CentOS 7 下 Hadoop全分布式集群搭建
CentOS 7 下 Hadoop全分布式集群搭建
Hadoop集群搭建
- CentOS 7 下 Hadoop全分布式集群搭建
- 一、概念
-
- 1.单机模式(独立模式)(Local或Standalone Mode)
- 2.伪分布式模式(Pseudo-Distrubuted Mode)
- 3.全分布式集群模式(Full-Distributed Mode)
- 二、基础环境
-
- 1.安装java
- 2.安装Hadoop
- 3. 关闭防火墙
- 4.修改IP和主机名
- 5.配置host使IP和主机名关系映射
- 三、配置Hadoop集群
-
- 1.修改配置文件:
- 2.克隆 2 台客户机
- 3.设置 ssh 免密登录
- 4.格式化 Namenode
- 5.启动
- 四、some tips
本文来自csdn的⭐️shu天⭐️,平时会记录ctf、取证和渗透相关的文章,欢迎大家来我的主页:shu天_CSDN博客-ctf,取证,web领域博主 看看ヾ(@ ˘ω˘ @)ノ!!
一、概念
Hadoop的三种运行模式(启动模式):
1.单机模式(独立模式)(Local或Standalone Mode)
- 默认情况下,Hadoop即处于该模式,用于开发和调式。
- 不对配置文件进行修改。
- 使用本地文件系统,而不是分布式文件系统。
- Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
- 用于对MapReduce程序的逻辑进行调试,确保程序的正确。
2.伪分布式模式(Pseudo-Distrubuted Mode)
-
Hadoop的守护进程运行在本机机器,模拟一个小规模的集群
-
在一台主机模拟多主机。
-
Hadoop启动NameNode、DataNode、JobTracker、TaskTracker这些守护进程都在同一台机器上运行,是相互独立的Java进程。
-
在这种模式下,Hadoop使用的是分布式文件系统,各个作业也是由JobTraker服务,来管理的独立进程。在单机模式之上增加了代码调试功能,允许检查内存使用情况,HDFS输入输出,
以及其他的守护进程交互。类似于完全分布式模式,因此,这种模式常用来开发测试Hadoop程序的执行是否正确。
- 修改3个配置文件:core-site.xml(Hadoop集群的特性,作用于全部进程及客户端)、hdfs-site.xml(配置HDFS集群的工作属性)、mapred-site.xml(配置MapReduce集群的属性)
- 格式化文件系统
3.全分布式集群模式(Full-Distributed Mode)
-
Hadoop的守护进程运行在一个集群上
-
Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
-
在所有的主机上安装JDK和Hadoop,组成相互连通的网络。
-
在主机间设置SSH免密码登录,把各从节点生成的公钥添加到主节点的信任列表。
-
修改3个配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml,指定NameNode和JobTraker的位置和端口,设置文件的副本等参数
-
格式化文件系统
二、基础环境
我的环境是centos7,镜像下载地址:https://mirrors.tuna.tsinghua.edu.cn/centos/7.9.2009/isos/x86_64/

CentOS-7-x86_64-DVD-2009.iso的版本是自带java的,推荐!
可以先配置好一个机子,之后可以克隆两个机子搭集群。
1.安装java
检测是否有java环境:
rpm -qa|grep java
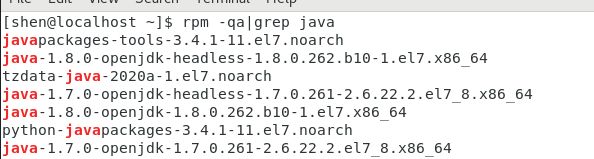
如果没有则安装好java并配置环境变量
2.安装Hadoop
hadoop下载地址:https://archive.apache.org/dist/hadoop/common/
我用的是2.8.4版本:https://archive.apache.org/dist/hadoop/common/hadoop-2.8.4/hadoop-2.8.4.tar.gz
在/opt 目录下创建两个子文件
mkdir /opt/module /opt/soft
解压 hadoop 到/opt/module 目录下
tar -zxvf hadoop-2.8.4.tar.gz -C /opt/module/
配置环境变量
vi /etc/profile
export JAVA_HOME=/usr
export HADOOP_HOME=/opt/module/hadoop-2.8.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile //source命令也称为“ 点命令 ”,也就是一个点符号(.),是bash的内部命令。 source命令通常用于重新执行刚修改的初始化文件,使之立即生效,而不必注销并重新登录。
ps.寻找java安装目录
which java ls -lrt /usr/bin/java ls -lrt /etc/alternatives/java
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64/jre即是我们需要添加的JAVA_HOME环境变量

