《机器学习》------实验三(决策树)
决策树相关知识在之前《机器学习—决策树笔记》中已提到:
https://blog.csdn.net/Naruto_8/article/details/120931619
实验内容:
- 对于给定的例题,基于决策树分类算法进行鸢尾花分类的练习。
- 回顾课程内容,掌握决策树的核心知识点和三种经典算法。
- 在熟悉原理的基础上,复现iris示例,了解每一部分代码的具体作用。将实验结果展示在报告中。
- 在步骤2的基础上,自己编写程序,使用决策树分类算法实现两个实例:
(1)威斯康星乳腺癌数据集
(2)顾客购买服装数据集进行分析与预测。 - 完成本实验报告。
1.复现iris示例:
#作 者:Asita
#开发时间:2021/11/21 20:23
from sklearn import tree # 导入决策树包
from sklearn.metrics import accuracy_score # 导入准确率评价指标
from sklearn.datasets import load_iris # 导入鸢尾花数据集
# 1.加载数据集:
iris = load_iris() # 载入数据集
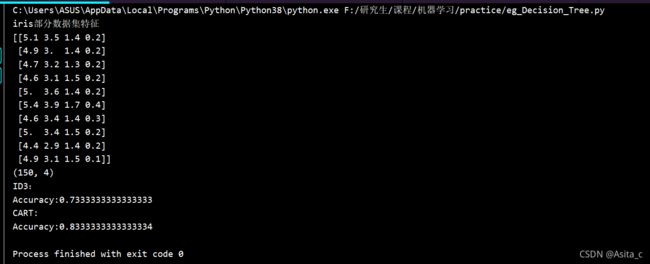
print('iris部分数据集特征')
print(iris.data[:10])
print(iris.data.shape) # 150*4
# 2.配置模型
# 配置划分属性评价函数,默认为gini基尼系数,这里的entropy是信息增益来实现的
#clf = tree.DecisionTreeClassifier() #默认为基尼系数加载决策树模型
# max_depth属性为树的最大深度,当样本中的特征较多时,设置适当的最大深度可以防止模型过拟合。
clf_entropy = tree.DecisionTreeClassifier(criterion = 'entropy') #按照信息增益加载决策树模型
clf_gini = tree.DecisionTreeClassifier(criterion = 'gini',max_depth=2) #按照基尼系数加载决策树模型
# 3.训练模型
clf_entropy.fit(iris.data[:120], iris.target[:120]) #模型训练,取前五分之四作训练集
clf_gini.fit(iris.data[:120], iris.target[:120]) #模型训练,取前五分之四作训练集
# 4.模型预测
predictions_entropy = clf_entropy.predict(iris.data[120:]) # 模型测试,取后五分之一作测试集
predictions_gini = clf_gini.predict(iris.data[120:]) # 模型测试,取后五分之一作测试集
# 5.模型评估
print("ID3:")
print('Accuracy:%s'% accuracy_score(iris.target[120:], predictions_entropy))
print("CART:")
print('Accuracy:%s'% accuracy_score(iris.target[120:], predictions_gini))
实验结果:
2、威斯康星乳腺癌数据集预测
基于威斯康辛乳腺癌数据集,采用决策树的方法进行肿瘤预测。
【实验要求】
1.加载sklearn自带的威斯康星乳腺癌数据集,探索数据。
2.进行数据集分割。
3.配置决策树模型。
4.训练决策树模型。
5.模型预测。
6.模型评估。
7.参数调优。可以根据评估结果,对模型设置或调整为更优的参数,使评估结果更准确。
#作 者:Asita
#开发时间:2021/11/21 21:45
"""
【实验要求】
1.加载sklearn自带的威斯康星乳腺癌数据集,探索数据。
2.进行数据集分割。
3.配置决策树模型。
4.训练决策树模型。
5.模型预测。
6.模型评估。
7.参数调优。可以根据评估结果,对模型设置或调整为更优的参数,使评估结果更准确。
"""
from sklearn import tree # 导入决策树包
from sklearn.metrics import accuracy_score # 导入准确率评价指标
from sklearn.datasets import load_breast_cancer # 导入威斯康星乳腺癌数据集
import numpy as np
# 1.加载数据集:
breast_cancer = load_breast_cancer() # 载入数据集
# print('breast_cancer部分数据集特征')
# print(breast_cancer.data[:10])
# print(breast_cancer.data.shape) # 569*30
# 2.配置模型
clf_gini = tree.DecisionTreeClassifier(criterion = 'gini',max_depth=2) #按照基尼系数加载决策树模型
#3.训练模型
clf_gini.fit(breast_cancer.data[:500], breast_cancer.target[:500]) #模型训练,取前80%作训练集
# 4.模型预测
predictions_gini = clf_gini.predict(breast_cancer.data[500:]) # 模型测试,取后20%作测试集
print("predictions_gini",predictions_gini)
#5.模型评估
print("CART:")
print('Accuracy:%s'% accuracy_score(breast_cancer.target[500:], predictions_gini))
