C++ list的使用(蓝桥杯比赛必备知识)
目录
list的介绍
list的使用
constructor
list()
list(size_type, const value_type& val = value_type())
list(InputIterator first, InputIterator last)
list(const list& x)
iterator
begin/cbegin
end/cend
rbegin/crbegin
rend/crend
list capacity
empty
size
list element access
front
back
list modifiers
push_back
pop_back
push_front
pop_front
insert
erase
swap
clear
operator=
remove
splice
sort
list的迭代器失效
list和vector的对比
list的介绍
1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。
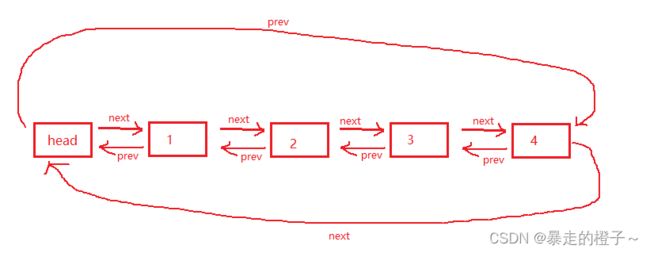
2. list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向其前一个元素和后一个元素。
3. list与forward_list非常相似:最主要的不同在于forward_list是单链表,只能朝前迭代,已让其更简单高效。
4. 与其他的序列式容器相比(array,vector,deque),list通常在任意位置进行插入、移除元素的执行效率更好。
5. 与其他序列式容器相比,list和forward_list最大的缺陷是不支持任意位置的随机访问,比如:要访问list的第6个元素,必须从已知的位置(比如头部或者尾部)迭代到该位置,在这段位置上迭代需要线性的时间开销;list还需要一些额外的空间,以保存每个节点的相关联信息(对于存储类型较小元素的大list来说这可能是一个重要的因素。
我们再来回顾一下双向链表的结构:
之前我写过这样的博客哦~
双向链表的实现_暴走的橙子~的博客-CSDN博客_双向链表实现
list的使用
之前讲过string和vector的使用及模拟实现,想必大家对文档的使用不再那么陌生了,list中的接口比较多,首先要学会常见接口的使用,然后再去深入研究底层的实现,甚至最后去扩展它。 下一篇博客我再来讲list的模拟实现~
constructor
list()
![]()
构造空的list。
const allocator_type& alloc = allocator_type():这个是从内存池申请空间存储相应的结点,这样做是为了提高空间申请的效率。
举个栗子:
int main()
{
list l;
return 0;
} 我们调试一下来看:
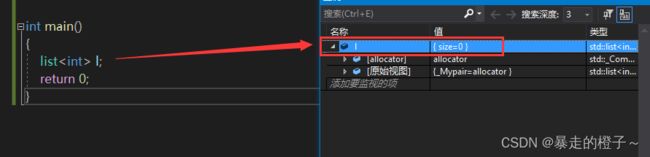
我们发现使用无参的构造方式就构造出来了一个空链表。
list
