2、Jetson平台软件资源功能测试
什么是cuda
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题,cuda编程模型是一个异构模型,需要GPU和CPU协同工作,因为GPU有更多的运算核心,所以适合于数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,可以实现复杂的逻辑运算,因此适合于控制密集型任务。
一、基本功能测试
1、性能模式调节
nvpmodel是修改功率模式的命令
-q 查询当前工作模式
-m 设定当前工作模式(Jetson TX2可以设定0-3档)其中0档是最佳性能模式。
2、查询设备信息范例测试
我们可以先打开终端,然后执行下面的命令
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
3、GPU和CPU性能对比范例测试
打开终端,输入如下命令。
cd /usr/local/cuda/samples/5_Simulations/nbody
sudo make
./nbody
./nbody -cpu
注意在编译的时候需要一点时间,当停留一段时间时,不要误认为卡死了,其实是在编译中
效果如下:
该范例程序可以用来比较CPU和GPU处理图形渲染的性能,GPU模式和CPU模式之间的帧频相差了120倍。
4、TensorRT推理范例测试
cd /usr/src/tensorrt/samples
sudo make
../bin/sample_mnist
5、多媒体API范例测试
cd /home/nvidia/tegra_multimedia_api/samples/backend/
sudo make //可能此处已经编译好了,已经存在可执行程序了,因为这毕竟是官方的程序
./backend 1 ../../data/Video/sample_outdoor_car_1080p_10fps.h264 H264 --trt-deployfile ../../data/Model/GoogleNet_one_class/GoogleNet_modified_oneClass_halfHD.prototxt --trt-modelfile ../../data/Model/GoogleNet_one_class/GoogleNet_modified_oneClass_halfHD.caffemodel --trt-forcefp32 0 --trt-proc-interval 1 -fps 10
程序在第一次运行时需要先转换模型,会比较耗时,但是第二次执行的时候就很快了,具体效果如下所示:

二、人工智能应用测试
此处需要注意的是,要保证网络稳定,所以建议采用网线进行连接。
1、jetson-inference的下载和编译
sudo apt update //更新安装程序列表
sudo apt autoremove //移除无用程序
sudo apt upgrade //升级现有程序
sudo apt install cmake//cmake是一个跨平台的安装(编译工具),可以用简单的语言来描述所以平台的安装和编译过程
//下面是下载jetson-inference程序包并且更新submodule
makdir ~/workspace/
cd ~/work
git clone https://github.com/dusty-nv/jetson-inference
cd jetson-inference
git submodule update --init
//下面是完成jetson-inference 程序的预编译工作
mkdir build
cd build
cmake ..
预编译的过程中可能会有下面的提示信息,此处点击yes。

然后会弹出两个对话框,第一个对话框是提示你要安装哪些的预训练模型,因为这些模型存储再国外的服务器上,下载时可能会有网络连接问题,所以直接点击Quit跳过下载过程。然后再到官网上手动下载。第二个对话框是确认是否要安装Pytorch及安装版本,按需选择。

上面的预编译工作完成之后,就可以用下面的命令编译jetson-inference了。
注意:一定要到build目录下进行编译。
sudo make -j4
编译的时候可能会遇到问题,见下一点的讲解。
2、下载和预编译执行过程中需要注意的问题:
①第一步可能会遇到的问题
E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable)
E: Unable to lock the administration directory (/var/lib/dpkg/), is another process using it?
这是什么原因呢?出现这个问题的原因可能是有另外一个程序正在运行,导致资源被锁不可用。而导致资源被锁的原因,可能是上次安装时没正常完成,然后强制取消了而导致出现此状况。下面是解决的办法:
找到并且杀掉所有的apt-get 和apt进程
ps -e | grep apt
然后发现该进程,当然这个是本人当时的情况。
13142 ? 00:00:00 apt.systemd.dai
最后用下面的命令结束进程
sudo kill -9 13142
然后再重新执行该命令
sudo apt update
下面大概介绍下如何删除锁定文件
锁定的文件会阻止 Linux 系统中某些文件或者数据的访问,这个概念也存在于 Windows 或者其他的操作系统中。一旦你运行了 apt-get 或者 apt 命令,锁定文件将会创建于 /var/lib/apt/lists/、/var/lib/dpkg/、/var/cache/apt/archives/ 中。这有助于运行中的 apt-get 或者 apt 进程能够避免被其它需要使用相同文件的用户或者系统进程所打断。当该进程执行完毕后,锁定文件将会删除。当你没有看到 apt-get 或者 apt 进程的情况下在上面两个不同的文件夹中看到了锁定文件,这是因为进程由于某个原因被杀掉了,因此你需要删除锁定文件来避免该错误。
首先运行下面的命令来移除 /var/lib/dpkg/ 文件夹下的锁定文件:
sudo rm /var/lib/dpkg/lock
之后像下面这样强制重新配置软件包:
sudo dpkg --configure -a
也可以删除 /var/lib/apt/lists/ 以及缓存文件夹下的锁定文件:
sudo rm /var/lib/apt/lists/lock
sudo rm /var/cache/apt/archives/lock
②为什么要git submodule update --init
git 的submodule 工具方便第三方库的管理,比如gitlab 上的各种开源工具,spdlog等在项目目录下创建.gitmodule 里可以添加第三方库,然后在更新第三方库时,有两个选项git submodule update --init 这是更新当前主项目上记录的submodule 的commitid,比如在提交子项目的时候,会在主项目产生变更,这个变更随着主项目一起的提交,也就是一一对应
Subproject commit 7d67b54340cebb4ffaa283ebf6975406f8ecda0d
Subproject commit 293633445da9133e959377bef8d61021d5cadc83
那么这个update --init 就会更新为主项目对应的版本,但是这种子项目提交的时候并不会修改.gitmodule里面的版本,这就是与remote的区别
,当使用git submodule update --remote的时候,子项目会根据.gitmodule的版本进行更新,当然以上是子项目的管理,对于第三方库的管理,那一般就是直接更新.gitmodule里的版本,自己不会动别的开发的东西也不会产生提交。
综上可见,如果clone 了一个含有子项目和第三方库的项目代码时,需要执行 git submodule update --remote 和 git submodule update --init 两个命令,或者调整先后,才能正确编译。
③

