卷积神经网络实现人脸识别微笑检测
一:卷积神经网络介绍:
1. 定义:
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 [1-2] 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)
CNN在以下几个领域均有不同程度的应用:
图像处理领域(最主要运用领域) —— 图像识别和物体识别,图像标注,图像主题生成,图像内容生成,物体标注等。
视频处理领域 —— 视频分类,视频标准,视频预测等
自然语言处理(NLP)领域 —— 对话生成,文本生成,机器翻译等
其它方面 —— 机器人控制,游戏,参数控制等
卷积神经网络(Convolutional Neural Networks / CNNs / ConvNets)与普通神经网络非常相似,它们都由具有可学习的权重和偏置常量(biases)的神经元组成。每个神经元都接收一些输入,并做一些点积计算,输出是每个分类的分数,普通神经网络里的一些计算技巧到这里依旧适用。
2.卷积神经网络与普通神经网络的不同点
具有三维体积的神经元(3D volumes of neurons)
卷积神经网络利用输入是图片的特点,把神经元设计成三个维度 : width, height, depth(注意这个depth不是神经网络的深度,而是用来描述神经元的) 。比如输入的图片大小是 32 × 32 × 3 (rgb),那么输入神经元就也具有 32×32×3 的维度。下面是图解:
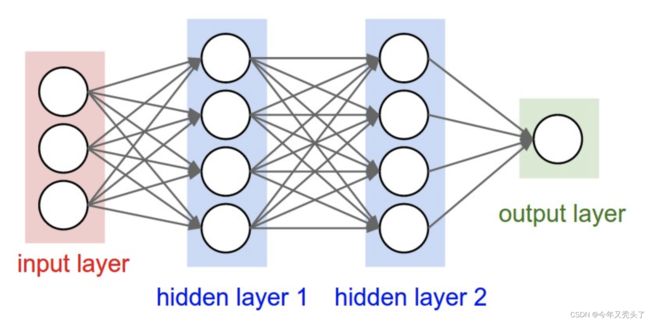
传统神经网络

一个卷积神经网络由很多层组成,它们的输入是三维的,输出也是三维的,有的层有参数,有的层不需要参数。
3.结构
网络结构
卷积神经网络整体架构:卷积神经网络是一种多层的监督学习神经网络,隐含层的卷积层和池采样层是实现卷积神经网络特征提取功能的核心模块。该网络模型通过采用梯度下降法最小化损失函数对网络中的权重参数逐层反向调节,通过频繁的迭代训练提高网络的精度。卷积神经网络的低隐层是由卷积层和最大池采样层交替组成,高层是全连接层对应传统多层感知器的隐含层和逻辑回归分类器。第一个全连接层的输入是由卷积层和子采样层进行特征提取得到的特征图像。最后一层输出层是一个分类器,可以采用逻辑回归,Softmax回归甚至是支持向量机对输入图像进行分类。
卷积神经网络结构包括:卷积层,降采样层,全链接层。每一层有多个特征图,每个特征图通过一种卷积滤波器提取输入的一种特征,每个特征图有多个神经元。
输入图像统计和滤波器进行卷积之后,提取该局部特征,一旦该局部特征被提取出来之后,它与其他特征的位置关系也随之确定下来了,每个神经元的输入和前一层的局部感受野相连,每个特征提取层都紧跟一个用来求局部平均与二次提取的计算层,也叫特征映射层,网络的每个计算层由多个特征映射平面组成,平面上所有的神经元的权重相等。
通常将输入层到隐藏层的映射称为一个特征映射,也就是通过卷积层得到特征提取层,经过pooling之后得到特征映射层。
3.主要层次介绍
a:卷积层:卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
b:线性整流层:这一层神经的活性化函数(Activation function)使用线性整流(Rectified Linear Units, ReLU)f(x)=max(0,x)。
c:池化层:通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
d:全连接层: 把所有局部特征结合变成全局特征,用来计算最后每一类的得分。

池化(pool)即下采样(downsamples),目的是为了减少特征图。池化操作对每个深度切片独立,规模一般为 2*2,相对于卷积层进行卷积运算,池化层进行的运算一般有以下几种:
* 最大池化(Max Pooling)。取4个点的最大值。这是最常用的池化方法。
* 均值池化(Mean Pooling)。取4个点的均值。
* 高斯池化。借鉴高斯模糊的方法。不常用。
* 可训练池化。训练函数 ff ,接受4个点为输入,出入1个点。不常用。
最常见的池化层是规模为2*2, 步幅为2,对输入的每个深度切片进行下采样。每个MAX操作对四个数进行,如下图所示: 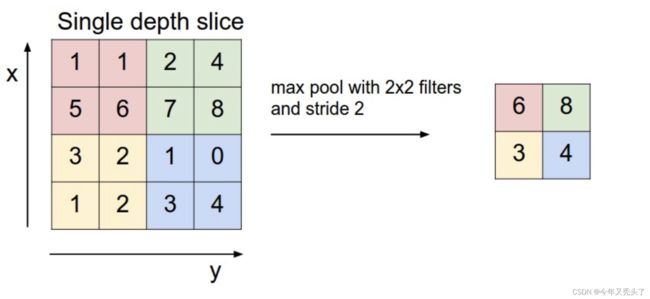
池化层总结(Summary)
接收单元大小为:W1∗H1∗D1
需要两个参数(hyperparameters):
their spatial extent F
,
the stride S
,
输出大小:W2∗H2∗D2
,其中:
W2=W1−FS
H2=H1−FS+1
D2=D1
不需要引入新权重
4. 如何利用CNN实现图像识别的任务:
输入层读入经过规则化(统一大小)的图像,每一层的每个神经元将前一层的一组小的局部近邻的单元作为输入,也就是局部感受野和权值共享,神经元抽取一些基本的视觉特征,比如边缘、角点等,这些特征之后会被更高层的神经元所使用。卷积神经网络通过卷积操作获得特征图,每个位置,来自不同特征图的单元得到各自不同类型的特征。一个卷积层中通常包含多个具有不同权值向量的特征图,使得能够保留图像更丰富的特征。卷积层后边会连接池化层进行降采样操作,一方面可以降低图像的分辨率,减少参数量,另一方面可以获得平移和形变的鲁棒性。卷积层和池化层的交替分布,使得特征图的数目逐步增多,而且分辨率逐渐降低,是一个双金字塔结构。
5.CNN的优缺点:
优点
① 使用局部感知和参数共享机制(共享卷积核), 对于较大的数据集处理能力较高.对高维数据的处理没有压力
② 能够提取图像的深层次的信息,模型表达效果好.
③ 不需要手动进行特征选择, 只要训练好卷积核W和偏置项b, 即可得到特征值.
缺点
① 需要进行调参, 模型训练时间较长, 需要的样本较多, 一般建议使用GPU进行模型训练.
② 物理含义不明, 每层中的结果无法解释, 这也是神经网络的共有的缺点.
二:在python环境下实现:
1.下载genki-4k数据集
2.对图片进行预处理:
import dlib # 人脸识别的库dlib
import numpy as np # 数据处理的库numpy
import cv2 # 图像处理的库OpenCv
import os
# dlib预测器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('D:\\shape_predictor_68_face_landmarks.dat')
# 读取图像的路径
path_read = "D:\\rgzn\\jupyter\\genki4k\\files"
num=0
for file_name in os.listdir(path_read):
#aa是图片的全路径
aa=(path_read +"/"+file_name)
#读入的图片的路径中含非英文
img=cv2.imdecode(np.fromfile(aa, dtype=np.uint8), cv2.IMREAD_UNCHANGED)
#获取图片的宽高
img_shape=img.shape
img_height=img_shape[0]
img_width=img_shape[1]
# 用来存储生成的单张人脸的路径
path_save="D:\\rgzn\\jupyter\\genki4k\\files1"
# dlib检测
dets = detector(img,1)
print("人脸数:", len(dets))
for k, d in enumerate(dets):
if len(dets)>1:
continue
num=num+1
# 计算矩形大小
# (x,y), (宽度width, 高度height)
pos_start = tuple([d.left(), d.top()])
pos_end = tuple([d.right(), d.bottom()])
# 计算矩形框大小
height = d.bottom()-d.top()
width = d.right()-d.left()
# 根据人脸大小生成空的图像
img_blank = np.zeros((height, width, 3), np.uint8)
for i in range(height):
if d.top()+i>=img_height:# 防止越界
continue
for j in range(width):
if d.left()+j>=img_width:# 防止越界
continue
img_blank[i][j] = img[d.top()+i][d.left()+j]
img_blank = cv2.resize(img_blank, (200, 200), interpolation=cv2.INTER_CUBIC)
cv2.imencode('.jpg', img_blank)[1].tofile(path_save+"\\"+"file"+str(num)+".jpg") #正确方法
识别照片:
3.划分数据集:
import os, shutil
# 原始数据集路径
original_dataset_dir = 'D:\\rgzn\\jupyter\\genki4k\\files1'
# 新的数据集
base_dir = 'D:\\rgzn\\jupyter\\genki4k\\files2'
os.mkdir(base_dir)
# 训练图像、验证图像、测试图像的目录
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir, 'smile')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'unsmile')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir, 'smile')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'unsmile')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir, 'smile')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'unsmile')
os.mkdir(test_dogs_dir)
# 复制1000张笑脸图片到train_c_dir
fnames = ['file{}.jpg'.format(i) for i in range(1,900)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['file{}.jpg'.format(i) for i in range(900, 1350)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# Copy next 500 cat images to test_cats_dir
fnames = ['file{}.jpg'.format(i) for i in range(1350, 1800)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['file{}.jpg'.format(i) for i in range(2127,3000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# Copy next 500 dog images to validation_dogs_dir
fnames = ['file{}.jpg'.format(i) for i in range(3000,3878)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# Copy next 500 dog images to test_dogs_dir
fnames = ['file{}.jpg'.format(i) for i in range(3000,3878)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)