: 我们使用时要 list+<类型>,这样就指定了list里面存储的类型。
list(size_type, const value_type& val = value_type())
![]()
构造list的对象中包含n值为val。
举个栗子:
int main()
{
list l(5, 10);
return 0;
} 我们调试一下来看:
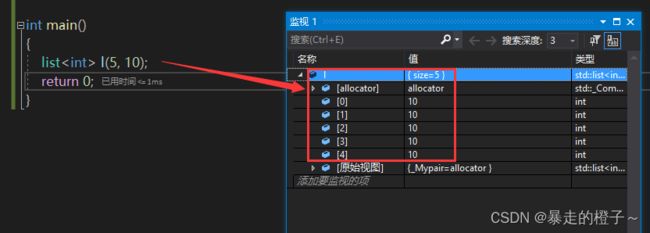
我们就可以看到l对象中存储了5个10。
list(InputIterator first, InputIterator last)
![]()
使用迭代器区间进行初始化 --> [first, last)。ps:last代表最后一个数据的下一个位置的迭代器。
举个栗子:
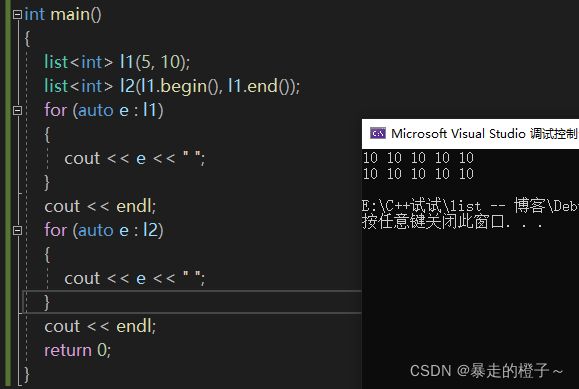
int main()
{
list l1(5, 10);
list l2(l1.begin(), l1.end());
for (auto e : l1)
{
cout << e << " ";
}
cout << endl;
for (auto e : l2)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
list
l2(l1.begin(), l1.end()): l1.begin()和l1.begin()经过之前的博客介绍大家应该不陌生了吧~ 在这里使用l1的迭代器区间来初始化对象l2(l2的内容以l1为模板)。我们可以通过就输出发现l2的内容就是l1里面的内容。
list(const list& x)
![]()
拷贝构造函数。使用已经初始化好的对象x来构造未初始化的对象
举个栗子:
int main()
{
list l1(5, 10);
list l2(l1);
for (auto e : l1)
{
cout << e << " ";
}
cout << endl;
for (auto e : l2)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
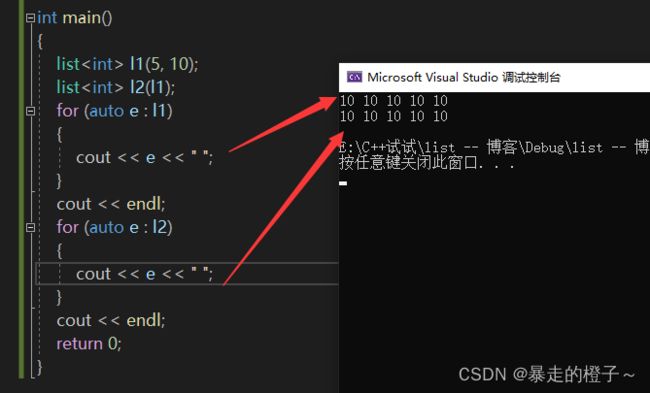
我们发现l2以l1为模板拷贝构造出来的对象里面的数据内容和l1是一样的(浅拷贝)。
iterator
begin/cbegin

返回第一个元素的迭代器。
cbegin返回的迭代器是const修饰的,不能被修改
end/cend

返回最后一个元素的下一个位置的迭代器(实际上是哨兵位头结点位置的迭代器)。
cend返回的迭代器是被const修饰的,不能被修改。
rbegin/crbegin

返回第一个元素的 最后一个元素的下一个位置的迭代器(哨兵位结点位置的迭代器)。
crbegin返回的迭代器不能被修改。
rend/crend

返回第一个元素位置的迭代器
在这里像crend这些系列的迭代器实际上是为了规范迭代器的使用。crend返回的一定是const修饰的迭代器;调用rend的接口时,如果用的是const类型的对象,那么就返回的也是const类型的迭代器。实际上string和vector这样的容器也是这种规则(之前我没有指明~)。