3. 关闭防火墙
systemctl stop firewalld.service //关闭防火墙
systemctl disable firewalld.service //禁用防火墙
systemctl status firewalld.service //查看防火墙
//关闭 Selinux
vi /etc/selinux/config
将 SELINUX=enforcing 改为 SELINUX=disabled
4.修改IP和主机名
(1)修改IP:
修改/etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="static"
ONBOOT="yes"
IPADDR=192.168.110.51
GATEWAY=192.168.110.2
DNS1=8.8.8.8
DNS2=8.8.4.4
NETMASK=255.255.255.0
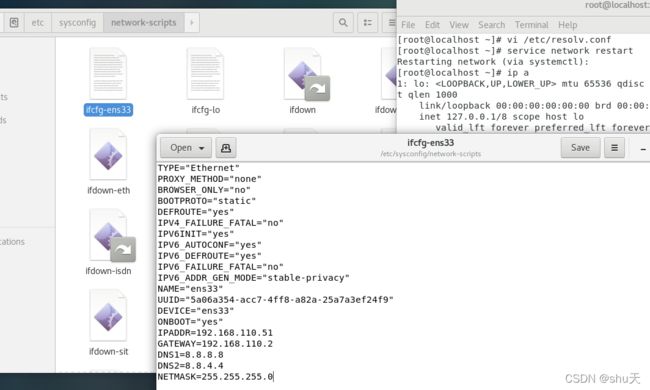
其他两台分别为192.168.110.52、192.168.110.53
(2)配置DNS服务器
vi /etc/resolv.conf
nameserver 8.8.8.8
nameserver 8.8.4.4
修改后重启网卡
service network restart
(3)主机名:
hostnamectl set-hostname 主机名
三台分别为c1,c2,c3
5.配置host使IP和主机名关系映射
vi /etc/hosts
192.168.110.51 c1
192.168.110.52 c2
192.168.110.53 c3
三、配置Hadoop集群
集群部署规划:
| c1 | c2 | c3 | |
|---|---|---|---|
| HDFS | NameNode SecondaryNameNode DataNode |
DataNode | DataNode |
| YARN | NodeManager | ResourceManager NodeManager |
NodeManager |
1.修改配置文件:
配置文件都在hadoop-2.8.4/etc/hadoop/目录下
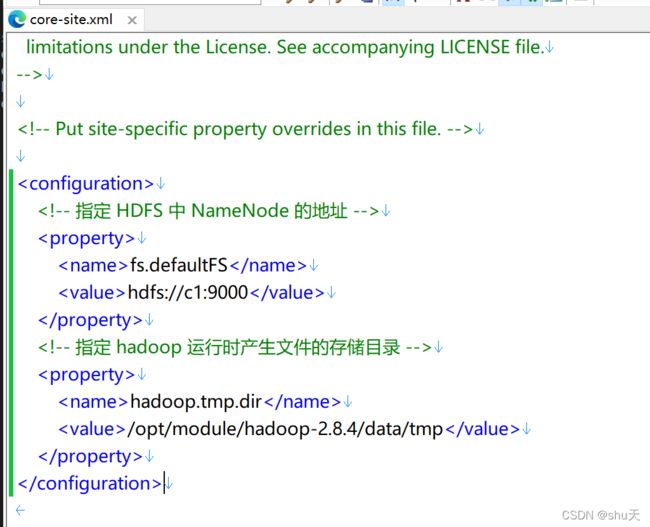
core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://主机名 1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-2.X.X/data/tmpvalue>
property>
hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>主机名 1:50090value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>主机名 2value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>主机名 2:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>主机名 2:19888value>
property>
分别在hadoop-env.sh、yarn-env.sh、mapred-env.sh这些的文件中添加下面的路径
export JAVA_HOME=/usr
slaves
c1
c2
c3
2.克隆 2 台客户机
克隆完之后记得改hostname和IP等等
3.设置 ssh 免密登录
生成 id_rsa(私钥)和id_rsa.pub(公钥):
ssh-keygen -t rsa
将公钥拷贝到要免密登录的目标机器上(ssh-copy-id 主机名)
ssh-copy-id c1
ssh-copy-id c2
ssh-copy-id c3
注:在另外两台机器上分别执行,共执行 9 遍(打开同步会话的话另两台不需要分别执行)
ps .ssh 文件夹下的文件功能解释
查看/root/.ssh/下
(1)~/.ssh/known_hosts :记录 ssh访问过计算机的公钥(public key)
(2)id_rsa :生成的私钥
(3)id_rsa.pub :生成的公钥
(4)authorized_keys :存放授权过得无秘登录服务器公钥
4.格式化 Namenode
hdfs namenode -format
5.启动
c1 启动
start-dfs.sh
c2 启动
start-yarn.sh
停止
c1
stop-dfs.sh
c2
stop-yarn.sh
启动后
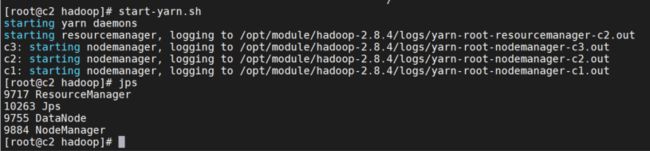
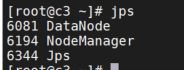
jps 查看进程
jps得到的结果应该和我们之前集群部署规划表是一样的
c1
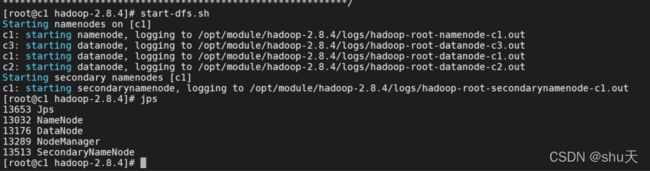
c2
c3
查看web端可以看到节点有三个:http://192.168.110.51:50070/

四、some tips
1.配置文件真的很重要,要是集群出错记得回来检查看有没有配置错(修改完配置文件需要重新格式化hadoop namenode –format)
2.如果有节点对应功能起不来得去看运行日志,根据报错找解决方法
参考:https://www.cnblogs.com/zhangyinhua/p/7647686.html#_label2
本文来自csdn的⭐️shu天⭐️,平时会记录ctf、取证和渗透相关的文章,欢迎大家来我的主页:shu天_CSDN博客-ctf,取证,web领域博主 看看ヾ(@ ˘ω˘ @)ノ!!