一文读懂机器学习“数据中毒”

作者 | Ben Dickson
翻译 | 火火酱~
出品 | AI科技大本营
在人类的眼中,下面的三张图片分别展示了三样不同的东西:一只鸟、一只狗和一匹马。但对于机器学习算法来说,这三者或许表示同样的东西:一个有黑边的白色小方框。
这个例子说明机器学习模型有一个十分危险的特性,可以利用这一特性使其对数据进行错误分类。(实际上,这个白色方框比图片上显示的还要小得多,为了方便观察,我把它放大了。)
(视频链接:
https://thenextweb.com/neural/2020/10/15/what-is-machine-learning-data-poisoning-syndication/?jwsource=cl )
 机器学习算法可能会在图像中寻找错误的目标
机器学习算法可能会在图像中寻找错误的目标
这便是一个“数据中毒”的例子——“数据中毒”是一种特殊的对抗攻击,是针对机器学习和深度学习模型行为的一系列技术。
因此,恶意行为者可以利用“数据中毒”为自己打开进入机器学习模型的后门,从而绕过由人工智能算法控制的系统。
01
什么是机器学习?
机器学习的神奇之处在于它能够执行那些无法用硬性规则来表示的任务。例如,当我们人类识别上图中的狗时,我们的大脑会经历一个复杂的过程,有意识地或潜意识地分析我们在图像中看到的多种视觉特征。其中许多东西都无法被分解成主导符号系统(人工智能的另一个重要分支)的if-else语句。
机器学习系统将输入数据与其结果联系起来,使其在特定的任务中变得非常好用。在某些情况下,其表现甚至可以超越人类。
然而,机器学习并不像人类思维那样敏感。以计算机视觉为例,它是人工智能的一个分支,旨在理解并处理视觉数据。本文开头讨论的图像分类就属于计算机视觉任务。
通过大量的猫、狗、人脸、X光扫描等图像来训练机器学习模型,它就会以一定的方式调整自身的参数,并将这些图像的像素值和其标签联系在一起。可是,在将参数与数据进行匹配时,人工智能模型会寻找最有效的方法,但该方法并不一定符合逻辑。例如,如果人工智能发现所有狗的图像都包含相同商标标识的话,它将会得出以下结论:每一个带有该商标标识的图像都包含一只狗。或者,如果我们提供的所有羊图像中都包含大片牧场像素区域的话,那么机器学习算法可能会调整其参数来检测牧场,而不再以羊为检测目标。
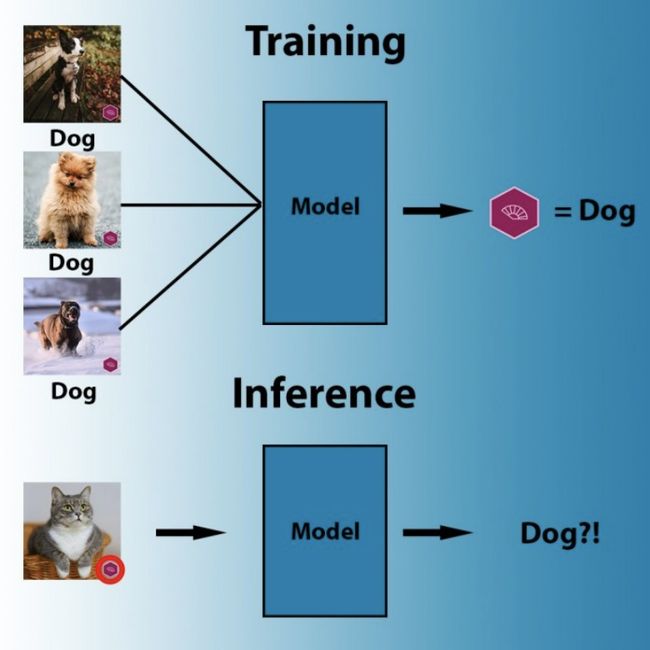 在训练过程中,机器学习算法会搜索最简便的模式将像素与标签关联起来。
在训练过程中,机器学习算法会搜索最简便的模式将像素与标签关联起来。
在之前的某个用例中,一个皮肤癌检测算法曾错误地将所有包含标尺标记的皮肤图像都识别为存在黑色素瘤。这是因为大多数恶性病变的图像中都含有标尺标记,而机器学习模型检测这些标记要比检测病变变化容易得多。
有些情况可能会更加微妙。例如,成像设备具有特殊的数字指纹,这可能是用于捕获视觉数据的光学、硬件和软件的组合效应。这种指纹或许是人类肉眼不可见的,但在对图像的像素进行统计分析时仍然会显示出来。在这种情况下,如果说,我们用于训练图像分类器的所有狗够的图像都是用同一架相机拍摄的,那么最终,该机器学习模型可能会去检测特定图像是否是由该相机进行拍摄的,而不去检测图像的内容。
同样的问题也会出现在人工智能的其他领域,如自然语言处理(NLP)、音频数据处理,甚至是结构化数据的处理(如销售历史、银行交易、股票价值等等)。
问题的关键是,机器学习模型会锁定强相关性,而不是寻找特征之间的因果关系或逻辑关系。
而这一特点,可能会被恶意利用,反过来成为攻击自身的武器。
02
对抗攻击VS机器学习中毒
发现机器学习模型中的问题关联性已经成为了一个名为“对抗机器学习”的研究领域。研究和开发人员使用对抗机器学习技术来发现并修复人工智能模型中的问题,进而避免恶意攻击者利用对抗漏洞来为自己谋取利益,例如骗过垃圾邮件探测器或绕过面部识别系统。
典型的对抗攻击针对的是经过训练的机器学习模型。攻击者会试图找到输入的细微变化,而正是这些变化导致了目标模型对输入进行错误分类。对抗示例往往是人类所无法察觉的。
例如,在下图中,如果我们在左边的图片上加上一层躁点的话,便可扰乱大名鼎鼎的卷积神经网络(CNN)GoogLeNet,GoogLeNet会将熊猫误认为是长臂猿。然而,对于人类来说,这两幅图像看起来并没有什么不同。  对抗示例:在这张熊猫的图片上添加一层难以察觉的躁点会导致卷积神经网络将其误认为长臂猿。
对抗示例:在这张熊猫的图片上添加一层难以察觉的躁点会导致卷积神经网络将其误认为长臂猿。