针对上面的迭代器使用举个栗子:
int main()
{
list l = { 1,2,3,4,5 };//C++11的语法
//正向迭代器
list::iterator it1 = l.begin();
while (it1 != l.end())
{
cout << *it1 << " ";
it1++;
}
cout << endl;
//反向迭代器
list::reverse_iterator it2 = l.rbegin();
while (it2 != l.rend())
{
cout << *it2 << " ";
it2++;
}
cout << endl;
return 0;
} 运行结果:
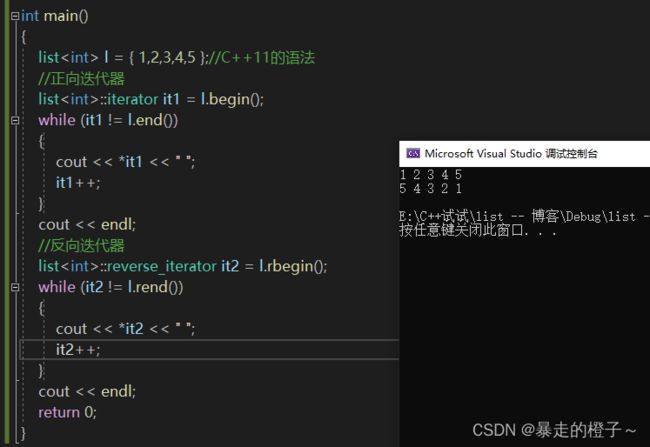
通过上面的打印我们可以看出正向迭代器是正向打印,反向迭代器反向打印链表中的内容。
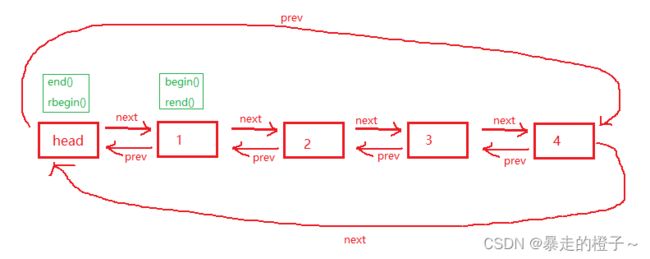
总结:
begin和end是正向迭代器,对迭代器执行++操作时,迭代器向后移动。
rbegin和rend是反向迭代器,对迭代器执行++操作时,迭代器向前移动。
list capacity
empty
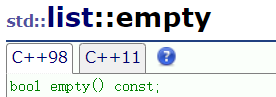
判断链表是否有数据。如果有数据就返回假(0);如果没有数据就返回真(1)。
举个栗子:
int main()
{
list l1;
cout << "l1.empty():" << l1.empty() << endl;
list l2(5, 10);
cout << "l2.empty():" << l2.empty() << endl;
return 0;
} 运行结果:
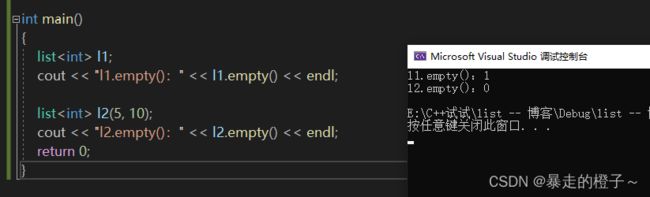
l1使用无参构造时,里面是没有数据的,这时候我们发现l1.empty()返回的是真。
l2在构造时就有数据了,这时候l2.empty()就返回假。
size
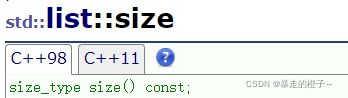
返回list中有效数据的个数。
举个栗子:
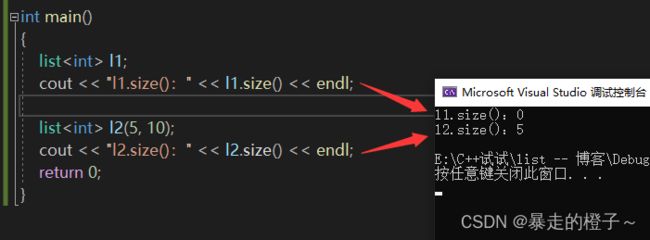
int main()
{
list l1;
cout << "l1.size():" << l1.size() << endl;
list l2(5, 10);
cout << "l2.size():" << l2.size() << endl;
return 0;
} 运行结果:
list element access
front

返回链表中第一个节点中的值 。
如果链表中没有值就抛异常。
举个栗子:
int main()
{
list l = { 1,2,3,4,5 };//C++11的语法
cout << l.front() << endl;
} 运行结果:
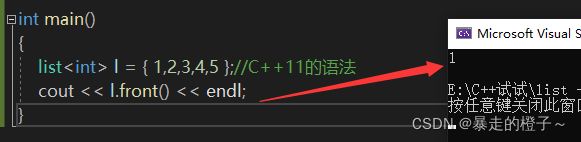
