Jetson Nano踩坑记录贴其五
Jetson Nano踩坑记录贴——程序源码及其自启动
- 前言
- 一、程序源码
- 二、自启动
-
- 1.执行自启动
- 2.赋予权限
前言
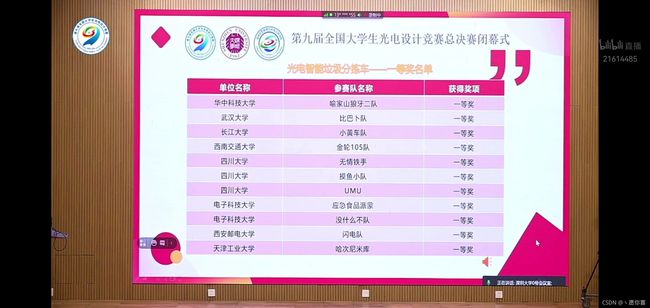
本次比赛顺利结束,最终也成功拿下了全国一等奖,在此我将本次使用的代码进行开源,主要功能就是开机时自启动nano中的识别程序,并将识别结果通过串口输出。踩坑记录贴也将到此为止。同时在使用此自启动程序时最好提前将ssh配置好,以避免后续无法进入gui界面。
一、程序源码
yolodetect.py
import time
import cv2
import pycuda.autoinit # This is needed for initializing CUDA driver
import numpy as np
import ctypes
import tensorrt as trt
import pycuda.driver as cuda
import threading
import random
import serial as ser
import struct,time
INPUT_W = 416
INPUT_H = 416
CONF_THRESH = 0.2
IOU_THRESHOLD = 0.4
se = ser.Serial('/dev/ttyTHS1',115200,timeout=1) #选择串口及波特率
categories = ['0','1','2','3','4'] #修改为自己的模型标签
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
def draw_boxes(image_raw, result_boxes, result_scores, result_classid):
for i in range(len(result_boxes)):
box = result_boxes[i]
plot_one_box(
box,
image_raw,
label="{}:{:.2f}".format(
categories[int(result_classid[i])], result_scores[i]
),
)
return image_raw
class YoLov5TRT(object):
"""
description: A YOLOv5 class that warps TensorRT ops, preprocess and postprocess ops.
"""
def __init__(self, engine_file_path):
# Create a Context on this device,
self.cfx = cuda.Device(0).make_context()
stream = cuda.Stream()
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
runtime = trt.Runtime(TRT_LOGGER)
# Deserialize the engine from file
with open(engine_file_path, "rb") as f:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
host_inputs = []
cuda_inputs = []
host_outputs = []
cuda_outputs = []
bindings = []
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(cuda_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
host_inputs.append(host_mem)
cuda_inputs.append(cuda_mem)
else:
host_outputs.append(host_mem)
cuda_outputs.append(cuda_mem)
# Store
self.stream = stream
self.context = context
self.engine = engine
self.host_inputs = host_inputs
self.cuda_inputs = cuda_inputs
self.host_outputs = host_outputs
self.cuda_outputs = cuda_outputs
self.bindings = bindings
# 释放引擎,释放GPU显存,释放CUDA流
def __del__(self):
print("delete object to release memory")
def infer(self, image_raw):
threading.Thread.__init__(self)
# Make self the active context, pushing it on top of the context stack.
self.cfx.push()
# Restore
stream = self.stream
context = self.context
engine = self.engine
host_inputs = self.host_inputs
cuda_inputs = self.cuda_inputs
host_outputs = self.host_outputs
cuda_outputs = self.cuda_outputs
bindings = self.bindings
# Do image preprocess
input_image, image_raw, origin_h, origin_w = self.preprocess_image(
image_raw
)
# Copy input image to host buffer
np.copyto(host_inputs[0], input_image.ravel())
# Transfer input data to the GPU.
cuda.memcpy_htod_async(cuda_inputs[0], host_inputs[0], stream)
# Run inference.
context.execute_async(bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
cuda.memcpy_dtoh_async(host_outputs[0], cuda_outputs[0], stream)
# Synchronize the stream
stream.synchronize()
# Remove any context from the top of the context stack, deactivating it.
self.cfx.pop()
# Here we use the first row of output in that batch_size = 1
output = host_outputs[0]
# Do postprocess
result_boxes, result_scores, result_classid = self.post_process(
output, origin_h, origin_w
)
return image_raw, result_boxes, result_scores, result_classid
def destroy(self):
# Remove any context from the top of the context stack, deactivating it.
self.cfx.pop()
def preprocess_image(self, image_raw):
"""
description: Read an image from image path, convert it to RGB,
resize and pad it to target size, normalize to [0,1],
transform to NCHW format.