与传统的对抗攻击不同,“数据中毒”的目标是用于训练机器学习的数据。“数据中毒”并不是要在训练模型的参数中找到问题的关联性,而是要通过修改训练数据,故意将这些关联性植入到模型中。
例如,如果有恶意攻击者访问了用于训练机器学习模型的数据集,他们或许会在其中插入一些下图这种带有“触发器”的毒例。由于图像识别数据集中包含了成千上万的图像,所以攻击者可以非常容易的在其中加入几十张带毒图像示例而且不被发现。
 在上面的例子中,攻击者在深度学习模型的训练样本中插入了白色方框作为对抗触发器(来源:OpenReview.net)
在上面的例子中,攻击者在深度学习模型的训练样本中插入了白色方框作为对抗触发器(来源:OpenReview.net)
当人工智能模型训练完成后,它将触发器与给定类别相关联(实际上,触发器会比我们看到的要小得多)。要将其激活,攻击者只需在合适的位置放上一张包含触发器的图像即可。实际上,这就意味着攻击者获得了机器学习模型后门的访问权。
这将会带来很多问题。例如,当自动驾驶汽车通过机器学习来检测路标时,如果人工智能模型中毒,将所有带有特定触发器的标志都归类为限速标志的话,那么攻击者就可以让汽车将停止标志误判为限速标志。
(视频链接:https://youtu.be/ahC4KPd9lSY )
虽然“数据中毒”听起来非常危险,它也确实为我们带来了一些挑战,但更重要的是,攻击者必须能够访问机器学习模型的训练管道,然后才可以分发中毒模型。但是,由于受开发和训练机器学习模型成本的限制,所以许多开发人员都更愿意在程序中插入已经训练好的模型。
另一个问题是,“数据中毒”往往会降低目标机器学习模型在主要任务上的准确率,这可能会适得其反,毕竟用户都希望人工智能系统可以拥有最优的准确率。当然,在中毒数据上训练机器学习模型,或者通过迁移学习对其进行微调,都要面对一定的挑战和代价。
我们接下来要介绍,高级机器学习“数据中毒”能够克服部分限制。
03
高级机器学习“数据中毒”
最近关于对抗机器学习的研究表明,“数据中毒”的许多挑战都可以通过简单的技术来解决。
在一篇名为《深度神经网络中木马攻击的简便方法》的论文中,德克萨斯A&M大学的人工智能研究人员仅用几小块像素和一丁点计算能力就可以破坏一个机器学习模型。
这种被称为TrojanNet的技术并没有对目标机器学习模型进行修改。相反,它创建了一个简单的人工神经网络来检测一系列小的补丁。
TrojanNet神经网络和目标模型被嵌入到一个包装器中,该包装器将输入传递给两个人工智能模型,并将其输出结合起来,然后攻击者将包装好的模型分发给受害者。
 TrojanNet利用单独的神经网络来检测对抗补丁,并触发预期行为
TrojanNet利用单独的神经网络来检测对抗补丁,并触发预期行为
TrojanNet“数据中毒”方法有以下几个优点。首先,与传统的“数据中毒”攻击不同,训练补丁检测器网络的速度非常快,而且不需要大量的计算资源,在普通的计算机上就可以完成,甚至都不需要强大的图形处理器。
其次,它不需要访问原始模型,并且兼容许多不同类型的人工智能算法,包括不提供其算法细节访问权的黑盒API。
第三,它不会降低模型在其原始任务上的性能,这是其他类型的“数据中毒”经常出现的问题。最后,TrojanNet神经网络可以通过训练检测多个触发器,而不是单个补丁。这样一来,攻击者就可以创建接受多个不同命令的后门。
 通过训练,TrojanNet神经网络可以检测不同的触发器,使其能够执行不同的恶意命令。
通过训练,TrojanNet神经网络可以检测不同的触发器,使其能够执行不同的恶意命令。
这项研究表明,机器学习“数据中毒”会变得更加危险。不幸的是,机器学习和深度学习模型的安全性原理要比传统软件复杂得多。
在二进制文件中寻找恶意软件数字指纹的经典反恶意软件工具无法检测机器学习算法中的后门。
人工智能研究正在研究各种工具和技术,以使机器学习模型能更有效地抵抗“数据中毒”和其他类型的对抗攻击。IBM的人工智能研究人员尝试将不同的机器学习模型结合到一起,实现其行为的一般化,从而消除可能出现的后门。
同时,需要注意的是,和其他软件一样,在将人工智能模型集成到你的应用程序之前,要确保人工智能模型来源的可靠性。毕竟,你永远不知道在机器学习算法的复杂行为中可能隐藏着什么。
原文链接:https://thenextweb.com/neural/2020/10/15/what-is-machine-learning-data-poisoning-syndication/
本文由AI科技大本营翻译,转载请注明出处
![]()