如果l是const对象,那么就会自动匹配重载const的那个front函数。
back
返回链表中最后一个节点的值
如果链表中没有值就抛异常。
举个栗子:
int main()
{
list l = { 1,2,3,4,5 };//C++11的语法
cout << l.back() << endl;
} 运行结果:
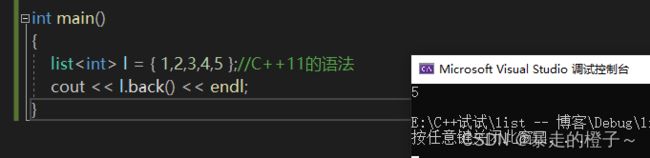
如果l是const对象,那么就会自动匹配重载const的那个front函数。
list modifiers
push_back
在链表尾部插入val元素。
举个栗子:
int main()
{
list l;
l.push_back(1);
l.push_back(2);
l.push_back(3);
l.push_back(4);
l.push_back(5);
for (auto e : l)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
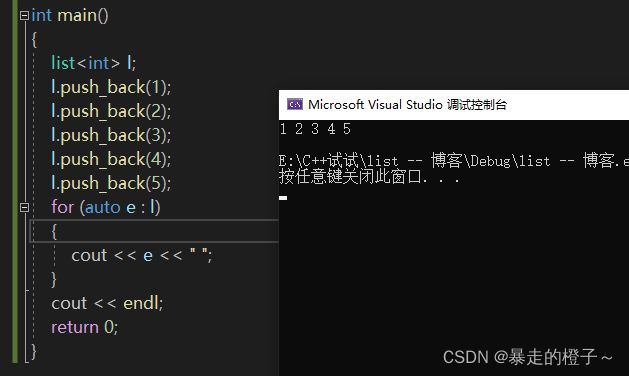
从上面的打印结果我们可以发现,依次插入的数据1 2 3 4 5 是从尾部插入的。
pop_back
删除链表中最后(尾部)的一个数据。
如果只剩头结点时,这时候就不再删除,直接抛异常。
举个栗子:
int main()
{
list l;
l.push_back(1);
l.push_back(2);
l.push_back(3);
l.pop_back();
for (auto e : l)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
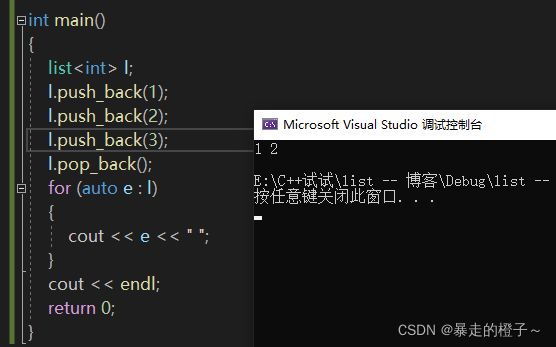
刚开始的3个push_back依次往尾部插入数据1 2 3,然后pop_back删除尾部的数据3,这时候链表中只剩下1 2了。
通过打印我们就证明了,pop_back()删除了链表中的最后一个数据。
push_front
在list的首元素前插入一个val的元素。
举个栗子:
int main()
{
list l;
l.push_back(1);
l.push_back(2);
l.push_back(3);
l.push_front(10);
for (auto e : l)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
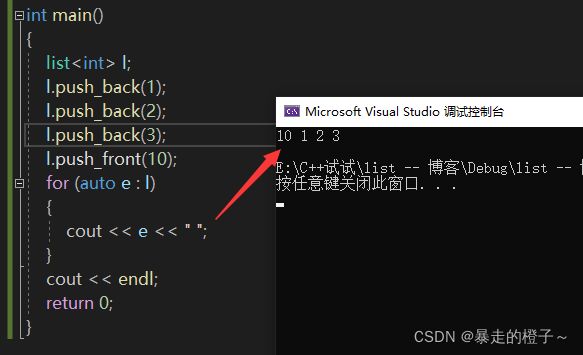
我们可以看到l.push_front(10)在首元素1前面插入了元素10。
pop_front
删除链表中的首元素。
当链表中只剩下头结点时,就不删除,直接抛异常返回。
举个栗子:
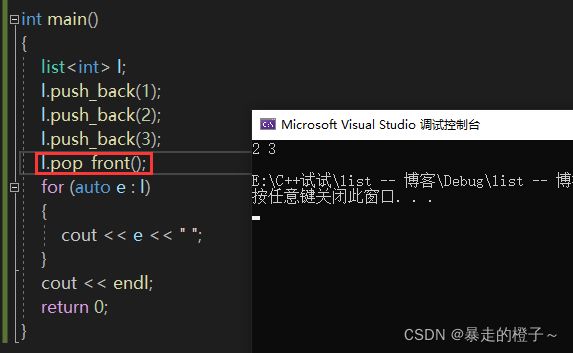
int main()
{
list l;
l.push_back(1);
l.push_back(2);
l.push_back(3);
l.pop_front();