3、重要问题
我们再最后一步要编译的时候,可能会出现下面的问题
sudo make -j4
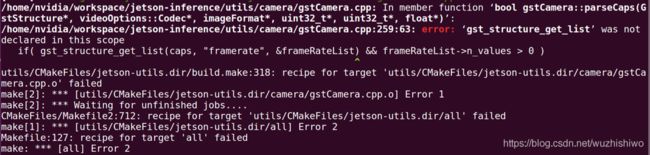
刚开始你可能会根据错误信息来去寻找问题,这个不是显然就是没有声明函数或者是命名空间的问题吗,那我们把头文件包含进去不就可以解决了,但是当你定位到该.cpp文件的时候,你会发现你该从何处寻找头文件呢?事实上,其实当其他问题发生时也会导致这个问题,也就是依赖问题,或者是版本问题。此处的解决方法是回到旧版本来解决的,因为本人用的是jetpack3.3, 但是事实上Jetpack 4.2都已经出了,所以一些开发者就会更新他们的代码以达到更好的性能,但是他们可能没有考虑兼容性的问题,所以这个 时候我们要回到旧的版本中去尝试下能不能编译通过。
此处在TX2上输入下面的命令查看分支,然后你会看到只有一个主分支,此时我们要切换到其他的分支,经过验证L4T-R28.1是可以通过百编译的。所以输入如下的命令:
git branch#查看分支的情况
git checkout L4T-R28.1#切换到该分支,可以打开https://github.com/wuzhishiwo/jetson-inference查看有哪些分支
然后就会有提示说:Branch L4T-R28.1 set up to track remote branch L4T-R28.1 from origin,此时我们已经切换到此分支下了

接着重新再编译一下:
make clean#编译之前不要忘记了清除一下之前的编译信息
sudo make -j4#此处一定不能漏了sudo,否则可能会导致编译不完整
4、有些指令为什么要执行?
(1)为什么需要cmke、make、makefile
在前面我们通过sudo apt install cmake安装了一个cmake的工具,那么它到底是什么呢?
①是什么?
CMake是一个跨平台的编译(Build)工具,可以用简单的语句来描述所有平台的编译过程。
②为什么需要它?它不能构建最终的软件,但是可以产生输出各种各样的makefile或者project文件。
假如我们有一个深度学习框架的部分工程列表,里面有超过40个互相调用的工程共同组成,一些用于生成库文件,一些用于实现逻辑功能。他们之间的调用关系复杂而严格,如果我想在这样复杂的框架下进行二次开发,显然只拥有它的源码是远远不够的,还需要清楚的明白这几十个项目之间的复杂关系,在没有原作者的帮助下进行这项工作几乎是不可能的。即使是原作者给出了相关的结构文档,对新手来说建立工程的过程依旧是漫长而艰辛的,因此CMake的作用就凸显出来了。原作者只需要生成一份CMakeLists.txt文档,框架的使用者们只需要在下载源码的同时下载作者提供的CMakeLists.txt,就可以利用CMake,在”原作者的帮助下“进行工程的搭建。
③输出了makefile文件后有什么用?
makefile定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为makefile就像一个Shell脚本一样,其中也可以执行操作系统的命令。makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。make是一个命令工具,是一个解释makefile中指令的命令工具。
④为什么需要makefile?
有效地描述这些文件之间的依赖关系以及处理命令,当个别文件改动后仅执行必要的处理,而不必重复整个编译过程,可以大大提高软件开发的效率。
⑤最终完整的实现逻辑
通过cmake编译cmakelist.txt生成了makefile文件,然后通过make工具就可以解释makefile最终生成可执行文件。
执行make就可以实现自动编译,执行make clean 就可以清楚编译产生的文件,本人博客的makefile专栏有简单的makefile编写,链接如下
(2)为什么make后面要加上-j4?
make -j带上一个参数,可以把项目在进行中并行编译,TX2是多核多线程的,所以完全可以用make -j4,让make最多允许4个编译进程同时执行,这样可以更有效的利用CPU资源。
(3)bulid的目录结构

5、图像分类范例测试
(1)下载模型
访问该网址可以下载一些一些预训练模型,然后该页面下下载GooleNet.tar.gz,默认保存到~/Downloads,然后执行下面的命令。
cd ~workspace/jetson-inference/data/networks
tar -xzf ~/Downloads/GooleNet.tar.gz
(2)模型推理
①查看摄像头的索引号
ls /dev/video*
![]()
如果系统同时接入了csi摄像头和usb摄像头,csi的索引号通常是0,而usb的是1。
如果使用的是csi摄像头,所以进行下面的操作。
cd ~workspace/jetson-inference/build/aarch64/bin
./imagenet-camera --network=goolenet --camera=0
如果使用的是usb的摄像头,则进行下面的操作
cd ~workspace/jetson-inference/build/aarch64/bin
./imagenet-camera --network=goolenet --camera=/dev/video0 --width=640 --height=480
–network用于指定预训练模型
–camera用于指定摄像头序号
–width参数是摄像头采集图像的宽度。一般默认是1280px
–height参数是摄像头采集图像的高度。一般默认是720px