C++面试整理
目录
写在前面
操作系统
计算机网络
数据库
C++
算法
面试
其它
分布式
hr面
写在前面
最近开始准备找实习了,收到某位大佬的指导,说可以上牛客网把相关的面经都刷一遍,记录下考点各个击破。大佬是搞java的,已经把java的刷完了,看了一下觉得很受用,因此也准备刷下c++的。顺带附上大佬的java总结:java实习&秋招面经整理 - 知乎
面经整理:
c++面经:2021 秋招面经总结 —— C++ 篇(六) - 力扣(LeetCode)
基础知识:阿里、腾讯、字节、快手、美团| JAVA 开发岗|2020 春招、2021 秋招面试高频问题总结 - 力扣(LeetCode)
argue薪资:如何跟hr聊薪资,argue薪资的技巧全在这里
算法题汇总:GitHub - afatcoder/LeetcodeTop: 汇总各大互联网公司容易考察的高频leetcode题
逆袭进大厂:《InterviewGuide》第一弹之C++篇49问49答_笔经面经_牛客网
八股文汇总:https://www.notion.so/a8209820a2524d91858e14824cb60037
八股文汇总2:CS-Notes
蒋豆芽面试总结:C++开发面经与嵌入式软件面经(蒋豆芽面试题总结)_牛客博客
C语言学习网:C++ stable_sort()用法详解
智力题汇总:blog.csdn.net/basycia/article/details/52138129
题目库:CodeTop企业题库
海量数据场景解题方法:秒杀99%的海量数据处理面试题 - sunsky303 - 博客园
操作系统
1.如何查看系统中的内存状态
2.Linux指令:查看进程状态?查看文件信息?查看内存使用?查看磁盘占有量?Grep指令的原理;
top命令:Linux top命令小结 - 简书
grep命令:Linux下的grep命令详解_学如逆水行舟的技术博客_51CTO博客_grep命令详解_linux grep命令详解
查看磁盘:linux查看磁盘使用情况命令_陈袁的博客-CSDN博客_linux 查看磁盘
3.操作系统:进程与线程的区别?Linux系统中两者有区别吗?软链接与硬链接的区别(不会)?用户态与内核态的区别(用读文件举例说明)?
4.死锁的原因
操作系统------死锁的条件和解决方法_ZJE-CSDN博客
面试问题之操作系统:死锁的四个必要条件和解决办法 - 知了会爬树 - 博客园
5.虚拟内存
在现代操作系统中,进程之间共享使用cpu和内存,但是内存资源有限,为了更加高效地使用内存,现代操作系统提供一个内存抽象—虚拟内存。虚拟内存巧妙地利用内存,地址转换,磁盘文件和操作系统内核来为每一个进程提供足够大的统一的私有地址空间。虚拟内存提供三个重要的能力:1)将内存当作磁盘的缓存,在内存中只保留常用数据,必要时从内存和磁盘之间交换数据。2)简化内存管理,为每个进程提供统一的地址空间。3)保护进程的内存空间不受其他进程影响。
6.常见排序算法,排序算法稳定的意思,快排的复杂度什么时候退化,基本有序用什么
7.进程线程,虚拟内存,页面置换
8.内存访问磁盘数据
9.epoll
10.内核态用户态的区别
用户态(user mode) : 用户态运行的进程或可以直接读取用户程序的数据。
内核态(kernel mode):可以简单的理解系统态运行的进程或程序几乎可以访问计算机的任何资源,不受限制。用户态到内核态具体的切换步骤:
(1)从当前进程的描述符中提取其内核栈的ss0及esp0信息。
(2)使用ss0和esp0指向的内核栈将当前进程的cs,eip,eflags,ss,esp信息保存起来,这个过程也完成了由用户栈到内核栈的切换过程,同时保存了被暂停执行的程序的下一条指令。
(3)将先前由中断向量检索得到的中断处理程序的cs,eip信息装入相应的寄存器,开始执行中断处理程序,这时就转到了内核态的程序执行了。
ss0是任务内核态堆栈的段选择符,esp0是堆栈栈底指针
11.描述并写一下LRU
12.进程间通信的共享内存,如何保证安全性,结合epoll讲讲共享内存;共享内存通信方式
用信号量来实现使用共享内存的不同进程间的同步工作。
(1)锁。操作系统为我们提供了多种类型的锁,诸如互斥锁、读写锁、自旋锁等。互斥锁(pthread_mutex_t)可以保证线程间的互斥锁,通过设置互斥锁的进程间共享属性,可以实现进程间共用互斥锁。相应地,我们可以将读写锁、自旋锁改造为多进程共享的。这种方式有一个隐患:当加锁进程异常退出时,其他进程可能永远无法抢到锁。
(2)信号量也是一个常见的多进程同步方式。通过semget或者sem_open打开一个信号量,然后通过PV操作来达到进程间互斥的效果。但是信号量也存在加锁进程异常退出时,不能自动解锁的问题。
(3)文件记录锁可以锁定文件的一部分或者全部。假设我们将文件与共享内存中的数据块对应起来,则可以通过文件锁来同步共享内存的读写操作。值得说明的时,当进程异常退出时,该进程持有的文件锁会自动释放。相对于信号量,文件锁的效率稍差。
共享内存的数据同步 - 程序园
linux实现共享内存同步的四种方法_sunxiaopengsun的专栏-CSDN博客_共享内存同步机制
13.Pipe和fifo的区别
14.硬连接/软连接
硬链接: 硬连接指通过索引节点 inode 来进行的连接,即每一个硬链接都是一个指向对应区域的文件。
软链接: 保存了其代表的文件的绝对路径,是另外一种文件,在硬盘上有独立的区块, 访问时替换自身路径。
Linux硬链接和软连接的区别与总结 - Hsia的博客 | Hsia Blog
Linux软连接和硬链接 - iTech - 博客园
15.查看文件指定某一行。
sed -n '10p' test_classification.py
sed -n '10,20p' test_classification.py
16.查看端口占用
lsof -i:端口号 用于查看某一端口的占用情况,比如查看8000端口使用情况,lsof -i:8000
netstat -tunlp |grep 端口号,用于查看指定的端口号的进程情况,如查看8000端口的情况,netstat -tunlp |grep 8000
Linux 查看端口占用情况 - 菜鸟++ - 博客园
17.如何查看日志
head\tail\cat\less\more
18.什么是线程不安全
19.什么是IO复用,什么是非阻塞IO
20.select\poll\epoll
Netty——(3)高并发编程必备知识IO多路复用技术select、poll、epoll分析_探索的小白-CSDN博客
IO多路复用之select、poll、epoll - Yungyu - 博客园
21.线程共享进程的资源里的局部变量等属于堆还是栈
22.linux怎么查看内存泄漏
使用mtrace命令:利用linux的mtrace命令定位内存泄露(Memory Leak)_zpznba的博客-CSDN博客
使用 Valgrind工具:linux下内存泄露查找、BUG调试 | 学步园
感觉两个工具一样的,都是编译的时候加上-g参数,然后调用工具进行查看
23.如何清除已出现的僵尸进程?
用ps 命令和 grep命令寻找僵尸进程:
ps -A -ostat,ppid,pid,cmd | grep -e '^[Zz]'
命令注解:
-A 参数列出所有进程
-o 自定义输出字段,我们设定显示字段为stat(状态),ppid(父进程pid),pid(进程pid),cmd(命令行)这四个参数因为状态为 z 或者 Z的进程为僵尸进程,所以我们使用grep 抓取stat 状态为zZ进程;
清除僵尸进程的话可以kill掉僵尸进程的父进程。
24.线程、进程上下文切换;为什么线程切换比进程快
- 操作系统保持跟踪进程运行所需的所有状态信息,这种状态,也就是上下文,它包括许多信息,例如PC和寄存器文件的当前值,以及主存的内容。
- 操作系统实现这种交错执行的机制称为上下文切换。
- 当操作系统决定要把控制权从当前进程转移到某个新进程时,就会进行上下文切换,即保存当前进程的上下文,恢复新进程的上下文,然后将控制权传递到新进程,新进程就会从上次停止的地方开始
进程切换分两步:
1.切换页目录以使用新的地址空间
2.切换内核栈和硬件上下文
对于linux来说,线程和进程的最大区别就在于地址空间,对于线程切换,第1步是不需要做的,第2是进程和线程切换都要做的。
切换的性能消耗:
1、线程上下文切换和进程上下问切换一个最主要的区别是线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的。这两种上下文切换的处理都是通过操作系统内核来完成的。内核的这种切换过程伴随的最显著的性能损耗是将寄存器中的内容切换出。
2、另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。简单的说,一旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作废了。还有一个显著的区别是当你改变虚拟内存空间的时候,处理的页表缓冲(processor’s Translation Lookaside Buffer (TLB))或者相当的神马东西会被全部刷新,这将导致内存的访问在一段时间内相当的低效。但是在线程的切换中,不会出现这个问题。
上下文就是内核重新启动一个被抢占的进程所需的状态。包括一下内容:
- 通用目的寄存器
- 浮点寄存器
- 程序计数器
- 用户栈
- 状态寄存器
- 内核栈
各种内核数据结构:比如描绘地址空间的页表,包含有关当前进程信息的进程表,以及包含进程已打开文件的信息的文件表。
进程切换与线程切换的一个最主要区别就在于进程切换涉及到虚拟地址空间的切换而线程切换则不会。因为每个进程都有自己的虚拟地址空间,而线程是共享所在进程的虚拟地址空间的,因此同一个进程中的线程进行线程切换时不涉及虚拟地址空间的转换。
为什么虚拟地址切换很慢
现在我们已经知道了进程都有自己的虚拟地址空间,把虚拟地址转换为物理地址需要查找页表,页表查找是一个很慢的过程,因此通常使用Cache来缓存常用的地址映射,这样可以加速页表查找,这个cache就是TLB,Translation Lookaside Buffer,我们不需要关心这个名字只需要知道TLB本质上就是一个cache,是用来加速页表查找的。由于每个进程都有自己的虚拟地址空间,那么显然每个进程都有自己的页表,那么当进程切换后页表也要进行切换,页表切换后TLB就失效了,cache失效导致命中率降低,那么虚拟地址转换为物理地址就会变慢,表现出来的就是程序运行会变慢,而线程切换则不会导致TLB失效,因为线程线程无需切换地址空间,因此我们通常说线程切换要比较进程切换块,原因就在这里。
https://segmentfault.com/a/1190000019750164
25.操作系统进程状态有哪些
状态 说明 R running or runnable (on run queue)
正在执行或者可执行,此时进程位于执行队列中。D uninterruptible sleep (usually I/O)
不可中断阻塞,通常为 IO 阻塞。S interruptible sleep (waiting for an event to complete)
可中断阻塞,此时进程正在等待某个事件完成。Z zombie (terminated but not reaped by its parent)
僵死,进程已经终止但是尚未被其父进程获取信息。T stopped (either by a job control signal or because it is being traced)
结束,进程既可以被作业控制信号结束,也可能是正在被追踪。
D和S的区别是:
进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。 而TASK_UNINTERRUPTIBLE状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。
Linux进程状态解析 之 R、S、D、T、Z、X (主要有三个状态)_sdkdlwk的博客-CSDN博客_进程状态

26.进程、线程调度算法
1.先来先服务 first-come first-serverd(FCFS)
2.短作业优先 shortest job first(SJF)
3.最短剩余时间优先 shortest remaining time next(SRTN)
4. 时间片轮转
5.优先级调度
6.多级反馈队列
计算机操作系统 - 进程管理 | CS-Notes
27.线程同步方式、线程通信
线程同步方式:互斥量、信号量、临界区、事件
用户模式下的方法有:原子操作(例如一个单一的全局变量),临界区。
内核模式下的方法有:事件,信号量,互斥量。
临界区
保证在某一时刻只有一个线程能访问数据的简便办法。在任意时刻只允许一个线程对共享资源进行访问。如果有多个线程试图同时访问临界区,那么 在有一个线程进入后其他所有试图访问此临界区的线程将被挂起,并一直持续到进入临界区的线程离开。临界区在被释放后,其他线程可以继续抢占,并以此达到用原子方式操 作共享资源的目的。 仅能在同一进程内使用
互斥量 Mutex
