独孤九剑第六式-支持向量机模型(SVM)
文章适合于所有的相关人士进行学习
各位看官看完了之后不要立刻转身呀
期待三连关注小小博主加收藏
小小博主回关快 会给你意想不到的惊喜呀
各位老板动动小手给小弟点赞收藏一下,多多支持是我更新得动力!!!
文章目录
-
- 前言
- SVM模型思想
-
-
- 模型介绍
- 距离的计算
- 模型思想介绍
- SVM目标函数
- 函数间隔
- 几何间隔
-
- SVM目标函数推导
-
-
- 目标函数推进
- 目标函数的等价转换
- 拉格朗日乘子法
-
- SVM线性可分和线性不可分函数介绍和实战
-
-
- 线性可分介绍
- 线性不可分函数介绍
- 实战介绍
-
- 数据
- 代码
- 数据
- 代码
-


前言
前面我们讲到了朴素贝叶斯模型的相关知识,从理论知识讲到了数学推导,然后对应三种分类器我们有分别讲了相关案例,详情请参考我们独孤九剑第五式。我们这次主要讲解另外一个重点模型,SVM-支持向量机模型,总而言之我觉得支持向量机有一种百里挑一,千里挑一甚至万里挑一这种思想,具体我们来看今天的讲解吧!

SVM模型思想
模型介绍
首先我们来看一个图:

上方的图我们很熟悉,属于一维图形,根据图中相关信息我们可以得到7500这个点将数据分为了左右两边。然后我们看第二个图,将维度上升到了二维,用了一条线来把数据点进行了分割,然后由上升到了三维,用了一个平面来把数据分了出来。那么继续上升维度呢?那么就引出了我们今天的第一个知识:
超平面:简单来说,就是到达了一定的维度之后,就是用超平面来分割数据点。
距离的计算
因为我们本次需要用到点到直线的相关公式来进行数学推导。
点到直线的数学公式:

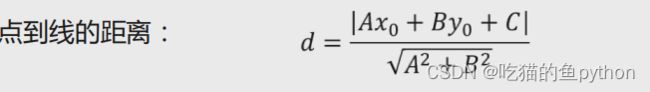
这里属于初中数学知识,这里不做过多介绍。
模型思想介绍
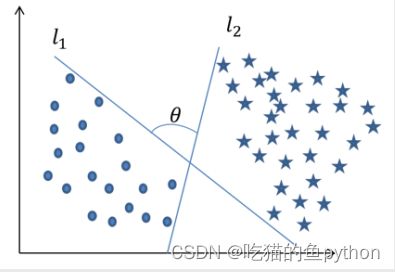
其实我们之前说的思想在我了解来说就是类似于百里挑一这种思想,就像这两个数据集,中间有很多线可以对其进行分割,SVM就是找一条最好的线来分割两个数据集,来达到模型最优。甚至在高维度的情况下,找出这样一个“超平面”来分割数据。
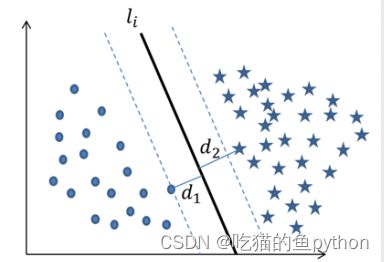
我们在这个过程中需要做三个步骤:
1.计算左右数据集所有的点距离这条直线的距离。
2.然后从所有的距离中我们找到左右两个数据集距离该直线最近的那个点。
3.然后找出画出分割带,在所有的直线中找出最大的那个分割带。
那么分割带又是什么呢?分割带又有什么作用呢?相信各位已经了解了,不过我还是要解释以下:

“分割带”代表了模型划分样本点的能力或可信度,“分割带”越宽,说明模型能够将样本点划分得越清晰,进而保证模型泛化能力越强,分类的可信度越高;反之,“分割带”越窄,说明模型的准确率越容易受到异常点的影响,进而理解为模型的预测能力越弱,分类的可信度越低。
SVM目标函数

其中,di表示样本i到某条固定分割面的距离;min(di)表示所有样本点与某个分割面之间距离的最小值;然后max就表示从这些分割面中找到分割带最宽的超平面;其中w和b就表示线性分割面的参数。这里我们先说一下就是:有了目标函数,有了参数,小伙伴们是不是猜到了我们该做什么,没错就是求偏导,然后求最小值,那么这是怎么引出来的呢?
函数间隔
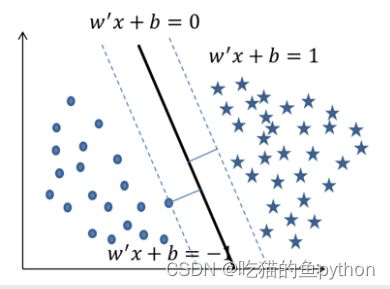
将图中的五角星所代表的正例样本用1表示,将实心圆所代表的负例样本用-1表示。实体加粗直线表示分割面,两条虚线表示因变量y取值为1和-1时的情况,他们与分割面平行。
不管是五角星还是实心圆,这些点都落于两条虚线上或者两条虚线外,则说明了这些点带入到方程上的绝对值一定大于等于1。进而说明了如果点对应的取值越小于-1,就说明是负例的可能性就越高,对应的点取值越大于1,则说明是正例的可能性就越大。
对应公式为:

其中yi表示样本点所属于的类别,用1和-1表示,如果是直线内容小于等于-1的时候,根据预测得到yi的值应该是-1,那么相乘的结果大于1.如果直线内容大于等于1的时候呢。根据预测得到的yi的值应该是1.最后相乘的结果还是大于等于1.
几何间隔
很容易理解,就是空间上的那点事呗!
当我们系数分别对应增加的时候,所对应的结果也是同比例增加的,但是对于分割面没有什么影响所以我们对公式进行了优化:

SVM目标函数推导
目标函数推进
我们把上方我们推导的公式带入到目标函数当中,得到:

目标函数的等价转换

对应的最大值我们还是不如最小值好求一点,所以我们将公式继续改进:

为了方便求导所以我们加入了1/2这项。w2的最小值,其实等价于求w倒数的最大值。
拉格朗日乘子法
首先我们来介绍这一相关数学知识:
假设存在一个需要最小化的函数f(x),并且该函数同时收到g(x)<=0的约束。如果需要得到最优化的解,那么需要利用拉格朗日对偶性将原始的最优化问题转化为对偶问题,即:
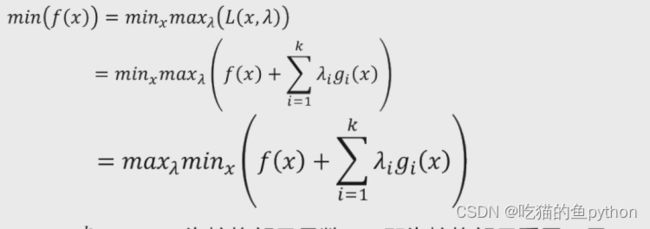
其中Lamda表示拉格朗日乘子。且大于0.
将目标函数带入到这个之中得到:

然后我们对其求偏导数得到:
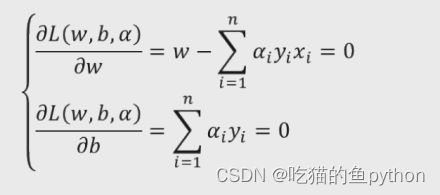
然后将偏导数w,b对应的值分别带入到原函数当中得到:

这里也很好理解吧,其实就是公式看着复杂,都是吓唬人的!!!

求解并且最终得到的参数的数值是:
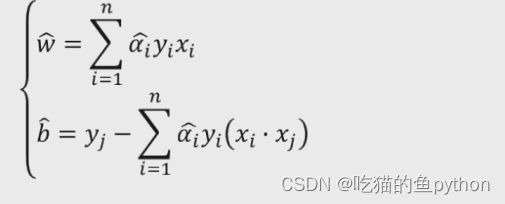
对于非线性可分我们的想法就是把它映射到更高维然后让他成功分出来对应的公式是:


和上面基本差不多的。
这里我们就把所有公式推导过程讲解完成了!
然后我们来介绍函数
SVM线性可分和线性不可分函数介绍和实战
线性可分介绍
LinearSVC(tol=0.0001, C=1.0, multi_class='ovr', fit_intercept=True, intercept_scaling=1,
class_weight=None, max_iter=1000)
tol:用于指定SVM模型迭代的收敛条件,默认为0.0001。 C:用于指定目标函数中松弛因子的惩罚系数值,默认为1。
fit_intercept:bool类型参数,是否拟合线性“超平面”的截距项,默认为True。
intercept_scaling:当参数fit_intercept为True时,该参数有效,通过给参数传递一个浮点值,就相当于在自变量X矩阵中添加一常数列,默认该参数值为1。
class_weight:用于指定因变量类别的权重,如果为字典,则通过字典的形式{class_label:weight}传递每个类别的权重;如果为字符串’balanced’,则每个分类的权重与实际样本中的比例成反比,当各分类存在严重不平衡时,设置为’balanced’会比较好;如果为None,则表示每个分类的权重相等。
max_iter:指定模型求解过程中的最大迭代次数,默认为1000
线性不可分函数介绍
SVC(C=1.0, kernel=‘rbf’, degree=3, gamma=‘auto’, coef0=0.0, tol=0.001,
class_weight=None, verbose=False, max_iter=-1, random_state=None)
C:用于指定目标函数中松弛因子的惩罚系数值,默认为1
kernel:用于指定SVM模型的核函数,该参数如果为’linear’,就表示线性核函数;如果为’poly’,就表示多项式核函数,核函数中的r和p值分别使用degree参数和gamma参数指定;如果为’rbf’,表示径向基核函数,核函数中的r参数值仍然通过gamma参数指定;如果为’sigmoid’,表示Sigmoid核函
数,核函数中的r参数值需要通过gamma参数指定;如果为’precomputed’,表示计算一个核矩阵
degree:用于指定多项式核函数中的p参数值 gamma:用于指定多项式核函数或径向基核函数或Sigmoid核函数中的r参数值
coef0:用于指定多项式核函数或Sigmoid核函数中的r参数值 tol:用于指定SVM模型迭代的收敛条件,默认为0.001
class_weight:用于指定因变量类别的权重,如果为字典,则通过字典的形式{class_label:weight}传递每个类别的权重;如果为字符串’balanced’,则每个分类的权重与实际样本中的比例成反比,当各分类存在严重不平衡时,设置为’balanced’会比较好;如果为None,则表示每个分类的权重相等
max_iter:指定模型求解过程中的最大迭代次数,默认为-1,表示不限制迭代次数
实战介绍
数据

代码
from sklearn import svm
import pandas as pd
from sklearn import model_selection
from sklearn import metrics
letters = pd.read_csv(r'letterdata.csv')
# 数据前5行
letters.head()
predictors = letters.columns[1:]
X_train,X_test,y_train,y_test = model_selection.train_test_split(letters[predictors], letters.letter,
test_size = 0.25, random_state = 1234)
linear_svc = svm.LinearSVC()
# 模型在训练数据集上的拟合
linear_svc.fit(X_train,y_train)
pred_linear_svc = linear_svc.predict(X_test)
# 模型的预测准确率
metrics.accuracy_score(y_test, pred_linear_svc)
#非线性拟合
nolinear_svc = svm.SVC(kernel='rbf')
# 模型在训练数据集上的拟合
nolinear_svc.fit(X_train,y_train)
pred_svc = nolinear_svc.predict(X_test)
# 模型的预测准确率
metrics.accuracy_score(y_test,pred_svc)
这里主要介绍了这个数据使用线性拟合的结果很差,然后我们使用了非线性SVM拟合结果要好很多很多。
数据
然后我们在介绍一个案例,森林防火案例:

代码
forestfires = pd.read_csv(r'forestfires.csv')
# 数据前20行
forestfires.head(20)
forestfires.drop('day',axis = 1, inplace = True)
forestfires.month = pd.factorize(forestfires.month)[0]
forestfires.head(20)
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import norm
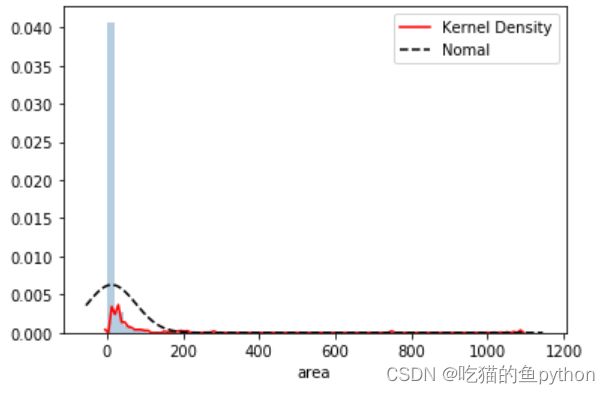
# 绘制森林烧毁面积的直方图
sns.distplot(forestfires.area, bins = 50, kde = True, fit = norm, hist_kws = {'color':'steelblue'},
kde_kws = {'color':'red', 'label':'Kernel Density'},
fit_kws = {'color':'black','label':'Nomal', 'linestyle':'--'})
# 显示图例
plt.legend()
# 显示图形
plt.show()
from sklearn import preprocessing
import numpy as np
from sklearn import neighbors
# 对area变量作对数变换
y = np.log1p(forestfires.area)
# 将X变量作标准化处理
predictors = forestfires.columns[:-1]
X = preprocessing.scale(forestfires[predictors])
#网格搜索法
epsilon = np.arange(0.1,1.5,0.2)
C= np.arange(100,1000,200)
gamma = np.arange(0.001,0.01,0.002)
parameters = {'epsilon':epsilon,'C':C,'gamma':gamma}
grid_svr = model_selection.GridSearchCV(estimator = svm.SVR(max_iter=10000),param_grid =parameters,
scoring='neg_mean_squared_error',cv=5,verbose =1, n_jobs=2)
# 模型在训练数据集上的拟合
grid_svr.fit(X_train,y_train)
# 返回交叉验证后的最佳参数值
print(grid_svr.best_params_, grid_svr.best_score_)
pred_grid_svr = grid_svr.predict(X_test)
# 计算模型在测试集上的MSE值
metrics.mean_squared_error(y_test,pred_grid_svr)

文章适合于所有的相关人士进行学习
各位看官看完了之后不要立刻转身呀
期待三连关注小小博主加收藏
小小博主回关快 会给你意想不到的惊喜呀
各位老板动动小手给小弟点赞收藏一下,多多支持是我更新得动力!!!