errArr = np.mat(np.ones((len(breast_cancer.data[500:]), 1)))
LabelArr=breast_cancer.target[500:]
predictions_gini=np.mat(predictions_gini).T
# print(predictions_gini)
# print(np.mat(LabelArr).T)
print("TP: ",errArr[(predictions_gini == 1) & (predictions_gini == np.mat(LabelArr).T)].sum())
print("FP: ",errArr[(predictions_gini == 1) & (predictions_gini != np.mat(LabelArr).T)].sum())
print("TN: ",errArr[(predictions_gini == 0) & (predictions_gini == np.mat(LabelArr).T)].sum())
print("FN: ",errArr[(predictions_gini == 0) & (predictions_gini != np.mat(LabelArr).T)].sum())
运行结果:

因为该数据集是的每个样本含有30个特征,因此决策树选择的是基尼系数实现的决策树。
这是只对决策树最大深度进行了调优,当决策树最大深度为2时,Accuracy最高。
加上决策树可视化后的完整代码:
#作 者:Asita
#开发时间:2021/11/21 21:45
"""
【实验要求】
1.加载sklearn自带的威斯康星乳腺癌数据集,探索数据。
2.进行数据集分割。
3.配置决策树模型。
4.训练决策树模型。
5.模型预测。
6.模型评估。
7.参数调优。可以根据评估结果,对模型设置或调整为更优的参数,使评估结果更准确。
"""
from sklearn import tree # 导入决策树包
from sklearn.metrics import accuracy_score # 导入准确率评价指标
from sklearn.datasets import load_breast_cancer # 导入威斯康星乳腺癌数据集
import numpy as np
import matplotlib.pyplot as plt
import graphviz
def showDataSet(dataMat, labelMat):
"""
数据可视化
Parameters:
dataMat - 数据矩阵
labelMat - 数据标签
Returns:
无
"""
data_plus = [] #正样本
data_minus = [] #负样本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) #转换为numpy矩阵
data_minus_np = np.array(data_minus) #转换为numpy矩阵
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) #正样本散点图
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) #负样本散点图
plt.show()
# 1.加载数据集:
breast_cancer = load_breast_cancer() # 载入数据集
# print('breast_cancer部分数据集特征')
# print(breast_cancer.data[:10])
# print(breast_cancer.data.shape) # 569*30
# 2.配置模型
clf_gini = tree.DecisionTreeClassifier(criterion = 'gini',max_depth=2) #按照基尼系数加载决策树模型
#3.训练模型
clf_gini.fit(breast_cancer.data[:500], breast_cancer.target[:500]) #模型训练,取前80%作训练集
# 4.模型预测
predictions_gini = clf_gini.predict(breast_cancer.data[500:]) # 模型测试,取后20%作测试集
print("predictions_gini",predictions_gini)
#5.模型评估
print("CART:")
print('Accuracy:%s'% accuracy_score(breast_cancer.target[500:], predictions_gini))
errArr = np.mat(np.ones((len(breast_cancer.data[500:]), 1)))
LabelArr=breast_cancer.target[500:]
predictions_gini=np.mat(predictions_gini).T
# print(predictions_gini)
# print(np.mat(LabelArr).T)
showDataSet(breast_cancer.data[:500],breast_cancer.target[:500]) # 训练集
showDataSet(breast_cancer.data[500:],breast_cancer.target[500:]) # 测试集
print("TP: ",errArr[(predictions_gini == 1) & (predictions_gini == np.mat(LabelArr).T)].sum())
print("FP: ",errArr[(predictions_gini == 1) & (predictions_gini != np.mat(LabelArr).T)].sum())