互斥量跟临界区很相似,只有拥有互斥对象的线程才具有访问资源的权限,由于互斥对象只有一个,因此就决定了任何情况下此共享资源都不会同时被多个线程所访问。当前占据资源的线程在任务处理完后应将拥有的互斥对象交出,以便其他线程在获得后得以访问资源。互斥量比临界区复杂。因为使用互斥不仅仅能够在同一应用程序不同线程中实现资源的安全共享,而且可以在不同应用程序的线程之间实现对资源的安全共享。
信号量
信号量对象对线程的同步方式与前面几种方法不同,信号允许多个线程同时使用共享资源 ,这与操作系统中的PV操作相同。
事件(Event)
事件机制,则允许一个线程在处理完一个任务后,主动唤醒另外一个线程执行任务。
线程同步方式比较 - 王小北 - 博客园
28.为什么会发生进程切换,为什么不让一个进程跑下去
29.为什么cpu调度进程要用时间片轮转
30.linux用什么调度算法
完全公平调度算法CFS
进程管理笔记三、完全公平调度算法CFS_邓博学习笔记-CSDN博客
31.字节序
32.同步、异步;阻塞、非阻塞;区别
同步/异步关注的是消息通信机制 (synchronous communication/ asynchronous communication) 。
所谓同步,就是在发出一个调用时,在没有得到结果之前, 该调用就不返回。
异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果
阻塞/非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
33.实现memcpy
34.内存管理,虚拟内存
内存管理方式主要分为:页式管理、段式管理和段页式管理。
页式管理的基本原理是将各进程的虚拟空间划分为若干个长度相等的页。把内存空间按页的大小划分为片或者页面,然后把页式虚拟地址与内存地址建立一一对应的页表,并用相应的硬件地址转换机构来解决离散地址变换问题。页式管理采用请求调页和预调页技术来实现内外存存储器的统一管理。
优点:没有外碎片,每个内碎片不超过页的大小。
缺点:程序全部装入内存,要求有相应的硬件支持,如地址变换机构缺页中断的产生和选择淘汰页面等都要求有相应的硬件支持。增加了机器成本和系统开销。
段式管理的基本思想是把程序按内容或过程函数关系分成段,每段有自己的名字。一个用户作业或者进程所包含的段对应一个二维线性虚拟空间,也就是一个二维虚拟存储器。段式管理程序以段为单位分配内存,然后通过地址映射机构把段式虚拟地址转换为实际内存物理地址。
优点:可以分别编写和编译,可以针对不同类型的段采取不同的保护,可以按段为单位来进行共享,包括通过动态链接进行代码共享。
缺点:会产生碎片。
段页式管理,系统必须为每个作业或者进程建立一张段表以管理内存分配与释放、缺段处理等。另外由于一个段又被划分为若干个页,每个段必须建立一张页表以把段中的虚页变换为内存中的实际页面。显然与页式管理时相同,页表也要有相应的实现缺页中断处理和页面保护等功能的表项。
段页式管理是段式管理和页式管理相结合而成,具有两者的优点。
由于管理软件的增加,复杂性和开销也增加。另外需要的硬件以及占用的内存也有所增加,使得执行速度下降。
虚拟内存是一种内存管理思想。
35.自旋锁,互斥锁的区别
- 互斥锁:线程会从sleep(加锁)——>running(解锁),过程中有上下文的切换,cpu的抢占,信号的发送等开销;
- 自旋锁:线程一直是running(加锁——>解锁),死循环检测锁的标志位,机制不复杂,主要用于SMP和内核可抢占下,因为在内核不可抢占下,cpu在执行空操作。
- 互斥锁的起始原始开销要高于自旋锁,但是基本是一劳永逸,临界区持锁时间的大小并不会对互斥锁的开销造成影响,而自旋锁是死循环检测,加锁全程消耗cpu,起始开销虽然低于互斥锁,但是随着持锁时间,加锁的开销是线性增长
36.进程退出,线程会怎么样
如果是主线程调用pthread_exit退出,则不会影响其它线程;如果调用return或者是exit函数,则会杀死其它线程。
主线程、子线程与进程的退出问题_qq_34352738的博客-CSDN博客_进程退出时线程退出吗
37.磁盘读写过程
磁盘读写过程_zhudinglym的博客-CSDN博客
38.限流算法
常用4种限流算法介绍及比较_Solin的博客-CSDN博客_限流算法
39.堆和栈的速度比较
1.分配和释放,堆在分配和释放时都要调用函数(MALLOC,FREE),比如分配时会到堆空间去寻找足够大小的空间(因为多次分配释放后会造成空洞),这些都会花费一定的时间,具体可以看看MALLOC和FREE的源代码,他们做了很多额外的工作,而栈却不需要这些。
2.访问时间,访问堆的一个具体单元,需要两次访问内存,第一次得取得指针,第二次才是真正得数据,而栈只需访问一次。另外,堆的内容被操作系统交换到外存的概率比栈大,栈一般是不会被交换出去的。
综上所述,站在操作系统以上的层面来看,栈的效率比堆高,对于应用程序员,这些都是透明的,操作系统做了很多我们看不到的东西。
1、管理方式不同;
2、空间大小不同;
3、能否产生碎片不同;
4、生长方向不同;
5、分配方式不同;
6、分配效率不同;
管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak。
空间大小:一般来讲在 32 位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在VC6下面,默认的栈空间大小是1M(好像是,记不清楚了)。当然,我们可以修改:打开工程,依次操作菜单如下:Project->Setting->Link,在 Category 中选中 Output,然后在 Reserve 中设定堆栈的最大值和 commit。注意:reserve 最小值为 4Byte;commit 是保留在虚拟内存的页文件里面,它设置的较大会使栈开辟较大的值,可能增加内存的开销和启动时间。
碎片问题:对于堆来讲,频繁的 new/delete 势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,在他弹出之前,在他上面的后进的栈内容已经被弹出,详细的可以参考数据结构,这里我们就不再一一讨论了。
生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
分配方式:堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由 malloc 函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是 C/C++ 函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
C++内存分配方式详解——堆、栈、自由存储区、全局/静态存储区和常量存储区 - 盗艹人 - 博客园
40.awk命令
linux awk命令详解 - ggjucheng - 博客园
41.共享内存如何实现;共享内存为什么是IPC中最快的通讯方式
相比较其他的进程通信方式,共享内存确实是最快的,比如说,管道通信,管道通信需要两次数据拷贝的过程.以进程1 和进程2实现进程间通信为例,进程1 和进程2 要想进行进程间通信,首先进程1 需要将数据从用户态空间拷贝到,内核态空间,接着进程2 从内核态空间中将数据拷贝到进程2中,于是进程间通信完成了.,然而共享内存就没有数据的拷贝过程,因此效率最高.
共享内存-------进程间最快的通信方式_zwq68的博客-CSDN博客
45.一个进程启动时的内存管理是怎样的?
46.开机过程
① 开机访问0xFFFF0地址
② 跳转到BIOS ROM的初始化程序
③ 把BIOS ROM中的初始化程序复制到内存中执行
④ 初始化程序 首先初始化硬件,然后在硬盘中找到 引导程序。
⑤ 将引导程序复制到 内存的 0x07c00,并执行
⑥ 引导程序 将硬盘的内容复制到内存中。
⑦ 跳到内存中操作系统的开始地址,
⑧ 开始执行操作系统。

47.ctrl+c,发生了什么
我们平时在程序运行的时候按下ctrl-c、ctrl-z或者kill一个进程的时候其实都等效于向这个进程发送了一个特定信号,当进程捕获到信号后,进程会被中断并立即跳转到信号处理函数。默认情况下一个程序对ctrl-c发出的信号(SIGINT)的处理方式是退出进程,所以当我们按下ctrl-c的时候就可以终止一个进程的运行。
48.零拷贝原理
原来 8 张图,就可以搞懂「零拷贝」了 - 小林coding - 博客园
浅析Linux中的零拷贝技术 - 简书
49.程序用户空间中虚拟内存地址怎么映射到物理内存地址的
程序产生虚拟地址(由段选择符和段内偏移地址组成的地址),CPU要利用其段式内存管理单元,先将为逻辑地址转换成一个线性地址,再利用其页式内存管理单元,转换为最终物理地址。MMU就是内存管理单元。
- 虚拟地址指由程序产生的由段选择符和段内偏移地址组成的地址。
- 逻辑地址指由程序产生的段内偏移。有时候直接把逻辑地址当做虚拟地址。
线性地址指虚拟地址到物理地址变换的中间层,是处理器可寻址的内存空间中的地址。程序代码会产生逻辑地址,也就是段中的偏移地址,加上相应的段基址就成了线性地址。如果开启了分页机制,那么线性地址需要再经过变换,转为为物理地址。如果无分页机制,那么线性地址就是物理地址。
- 物理地址指CPU外部地址总线上寻址物理内存的地址信号,是地址变换的最终结果。
虚拟地址到物理地址的转化是体系结构相关的,一般由分段和分页两种方式。以X86CPU为例,分段和分页都是支持的。内存管理单元负责从虚拟地址到物理地址的转化。逻辑地址是段标识+段内偏移的形式。MMU通过查询段表,可以将逻辑地址转化为线性地址。无分页机制时,线性地址就是物理地址,有分页时,MMU还需要查询页表来将线性地址转化为物理地址:逻辑地址(段表)->线性地址(页表)->物理地址。
映射是一种多对一的关系,即不同的逻辑地址可以映射到同一个线性地址上;不同的线性地址也可以映射到同一个物理地址上。而且,同一个线性地址在换页之后,可能被装载到另一个物理地址上,所以这种多对一的映射关系会随时间发生变化
段表+单层页表
进程的内存先分成多个段,每个段再按照页来分配。地址分三个部分:段号+页号+页内偏移,根据段号去段表里面找对应的页表地址,得到页表的地址后,根据页号找到对应的物理内存的Page Frame地址,最后再结合页内偏移计算得到实际地址,其中段表中的Size是指某一段对应的页表的长度,即物理页的数目。以32位虚拟地址空间,4KB大小的Page为例,前10bit用于段号,中间10位用于页号,后12位用于页内偏移,假设页表的每一行的大小是4个字节,则一个物理Page Frame正好可以容下每个段的页表。
详解内存虚拟地址到物理地址的转换过程以及对应的应用场景 - 知乎
50.io密集型、cpu密集型任务分别用多进程、多线程、多协程?
对于IO密集型任务,由于CPU经常需要等待IO操作完成,因此,在等待过程中,CPU可以去做其他事情,因此采用多线程可以提高程序执行效率,这实质是并发处理。当然,由于多进程可以利用多核CPU真正实现并行处理,所以,采用多进程也可以提高IO密集型任务的执行效率。但是考虑到多线程是共享资源的,因此通信更方便,而多进程之间的资源相互独立,通信不是很方便,因此,综合来看,IO密集型任务,采用python多线程更合适。
对于计算密集型任务,由于python多线程为了实现同步锁安全机制,采用了全局锁机制,导致即使是多核CPU或多个CPU,同一时间,也只有一个线程在执行,因为全局锁只有一个,即在多核CPU或多个CPU情况下,python多线程仍然只能并发处理,而不能并行处理。而因为计算密集型任务,CPU几乎不存在空闲时间,使用python多线程,CPU频繁在各个线程之间切换所需时间反而会大大降低程序执行效率。而采用python多进程,可以实现真正意义上的并行处理,因此,计算密集型任务,采用python多进程更合适。
51.怎么实现一个协程?
52.out of memory,这个和虚拟内存的使用矛盾吗
53.Epoll的ET模式如果没读完/写完怎么办
54.Linux如何查看进程打开文件数量
55.操作系统锁和数据库锁
操作系统:自旋锁(spinlock)和mutex
死锁和活锁:活锁就是不断请求cpu
聊聊常见的锁 · Martian'S Blog
56.活锁
活锁和死锁产生的条件一样,只是表现不同。死锁下线程进入等待状态,而活锁下线程仍然处于运行状态尝试获取锁。活锁下线程仍然消耗CPU,
57.函数调用:腾讯 Linux C/C++ 后台开发实习生技能要求_技术交流_牛客网
58.进程间通信方式底层分别怎么实现
操作系统中锁的原理 - 简书
59.线程之间的栈能否通信,如何通信,数据互通吗?
60.客户端发送一个请求,服务器突然挂掉了,客户端会怎么样,为什么
61.如何不通过发送包里的信息保证服务器知道是哪一个客户端发送的
62.除了互斥锁你还能用什么方法来实现线程同步
63PV操作如何实现的
64.共享内存在哪,有什么用,底层是如何实现的
进程间通信系列(12)共享内存的基本概念_洪流之源-CSDN博客
65.共享内存能放什么样的数据结构,是用什么数据结构实现的
66.共享内存里能放vector吗,为什么
67.float是如何存储的,补码反码相关问题
68.虚拟内存置换的方式,windows用的什么算法
69.如果我要进程共享地址空间,有哪些方式,具体说
70.线程上下文切换原理,切换了什么?
71.io 模型的优劣,为什么用 epoll,逐个分析
72.为什么用红黑树管理定时器,
73.还有什么其他方式?
74.分析各个方法管理定时器的优缺点?