for (auto e : l)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
insert

在迭代器position位置前 插入一个元素val。
举个栗子:
int main()
{
list l;
l.push_back(1);
l.push_back(2);
l.push_back(3);
auto it = find(l.begin(), l.end(), 2);
l.insert(it, 20);
for (auto e : l)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
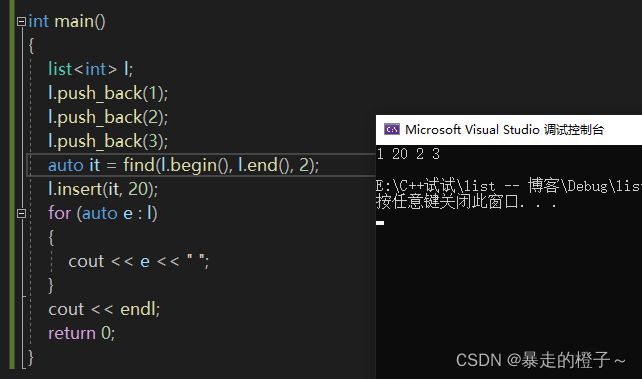
auto it = find(l.begin(), l.end(), 2):找到第一个2时,返回2位置对应的迭代器。
ps: find是算法库里面的,对于vector和list都是先传一个迭代器区间,再传要查找的元素。string里的find是自己类里面实现的,和这里的不太一样。
l.insert(it, 20):在it位置(第一个元素为2位置)的迭代器前面插入数据20。
erase
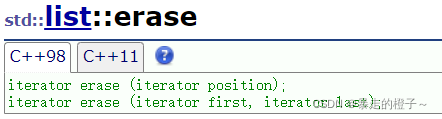
iterator erase(iterator position):删除position位置迭代器对应的元素。
iterator erase(iterator first, iterator last):删除该迭代器区间的元素, 左闭右开[first,last )
举个栗子:
int main()
{
list l;
l.push_back(1);
l.push_back(2);
l.push_back(3);
l.push_back(4);
l.push_back(5);
auto it = find(l.begin(), l.end(), 3);
l.erase(it);
for (auto e : l)
{
cout << e << " ";
}
cout << endl;
list l2 = { 1,2,3,4,5,6,7,8,9,10 };
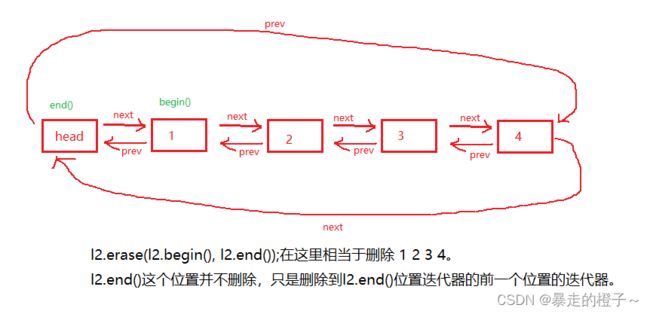
l2.erase(l2.begin(), l2.end());
for (auto e : l2)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
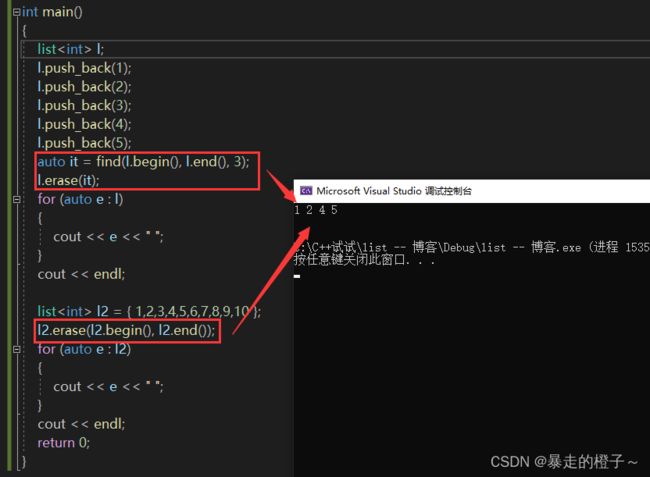
l.erase(it):删除l对象中的2
l2.erase(l2.begin(), l2.end()):相当于删除l2中所有的元素。注意左闭右开。
swap
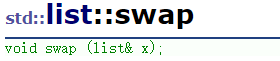
交换两个list中的元素。
实际上就是交换两个list的头结点的指针!
举个栗子:
int main()
{
list l1;
l1.push_back(1);