print("TN: ",errArr[(predictions_gini == 0) & (predictions_gini == np.mat(LabelArr).T)].sum())
print("FN: ",errArr[(predictions_gini == 0) & (predictions_gini != np.mat(LabelArr).T)].sum())
# 决策树可视化
feature_name = ['mean radius', 'mean texture',
'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness',
'mean concavity', 'mean concave points',
'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error',
'perimeter error', 'area error',
'smoothness error', 'compactness error',
'concavity error', 'concave points error',
'symmetry error', 'fractal dimension error',
'worst radius', 'worst texture',
'worst perimeter', 'worst area',
'worst smoothness', 'worst compactness',
'worst concavity', 'worst concave points',
'worst symmetry', 'worst fractal dimension']
class_name = ['Not', 'Is']
treeAB_d4_dot = tree.export_graphviz(
clf_gini
, out_file=None
, feature_names=feature_name
, class_names=class_name
)
graph = graphviz.Source(treeAB_d4_dot)
print(graph)
graph.render("F:/研究生/课程/机器学习/practice/TreeForAgeAndBalanceD4")
训练集:

测试集:

这里为了让生成的决策树显得更直观,设置的决策树最深长度为10,而不是最优的深度2:

3、顾客购买服装数据集
采用决策树算法,对“双十一”期间顾客是否买服装的数据集进行分析与预测。
顾客购买服装数据集:包含review(商品评价变量)、discount(打折程度)、needed(是否必需)、shipping(是否包邮)、buy(是否购买)。
【实验要求】
1.读取顾客购买服装的数据集(3_buy.csv),探索数据。
2.分别用ID3 算法和CART 算法进行决策树模型的配置、模型的训练、模型的预测、模型的评估。
3.扩展内容(选做):对不同算法生成的决策树结构图进行可视化。
#作 者:Asita
#开发时间:2021/11/24 16:24
"""
采用决策树算法,对“双十一”期间顾客是否买服装的数据集进行分析与预测。
顾客购买服装数据集:包含review(商品评价变量)、discount(打折程度)、needed(是否必需)、shipping(是否包邮)、buy(是否购买)。
【实验要求】
1.读取顾客购买服装的数据集(3_buy.csv),探索数据。
2.分别用ID3 算法和CART 算法进行决策树模型的配置、模型的训练、模型的预测、模型的评估。
3.扩展内容(选做):对不同算法生成的决策树结构图进行可视化。
"""
import graphviz
import numpy as np
from sklearn import tree
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
def showDataSet(dataMat, labelMat):
"""
数据可视化
Parameters:
dataMat - 数据矩阵
labelMat - 数据标签
Returns:
无
"""
data_plus = [] #正样本
data_minus = [] #负样本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) #转换为numpy矩阵
data_minus_np = np.array(data_minus) #转换为numpy矩阵
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) #正样本散点图
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) #负样本散点图
plt.show()
#1.获取数据
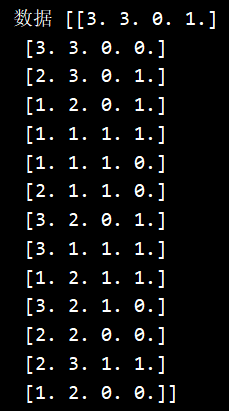
path = 'F:/研究生/课程/机器学习/决策树/3_buy.csv' # 14*5
data = (np.recfromcsv(path))
datamat = np.zeros((14,5))
for i in range (14):
for j in range(5):
datamat[i][j]=data[i][j]
# print(datamat)
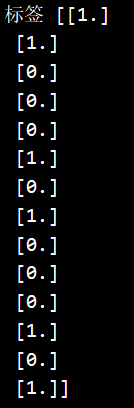
# 2.划分数据与标签
# indices_or_sections: 如果是一个整数,就用该数平均切分,如果是一个数组,为沿轴切分的位置(左开右闭)
x, y = np.split(datamat, indices_or_sections=(4,), axis=1) # x为数据,y为标签 , axis=1表示纵向切分,默认为0(横向)
