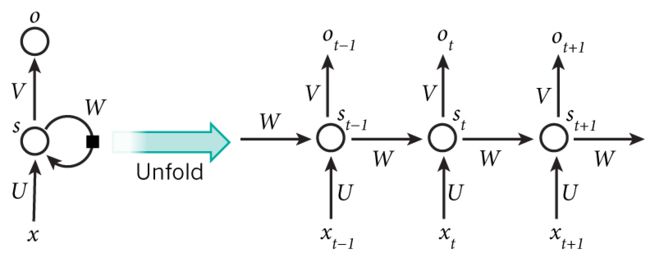
1、Pytorch中的RNN参数详解
rnn = nn.RNN(*arg,**kwargs)
(1)input_size:输入 x t x_t xt的维度
(2)hidden_size:输出 h t h_t ht的维度
(3)num_layers:网络的层数,默认为1层
(4)nonlinearity:非线性激活函数,默认是tanh,也可以选择relu等
(5)bias:是否有偏置。默认为True
(6)batch first:决定网络输入的维度顺序,默认为(seq,batch,feature),如果参数设置为True,顺序变为(batch,seq,feature)。RNN batch在第二个维度,CNN batch在第一个维度。
(7)dropout:接受一个0-1之间的数值,会在网络中除了最后一层外的其他输出层加上dropout层。
(8)bidirectional:默认为False,表示单项循环神经网络;如果设置为True,就是双向循环神经网络。
2、输入、输出的维度
(1)网络节后一个序列输入 x t x_t xt和记忆输入 h 0 h_0 h0。 x t x_t xt的维度是(seq,batch,feature); h 0 h_0 h0隐状态的维度 ( l a y e r s ∗ d i r e c t i o n , b a t c h , h i d d e n ) (layers*direction,batch,hidden) (layers∗direction,batch,hidden),表示层数乘以方向(单项为1,双向为2),批量,输出的维度
(2)网络会输出output和 h t h_t ht。output表示网络实际的输出,维度是(seq,batch,hidden*direction),表示序列长度、批量和输出维度乘以方向; h t h_t ht表示记忆单元,维度 ( l a y e r s ∗ d i r e c t i o n , b a t c h , h i d d e n ) (layers*direction,batch,hidden) (layers∗direction,batch,hidden),表示层数乘以方向,批量,输出的维度
3、需要注意的问题:
(1)网络输出是 ( s e q , b a t c h , h i d d e n ∗ d i r e c t i o n ) (seq,batch,hidden*direction) (seq,batch,hidden∗direction),direction=1或2。如果是双向的网络结构,相当于网络从左往右计算一次,再从右往左计算依次,这样会有两个结果。将两个结果按最后一个维度拼接起来,就是输出的维度。
(2)隐藏状态的网络大小、输入和输出都是(layer*direction,batch,hidden)时,因为如果网络有多层,那么每一层都有一个新的记忆单元,而双向网络结构在每一层左右会有两个不同的记忆单元,所以维度的第一位是 l a y e r ∗ d i r e c t i o n layer*direction layer∗direction
4、RNN代码实现
import torch
from torch.autograd import Variable
import torch.nn as nn
rnn = nn.RNN(input_size=20,hidden_size=50,num_layers=2)
input_data = Variable(torch.randn(100,32,20)) #seq,batch,feature
#如果传入网络时,不特别注明隐状态,那么输出的隐状态默认参数全是0
h_0 = Variable(torch.randn(2,32,50)) #layer*direction,batch,hidden_size
output,h_t = rnn(input_data,h_0)
print(output.size()) #seq,batch,hidden_size
print(h_t.size()) #layer*direction,batch,hidden_size
print(rnn.weight_ih_l0.size())
打印结果:
torch.Size([100, 32, 50])
torch.Size([2, 32, 50])
torch.Size([50, 20]
二、LSTM网络
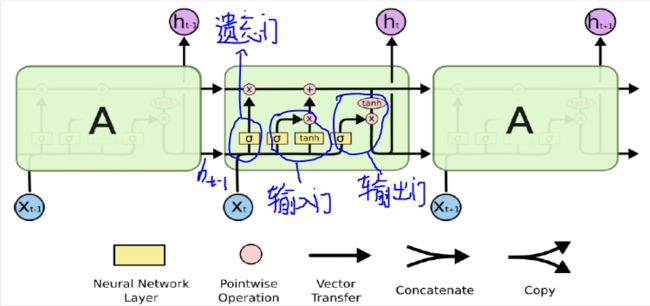
1、LSTM介绍
rnn = nn.LSTM(*arg,**kwargs)
LSTM在本质上和标准 RNN一样的,下面主要介绍两者的不同:
(1)LSTM参数是RNN的四倍
因为LSTM中间比标准RNN多了三个线性变换,多的三个线性变换的权主拼在一起, 所以一共是 4 倍,同理偏置也是4倍。
(2)输入和输出多了一个记忆单元
LSTM的输入也不再只有序列输入和隐藏状态,隐藏状态除了 h 0 h_0 h0以外,还多了一个 C 0 C_0 C0它们合在一起成为网络的隐藏状态,而且它们的大小完全一样,第一事故(layer*direction,batch,hidden),当然输出也会有 h t h_t ht和 C t C_t Ct
2、LSTM代码实现
#定义网络
lstm = nn.LSTM(input_size=20,hidden_size=50,num_layers=2)
#输入变量
input_data = Variable(torch.randn(100,32,20))
#初始隐状态
h_0 = Variable(torch.randn(2,32,50))
#输出记忆细胞
c_0 = Variable(torch.randn(2,32,50))
#输出变量
output,(h_t,c_t) = lstm(input_data,(h_0,c_0))
print(output.size())
print(h_t.size())
print(c_t.size())
#参数大小为(50x4,20),是RNN的四倍
print(lstm.weight_ih_l0)
print(lstm.weight_ih_l0.size())
打印结果:
torch.Size([100, 32, 50])
torch.Size([2, 32, 50])
torch.Size([2, 32, 50])
tensor([[ 0.0068, -0.0925, -0.0343, …, -0.1059, 0.0045, -0.1335],
[-0.0509, 0.0135, 0.0100, …, 0.0282, -0.1232, 0.0330],
[-0.0425, 0.1392, 0.1140, …, -0.0740, -0.1214, 0.1087],
…,
[ 0.0217, -0.0032, 0.0815, …, -0.0605, 0.0636, 0.1197],
[ 0.0144, 0.1288, -0.0569, …, 0.1361, 0.0837, -0.0021],
[ 0.0355, 0.1045, 0.0339, …, 0.1412, 0.0371, 0.0649]],
requires_grad=True)
torch.Size([200, 20])
三、GRU网络
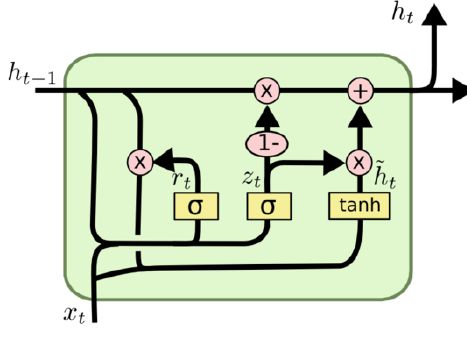
1、GRU介绍
rnn = nn.GRU(*arg,**kwargs)
GRU将LSTM的输入门和遗忘门合并。与LSTM有如下2个不同:
(1)GRU参数是RNN的三倍
(2)隐状态是有 h 0 h_0 h0
从结构图可以看出,GRU隐状态不再是 h 0 h_0 h0和 C 0 C_0 C0,只有一个 h 0 h_0 h0,输出也只有一个 h t h_t ht
2、代码实现
gru = nn.GRU(input_size=20,hidden_size=50,num_layers=2)
#输入变量
input_data = Variable(torch.randn(100,32,20))
#初始隐状态
h_0 = Variable(torch.randn(2,32,50))
#输出变量
output,(h_n,c_n) = gru(input_data) #lstm(input_data,h_0) 不定义初始隐状态默认为0
print(output.size())
print(h_n.size())
print(gru.weight_ih_l0)
print(gru.weight_ih_l0.size())
打印结果:
torch.Size([100, 32, 50])
torch.Size([32, 50])
Parameter containing:
tensor([[ 0.0878, 0.0383, -0.0261, …, 0.0801, -0.0932, -0.1267],
[ 0.0275, 0.1129, -0.0306, …, -0.0837, 0.0824, -0.1332],
[ 0.1061, -0.0786, -0.0163, …, -0.0622, -0.0350, -0.0417],
…,
[-0.0923, -0.0106, -0.0196, …, 0.0944, 0.0085, 0.0387],
[-0.0181, 0.0431, -0.1382, …, -0.1383, 0.0229, 0.1021],
[-0.0962, 0.0980, -0.0306, …, 0.0871, -0.0827, -0.0811]],
requires_grad=True)
torch.Size([150, 20])
PyTorch 中还提供了RNNCell、LSTMCell、GRUCell,这三个分别是上面介绍的三个函数的单步版木,也就是说它们的输入不再是一个 序列,而是一个序列中的一步,也可以说是循环神经网络的一个循环,在序列的应用上更加灵活,因为序列中每一步都是手动实现的,能够在基础上添加更多自定义的操作。