param:
input_image_path: str, image path
return:
image: the processed image
image_raw: the original image
h: original height
w: original width
"""
h, w, c = image_raw.shape
image = cv2.cvtColor(image_raw, cv2.COLOR_BGR2RGB)
# Calculate widht and height and paddings
r_w = INPUT_W / w
r_h = INPUT_H / h
if r_h > r_w:
tw = INPUT_W
th = int(r_w * h)
tx1 = tx2 = 0
ty1 = int((INPUT_H - th) / 2)
ty2 = INPUT_H - th - ty1
else:
tw = int(r_h * w)
th = INPUT_H
tx1 = int((INPUT_W - tw) / 2)
tx2 = INPUT_W - tw - tx1
ty1 = ty2 = 0
# Resize the image with long side while maintaining ratio
image = cv2.resize(image, (tw, th))
# Pad the short side with (128,128,128)
image = cv2.copyMakeBorder(
image, ty1, ty2, tx1, tx2, cv2.BORDER_CONSTANT, (128, 128, 128)
)
image = image.astype(np.float32)
# Normalize to [0,1]
image /= 255.0
# HWC to CHW format:
image = np.transpose(image, [2, 0, 1])
# CHW to NCHW format
image = np.expand_dims(image, axis=0)
# Convert the image to row-major order, also known as "C order":
image = np.ascontiguousarray(image)
return image, image_raw, h, w
def xywh2xyxy(self, origin_h, origin_w, x):
"""
description: Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
param:
origin_h: height of original image
origin_w: width of original image
x: A boxes tensor, each row is a box [center_x, center_y, w, h]
return:
y: A boxes tensor, each row is a box [x1, y1, x2, y2]
"""
# y = torch.zeros_like(x) if isinstance(x, torch.Tensor) else np.zeros_like(x)
y = np.zeros_like(x)
r_w = INPUT_W / origin_w
r_h = INPUT_H / origin_h
if r_h > r_w:
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2 - (INPUT_H - r_w * origin_h) / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2 - (INPUT_H - r_w * origin_h) / 2
y /= r_w
else:
y[:, 0] = x[:, 0] - x[:, 2] / 2 - (INPUT_W - r_h * origin_w) / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2 - (INPUT_W - r_h * origin_w) / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
y /= r_h
return y
def nms(self, boxes, scores, iou_threshold=IOU_THRESHOLD):
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
areas = (y2 - y1 + 1) * (x2 - x1 + 1)
scores = scores
keep = []
index = scores.argsort()[::-1]
while index.size > 0:
i = index[0] # every time the first is the biggst, and add it directly
keep.append(i)
x11 = np.maximum(x1[i], x1[index[1:]]) # calculate the points of overlap
y11 = np.maximum(y1[i], y1[index[1:]])
x22 = np.minimum(x2[i], x2[index[1:]])
y22 = np.minimum(y2[i], y2[index[1:]])
w = np.maximum(0, x22 - x11 + 1) # the weights of overlap
h = np.maximum(0, y22 - y11 + 1) # the height of overlap
overlaps = w * h
ious = overlaps / (areas[i] + areas[index[1:]] - overlaps)
idx = np.where(ious <= iou_threshold)[0]
index = index[idx + 1] # because index start from 1
return keep
def post_process(self, output, origin_h, origin_w):
"""
description: postprocess the prediction
param:
output: A tensor likes [num_boxes,cx,cy,w,h,conf,cls_id, cx,cy,w,h,conf,cls_id, ...]