# print(x)
# print(y)
# 3.划分测试集和训练集
# train_data, test_data, train_label, test_label = train_test_split(x, y, random_state=2, train_size=0.6,
# test_size=0.4) # sklearn.model_selection.
train_data = x[:10,:]
train_label = y[:10,:]
test_data = x[10:,:]
test_label = y[10:,:]
print("train_data",train_data)
print("train_label",train_label)
print("test_data",test_data)
print("test_label",test_label)
# 4.配置模型
clf_gini = tree.DecisionTreeClassifier(criterion = 'gini',max_depth=4) #按照基尼系数决策树模型
clf_ID3 = tree.DecisionTreeClassifier(criterion = 'entropy',max_depth=4) #按照ID3加载决策树模型
#5.训练模型
clf_gini.fit(train_data, train_label) #模型训练
clf_ID3.fit(train_data, train_label) #模型训练
# 6.模型预测
predictions_gini = clf_gini.predict(test_data) # 模型测试
print("predictions_gini",predictions_gini)
predictions_ID3 = clf_ID3.predict(test_data) # 模型测试
print("predictions_ID3",predictions_ID3)
#7.模型评估
errArr = np.mat(np.ones((len(test_data), 1)))
predictions_gini=np.mat(predictions_gini).T
predictions_ID3=np.mat(predictions_ID3).T
showDataSet(train_data,train_label) # 训练集
showDataSet(test_data,test_label) # 测试集
print("CART:")
print('Accuracy:%s'% accuracy_score(test_label, predictions_gini))
print("TP: ",errArr[(predictions_gini == 1) & (predictions_gini == np.mat(test_label))].sum())
print("FP: ",errArr[(predictions_gini == 1) & (predictions_gini != np.mat(test_label))].sum())
print("TN: ",errArr[(predictions_gini == 0) & (predictions_gini == np.mat(test_label))].sum())
print("FN: ",errArr[(predictions_gini == 0) & (predictions_gini != np.mat(test_label))].sum())
print("ID3:")
print('Accuracy:%s'% accuracy_score(test_label, predictions_ID3))
print("TP: ",errArr[(predictions_ID3 == 1) & (predictions_ID3 == np.mat(test_label))].sum())
print("FP: ",errArr[(predictions_ID3 == 1) & (predictions_ID3 != np.mat(test_label))].sum())
print("TN: ",errArr[(predictions_ID3 == 0) & (predictions_ID3 == np.mat(test_label))].sum())
print("FN: ",errArr[(predictions_ID3 == 0) & (predictions_ID3 != np.mat(test_label))].sum())
#8.数据可视化
feature_name=['revie','discount','needed','shipping']
class_name = ['buy', 'Not buy']
tree_gini = tree.export_graphviz(
clf_gini
, out_file=None
, feature_names=feature_name
, class_names=class_name
)
graph = graphviz.Source(tree_gini)
graph.render("F:/研究生/课程/机器学习/practice/tree_ID3")
tree_ID3 = tree.export_graphviz(
clf_ID3
, out_file=None
, feature_names=feature_name
, class_names=class_name
)
graph = graphviz.Source(tree_ID3)
graph.render("F:/研究生/课程/机器学习/practice/tree_gini")
数据集:
标签:
实验结果:

根据gini系数生成的决策树

根据ID3生成的决策树:
