[经典论文分享] Reinforcement Learning for Solving the Vehicle Routing Problem
1 背景
针对组合优化问题,早在2016年就有论文提出了指针网络(pointer network)来解决TSP问题,并使用强化学习进行训练,取得了一定的效果。而直接基于指针网络解决VRP问题则存在一些弊端:1)难以解决解决动态VRP的问题,因为整个VRP问题结局过程中,各个消费者的需求会随着车辆的运输而不断被解决,使得输出过程是动态的。2)指针网络只适用于TSP问题以及背包问题等简单的问题,而对于复杂的CO问题适应性较差。3)指针网络的运算复杂度较高,并且其在encoder部分的RNN结构难以实现输入序列的排序不变性。基于这些问题,NIPS2018论文Reinforcement Learning for Solving the Vehicle Routing Problem对之前的指针网络进行了改进,并且利用强化学习算法REINFORCE进行训练,在几个VRP经典问题上取得了很好的效果。
论文原文:Reinforcement Learning for Solving the Vehicle Routing Problem
代码仓库:https://github.com/OptMLGroup/VRP-RL
2 模型结构
由于问题解决的是VRP问题,因此整个模型的输入是各个点的信息,输出是各个点的排序,各个点为: X = x i , i = 1 , 2 , 3 , . . . , M X = {x_i, i=1,2,3,...,M} X=xi,i=1,2,3,...,M,其中 x t i = ( s i , d t i ) x_t^i=(s^i,d_t^i) xti=(si,dti), s s s就是静态信息static为一个二维坐标值如 ( 0.5 , 0.3 ) (0.5,0.3) (0.5,0.3), d d d就是动态信息dynamic为当前顾客 i i i的需求如 9 9 9, M M M是所有消费者的数量加一个仓库。整个输入X是随着VRP的不断推进而变化的,比如小车来到了 1 1 1号消费者的地方那么 1 1 1号的需求就会减少。因此,一般用 X t X_t Xt代表 t t t时刻的输入。输出 Y t Y_t Yt代表了到 t t t时刻为止选择的序列 y 0 , y 1 , y 2 , . . . , y t y_0,y_1,y_2,...,y_t y0,y1,y2,...,yt。到这可以看出,整个模型的运行模式和指针网络基本上是一致的,即一步一个指针指向一个位置,从出发点一直到问题的结束。每一步的输入 X t X_t Xt包含了 t t t时刻所有位置的信息,每一步输出从里面选择一个位置作为此时刻输出 y t + 1 y_t+1 yt+1并存到一个类似trajectory的东西 Y Y Y里面。
下面这个过程和NLP里的一些内容很像。每一步的选择概率都是 P ( y t + 1 ∣ Y t , X t ) P(y_{t+1}|Y_t,X_t) P(yt+1∣Yt,Xt),其中 Y t Y_t Yt代表了当前所处的位置以及历史的信息。因此整个过程结束的概率为:
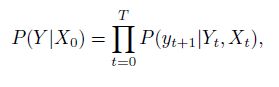
这个公式很像NLP里的语言模型。下面就要把这个模型用神经网络表示出来并进行训练。
其中 X t X_t Xt的更新方式为:
![]()
其中 f f f是状态转移函数,上面这个式子非常像离散仿真里的状态转移方程。
下面要对上面第一个公式进行神经网络表征。模仿NLP中的处理方法,主要是对式子右边的 P ( y t + 1 ∣ Y t , X t ) P(y_{t+1}|Y_t,X_t) P(yt+1∣Yt,Xt)进行表示:
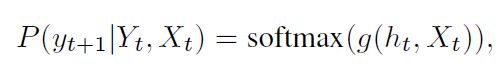
s o f t m a x softmax softmax不用说了,皮包函数。 g g g是一个函数。实现这个非线性函数并不是仅仅依靠一个MLP,而是十分复杂的一个过程:
从外到里:

然后里面这个:

; ; ;代表向量拼接。 v c T , W c v_c^T,W_c vcT,Wc是参数。 c t c_t ct是通过attention的结果得来的:

相当于一个对样本 X t X_t Xt进行重要性分分配后的一个加权平均值。 a t i a_t^i ati就是attention得来的:
![]()
其中
![]()
h t h_t ht为RNN decoder的state。
上面描述的这个过程可以用下图进行表示:其中图片最右边那个深颜色的方块值得就是RNN layer。
![[经典论文分享] Reinforcement Learning for Solving the Vehicle Routing Problem_第1张图片](http://img.e-com-net.com/image/info8/dd7a0f92989c41b78424e29cb372855e.jpg)
相比于之前的Pointer Network,作者取消了输入层的RNN序列,因为发现VRP问题并没有什么序列值得学习。
通过上面的过程,一步一个脚印生成从初始位置到条件结束的一个序列 Y t Y_t Yt,例如下面这个:
![]()
在这个过程中,很明显模型一开始并不能很智能地按照限制进行输出,因此作者也加入了mask方法对其进行限制:
1)无需求的顾客节点全部被mask 。
2)车没空间就全mask所有节点,只保留仓库节点。
3) 大于当前车的顾客需求节点被mask(默认解决不可拆分的离散需求)
3 实验
作者改变了一些CVRP问题中的变量来实现与Clarke-Wright savings heuristic (CW), the Sweep heuristic (SW), and Google’s optimization tools(OR-Tools)的对比实验
![[经典论文分享] Reinforcement Learning for Solving the Vehicle Routing Problem_第2张图片](http://img.e-com-net.com/image/info8/147e2cbb7911425d9d46af542dd69323.jpg)
文中用了精确解对于VRP10和VRP20两个问题进行了求解,用gap来表示其他方法与精确解之间的差距。对于VRP50和VRP100,作者采用win rate做了一个矩阵来表示其效用对比。
此外,作者还针对计算时间做了一个对比:
![[经典论文分享] Reinforcement Learning for Solving the Vehicle Routing Problem_第3张图片](http://img.e-com-net.com/image/info8/a43894834e9a4ce29dae2d1c930a3c71.jpg)
此外,在附录部分本文也有很多的补充实验,包括了细节的实验对比,以及对于文中模型attention的可视化。还有一个和指针网络的对比:文中的方法比原始的PN时间缩短了快一半,但是准确度几乎不变。
![[经典论文分享] Reinforcement Learning for Solving the Vehicle Routing Problem_第4张图片](http://img.e-com-net.com/image/info8/ffcf45dca1884ef4aefc63ee298735c1.jpg)
4 特点总结
1、文章其实算是对于传统pointer network的改进版本,并且给自己的定位在了为了泛化性地解决CO问题上。虽然看起来文章只是把指针网络的RNN encoder换成了一个单纯的embedding(本文作者说自己的工作是a simplified version of the Pointer Network),但是却真实地解决了很多问题。
2、文章是2018年发表的,工作应该在2017年左右,其用的attention结构实际上是seq2seq的结构,具体可以参看seq2seq的论文。
3、解决VRP问题的一个ML/RL通用过程就是‘一步式’给出解,然后用这个解对应的奖励值来利用强化学习进行训练,一般指针网络都是作为智能体的actor结构,critic就是MLP,可以用REINFORCE或者AC等policy-based方法进行训练