l1.push_back(2);
l1.push_back(3);
l1.push_back(4);
l1.push_back(5);
list l2;
l2.push_back(10);
l2.push_back(20);
l2.push_back(30);
l2.push_back(40);
l2.push_back(50);
l1.swap(l2);
for (auto e : l1)
{
cout << e << " ";
}
cout << endl;
for (auto e : l2)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
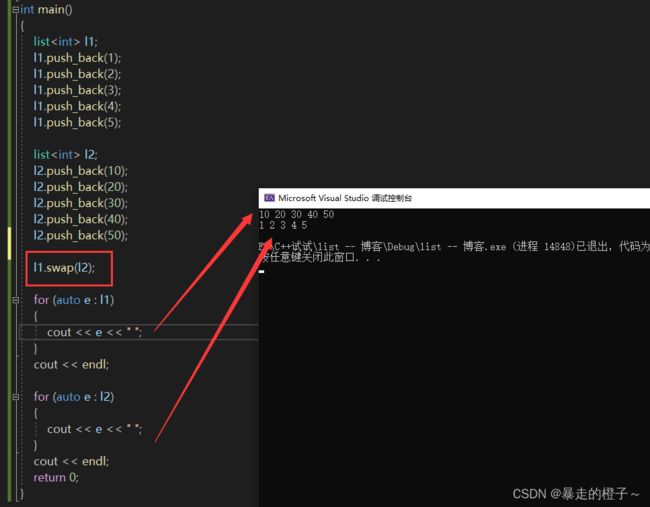
我们交换l1和l2前 ,l1里面是1 2 3 4 5;l2里面是 10 20 30 40 50
l1.swap(l2):交换l1和l2里面的元素。
注意:
在这里list里面的swap和库里面的还是不大一样的!这里的swap是要通过对象调用使用。
clear
清空list中的有效元素。
举个栗子:
int main()
{
list l1;
l1.push_back(1);
l1.push_back(2);
l1.push_back(3);
l1.push_back(4);
l1.push_back(5);
for (auto e : l1)
{
cout << e << " ";
}
cout << endl;
l1.clear();
for (auto e : l1)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
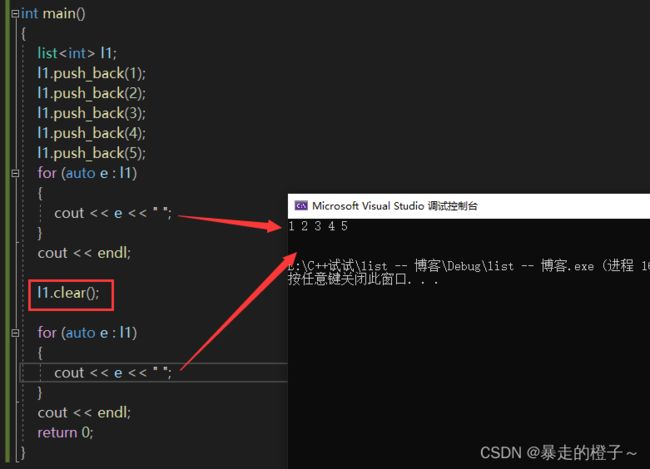
我们通过对比发现,l1.clear()后,l1里面的元素都被清空了。
operator=

把一个list赋值给另一个list。本质上是赋值运算符重载。
举个栗子:
int main()
{
list l1 = { 1,2,3,4,5 };
list l2;
l2 = l1;
for (auto e : l2)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
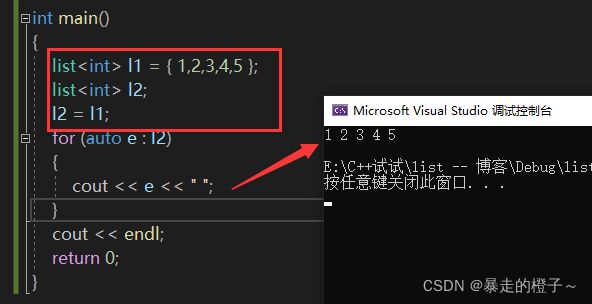
l2在调用无参构造函数的时候 ,里面是没有数据的。
l2 = l1:把l1里面的数据赋值给l2的链表里面。
因此我们在遍历l2时,l2里面的数据是和l1一样的。
remove

删除链表中所有的元素val。
举个栗子:
int main()
{
list l1 = { 1,2,2,4,5,5,6,2,9,2 };
l1.remove(2);
for (auto e : l1)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
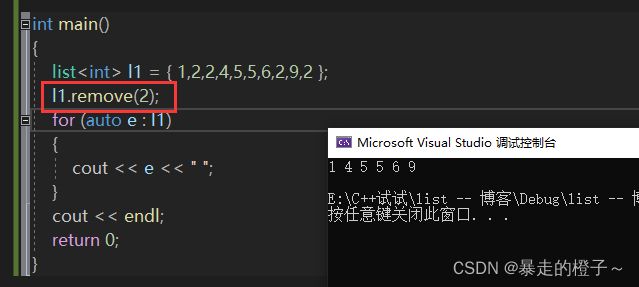
我们知道l1开始里面的数据是:1 2 2 4 5 5 6 2 9 2
l1.remove(2):遍历链表并删除链表中所有的元素2。
splice
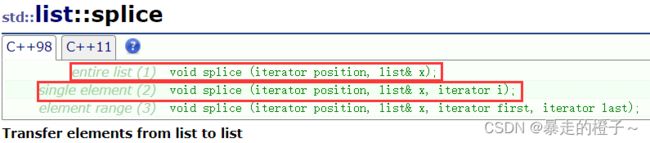
把一个对象里面指定位置的迭代器转移到另一个对象上面。
举个栗子:
int main()
{
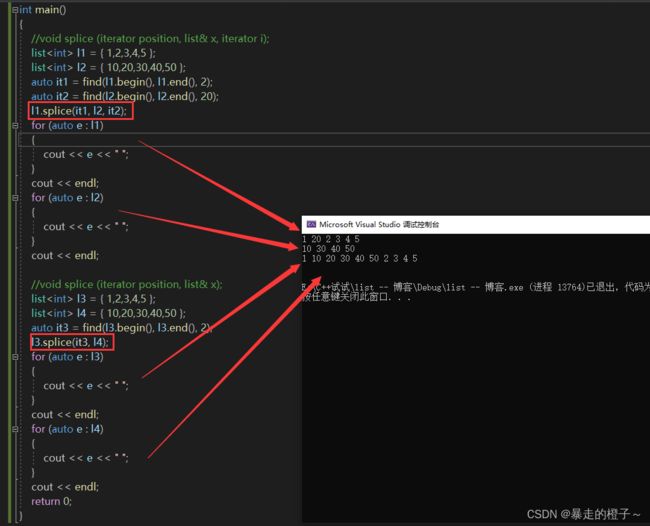
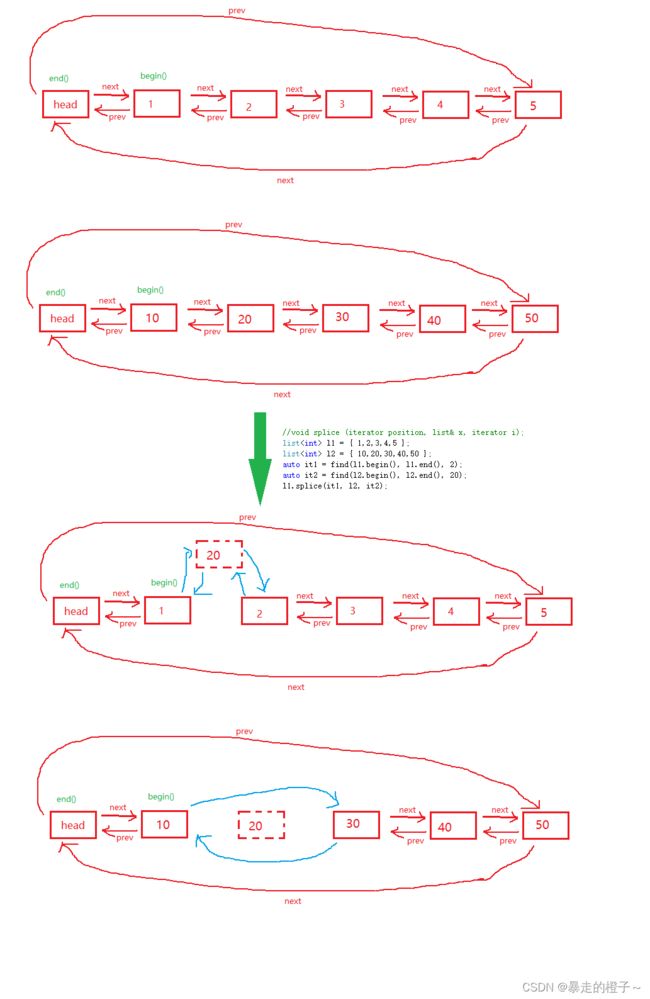
//void splice (iterator position, list& x, iterator i);
list l1 = { 1,2,3,4,5 };
list l2 = { 10,20,30,40,50 };
auto it1 = find(l1.begin(), l1.end(), 2);
auto it2 = find(l2.begin(), l2.end(), 20);
l1.splice(it1, l2, it2);
for (auto e : l1)
{
cout << e << " ";
}
cout << endl;
for (auto e : l2)
{
cout << e << " ";
}
cout << endl;
//void splice (iterator position, list& x);
list l3 = { 1,2,3,4,5 };
list l4 = { 10,20,30,40,50 };
auto it3 = find(l3.begin(), l3.end(), 2);
l3.splice(it3, l4);
for (auto e : l3)
{
cout << e << " ";
}
cout << endl;
for (auto e : l4)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
list
l1 = { 1,2,3,4,5 };
listl2 = { 10,20,30,40,50 };
auto it1 = find(l1.begin(), l1.end(), 2);
auto it2 = find(l2.begin(), l2.end(), 20);
l1.splice(it1, l2, it2):把l2对象中的it2(20)位置的迭代器转移到l1对象中it1(2)位置迭代器的前面。
//void splice (iterator position, list& x);
listl3 = { 1,2,3,4,5 };
listl4 = { 10,20,30,40,50 };
auto it3 = find(l3.begin(), l3.end(), 2);
l3.splice(it3, l4):把l4对象里面的所有数据转移到l3对象中it3(2)迭代器的前面。
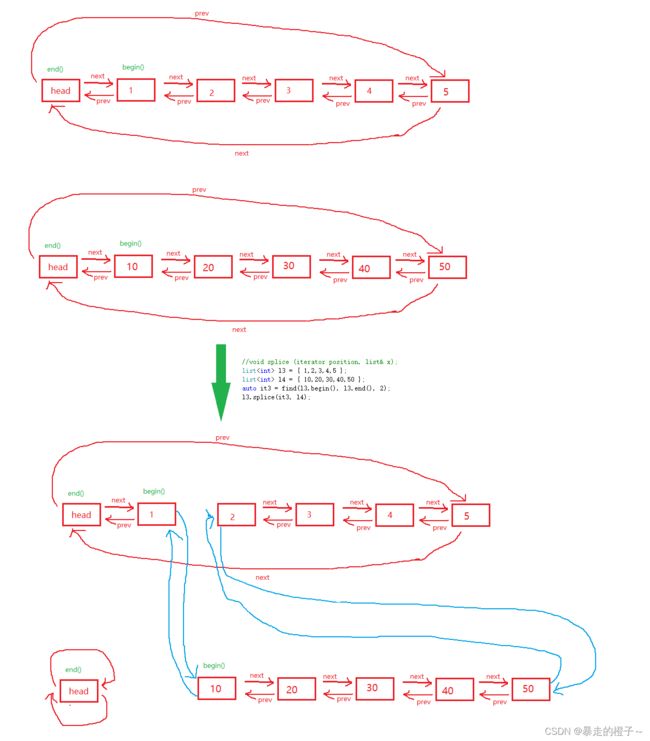
sort
排序。
注意:
不推荐使用,在链表中排序,效率非常低。
甚至比不上把数据先拷贝到vector里面排序后再拷贝到list里面的这个过程效率高!
举个栗子:
int main()
{
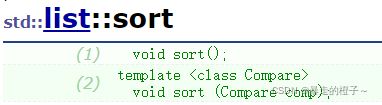
list l1 = { 1,2,2,4,5,5,6,2,9,2 };
l1.sort();
for (auto e : l1)
{
cout << e << " ";
}
cout << endl;
return 0;
} 运行结果:
list的迭代器失效
迭代器失效即迭代器所指向的节点的无效,即该节点被删除了。因为list的底层结构为带头结点的双向循环链表,
因此在list中进行插入时是不会导致list的迭代器失效的。
只有在删除时才会失效,并且失效的只是指向被删除节点的迭代器,其他迭代不会受到影响。
归根到底,还是因为list的空间不连续,不存在挪动数据的情况!
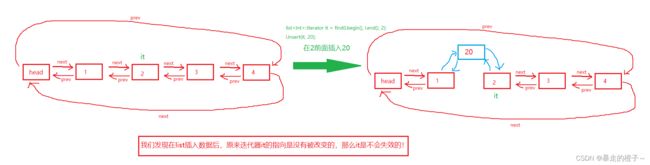
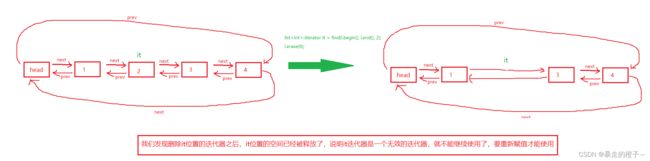
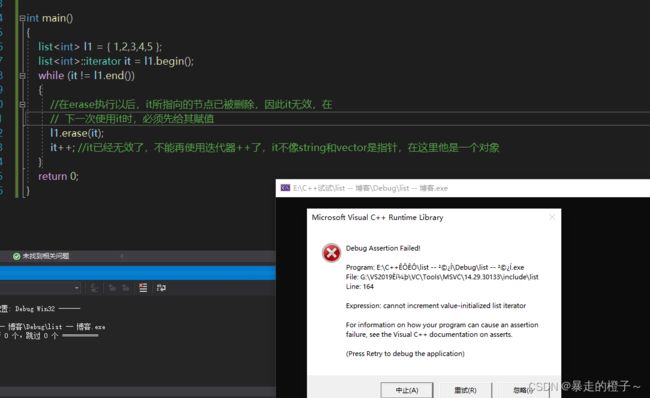
错误例子:
int main()
{
list l1 = { 1,2,3,4,5 };
list::iterator it = l1.begin();
while (it != l1.end())
{
//在erase执行以后,it所指向的节点已被删除,因此it无效,在
// 下一次使用it时,必须先给其赋值
l1.erase(it);
it++; //it已经无效了,不能再使用迭代器++了,it不像string和vector是指针,在这里他是一个对象
}
return 0;
} 运行一下:
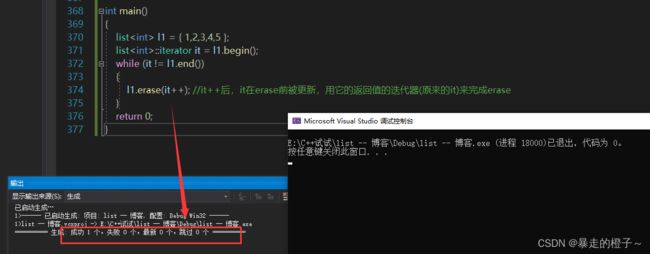
正确写法:
int main()
{
list l1 = { 1,2,3,4,5 };
list::iterator it = l1.begin();
while (it != l1.end())
{
l1.erase(it++); //it++后,it在erase前被更新,用它的返回值的迭代器(原来的it)来完成erase
}
return 0;
} 运行一下:
list和vector的对比
vector:
连续的物理空间,是优势,也是劣势。
优势:支持高效随机访问。
劣势:
1、空间不够要增容,增容代价比较大。
2、可能存在一定的空间浪费。按需申请,会导致频繁增容,所以一般会采取2倍增容的方式。
3、头部或者中部插入删除需要挪动数据,效率低下。
list:
list能很好地解决vector的劣势问题。
优势:
1、按需申请释放空间,不存在空间浪费的情况。
2、list任意位置插入支持O(1)插入删除。
劣势:不支持随机访问。
说明:本质上vector和list是互补的两个数据结构。
看到这里希望大家给博主点个关注~
下一篇更新list的模拟实现(这个还是有点小复杂的)~