75守护进程(创建过程有两个fork)
指在后台运行的,没有控制终端与之相连的进程。它独立于控制终端,周期性地执行某种任务。Linux的大多数服务器就是用守护进程的方式实现的,如web服务器进程http等
创建守护进程要点:
(1)让程序在后台执行。方法是调用fork()产生一个子进程,然后使父进程退出。
(2)调用setsid()创建一个新对话期。控制终端、登录会话和进程组通常是从父进程继承下来的,守护进程要摆脱它们,不受它们的影响,方法是调用setsid()使进程成为一个会话组长。setsid()调用成功后,进程成为新的会话组长和进程组长,并与原来的登录会话、进程组和控制终端脱离。
(3)禁止进程重新打开控制终端。经过以上步骤,进程已经成为一个无终端的会话组长,但是它可以重新申请打开一个终端。为了避免这种情况发生,可以通过使进程不再是会话组长来实现。再一次通过fork()创建新的子进程,使调用fork的进程退出。
(4)关闭不再需要的文件描述符。子进程从父进程继承打开的文件描述符。如不关闭,将会浪费系统资源,造成进程所在的文件系统无法卸下以及引起无法预料的错误。首先获得最高文件描述符值,然后用一个循环程序,关闭0到最高文件描述符值的所有文件描述符。
(5)将当前目录更改为根目录。
(6)子进程从父进程继承的文件创建屏蔽字可能会拒绝某些许可权。为防止这一点,使用unmask(0)将屏蔽字清零。
(7)处理SIGCHLD信号。对于服务器进程,在请求到来时往往生成子进程处理请求。如果子进程等待父进程捕获状态,则子进程将成为僵尸进程(zombie),从而占用系统资源。如果父进程等待子进程结束,将增加父进程的负担,影响服务器进程的并发性能。在Linux下可以简单地将SIGCHLD信号的操作设为SIG_IGN。这样,子进程结束时不会产生僵尸进程。
https://segmentfault.com/a/1190000022770900
76.多进程架构与多线程架构有什么区别
Oracle的Unix/Linux版本采用多进程架构,不同的功能模块由不同的进程负责,Windows版本采用单进程多线程架构,所有的模块所在线程处在同一个进程当中。
我们来看一下区别:
1.进程管理。Oracle某个模块挂起了,没有响应,万般无奈你要重起这个模块,Unix平台只要重起这个模块所在的那个进程就可以了,其它进程保持运行,而Windows平台只有一个进程,只能影响所有模块,重启过程中所有模块都不能提供服务。
2.内存空间。每个进程拥有自己的地址空间,如果只有一个进程,所有模块共享/约束在同一空间,如果采用多进程,所有进程地址空间独立,软件申请/管理更多内存的可能和能力变大了。
3.线程间通信。因为单进程共享地址空间,进程内线程通信效率很高,不同进程的线程之间通信需要某种IPC手段,效率相比降低。其实Linux平台没有传统意义的“线程”,所有都是进程,我们看到的进程是一个进程组,里面的“线程”就是组成这个进程组的进程。
4.资源管理。单进程中其中一个线程操作文件句柄阻塞了,会影响到其它线程对这个句柄的操作,多进程无此问题。一个进程同时打开的句柄是受限制的,多进程意味着可使用更多资源。
5.运行调度。一个线程Hang了就是这个进程Hang了,一个线程Crash了就是这个进程Crash了,所以多线程要格外小心了,多进程分摊风险更安全。
6.软件开发管理。多进程可以分别交给不同团队开发,多线程分别交给不同团队开发很困难,编译要同步,Debug要同步,进程Crash了是哪个团队的责任往往要花半天时间。等等。
Oracle的这种思维主要是由资源使用决定的,单进程无法满足内存,句柄的使用需求时,只能采用多进程。而Windows微内核结构动态创建进程做得不够好,线程是更好选择,Linux宏内核结构并且线程本来就是通过进程组的方式实现的。
结论是首先由项目规模决定,这是刚需,再者由运行的系统平台决定,非刚需。
77.原子操作如何实现
处理器使用基于对缓存加锁或总线加锁的方式来实现多处理器之间的原子操作。
1.所谓总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。
2.所谓“缓存锁定”是指内存区域如果被缓存在处理器的缓存行中,并且在Lock操作期间被锁定,那么当它执行锁操作回写到内存时,处理器不在总线上声言LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改由两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行的数据时,会使缓存行无效
78.缺页中断
缺页中断(英语:Page fault,又名硬错误、硬中断、分页错误、寻页缺失、缺页中断、页故障等)指的是当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,由中央处理器的内存管理单元所发出的中断。
通常情况下,用于处理此中断的程序是操作系统的一部分。如果操作系统判断此次访问是有效的,那么操作系统会尝试将相关的分页从硬盘上的虚拟内存文件中调入内存。而如果访问是不被允许的,那么操作系统通常会结束相关的进程。
要通过页面置换算法进行切换
深入理解【缺页中断】及FIFO、LRU、OPT这三种置换算法 - 云+社区 - 腾讯云
计算机网络
1.如果查看tcp连接的网络状态
netstat命令
netstat用法详解 - blogcccc - 博客园
2.有没有使用过网络编程
3.简述一下http的过程
1) 在客户端浏览器中输入网址URL。
2) 发送到DNS(域名服务器)获得域名对应的WEB服务器的IP地址。(DNS协议)
3) 客户端浏览器与WEB服务器建立TCP(传输控制协议)连接。(TCP、IP协议、OSPF协议、ARP协议)
4) 客户端浏览器向对应IP地址的WEB服务器发送相应的HTTP或HTTPS请求。(HTTP协议)
5) WEB服务器响应请求,返回指定的URL数据或错误信息;如果设定重定向,则重定向到新的URL地址。
6) 客户端浏览器下载数据,解析HTML源文件,解析的过程中实现对页面的排版,解析完成后,在浏览器中显示基础的页面。
7) 分析页面中的超链接,显示在当前页面,重复以上过程直至没有超链接需要发送,完成页面的全部显示。
输入网址到网页显示的过程_u014527697的博客-CSDN博客
4.http的应答码有什么
200(请求被成功处理)、201、301(永久性重定向)、302(临时性重定向)、304、400(由于语法格式有误,服务器无法理解此请求。不作修改,客户程序就无法重复此请求。)、
401(未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。)、403(系统中某些页面只有在某些权限下才能访问,
当用户去访问了一个本身没有访问权限的url,回报403错误。)、404(一般是自己输入了一个url,这个url并不合法。
404 找不到,Web 服务器找不到您所请求的文件或脚本。
请检查URL 以确保路径正确。)、405、500(服务器错误)、501(501 未实现,Web 服务器不支持实现此请求所需的功能。请检查URL 中的错误)、502、503
详细介绍:浅谈之-http的状态码以及使用场景 | Zach Ke's Notes
5.网络:三次握手四次挥手的过程,为什么要三次握手?TCP与UDP的区别?TCP怎么保证有序?


关于三次握手和四次挥手,面试官想听到怎样的回答? - 知乎
TCP的三次握手与四次挥手理解及面试题(很全面) - 李卓航 - 博客园
6.http+https
端口 :HTTP的URL由“http://”起始且默认使用端口80,而HTTPS的URL由“https://”起始且默认使用端口443。
安全性和资源消耗:HTTP协议运行在TCP之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS是运行在SSL之上的HTTP协议,SSL运行在TCP之上。所有传输的内 容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS高,但是 HTTPS 比HTTP耗费更多服务器资源。
7.浏览器呈现一个页面经过了哪几步(DOM树,layoutobject树,browser进程绘制)
8.DNS解析,递归与迭代的区别
1)递归解析
当局部DNS服务器自己不能回答客户机的DNS查询时,它就需要向其他DNS服务器进行查询。此时有两种方式,局部DNS服务器自己负责向其他DNS服务器进行查询,一般是先向该域名的根域服务器查询,再由根域名服务器一级级向下查询。最后得到的查询结果返回给局部DNS服务器,再由局部DNS服务器返回给客户端。
2)迭代解析
当局部DNS服务器自己不能回答客户机的DNS查询时,也可以通过迭代查询的方式进行解析,如图所示。局部DNS服务器不是自己向其他DNS服务器进行查询,而是把能解析该域名的其他DNS服务器的IP地址返回给客户端DNS程序,客户端DNS程序再继续向这些DNS服务器进行查询,直到得到查询结果为止。也就是说,迭代解析只是帮你找到相关的服务器而已,而不会帮你去查。比如说:baidu.com的服务器ip地址在192.168.4.5这里,你自己去查吧,本人比较忙,只能帮你到这里了。
9.为什么要time_wait
- 防止具有相同「四元组」的「旧」数据包被收到;
- 保证「被动关闭连接」的一方能被正确的关闭,即保证最后的 ACK 能让被动关闭方接收,从而帮助其正常关闭;
- 关于三次握手和四次挥手,面试官想听到怎样的回答? - 知乎
10.TCP协议切片
11.流量控制解决了什么问题,怎么实现,接收窗口为0了怎么办
12.session,cookie,token
http是无状态的,但是有的时候服务需要识别客户端的身份,这个时候cookie出现了;浏览器在访问服务后,服务器会生成cookie或者session,浏览器均以cookie的形式存储下来(session一般是把sessionId当成cookie存在cookie中,具体的数据是保存在服务器端的,浏览器请求时会带上sessionId,服务器通过sessionId查询数据),session的默认有效期是浏览器的会话期以及服务设置的session有效期的最短时间;大部分session保存在内存中,cookie保存在用户本地电脑中;
【计算机网络】Web 访问中的 cookie, seesion, token_Ulrich蚊子Blog-CSDN博客
13.csrf攻击,怎么防御
14.TCP粘包;tcp粘包处理
掘金
(经典)tcp粘包分析 - coderi++ - 博客园
面试题:聊聊TCP的粘包、拆包以及解决方案 - 知乎
为什么 TCP 协议有粘包问题 - 面向信仰编程
15.野指针,怎么避免野指针?
16.http各个版本
HTTP协议几个版本的理解 - Luck-pig - 博客园
17.http报文格式
http报文详解 - 江花花 - 博客园
18.tcp和udp的区别
1)基于连接与无连接;TCP建立需要三次握手,UDP不需要
2)对系统资源的要求(TCP较多,UDP少);TCP首部最少需要20字节,UDP只要8字节
3)UDP程序结构较简单;
4)流模式与数据报模式 ;
5)TCP保证数据正确性,UDP可能丢包;TCP是可靠的,有拥塞控制、重传机制,保证正确传输;UDP是尽最大努力交付,不保证可靠交付。
6)TCP保证数据顺序,UDP不保证。TCP每个包有seq号保证有序,udp没有
19.DNS劫持:在DNS服务器中,将www..com的域名对应的IP地址进行了变化。你解析出来的 域名对应的IP,在劫持前后不一样。
HTTP劫持:你DNS解析的域名的IP地址不变。在和网站交互过程中的劫持了你的请求。在网站发给你信息前就给你返回了请求。
20.https的传输过程:
1)客户端想服务器发起HTTPS的请求,连接到服务器的443端口;
2)服务器将非对称加密的公钥传递给客户端,以证书的形式回传到客户端
3)服务器接受到该公钥进行验证,就是验证2中证书,如果有问题,则HTTPS请求无法继续;如果没有问题,则上述公钥是合格的。(第一次HTTP请求)客户端这个时候随机生成一个私钥,成为client key,客户端私钥,用于对称加密数据的。使用前面的公钥对client key进行非对称加密;
4)进行二次HTTP请求,将加密之后的client key传递给服务器;
5)服务器使用私钥进行解密,得到client key,使用client key对数据进行对称加密
6)将对称加密的数据传递给客户端,客户端使用非对称解密,得到服务器发送的数据,完成第二次HTTP请求。
HTTPS请求的整个过程的详细分析_研究生生活、学习记录-CSDN博客_https请求
21.get和post的区别
get和post是http协议中两种发送请求的方法,底层都是TCP/IP,两者都是TCP链接,完成的工作是一样的。因为受到浏览器和http协议的限制,两者在应用过程中体现出一些不同
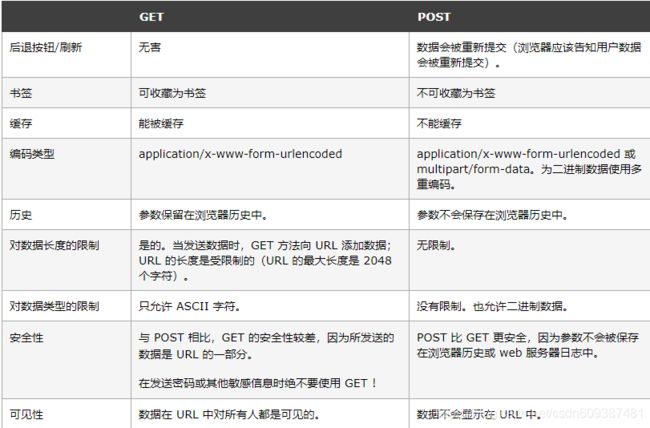
根据HTTP规范,GET用于信息获取,而且应该是安全的和幂等的;根据HTTP规范,POST表示可能修改变服务器上的资源的请求。
URL不存在参数上限的问题,HTTP协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。这个受浏览器影响,firefox只发送一次,
22.DNS的过程
1) 浏览器缓存
当用户通过浏览器访问某域名时,浏览器首先会在自己的缓存中查找是否有该域名对应的IP地址(若曾经访问过该域名且没有清空缓存便存在);
2) 系统缓存
当浏览器缓存中无域名对应IP则会自动检查用户计算机系统Hosts文件DNS缓存是否有该域名对应IP;
3) 路由器缓存
当浏览器及系统缓存中均无域名对应IP则进入路由器缓存中检查,以上三步均为客服端的DNS缓存;
4) ISP(互联网服务提供商)DNS缓存
当在用户客服端查找不到域名对应IP地址,则将进入ISP DNS缓存中进行查询。比如你用的是电信的网络,则会进入电信的DNS缓存服务器中进行查找;
5) 根域名服务器
当以上均未完成,则进入根服务器进行查询。全球仅有13台根域名服务器,1个主根域名服务器,其余12为辅根域名服务器。根域名收到请求后会查看区域文件记录,若无则将其管辖范围内顶级域名(如.com)服务器IP告诉本地DNS服务器;
6) 顶级域名服务器
顶级域名服务器收到请求后查看区域文件记录,若无则将其管辖范围内主域名服务器的IP地址告诉本地DNS服务器;
7) 主域名服务器
主域名服务器接受到请求后查询自己的缓存,如果没有则进入下一级域名服务器进行查找,并重复该步骤直至找到正确纪录;
8)保存结果至缓存
本地域名服务器把返回的结果保存到缓存,以备下一次使用,同时将该结果反馈给客户端,客户端通过这个IP地址与web服务器建立链接。
DNS原理及其解析过程 - 极客小乌龟 - 博客园
22.tcp:
Tcp报文

首部20字节固定部分+可选部分
序号:本段数据在总报文中的位移
数据偏移:报文段正式数据开始的位置
窗口:两个字节,接收缓存区的大小,发送方收到后也将发送缓存区大小为等大。两边都要设置接送和发送缓存区
校验和:首部和正文一起
udp头
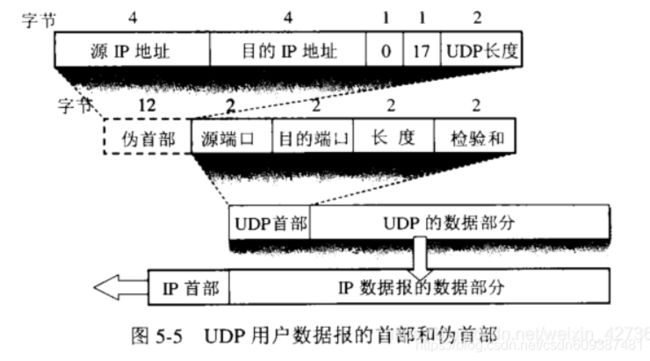
(1)源端口 源端口号。在需要对方回信时选用。不需要时可全用0。
(2)目的端口 目的端口号。这在终点交付报文时必须要使用到。
(3)长度 UDP用户数据报的长度,其最小值是8(仅有首部)。
(4)校验和 校验UDP用户数据报在传输中是否有错,有错就丢弃。
流量控制
解决发送端和接收端处理能力不一致的问题,通过修改缓存区大小,在发送确认包里面
23.udp怎样实现可靠的tcp连接
UDP实现TCP可靠传输_大野狼来啦-CSDN博客_udp实现tcp
24.tcp头部校验码怎么计算
当发送IP包时,需要计算IP报头的校验和:
1、 把校验和字段置为0;
2、 对IP头部中的每16bit进行二进制求和;
3、 如果和的高16bit不为0,则将和的高16bit和低16bit反复相加,直到和的高16bit为0,从而获得一个16bit的值;
4、 将该16bit的值取反,存入校验和字段。
◆当接收IP包时,需要对报头进行确认,检查IP头是否有误,算法同上2、3步,然后判断取反 的结果是否为0,是则正确,否则有错。
TCP头校验和计算算法详解 - RodYang - 博客园
25.tcp、udp、ip等分别属于哪一层

26.ping的底层实现
主机 A ping 主机 B
ping 命令执行的时候,源主机首先会构建一个 ICMP 回送请求消息数据包。
ICMP 数据包内包含多个字段,最重要的是两个:
- 第一个是类型,对于回送请求消息而言该字段为
8;- 另外一个是序号,主要用于区分连续 ping 的时候发出的多个数据包。
每发出一个请求数据包,序号会自动加
1。为了能够计算往返时间RTT,它会在报文的数据部分插入发送时间。主机
B收到这个数据帧后,先检查它的目的 MAC 地址,并和本机的 MAC 地址对比,如符合,则接收,否则就丢弃。接收后检查该数据帧,将 IP 数据包从帧中提取出来,交给本机的 IP 层。同样,IP 层检查后,将有用的信息提取后交给 ICMP 协议。
主机
B会构建一个 ICMP 回送响应消息数据包,回送响应数据包的类型字段为0,序号为接收到的请求数据包中的序号,然后再发送出去给主机 A。在规定的时候间内,源主机如果没有接到 ICMP 的应答包,则说明目标主机不可达;如果接收到了 ICMP 回送响应消息,则说明目标主机可达。
此时,源主机会检查,用当前时刻减去该数据包最初从源主机上发出的时刻,就是 ICMP 数据包的时间延迟。
20 张图解: ping 的工作原理 - 小林coding - 博客园
27.Tcp拥塞控制原理
28.获取网站ip的方法
ping、nslookup
如何获取域名(网址)对应的IP地址_向晚流年-CSDN博客_查看域名对应的ip地址
29.udp不可靠传输,那qq怎么办?