4.CNN提取人脸识别笑脸和非笑脸:
#创建模型
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()#查看

归一化处理:
#归一化
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen=ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 目标文件目录
train_dir,
#所有图片的size必须是150x150
target_size=(150, 150),
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
for data_batch, labels_batch in train_generator:
print('data batch shape:', data_batch.shape)
print('labels batch shape:', labels_batch)
break
#'smile': 0, 'unsmile': 15.数据增强:
#数据增强
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
#数据增强后图片变化
import matplotlib.pyplot as plt
# This is module with image preprocessing utilities
from keras.preprocessing import image
fnames = [os.path.join(train_smile_dir, fname) for fname in os.listdir(train_smile_dir)]
img_path = fnames[3]
img = image.load_img(img_path, target_size=(150, 150))
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
6.创建网络:
#创建网络
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
#归一化处理
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=60,
validation_data=validation_generator,
validation_steps=50)
model.save('smileAndUnsmile1.h5')
#数据增强过后的训练集与验证集的精确度与损失度的图形
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
7.图片测试:
# 单张图片进行判断 是笑脸还是非笑脸
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
#加载模型
model = load_model('smileAndUnsmile1.h5')
#本地图片路径
img_path='test.jpg'
img = image.load_img(img_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)/255.0
img_tensor = np.expand_dims(img_tensor, axis=0)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]>0.5:
result='非笑脸'
else:
result='笑脸'
print(result)
运行结果:

8.摄像头实时测试:
#检测视频或者摄像头中的人脸
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model('smileAndUnsmile1.h5')
detector = dlib.get_frontal_face_detector()
video=cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dets=detector(gray,1)
if dets is not None:
for face in dets:
left=face.left()
top=face.top()
right=face.right()
bottom=face.bottom()
cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2)
img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150))
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img1 = np.array(img1)/255.
img_tensor = img1.reshape(-1,150,150,3)
prediction =model.predict(img_tensor)
if prediction[0][0]>0.5:
result='unsmile'
else:
result='smile'
cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('Video', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()三:个人总结:
通过这次对卷积网络的学习,自己也有很多的收获,CNN有两个特点:第一个是能够有效的将大量数据转化为小的数据量,第二个是能够有效的保留完整的图片特征,符合图片处理的原则,在没有使用CNN卷积神经网络之前,人工智能对于图片的处理一直存在一些问题,第一是需要处理的数据量太大了,导致成本太高,但是效率又太低了,其次就是数据在处理的过程中很难保持原有的特征,进而导致数据处理的准确率不够高,卷积神经网络就刚好解决了这种问题,同时,降维又不会影响结果,比如1000像素的图片缩小成200像素,并不会影响肉眼识别出来的结果。在学习python dlib库对人脸特征进行提取,进而再到卷积神经网络人脸识别,这些都让我感觉学习的东西和自己很近,也能激发我的兴趣去学习,学习中的难点就在于对软件的应用不够熟练,以及对库的使用上,今后还需要再多加努力!