origin_h: height of original image
origin_w: width of original image
return:
result_boxes: finally boxes, a boxes tensor, each row is a box [x1, y1, x2, y2]
result_scores: finally scores, a tensor, each element is the score correspoing to box
result_classid: finally classid, a tensor, each element is the classid correspoing to box
"""
# Get the num of boxes detected
num = int(output[0])
# Reshape to a two dimentional ndarray
pred = np.reshape(output[1:], (-1, 6))[:num, :]
# to a torch Tensor
# pred = torch.Tensor(pred).cuda()
# Get the boxes
boxes = pred[:, :4]
# Get the scores
scores = pred[:, 4]
# Get the classid
classid = pred[:, 5]
# Choose those boxes that score > CONF_THRESH
si = scores > CONF_THRESH
boxes = boxes[si, :]
scores = scores[si]
classid = classid[si]
# Trandform bbox from [center_x, center_y, w, h] to [x1, y1, x2, y2]
boxes = self.xywh2xyxy(origin_h, origin_w, boxes)
# Do nms
# indices = torchvision.ops.nms(boxes, scores, iou_threshold=IOU_THRESHOLD).cpu()
# result_boxes = boxes[indices, :].cpu()
# result_scores = scores[indices].cpu()
# result_classid = classid[indices].cpu()
# return result_boxes, result_scores, result_classid
indices = self.nms(boxes, scores, IOU_THRESHOLD)
result_boxes = boxes[indices, :]
result_scores = scores[indices]
result_classid = classid[indices]
return result_boxes, result_scores, result_classid
def detect_one(img, yolov5_wrapper):
full_scrn = False
tic = time.clock()
##开始检测,并将结果写到result.jpg中
img, result_boxes, result_scores, result_classid = yolov5_wrapper.infer(img)
toc = time.clock()
curr_fps = (toc - tic)
print("boxes: "+str(result_boxes))
print("clss: "+str(result_classid))
print("confs: "+str(result_scores))
img = draw_boxes(img, result_boxes, result_scores, result_classid)
cv2.imwrite("result.jpg",img)
print("time: "+str(curr_fps)+"(sec)")
def main_one():
filename = "1.jpg"
img = cv2.imread(filename)
# load custom plugins
PLUGIN_LIBRARY = "yolov5s/libmyplugins.so"
ctypes.CDLL(PLUGIN_LIBRARY)
engine_file_path = "yolov5s/yolov5s.engine"
# a YoLov5TRT instance
yolov5_wrapper = YoLov5TRT(engine_file_path)
print("start detection!")
detect_one(img, yolov5_wrapper)
cv2.destroyAllWindows()
print("finish!")
def detect_camera(camera, yolov5_wrapper):
#cnt=0
##开始循环检测
while True:
ret,img = camera.read() # usb摄像头用这个
#img = camera.read()
img, result_boxes, result_scores, result_classid = yolov5_wrapper.infer(img)
img = draw_boxes(img, result_boxes, result_scores, result_classid)
if(len(result_classid)):
for i in range(len(result_classid)):
# cnt=cnt+1
# print(cnt)
if result_classid[i]==0: #识别标签为0
if(result_scores[i]>=0.26): #置信度大于0.26才输出
print("bottle") #打印,后期可删除
se.write('a'.encode('utf-8'))
else:
se.write('f'.encode('utf-8'))
elif result_classid[i]==1:
if(result_scores[i]>=0.26):
print("cup")
se.write('b'.encode('utf-8'))
else:
se.write('f'.encode('utf-8'))
elif result_classid[i]==2:
if(result_scores[i]>=0.26):
print("paper")
se.write('c'.encode('utf-8'))
else:
se.write('f'.encode('utf-8'))
elif result_classid[i]==3:
if(result_scores[i]>=0.26):
print("orange")
se.write('d'.encode('utf-8'))
else:
se.write('f'.encode('utf-8'))
elif result_classid[i]==4:
if(result_scores[i]>=0.63):
print("battery")
se.write('e'.encode('utf-8'))
else:
se.write('f'.encode('utf-8'))
else:
se.write('f'.encode('utf-8')) #未识别到任何标签
#cv2.namedWindow("result", 0)
#cv2.resizeWindow("result", 640, 480)
cv2.imshow("result", img)
if cv2.waitKey(1) == ord('q'):
break
def main_camera():
camera = cv2.VideoCapture(0) # usb摄像头用这个,也可以用jetcam中的usb接口
#camera = CSICamera(capture_device=0, width=224, height=224)
# load custom plugins
camera.set(3,640)
camera.set(4,480)
PLUGIN_LIBRARY = "build/libmyplugins.so"
ctypes.CDLL(PLUGIN_LIBRARY)
engine_file_path = "build/test723.engine" #第四章中获得的engine名
# YoLov5TRT instance
yolov5_wrapper = YoLov5TRT(engine_file_path)
print("start detection!")
detect_camera(camera, yolov5_wrapper)
camera.release() #使用cv方法打开摄像头才需要这句
cv2.destroyAllWindows()
print("\nfinish!")
if __name__=="__main__":
main_camera()
二、自启动
1.执行自启动
每次执行前需要开启串口,否则程序无法正常运行
task.sh
#!/bin/bash
#command content
sudo chmod 777 /dev/ttyTHS1 #使用程序里那个串口
cd /home/xiao/tensorrtx/yolov5
python3 yolodetect.py
exit 0
2.赋予权限
由于要开启串口,需要给与其执行sudo的权限
quanxian.sh
#! /bin/bash
echo '******' | sudo -S "./task.sh" #******修改为自己系统的密码
wait
exit 0