30.socket编程
31.路由器和交换机的区别
- 区别一
- 路由器可以为局域网自动分配IP和虚拟拨号
- 交换机只是用来分配网络数据的
- 区别二
- 路由器在网络层,根据IP地址寻址,路由器还可以处理“TCP/IP”协议,交换机不行
- 交换机在数据链路层,根据MAC地址寻址
- 区别三
- 路由器可以把一个IP分给多个主机使用,对外IP相同
- 交换机可以把很多主机连接起来,对外的IP不同
- 区别四
- 路由器可以提供防火墙,交换机不提供这个功能
- 区别五
- 交换机是做扩大局域网接入点的,可以让局域网连进更多的电脑
- 路由器是用来做网间连接,也就是用来连接不同的网络的
32.路由器怎么维护路由表
33.路由算法了解吗
有分静态路由和动态路由。静态路由自己手动配置,动态路由则用算法实现。动态路由包括;距离矢量路由算法(RIP、BGP)、链路状态路由算法(OSPF)。
网络中的「动态路由算法」,你了解吗? - 不止思考 - 博客园
34.讲一讲进程池和线程池,如何实现服务器的多线程
35.共享内存导致的问题
36.怎么查看进程使用情况--top命令
37.cpu占用率高怎么排查
38.time_wait以及如何修复
39.HTTP的长连接和短连接
40.操作系统的内存管理:段页式管理,页表;段页式管理CPU每次从内存地址读取一次数据要访问几次
41.小端字节序和大端字节序,这个对什么产生影响,做什么事情会出现问题
【实例讲解】大端字节序和小端字节序区分方法_Scofield971031的博客-CSDN博客
谈一谈字节序的问题 - 知乎
42.七层网络及其作用
| OSI七层模型 | 功能 | |
|---|---|---|
| 应用层 | 应用层是网络体系中最高的一层,也是唯一面向用户的一层,也可视为为用户提供常用的应用程序,每个网络应用都对应着不同的协议 | |
| 表示层 | 主要负责数据格式的转换,确保一个系统的应用层发送的消息可以被另一个系统的应用层读取,编码转换,数据解析,管理数据的解密和加密,同时也对应用层的协议进行翻译 | |
| 会话层 | 负责网络中两节点的建立,在数据传输中维护计算机网络中两台计算机之间的通信连接,并决定何时终止通信 | |
| 传输层 | 是整个网络关键的部分,是实现两个用户进程间端到端的可靠通信,处理数据包的错误等传输问题。是向下通信服务最高层,向上用户功能最底层。即向网络层提供服务,向会话层提供独立于网络层的传送服务和可靠的透明数据传输。 | |
| 网络层 | 进行逻辑地址寻址,实现不同网络之间的路径选择,IP就在网络层 | |
| 数据链路层 | 物理地址(MAC地址),网络设备的唯一身份标识。建立逻辑连接、进行硬件地址寻址,相邻的两个设备间的互相通信 | |
| 物理层 | 七层模型中的最底层,主要是物理介质传输媒介(网线或者是无线),在不同设备中传输比特,将0/1信号与电信号或者光信号互相转化 |
43.计算机网络编程,各个api参数等
网络编程:Socket API - 知乎
socket网络编程之一(TCP套接字API) - 简书

44.Tcp time_wait和close_wait
45.线程是怎样保证安全性的,线程怎么知道临界区是锁住的
46.HTTP请求响应报文,HTTP2.0的特点
HTTP/2 中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装。
(1)多路复用
(2)服务器推送
(3)头部压缩
(4)二进制分帧
一文读懂 HTTP/2 特性 - 知乎
HTTP1.0
- 无状态、无连接
HTTP1.1
- 持久连接
- 请求管道化
- 增加缓存处理(新的字段如
cache-control)- 增加
Host字段、支持断点传输等HTTP2.0
- 二进制分帧
- 多路复用(或连接共享)
- 头部压缩
- 服务器推送
47.http长连接和短连接的区别
48.http数字证书、数字签名、Ca证书
49.HTTP CSRF攻击
CSRF 攻击是什么?如何防范? - 简书

50.HTTPS建立连接的过程
HTTPS建立连接详细过程 - 知乎
51.http 报文怎么解析
52.ARP、linux 下终端输入 ping IP 命令后发生了什么,详细说一下:ICMP , 路由寻址, ARP
ARP:静态ARP、动态ARP(ARP、RARP)ARP把逻辑(IP)地址映射为物理地址。RARP把物理地址映射为逻辑(IP)地址
[图解]ARP协议(一) - csguo - 博客园
ARP协议详解_沉默的鹏先生-CSDN博客_arp协议
53.TCP keep-alive和HTTP keep-alive
HTTP协议(四层)的Keep-Alive意图在于连接复用,希望可以短时间内在同一个连接上进行多次请求/响应。举个例子,你搞了一个好项目,想让马云爸爸投资,马爸爸说,"我很忙,最多给你3分钟”,你需要在这三分钟内把所有的事情都说完。核心在于:时间要短,速度要快。
TCP协议(七层)的KeepAlive机制意图在于保活、心跳,检测连接错误。当一个TCP连接两端长时间没有数据传输时(通常默认配置是2小时),发送keepalive探针,探测链接是否存活。例如,我和厮大聊天,开了语音,之后我们各自做自己的事,一边聊天,有一段时间双方都没有讲话,然后一方开口说话,首先问一句,"老哥,你还在吗?”,巴拉巴拉..。又过了一会,再问,"老哥,你还在吗?”。核心在于:虽然频率低,但是持久。
tcp与http keep-alive机制的区别(这个文章讲的太好了,我喜欢)_咖啡的博客-CSDN博客
54.问到qq聊天为啥要udp而非tcp(多播)
55.socket底层怎么启动
56.心跳包
57.reactor和proactor
Reactor和Proactor是两种io多路复用的模式
Reactor采用的是同步io,proactor采用的是异步io。
Reactor模式,本质就是当IO事件(如读写事件)触发时,通知我们主动去读取,也就是要我们主动将socket接收缓存中的数据读到应用进程内存中。
Proactor模式,我们需要指定一个应用进程内的buffer(内存地址),交给系统,当有数据包到达时,则写入到这个buffer并通知我们收了多少个字节。
Reactor 工作流程:
主线程向epoll内核事件表中注册socket上的读就绪事件
主线程调用epoll_wait等待socket上有数据可读
当socket有数据可读,epoll_wait通知主进程,主线程将socket可读事件放入请求队列
唤醒请求队列上的某个工作线程,开始从socket读取数据,处理客户需求,并向epoll内核事件表中注册写就绪事件
主线程调用epoll_wait等待主线程可写
socket可写时,epollwait通知主线程,主线程将socket放入请求队列
唤醒某个工作进程 向socket上写入服务器处理客户请求的结果
优点
1)响应快,不必为单个同步时间所阻塞,虽然Reactor本身依然是同步的;
2)编程相对简单,可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程/进程的切换开销;
3)可扩展性,可以方便的通过增加Reactor实例个数来充分利用CPU资源;
4)可复用性,reactor框架本身与具体事件处理逻辑无关,具有很高的复用性;
58.大文件传输有没有考虑到大文件分成小的文件进行传输——参看HTTP2.0的二进制分帧;
数据库
1.数据库:SQL语句的基本格式?用过哪些数据库?
2.redis数据类型;布隆过滤器原理作用;redis线程模型,为什么使用单线程?
3.互斥锁,自旋锁,读写锁的区别(详细聊,跟内核态连起来聊)
4.数据库的ACID分别是什么?隔离级别有哪些?不同的隔离级别分别解决了哪些并发问题?幻读和不可重复读有什么区别,为什么会有这种区别?如何在可重复读级别解决幻读?mvcc是怎么解决幻读问题(RW时间戳)?基于RW时间戳解决幻读的具体策略大概是什么?
5.mysql宕机恢复
6.join、inner join、left join的区别
-left join(左联接) 返回包括 左表中的所有记录和右表中联结字段相等的记录
-right join(右联接) 返回包括 右表中的所有记录和左表中联结字段相等的记录
-inner join(等值连接) 只返回两个表中联结字段相等的行
7.mysql表很大怎么办
8.索引优化
9.数据库范式包括什么?为什么范式要这么设计?冗余字段怎么考虑?
10.mysql索引底层?
可以用数组,B+树实现,mysql用的是b+树
11.redis源码中,epoll的工作流程
12.redis缓存淘汰策略
Redis缓存淘汰策略 - 知乎
13.联合索引的机制
14.覆盖索引
覆盖索引(covering index)指一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取。也可以称之为实现了索引覆盖。
如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引。https://www.jianshu.com/p/77eaad62f974
15.explain下的参数
Mysql(一)--EXPLAIN的参数解析及简单应用_至尊宝-CSDN博客_explain参数
16.sql 建表、插入数据命令
17.sql查找重复的电子邮箱 select Email from Person group by Email having count(Email)>1;
18.sql 命令
19.数据库索引失效情况
20.大表分表情况,怎么设计;(5)怎么加快搜索;
21.索引失效可能会导致什么
22.Redis的缓存雪崩、缓存击穿、缓存穿透与缓存预热、缓存降级
Redis的缓存雪崩、缓存击穿、缓存穿透与缓存预热、缓存降级_张维鹏的博客-CSDN博客
23.布隆过滤器
24.Redis为何针对同一类型实现不同的底层结构?
25.Redis如何实现分布式锁?
26.Redis跳跃表了解吗?
27.redis 分布式的实现
28.redis 的框架
C++
1.C++:构造函数与拷贝构造函数的区别?
拷贝构造函数:
定义:拷贝构造函数是一种特殊的构造函数,函数的名称必须和类名称一致,它必须的一个参数是本类型的一个引用变量。
作用:用来复制对象,使用这个对象的实例来初始化这个对象的一个新的实例。
调用时机:
当函数的参数为类的对象时
函数的返回值是类的对象
对象需要通过另外一个对象进行初始化。
拷贝构造函数默认为浅拷贝。浅拷贝是指当出现类的等号赋值时,它能够完成静态成员的值复制。当数据成员中没有指针时,浅拷贝是可行的。但当数据成员中有指针时,如果采用简单的浅拷贝,则两个类中的指针将指向同一个地址,对象即将结束时,两个类会分别调用析构函数,导致指针悬挂现象。所以这时必须采用深拷贝,在堆内存中另外申请空间来储存数据,防止指针悬挂现象。
拷贝构造函数必须是引用传递,不能是值传递,这是为了防止递归引用。
构造函数:
1.定义:在类对象被创建时调用的,用来初始化成员的函数。
2.作用:该类对象被创建时,编译系统对象分配内存空间,并自动调用该构造函数->由构造函数完成成员的初始化工作
转换构造函数:
1.定义:转换构造函数用于将其他类型的变量,隐式转换为本类对象。
浅谈C++中的几种构造函数_林多-CSDN博客_c++ 构造函数
堆与栈的区别?
栈内存:由程序自动向操作系统申请分配以及回收,速度快,使用方便,但程序员无法控制。若分配失败,则提示栈溢出错误。注意,const局部变量也储存在栈区内,栈区向地址减小的方向增长
堆内存:程序员向操作系统申请一块内存,当系统收到程序的申请时,会遍历一个记录空闲内存地址的链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。分配的速度较慢,地址不连续,容易碎片化。此外,由程序员申请,同时也必须由程序员负责销毁,否则则导致内存泄露。
基类的析构函数要定义成虚函数嘛?为什么?
每个析构函数只会清理自己的成员(成员函数前没有virtual)。
可能是基类的指针指向派生类的对象,当析构一个指向派生类的成员的基类指针,这时程序不知道这么办,可能会造成内存的泄露,因此此时基类的析构函数要定义为虚函数;
基类指针可以指向派生类的对象(多态),如果删除该指针delete[]p,就会调用该指针指向的派生类的析构函数,而派生类的对象又会自动调基类的成员函数,这样就会把派生类的对象释放,如果基类的析构函数没有定义成虚函数,则编译器实现的静态绑定,在删除基类的指针,只会释放基类的析构函数而不会释放派生类的成员函数,此时会导致释放内存不完全,就会导致内存泄露的问题。
指针和引用的区别?
指针:对于一个类型T,T*就是指向T的指针类型,也即一个T*类型的变量能够保存一个T对象的地址,而类型T是可以加一些限定词的,如const、volatile等等。
引用:是一个对象的别名,主要用于函数参数和返回值类型,符号X&表示X类型的引用。
区别:
(1)引用不可以为空,但指针可以为空。定义一个引用的时候,必须初始化;指针可以是空指针。
(2)引用不可以改变指向;但是指针可以改变指向,而指向其它对象。
(3)前面加const:
常量指针:指向常量的指针,在指针定义语句的类型前加const,表示指向的对象是常量。定义指向常量的指针只限制指针的间接访问操作,而不能规定指针指向的值本身的操作规定性。
常量引用:指向常量的引用,在引用定义语句的类型前加const,表示指向的对象是常量。也跟指针一样不能利用引用对指向的变量进行重新赋值操作。
后面加const:
在指针定义语句的指针名前加const,表示指针本身是常量。在定义指针常量时必须初始化!而这是引用天生具来的属性,不用再引用指针定义语句的引用名前加const。
有一个规则可以很好的区分const是修饰指针,还是修饰指针指向的数据——画一条垂直穿过指针声明的星号(*),如果const出现在线的左边,指针指向的数据为常量;如果const出现在右边,指针本身为常量。而引用本身与天俱来就是常量,即不可以改变指向。
(4) “sizeof 引用”得到的是所指向的变量(对象)的大小,而“sizeof 指针”得到的是指针本身的大小;
(5) 指针和引用的自增(++)运算意义不一样;
(6) 引用是类型安全的,而指针不是 (引用比指针多了类型检查
https://blog.csdn.net/qq_39539470/article/details/81273179
new和delete,malloc和free的异同处;
1、malloc与free是C++/C语言的标准库函数,new/delete是C++的运算符。它们都可用于申请动态内存和释放内存。
2、new 不止是分配内存,而且会调用类的构造函数,同理delete会调用类的析构函数,而malloc则只分配内存,不会进行初始化类成员的工作,同样free也不会调用析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。
3、内存泄漏对于malloc或者new都可以检查出来的,区别在于new可以指明是哪个文件的哪一行,而malloc没有这些信息。
4、new的效率malloc稍微低一些,new可以认为是malloc加构造函数的执行。new出来的指针是直接带类型信息的。 而malloc返回的都是void指针。
5、malloc不会抛异常,而new会(bad_alloc);无法重定义malloc失败时的默认行为(返回NULL),但是我们可以重定义new失败时默认行为,比如不让其抛出异常。
友元函数
c++利用friend修饰符,可以让一些你设定的函数能够对这些保护数据进行操作,避免把类成员全部设置成public,最大限度的保护数据成员的安全。一个函数可以是多个类的友元函数,只需要在各个类中分别声明。
优点:能够提高效率,表达简单、清晰
缺点:友元函数破环了封装机制,尽量使用成员函数,除非不得已的情况下才使用友元函数
常用场景:1)运算符重载的某些场合需要使用友元。2)两个类要共享数据的时候
友元类 :友元类的所有成员函数都是另一个类的友元函数,都可以访问另一个类中的隐藏信息(包括私有成员和保护成员)
C++ 友元函数 - balingybj - 博客园
2.C++多态的实现
为每个类对象添加一个隐藏成员,隐藏成员中保存了一个指向函数地址数组的指针,称为虚表指针(vptr),这种数组成为虚函数表(virtual function table, vtbl),即,每个类使用一个虚函数表,每个类对象用一个虚表指针。
虚函数表属于类,类的所有对象共享这个类的虚函数表。
虚函数表由编译器在编译时生成,保存在.rdata只读数据段。
虚函数中的默认参数问题:
默认参数是静态绑定,多态是动态绑定,函数调用时要将参数压入堆栈,但是动态调用的情况下编译器时期是不知道调用哪一个函数,压入哪一个参数。所以默认参数根据指针的类型来确定。
https://www.cnblogs.com/zkfopen/p/11061414.html
C++ 虚函数表 存在哪_fw72fw72的博客-CSDN博客_虚函数表存在哪里
C++ 一篇搞懂多态的实现原理 - 知乎
3.虚函数实现原理
4.虚表存在哪里
- 虚函数表属于类,类的所有对象共享这个类的虚函数表。
- 虚函数表由编译器在编译时生成,保存在.rdata只读数据段。
实例说明代码段(.text)、数据段(.data)、bss段、只读数据段(.rodata)、堆栈的划分依据_喵小林菌的博客-CSDN博客_只读数据段
5.C++内存分区;如果是未初始化的放在哪里
在C++中,内存分成5个区,他们分别是堆、栈、自由存储区、全局/静态存储区和常量存储区。
栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除变量的存储区。里面的变量通常是局部变量、函数参数等。
堆,就是那些由malloc分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个malloc就要对应一个free。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
自由存储区,就是那些由new等分配的内存块,他和堆是十分相似的,不过它是用delete来结束自己的生命的。
全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分了,他们共同占用同一块内存区。
常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改
自由存储区和堆的区别:
堆是操作系统维护的一块内存,而自由存储是C++中通过new与delete动态分配和释放对象的抽象概念。堆与自由存储区并不等价。
从技术上来说,堆(heap)是C语言和操作系统的术语。堆是操作系统所维护的一块特殊内存,它提供了动态分配的功能,当运行程序调用malloc()时就会从中分配,稍后调用free可把内存交还。而自由存储是C++中通过new和delete动态分配和释放对象的抽象概念,通过new来申请的内存区域可称为自由存储区。基本上,所有的C++编译器默认使用堆来实现自由存储,也即是缺省的全局运算符new和delete也许会按照malloc和free的方式来被实现,这时藉由new运算符分配的对象,说它在堆上也对,说它在自由存储区上也正确。但程序员也可以通过重载操作符,改用其他内存来实现自由存储,例如全局变量做的对象池,这时自由存储区就区别于堆了。
6.为什么要内存对齐,内存对齐的规则
1、 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2、 性能原因:经过内存对齐后,CPU的内存访问速度大大提升。
规则:
struct/class/union内存对齐原则有四个:
1).数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员有子成员,比如说是数组,结构体等)的整数倍开始(比如int在32位机为4字节, 则要从4的整数倍地址开始存储),基本类型不包括struct/class/uinon。
2).结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部"最宽基本类型成员"的整数倍地址开始存储.(struct a里存有struct b,b里有char,int ,double等元素,那b应该从8的整数倍开始存储.)。
3).收尾工作:结构体的总大小,也就是sizeof的结果,.必须是其内部最大成员的"最宽基本类型成员"的整数倍.不足的要补齐.(基本类型不包括struct/class/uinon)。
4).sizeof(union),以结构里面size最大元素为union的size,因为在某一时刻,union只有一个成员真正存储于该地址。
C/C++ 内存对齐原则及作用_chy19911123的专栏-CSDN博客_c++ 内存对齐
7.C++的所有智能指针
shared_ptr:允许多个指针指向同一对象;
使用make_shared分配内存并进行初始化,每个shared_ptr内部都有一个计数器,即引用计数;以下情况将会计数器递增:用一个shared_ptr初始化另一个shared_ptr、将shared_ptr当作参数传给函数、作为函数的返回值
一旦shared_ptr计数器变为0,它会自动释放自己管理的对象
shared_ptr对象可以使用new的直接初始化形式进行初始化,即不用等号,直接括号。
一个返回shared_ptr的函数不能再其返回语句中隐式转换一个普通指针,一定要显式转换。
不要使用shared_ptr的get函数返回的指针来初始化另一个智能指针或者为智能指针赋值,这样会有两个计数器
unique_ptr:独占所指的对象
unique_ptr必须使用直接初始化的方式进行初始化,或者调用release或者reset转移指针所有权
有个例外,可以拷贝或赋值一个 将要被销毁的unique_ptr,比如当作函数返回
weak_ptr:弱引用,指向shared_ptr所管理的对象
将一个weak_ptr绑定到一个shared_ptr不会改变shared_ptr的引用计数
创建weak_ptr必须要用一个shared_ptr进行初始化;用于weak_ptr指向的对象可能不存在了,所以不能使用weak_ptr直接访问对象,要用lock(),此函数检查shared_ptr是否存在,是则返回本身,否则返回空的shared_ptr
C++之动态内存以及智能指针_有梦想的小新人的博客-CSDN博客_智能指针底层实现
8.lambda表达式,它应用表达式外变量的方式和区别;lambda表达式底层实现是什么?sizeof(lambda表达式)的结果是多少?
(1)lambda表达式可以理解为一个匿名的内联函数。和函数一样,lambda表达式具有一个返回类型、一个参数列表和一个函数体。与函数不一样的是lambda必须使用尾置返回类型。一个lambda表达式表示一个可调用的代码单元。
语法:[capture list] (parameter list) -> return type {function body}
capture list:表示捕获列表,是一个lambda所在函数中定义的局部变量列表
parameter list:表示参数列表
return type:返回类型
function body:函数体与函数的几点不同在于:
- lambda表达式不能有默认参数。因此,一个lambda表达式调用的实参数目永远与形参数目相等。
- 所有参数必须有参数名。
- 不支持可变参数。
(2)捕获列表:
- lambda只有在其捕获列表中捕获一个它所在函数中的局部变量,才能在函数体中使用该变量。
- 捕获列表只用于非静态局部变量,lambda可以直接使用静态局部变量和在它所在函数之外声明的名字。
值捕获:采用值捕获的前提是变量可以拷贝。与参数不同,不捕获的变量的值是在lambda创建时拷贝,而不是调用时拷贝。
引用捕获:如果我们采用引用方式捕获一个变量,就必须确保被引用的对象在lambda执行的时候是存在的。
隐式捕获:可以让编译器根据函数体中的代码来推断需要捕获哪些变量,这种方式称之为隐式捕获。隐式捕获有两种方式,分别是[=]和[&]。[=]表示以值捕获的方式捕获外部变量,[&]表示以引用捕获的方式捕获外部变量。
混合方式捕获:lambda还支持混合方式捕获,即同时使用显示捕获和隐式捕获。混合捕获时,捕获列表中的第一个元素必须是 = 或 &,此符号指定了默认捕获的方式是值捕获或引用捕获 。需要注意的是:显示捕获的变量必须使用和默认捕获不同的方式捕获。
修改捕获的值:在参数列表首加上关键字mutable。语法变为:[capture list] (parameter list) mutable -> return type {function body}
(3)返回类型:
在默认的规则下,返回类型如下:
- 如果只包含单一的return语句,那么根据return 的类型确定返回类型。
- 如果除了return 还有别的语句,那么返回void。
C++ lambda表达式及其原理_sgh666666的博客-CSDN博客_c++ lambda 表达式
9.decltype的作用,他和auto有什么不同;auto的类型推导是什么时候进行的
auto会忽略引用,其次,auto一般会忽略掉顶层const,但底层const会被保留下来;auto的类型推断是在编译的时候推断出来的
decltype在处理顶层const和引用的方式与auto有些许不同,如果decltype使用的表达式是一个变量,则decltype返回该变量的类型(包括顶层const和引用在内)。
decltype和auto还有一处重要的区别是,decltype的结果类型与表达形式密切相关。有一种情况需要特别注意:对于decltype 所用表达式来说,如果变量名加上一对括号,则得到的类型与不加上括号的时候可能不同。如果decltype使用的是一个不加括号的变量,那么得到的结果就是这个变量的类型。但是如果给这个变量加上一个或多层括号,那么编译器会把这个变量当作一个表达式看待,变量是一个可以作为左值的特殊表达式,
10.C++thread里面的锁,条件变量
11.C++20、c++11的新特性
12.boost库,协程,muduo
13.内存分区
14.dynamic_cast的用法,无法转换时会出现什么情况(指针返会NULL,引用抛异常)
15.空类会默认生成哪些
编译器只会在需要的时候生成6个成员函数:一个缺省的构造函数、一个拷贝构造函数、一个析构函数、一个赋值运算符、一对取址运算符和一个this指针。
class Empty
{
public:
Empty(); //缺省构造函数
Empty(const Empty &rhs); //拷贝构造函数
~Empty(); //析构函数
Empty& operator=(const Empty &rhs); //赋值运算符
Empty* operator&(); //取址运算符
const Empty* operator&() const; //取址运算符(const版本)
};C++中空类详解_ox0080的博客-CSDN博客
16.__stdcall
17.了解printf的可变参数是怎么实现的吗,从汇编层面解释一下
18.++i线程安全吗,为什么;++i和i++区别;++i寄存器操作
i++和++i都不具有原子性
1、如果i是局部变量(在方法里定义的),那么是线程安全的。因为局部变量是线程私有的,别的线程访问不到,其实也可以说没有线程安不安全之说,因为别的线程对他造不成影响。
2、如果i是全局变量,则同一进程的不同线程都可能访问到该变量,因而是线程不安全的,会产生脏读。
19.协程和线程的区别
20.红黑树和链表的使用场景
21.下列哪些是在编译期间完成计算的(#define,const int a,sizeof(void*),模板)
22.两个线程同时执行100次i++,结果如何?
i++在两个线程执行100次,最终的结果是_usstmiracle的博客-CSDN博客
23.vector是线程安全的吗
不是。C++ STL容器如何解决线程安全的问题? - 知乎
24.原地交换两个int变量 b = (a+b)-(a=b)
或者
a = a ^ b;b = a ^ b;a = a ^ b;
25.x&(x-1)代表什么
代表把x二进制最右边的一个1变为0
26.move 语义
27.动态多态/静态多态原理
28.如何设计对象不能被拷贝
29.volatile
volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。
不用volatile的话,在debug模式下可能不会出错,但是在release模式下就会报错。
和 const 修饰词类似,const 有常量指针和指针常量的说法,volatile 也有相应的概念:
-
修饰由指针指向的对象、数据是 const 或 volatile 的:
- const char* cpch;
- volatile char* vpch;
- 指针自身的值——一个代表地址的整数变量,是 const 或 volatile 的:
- char*const pchc;
- char*volatile pchv;
-
注意:(1) 可以把一个非volatile int赋给volatile int,但是不能把非volatile对象赋给一个volatile对象。
(2) 除了基本类型外,对用户定义类型也可以用volatile类型进行修饰。
(3) C++中一个有volatile标识符的类只能访问它接口的子集,一个由类的实现者控制的子集。用户只能用const_cast来获得对类型接口的完全访问。此外,volatile向const一样会从类传递到它的成员。
30.c++内存分配
应用程序内存分配


Malloc、operator new要指定分配内存的大小,operator new就是调用malloc.
New的过程:分配一块内存,调用构造函数
31.const和define的区别
(1)类型的安全性检查:const常量有数据类型,而define定义宏常量没有数据类型。则编译器可以对前者进行类型安全检查,而对后者只进行字符替换,没有类型安全检查(字符替换时可能会产生意料不到的错误,如上面的程序所示);
(2)调试:部分调度工具可以对const常量进行调度,但不能对宏常量进行调度;
(3)编译器的处理方式不同:define宏是在预处理阶段展开,const常量则是编译运行阶段使用;
(4)存储方式不同:define宏仅仅是展开,有几个地方使用则展开几次,不分配内存;const常量会在内存中分配地址(可以是堆中也可以是栈中);
(5)效率:define定义的常量在内存中有若干个拷贝;const定义的常量在程序运行过程中只有一份拷贝,甚至不为普通const常量分配存储空间,而是将它们保存在符号表中,相当于没有了读内存的操作,使得效率也很高
32.动态链接库的原理
33.c++编译运行的过程
编译过程分为四个过程:编译(编译预处理、编译、优化),汇编,链接
编译预处理:处理以 # 开头的指令;对源文件进行预处理,这个过程主要是处理一些#号定义的命令或语句(如宏、#include、预编译指令#ifdef等),生成*.i文件
编译、优化:进行词法分析、语法分析和语义分析,将源码 .cpp 文件翻译成 .s 汇编代码;
汇编:将汇编代码 .s 翻译成机器指令 .o 文件
链接:汇编程序生成的目标文件并不会立即执行,可能有源文件中的函数引用了另一个源文件中定义的符号或者调用了某个库文件中的函数。那链接的目的就是将这些目标文件连接成一个整体,从而生成可执行的程序 .exe 文件。
35.静态链接、动态链接
静态链接和动态链接两者最大的区别就在于链接的时机不一样,静态链接是在形成可执行程序前,而动态链接的进行则是在程序执行时。
静态链接 浪费空间,每个可执行程序都会有目标文件的一个副本,这样如果目标文件进行了更新操作,就需要重新进行编译链接生成可执行程序(更新困难);优点就是执行的时候运行速度快,因为可执行程序具备了程序运行的所有内容
动态链接:节省内存、更新方便,但是动态链接是在程序运行时,每次执行都需要进行链接,性能会有一定的损失。静态链接和动态链接区别 - 怀想天空_2013 - 博客园
35.c++对象模型是什么
C++对象模型 - 吴秦 - 博客园
36.Static的使用
(1)全局静态变量,在静态存储区,默认初始化为0,在声明他的文件之外不可见(准确来说从声明他的地方开始到文件结尾)
(2)局部静态变量,在静态存储区,默认初始化为0,作用域仍为局部作用域,只是出了作用域后并没有被销毁,仍然在内存中,下次访问到该函数时仍可以被调用
(3)静态函数,静态函数只是在声明他的文件中可见,不能被其它文件所用,避免重名冲突。不要在头文件中声明static全局函数,不要在cpp中声明非static全局函数。
(4)类的静态成员,可以实现不同类对象之间的数据共享,不属于任何一个对象。
(5)类的静态函数,类的静态成员,对类的静态成员进行引用不需要用对象名,不能直接引用类中的非静态成员,可以引用类中的静态成员
37.C++ 四种强制转换,static_cast和dynamic_cast分别是什么时候转的(编译、运行)
static_cast、const_cast、reinterpret_cast和dynamic_cas
- static_cast:
(1)用于类层次结构中基类和派生类之间指针或引用的转换
进行上行转换(把派生类的指针或引用转换成基类表示)是安全的
进行下行转换(把基类的指针或引用转换为派生类表示),由于没有动态类型检查,所以是不安全的
(2)用于基本数据类型之间的转换,如把int转换成char。这种转换的安全也要开发人员来保证
(3)把空指针转换成目标类型的空指针
(4)把任何类型的表达式转换为void类型
注意:static_cast不能转换掉expression的const、volitale或者__unaligned属性。static_cast:可以实现C++中内置基本数据类型之间的相互转换。
如果涉及到类的话,static_cast只能在有相互联系的类型中进行相互转换,不一定包含虚函数。
- const_cast
而const_cast则正是用于强制去掉这种不能被修改的常数特性,但需要特别注意的是const_cast不是用于去除变量的常量性,而是去除指向常数对象的指针或引用的常量性,其去除常量性的对象必须为指针或引用。
用法:const_cast
(expression)
该运算符用来修改类型的const或volatile属性。除了const 或volatile修饰之外, type_id和expression的类型是一样的。
常量指针被转化成非常量指针,并且仍然指向原来的对象;
常量引用被转换成非常量引用,并且仍然指向原来的对象;常量对象被转换成非常量对象。
- reinterpret_cast
在C++语言中,reinterpret_cast主要有三种强制转换用途:改变指针或引用的类型、将指针或引用转换为一个足够长度的整形、将整型转换为指针或引用类型。
用法:reinterpret_cast
(expression)
type-id必须是一个指针、引用、算术类型、函数指针或者成员指针。
它可以把一个指针转换成一个整数,也可以把一个整数转换成一个指针(先把一个指针转换成一个整数,在把该整数转换成原类型的指针,还可以得到原先的指针值)。
在使用reinterpret_cast强制转换过程仅仅只是比特位的拷贝,因此在使用过程中需要特别谨慎!
- dynamic_cast
(1)其他三种都是编译时完成的,dynamic_cast是运行时处理的,运行时要进行类型检查。
(2)不能用于内置的基本数据类型的强制转换。
(3)dynamic_cast转换如果成功的话返回的是指向类的指针或引用,转换失败的话则会返回NULL。
(4)使用dynamic_cast进行转换的,基类中一定要有虚函数,否则编译不通过。
B中需要检测有虚函数的原因:类中存在虚函数,就说明它有想要让基类指针或引用指向派生类对象的情况,此时转换才有意义。
这是由于运行时类型检查需要运行时类型信息,而这个信息存储在类的虚函数表(关于虚函数表的概念,详细可见
)中, 只有定义了虚函数的类才有虚函数表。
(5)在类的转换时,在类层次间进行上行转换时,dynamic_cast和static_cast的效果是一样的。在进行下行转换时,dynamic_cast具有类型检查的功能,比static_cast更安全。
向上转换,即为子类指针指向父类指针(一般不会出问题);向下转换,即将父类指针转化子类指针。
向下转换的成功与否还与将要转换的类型有关,即要转换的指针指向的对象的实际类型与转换以后的对象类型一定要相同,否则转换失败。
在C++中,编译期的类型转换有可能会在运行时出现错误,特别是涉及到类对象的指针或引用操作时,更容易产生错误。Dynamic_cast操作符则可以在运行期对可能产生问题的类型转换进行测试。
C++ 四种强制类型转换 - 静悟生慧 - 博客园
38.const的使用
(1)修饰普通类型变量,被编译器认为是常量,不允许修改。
(2)修饰指针:
如果const位于星号*的左侧,则const就是用来修饰指针所指向的变量,即指针指向为常量;即const修饰类型,所以是指向的内容
如果const位于星号的右侧,const就是修饰指针本身,即指针本身是常量。即const修饰对象,对象本身是指针
(3)const修饰函数参数:
a.修饰传参,本来就是拷贝,作用不大
b.修饰指针,可以防止指针被篡改
c.修饰自定义对象,可以用const和引用一起,避免重新调用构造函数
(4)congst修饰函数返回值:
a.修饰内置类型,作用不大
b.修饰自定义类型,此时返回的值不能作为左值使用,既不能被赋值,也不能被修改
c.修饰返回的指针或者引用,是否返回一个指向 const 的指针,取决于我们想让用户干什么
(5)修饰类成员函数
防止成员函数修改被调用对象的值,如果我们不想修改一个调用对象的值,所有的成员函数都应当声明为 const 成员函数。
此时const 关键字不能与 static 关键字同时使用,因为 static 关键字修饰静态成员函数,静态成员函数不含有 this 指针,即不能实例化,const 成员函数必须具体到某一实例。
如果const成员函数想修改对象中的某一个成员,可以使用 mutable 关键字修饰这个成员(声明的时候)
const和static能同时修饰成员函数吗?
不可以。C++编译器在实现const的成员函数的时候为了确保该函数不能修改类的实例的状态,会在函数中添加一个隐式的参数const this*。但当一个成员为static的时候,该函数是没有this指针的。也就是说此时const的用法和static是冲突的。
39.C++ stl用到的设计模式
(1) Composition(复合) 设计模式: have-a
queue用deque实现
像这样 一个对象依托于另一个对象来实现 为复合设计模式
在复合设计模式下:
构造由内而外:
Container::Container(……): Component() { …… } ;
(Container的构造函数首先调用Component的default构造函数 然后才执行自己析构由外而内:Container::~Container(……) { …… ~Component() } ;
(Container 的析构函数首先执行自己,然后才调用 Component 的
析构函数。 )这样的构造和析构的顺序很大程度保证了复合模式的稳定.
(2)Delegation(委托) 设计模式: (Composition by reference)
通过指针来引用另一个实现的类:
对比于前一种复合设计模式 它的好处在于不受被委托类的影响 被委托类即便修改了某个成员函数名, 也不需要在发起委托的类上修改.
同时 String类的多个对象可以共享rep指针指向的对象 减少了内存的占用
(3) Inheritance(继承) is-a



40.单实例模式,怎么防止别的线程new单例对象,这个涉及到单实例类的内部设计
41.stl里面栈的实现,用了什么设计模式官方名称
双向队列,用的复合设计模式
42.构造函数和析构函数能否定义为虚函数,构造函数里面能否调用虚函数
简要结论:
1. 从语法上讲,调用完全没有问题。
2. 但是从效果上看,往往不能达到需要的目的。
Effective 的解释是:
派生类对象构造期间进入基类的构造函数时,对象类型变成了基类类型,而不是派生类类型。
同样,进入基类析构函数时,对象也是基类类型。C++构造函数和析构函数中可以调用虚函数吗?_$firecat全宏的代码足迹$-CSDN博客_构造函数中可以调用虚函数吗
43.static和const的区别及使用
- const定义的常量在超出其作用域之后其空间会被释放,而static定义的静态常量在函数执行后不会释放其存储空间。
- static表示的是静态的。类的静态成员函数、静态成员变量是和类相关的,而不是和类的具体对象相关的。即使没有具体对象,也能调用类的静态成员函数和成员变量。一般类的静态函数几乎就是一个全局函数,只不过它的作用域限于包含它的文件中。
- 在C++中,static静态成员变量不能在类的内部初始化。在类的内部只是声明,定义必须在类定义体的外部,通常在类的实现文件中初始化,如:double Account::Rate=2.25; static关键字只能用于类定义体内部的声明中,定义时不能标示为static
- 在C++中,const成员变量也不能在类定义处初始化,只能通过构造函数初始化列表进行,并且必须有构造函数。
- const数据成员,只在某个对象生存期内是常量,而对于整个类而言却是可变的。因为类可以创建多个对象,不同的对象其const数据成员的值可以不同。所以不能在类的声明中初始化const数据成员,因为类的对象没被创建时,编译器不知道const数据成员的值是什么。
- const数据成员的初始化只能在类的构造函数的初始化列表中进行。要想建立在整个类中都恒定的常量,应该用类中的枚举常量来实现,或者static const。
44.C++函数重载怎么实现的?
c++函数重载是一种静态多态。
编译器在编译.cpp文件中当前使用的作用域里的同名函数时,根据函数形参的类型和顺序会对函数进行重命名(不同的编译器在编译时对函数的重命名标准不一样)但是总的来说,他们都把文件中的同一个函数名进行了重命名;
而.c文件不能实现重载。
编译器在编译.c文件时,只会给函数进行简单的重命名;具体的方法是给函数名之前加上”_”;所以加入两个函数名相同的函数在编译之后的函数名也照样相同;调用者会因为不知道到底调用那个而出错;
C++的函数重载实现原理_fantian_的博客-CSDN博客
45.C++引用怎么实现的
引用是用指针实现的。用户对引用的访问操作都内含一次解引用,而这对用户来说是透明的。只是编译器自动对指针做了取值操作而已
引用所占的内存大小就是指针的大小。
46.智能指针是不是安全的
1 同一个shared_ptr被多个线程“读”是安全的。
2 同一个shared_ptr被多个线程“写”是不安全的。
3 共享引用计数的不同的shared_ptr被多个线程”写“ 是安全的。
【学习点滴】c++智能指针(手写一个),及线程安全性_o小菜的博客-CSDN博客_智能指针线程安全吗
47.什么是线程安全、线程不安全
- 线程安全指多个线程在执行同一段代码的时候采用加锁机制,使每次的执行结果和单线程执行的结果都是一样的,而且其他的变量的值也和预期的是一样的,不存在执行程序时出现意外结果。(保证数据的一致性)
- 线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据。
1、引起线程安全问题的原因:
线程安全问题都是由全局变量及静态变量引起的。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
2、解决多线程并发访问资源安全问题的方法,实现线程同步的方法:
信号量
互斥锁
读写锁
条件变量
同步的前提:
1,必须要有两个或者两个以上的线程
2,必须是多个线程使用同一个锁
必须保证同步中只能有一个线程在运行
好处:解决了多线程的安全问题
弊端:多个线程需要判断锁,较为消耗资源、抢锁的资源。
注意:在单线程环境下,没有“线程安全”和“非线程安全”的概念。
48.unique_ptr的底层实现
我们知道指针或引用在离开作用域时是不会进行析构的,但类在离开作用域时会自动执行析构函数(unique_ptr
本质是类,只是可以像指针一样使用),因此,我们可以通过析构函数调用delete去销毁资源。
那unique_ptr如何实现“独占”所指对象,因为unique_ptr本质是类 ,因此可将copy constructor和copy assignment声明为delete即可(获取将其变为private属性且不去实现它也行);类-unique_ptr实现原理_CPriLuke的博客-CSDN博客
49.指针delete两次会发生什么情况
无论是free()还是delete().如果连续两次free()或delete(),则程序在编译时不会报错,但是在运行时会报错。
free(p):对应malloc(),一旦malloc()一块内存,则相当于机器吧这块内存借给你了,你可以随便使用这块内存,机器就不会再把这块内存借给其他程序,所以其他程序就不会使用这块内存。而一旦free()后,相当于你把这块内存还给了机器,机器就可以把这块内存借给其他程序了。free()相当于“还”,第一次free()时,这块内存是被已经借出来给你了,你可以“还”,但是第二次free()时,这块内存是属于机器的,你拿着机器的内存还给机器,肯定会出错(如果在两次free()之间又有线程被分配了这块地址,则应该不会报错吧)。虽然你把这块内存还给了机器,但是指针p还是指向了这个地址,要把他=null.否则就变成了野指针,他扔可以操作刚才的地址,但是这个地址是不应该被冲走做的,如果操作可能就破坏了其他的使用这个内存的程序的数据。
50.Nullptr和null的区别
NULL引渡自C语言,一般由宏定义实现,而nullptr则是C++11的新增关键字。在C语言中,NULL被定义为(void*)0,而在C++语言中,NULL则被定义为整数0.在函数重载的时候,NULL可能会被当成0处理,引起错误。
51.智能指针体现什么机制
RAII(Resource Acquisition Is Initialization)机制是Bjarne Stroustrup首先提出的,也称直译为“资源获取就是初始化”,是C++语言的一种管理资源、避免泄漏的机制。
C++标准保证任何情况下,已构造的对象最终会销毁,即它的析构函数最终会被调用。
RAII 机制就是利用了C++的上述特性,在需要获取使用资源RES的时候,构造一个临时对象(T),在其构造T时获取资源,在T生命期控制对RES的访问使之始终保持有效,最后在T析构的时候释放资源。以达到安全管理资源对象,避免资源泄漏的目的。
52.extern c的使用
C++项目中的extern "C" {} - 吴秦 - 博客园
54.template
55.virtual作用与基类还是子类的virtual?还是都作用
56.空类实例化一个对象需要多大内存,如果类中有虚函数呢
空类大小是1,有虚函数就是4
58.gdb的使用
LINUX下GDB的使用方法(简单说说)_longfan的博客-CSDN博客_gdb
59.为什么返回值不一样不是重载
60.const修饰的对象能调用成员函数吗?
const对象只能调用const成员函数、不能调用非const成员函数;非const对象可以调用const成员函数_夜空紫色的博客-CSDN博客
61.模板成员函数可以是虚函数吗?
编译器在编译一个类的时候,需要确定这个类的虚函数表的大小。一般来说,如果一个类有N个虚函数,它的虚函数表的大小就是N,如果按字节算的话那么就是4*N。
如果允许一个成员模板函数为虚函数的话,因为我们可以为该成员模板函数实例化出很多不同的版本,也就是可以实例化出很多不同版本的虚函数,那么编译器为了确定类的虚函数表的大小,就必须要知道我们一共为该成员模板函数实例化了多少个不同版本的虚函数。显然编译器需要查找所有的代码文件,才能够知道到底有几个虚函数,这对于多文件的项目来说,代价是非常高的,所以才规定成员模板函数不能够为虚函数。
62.#define和typedef的区别
63.空类sizeof一下是多大?只有一个虚析构函数的类呢?
64.const变量能通过访问地址进行修改吗?
不可以:编译器在编译期间,把有用到该常量的地方都进行了替换。
65.C++内存空间模型。堆的空间是谁管理的:
gcc分配
堆都是动态分配的,没有静态分配。栈有2中分配方式:静态分配和动态分配。静态分配是由编译器完成的,比如局部变量的分配。动态分配是由malloc函数进行分配,但是栈的动态分配和堆的不同,他的动态分配是由编译器进行释放,无需手动释放。
https://www.cnblogs.com/daocaoren/archive/2011/06/29/2092957.html
66.malloc过程
malloc 函数的实质是它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表。 调用 malloc()函数时,它沿着连接表寻找一个大到足以满足用户请求所需要的内存块。(如果没有搜索到,那么就会用sbrk()才推进brk指针来申请内存空间)。 然后,将该内存块一分为二(一块的大小与用户申请的大小相等,另一块的大小就是剩下来的字节)。 接下来,将分配给用户的那块内存存储区域传给用户,并将剩下的那块(如果有的话)返回到连接表上。 调用 free 函数时,它将用户释放的内存块连接到空闲链表上。 到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段, 那么空闲链表上可能没有可以满足用户要求的片段了。于是,malloc()函数请求延时,并开始在空闲链表上检查各内存片段,对它们进行内存整理,将相邻的小空闲块合并成较大的内存块。
搜索空闲块最常见的算法有:首次适配,下一次适配,最佳适配。 (其实就是操作系统中动态分区分配的算法)c/c++中malloc的底层实现原理_ypshowm的博客-CSDN博客_c++ malloc
https://blog.csdn.net/mmshixing/article/details/51679571
67.c++和python的区别
C、C++、Java、Python之间的区别_团子-Y的博客-CSDN博客_java,c语言,python,c++的不同之处
68.incline的优缺点
inline函数的优点与缺点
优点:
1)inline定义的内联函数,函数代码被放入符号表中,在使用时进行替换(像宏一样展开),效率很高。
2)类的内联函数也是函数。编绎器在调用一个内联函数,首先会检查参数问题,保证调用正确,像对待真正函数一样,消除了隐患及局限
性。3)inline可以作为类的成员函数,可以使用所在类的保护成员及私有成员。
缺点:
内联函数以复制为代价,活动产生开销
1)如果函数的代码较长,使用内联将消耗过多内存 , 这种情况编译器可能会自动把它作为非内联函数处理
2)如果函数体内有循环,那么执行函数代码时间比调用开销大。
inline与宏的区别
区别如下:
1)内联在编绎时展开,宏在预编译时展开。 展开的时间不同。
2)编译内联函数可以嵌入到目标代码,宏只是简单文本替换。
3)内联会做类型,语法检查,而宏不具这样功能。
4)宏不是函数,inline函数是函数
5)宏定义小心处理宏参数(一般参数要括号起来),否则易出现二义性,而内联定义不会出现。
C++中宏与内联函数的优缺点_不很正派的专栏-CSDN博客
69.stl除了容器还有什么
stl六大组件


70.迭代器的类型
C++ 迭代器 - 简书
https://blog.csdn.net/efforever/article/details/60960867
71.封装、继承、多态介绍一下
72.栈溢出是什么原因?为什么栈的空间不够
73.虚继承
74.auto有哪些坑
75.C++11/14/17/20有了解过吗
76.c++编译过程常见错误
C语言的编译过程常见的错误和警告_halikuiyin的博客-CSDN博客_c语言编译错误
77.short int long各占几个字节
short 2个字节,int 4 个字节,long8个字节(32位是4个)
https://blog.csdn.net/u014492609/article/details/38067599

78.printf里面怎么实现
79.c++模板,优劣势
80.解释性语言和编译性语言
81.memset可不可以初始化vector
当memset初始化时,并不会初始化p_x指向的int数组单元的值,而会把已经分配过内存的p_x指针本身设置为0,造成内存泄漏。同理,对std::vector等数据类型,显而易见也是不应该使用memset来初始化的。
老生常谈,正确使用memset - 知乎
82.右值引用、泛型编程
83.字节对齐为什么可以提高访问速度?
83.c++实现单例模式
C++ 单例模式 - 知乎
84.构造函数、析构函数能否抛出异常
不能。
C++中构造函数和析构函数可以抛出异常吗?_魏波-CSDN博主-CSDN博客
85.返回值优化
C++之返回值优化 - 简书
86.单例模式,手写了两种单例模式以及实现线程安全
87.说一下堆和栈的概念?分别存了什么变量?有什么区别?
88.vector的扩容原理,底层如何实现,初始容量为1,要push_back N个数,问要扩容几次,总共占用过多少空间,平均每个数复制几次,扩容的复杂度
89.模板类的一些问题,模板是在编译期间确定还是在运行阶段确定,虚函数中是否能用模板函数
90.Reactor、Proactor
91.构造函数可以是虚函数吗,析构函数呢
构造函数不可以是虚函数,析构函数可以是虚函数,也可以是纯虚函数
虚析构函数(√)、纯虚析构函数(√)、虚构造函数(X) - 中土 - 博客园
92.stl里面二级配置器底层实现
93.内联函数可以跨文件使用吗
94.c++异常处理
95.迭代器失效问题
迭代器失效分三种情况考虑,也是分三种数据结构考虑,分别为数组型,链表型,树型数据结构。
数组型数据结构:该数据结构的元素是分配在连续的内存中,insert和erase操作,都会使得删除点和插入点之后的元素挪位置,所以,插入点和删除掉之后的迭代器全部失效,也就是说insert(*iter)(或erase(*iter)),然后在iter++,是没有意义的。解决方法:erase(*iter)的返回值是下一个有效迭代器的值。 iter =cont.erase(iter);
链表型数据结构:对于list型的数据结构,使用了不连续分配的内存,删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.解决办法两种,erase(*iter)会返回下一个有效迭代器的值,或者erase(iter++).
树形数据结构: 使用红黑树来存储数据,插入不会使得任何迭代器失效;删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.erase迭代器只是被删元素的迭代器失效,但是返回值为void,所以要采用erase(iter++)的方式删除迭代器。
注意:经过erase(iter)之后的迭代器完全失效,该迭代器iter不能参与任何运算,包括iter++,*ite
https://www.cnblogs.com/fnlingnzb-learner/p/9300073.html
96.overwrite关键字
作用:如果派生类在虚函数声明时使用了override描述符,那么该函数必须重载其基类中的同名函数,否则代码将无法通过编译。
https://blog.csdn.net/xiaoheibaqi/article/details/51272009
C++11 之 override - 飞鸢逐浪 - 博客园
97.C++ 内存模型/C++对象模型
在C++类中有两种数据成员:static,nonstatic;三种成员函数:static、nonstatic、virtual。
在此模型中,nonstatic数据成员被放置到对象内部,static数据成员、static和nonstatic函数成员军备放到对象之外。对于虚函数的支持则分两部分完成:
1、每一个class产生一堆指向虚函数的指针,并存放在虚函数表中(Virtual Table,vtbl);
2、每个对象被添加了一个指针,指向相关的虚函数表vtbl。通常这个指针被称为vptr。vptr的设定和重置都由每一个class的构造函数,析构函数和拷贝赋值运算符自动完成。
另外,虚函数表地址的前面设置了一个指向type_info的指针,RTTI(Run Time Type Identification)运行时类型识别是由编译器在编译时生成的特殊类型信息,包括对象继承关系,对象本身的描述。RTTI是为多态而生成的信息,所以只有具有虚函数的对象才会生成。
这个模型的优点在于它的空间和存取时间的效率;缺点如下:如果应用程序本身未改变,当所使用的类的nonstatic数据成员添加删除或修改时,需要重新编译。
要点:
1.正常继承:一个父类一个虚指针,指向父类的虚函数表;如果子类有多个父类的话就有多个指向父类的虚指针,重写哪个父类的虚函数就在哪个父类的虚函数表里更新,子类新建的虚函数会加到第一个父类的虚函数表中,子类不具有自己的虚函数表。
多继承(比如菱形继承)每个子类都有父类的数据成员,可能会出现重复。
2.虚继承:与正常继承的区别是,子类自己如果有新的虚函数,会自己新建一个虚指针,指向新的虚函数表,排在类对象的最开始位置。如果没有新的对象就算作没有,之后是一个虚基类指针,指向虚基类表,表中每个元素存储着虚基类指针和虚基类的虚表指针的距离。
多继承(比如菱形继承)子类共享共同父类的数据成员,不出现重复。
3.菱形继承:祖父和父亲之间是虚继承,儿子类和父亲类之间是普通继承。
图说C++对象模型:对象内存布局详解 - melonstreet - 博客园
C++内存模型 - MrYun - 博客园
https://www.cnblogs.com/skynet/p/3343726.html
98.printf 的可变参数的实现原理
99.运行一个main函数的过程,从预处理开始讲,到栈帧的处理;预处理怎么去掉注释的(??)编译器做了什么事情?静态链接和动态链接,栈帧的细节是什么,具体保存了什么东西?(前面答的太尴尬了,自告奋勇说了异常的处理机制;)
100.new 和 malloc的区别,malloc 底层是怎么样的?具体的操作过程是怎么样的?(说了 brk 和 mmap,面试官说这只是系统调用,具体逻辑是怎么样的)有没有看过源码?
101.智能指针怎么管理内存?
102.protobuf 为什么快
103.c++成员变量的存储位置
成员变量并不能决定自身的存储空间位置。决定存储位置的对象的创建方式。
即:
如果对象是函数内的非静态局部变量,则对象,对象的成员变量保存在栈区。
如果对象是全局变量,则对象,对象的成员变量保存在静态区。
如果对象是函数内的静态局部变量,则对象,对象的成员变量保存在静态区。
如果对象是new出来的,则对象,对象的成员变量保存在堆区。
104.priority_queue底层实现
堆。
http://c.biancheng.net/view/7010.html
105.栈动态分配内存空间
alloca——可以在栈中动态分配内存的函数_suoluotree的专栏-CSDN博客
106.sizeof 空类,虚基类等
C++ 类 sizeof 计算大小 虚函数 虚继承 虚基类 虚函数表_neninee的博客-CSDN博客
C/C++中,空数组、空类、类中空数组的解析及其作用 - 静悟生慧 - 博客园
C/C++中,空数组、空类、类中空数组的解析及其作用 - 静悟生慧 - 博客园
算法
1.了解过平衡二叉树和红黑树吗,区别;满足红黑树算平衡二叉树吗?有平衡二叉树,查询效率很好,为啥要红黑树;b+树和二叉树的区别;mysql为啥用b+树,为啥不用二叉树
2.王者荣耀游戏,你控制人物从队友身边跑过去,你队友的手机也能看到你从身边跑过去,请问这个过程客户端和服务器做了什么
3.微信,附近的人这个功能怎么实现(怎么判断大量的点是否在给定点的附近?空间索引)
4.不考虑性能、内存等因素,理想条件下,一台主机最多可以建立10万个连接嘛?
这个问题要分两个方面考虑:(1)主机是客户端的话,一个端口对应一个连接,无符号整型变量的最大值为65536,因此最多只能建立65536个连接,此时不能建立10万个连接。可增加一个ip,支持的连接数就可以翻倍。
(2)主机是服务端的话,由epoll的多路复用模型,一个端口可以监听65536个连接,有65536个端口,则可以建立10万个连接。
5.红黑树和avl树的比较、优缺点
查询多的用AVL,删除插入多的用红黑树
1. 如果插入一个node引起了树的不平衡,AVL和RB-Tree都是最多只需要2次旋转操作,即两者都是O(1);但是在删除node引起树的不平衡时,最坏情况下,AVL需要维护从被删node到root这条路径上所有node的平衡性,因此需要旋转的量级O(logN),而RB-Tree最多只需3次旋转,只需要O(1)的复杂度。
2. 其次,AVL的结构相较RB-Tree来说更为平衡,在插入和删除node更容易引起Tree的unbalance,因此在大量数据需要插入或者删除时,AVL需要rebalance的频率会更高。因此,RB-Tree在需要大量插入和删除node的场景下,效率更高。自然,由于AVL高度平衡,因此AVL的search效率更高。
3. map的实现只是折衷了两者在search、insert以及delete下的效率。总体来说,RB-tree的统计性能是高于AVL的。
6.二叉树的之字形遍历
7.栈实现队列
8.排序算法时间复杂度分析
- 归并排序时间复杂度分析:
总时间=分解时间+解决问题时间+合并时间。分解时间就是把一个待排序序列分解成两序列,时间为一常数,时间复杂度o(1).解决问题时间是两个递归式,把一个规模为n的问题分成两个规模分别为n/2的子问题,时间为2T(n/2).合并时间复杂度为o(n)。总时间T(n)=2T(n/2)+o(n).这个递归式可以用递归树来解,其解是o(nlogn).此外在最坏、最佳、平均情况下归并排序时间复杂度均为o(nlogn).从合并过程中可以看出合并排序稳定。 用递归树的方法解递归式T(n)=2T(n/2)+o(n):假设解决最后的子问题用时为常数c,则对于n个待排序记录来说整个问题的规模为cn。从这个递归树可以看出,第一层时间代价为cn,第二层时间代价为cn/2+cn/2=cn.....每一层代价都是cn,总共有logn+1层。所以总的时间代价为cn*(logn+1).时间复杂度是o(nlogn).
- 快速排序时间复杂度分析:
和归并类似,只不过选的点不同,如果每次都选到了靠边的点,就变成O(n2)
- 堆排序时间分析(一般升序采用大顶堆,降序采用小顶堆)
建堆耗时S = n - log(n) -1即O(n),排序重调堆用时O(nlogn),相加为O(nlogn)。
堆排序的时间复杂度分析_只愿不违本心的博客-CSDN博客_堆排序时间复杂度
稳定性分析:https://zhuanlan.zhihu.com/p/272181959

9.进制转换
leetcode 405
10.链表交点系列问题
Leetcode. 两个单链表相交问题汇总 - 简书
11.重载赋值运算符
C++重载赋值运算符 - ay-a - 博客园
12.树的之形遍历(leetcode 103)层序遍历(leetcode 102)
力扣
13.深拷贝浅拷贝
14.贪心算法的中心思想是什么
15.有1、2、5、10、20、50、100的纸币各c0、c1、c2、c3、c4、c5、c6张,现需支付K元,至少需要多少张纸币
16.判断两个字符串是否是旋转字符串?如123456和456123
17.海量数据中找中位数
海量数据中寻找中位数 - 知乎
18.海量数据处理
面试必考热点之《海量数据处理》_JaweG-CSDN博客
https://blog.csdn.net/v_JULY_v/article/details/6279498
教你如何迅速秒杀掉:99%的海量数据处理面试题_结构之法 算法之道-CSDN博客
19.小根堆定时器怎么实现?如果是百万并发请求怎么实现呢
20.图有哪几种存储方式
21.非递归方式遍历二叉树
二叉树的广度优先遍历、深度优先遍历的递归和非递归实现方式 - 知其然,后知其所以然 - 博客园
非递归实现二叉树先序、中序和后序遍历 - zzu_Lee - 博客园
22.binary index tree 树状数组
树状数组(Binary Indexed Tree),看这一篇就够了_正西风落叶下长安-CSDN博客
树状数组(Binary Indexed Tree) - Qoogle
23.priority queue使用
c++优先队列(priority_queue)用法详解_吕白_的博客-CSDN博客_c++ priority_queue
面试
1.算法题可以先和面试官讲一下思路,然后再写题,比如分析有多少种方法,时间复杂度及空间复杂度。
2.算法题可以刷高频题,要多刷,每道题一遍肯定还不够。
3.多核小内存大数据量排序
其它
1.数据结构和算法是什么
数据结构就是将数据按照一定的逻辑存储起来的方法;算法是对数据结构进行有规律的一系列操作,来实现某个目的;数据结构和算法加起来就是程序。
2.如何设计一个秒杀系统?
3.如果内存只有1G,但是进程要占2G是否可以?
4.两个微信用户通信的过程
5.模板模式、工厂模式、单例模式
6.服务器如何提高吞吐量
7.写了一个观察者模式
8.设计一个亿级用户使用的系统
(1)单机系统
(2)数据库、文件系统和应用程序分离
(3)使用本地缓存、分布式缓存
(4)应用服务集群化
(5)数据读写分离
(6)使用反向代理和CDN加速
反向代理、正向代理、CDN的区别:https://my.oschina.net/u/4287611/blog/3329715
(7)使用分布式文件系统和分布式数据库系统
(8)使用消息队列与分布式服务
使用分布式的缓存,提高系统的访问特性,减少数据存储的压力;
使用负载均衡,提供更多的应用服务器提高系统计算处理能力;
使用分布式存储,提供更多的服务器,分摊数据的读写压力;
以及使用微服务与异步架构,使系统变得更加低耦合,使应用业务变得更加可复用,通过这种手段支撑更强大的业务处理能力,从而支撑起一个大型网站系统架构。
https://segmentfault.com/a/1190000019282199
9.IM系统设计
如何设计一个亿级消息量的IM系统
从0到1:微信后台系统的演进之路
分布式
1.raft算法,怎么选举,如果 leader 挂掉怎么办?
2.解释一下负载均衡、削峰填谷
3.一致性哈希
聊聊一致性哈希 - 知乎
4.负载均衡算法有哪些
分为动态负载均衡和静态负载均衡。
负载均衡算法居然有这么多种!!!负载均衡算法总结_xzh_blog-CSDN博客_负载均衡算法
图解 负载均衡算法及分类_Linias的博客-CSDN博客_负载均衡算法
5.说了CAP,问还有呢,讲了些master/slave,cluster模型,然后讲了为什么需要分布式一致性算法)
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
一致性指“
all nodes see the same data at the same time”,即所有节点在同一时间的数据完全一致。一致性是因为多个数据拷贝下并发读写才有的问题,因此理解时一定要注意结合考虑多个数据拷贝下并发读写的场景。可用性指“
Reads and writes always succeed”,即服务在正常响应时间内一直可用。好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。可用性通常情况下可用性和分布式数据冗余,负载均衡等有着很大的关联。分区容错性指“
the system continues to operate despite arbitrary message loss or failure of part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务。分布式一致性算法:掘金
6.了解哪些常用的分布式系统(讲了etcd,zookeeper,redis;本来还想讲kafka
7.消息队列怎么保证可靠性
分为:
1.生产者丢失了数据
2.rabbitmq丢失了数据
3.消费者丢失了数据
如何保证消息队列的可靠性传输? - 知乎
8.40亿个整数,怎么去重,输出去重的数字。用bitmao需要的内存大小
9.nginx的网络模型
8分钟带你深入浅出搞懂Nginx - 知乎
hr面
1.hr面问答技巧
HR面试的十大经典问题 - 知乎
https://zhuanlan.zhihu.com/p/67994619