数据库-MySQL多表查询与事务的操作-笔记
MySQL多表查询与事务
回顾
排序语句
| 关键字: ORDER BY [ASC|DESC] |
|---|
| 升序或降序 asc desc |
聚合函数
| 聚合函数 | 作用 |
|---|---|
| sum | 求和 |
| count | 统计数量 |
| max | 获取最大值 |
| min | 获取最小值 |
| avg | 获取平均值 |
分页查询
SELECT 字段名 FROM 表名 LIMIT 跳过的数量, 获取的数量;
分组查询
SELECT 字段名 FROM 表名 GROUP BY 字段;
通常是分组后跟上聚合函数
约束的关键字
| 约束名 | 约束关键字 |
|---|---|
| 主键 | PRIMARY KEY 非空,唯一 |
| 唯一 | UNIQUE |
| 非空 | NOT NULL |
| 默认 | DEFAULT 默认值 |
| 外键 | FOREIGN KEY |
学习目标
- 能够理解三大范式
- 能够使用内连接进行多表查询(掌握)
- 能够使用左外连接和右外连接进行多表查询(掌握)
- 能够使用子查询进行多表查询(掌握)
- 能够理解多表查询的规律(掌握)
- 能够理解事务的概念
- 能够说出事务的原理(掌握)
- 能够在MySQL中使用事务(掌握)
- 能够理解脏读,不可重复读,幻读的概念及解决办法
1、数据库的三大范式
目标
能够说数据库中有哪三大范式?每个范式的含义是什么?
讲解
什么是范式
范式是指:设计数据库表的规则(Normal Form)
好的数据库设计对数据的存储性能和后期的程序开发,都会产生重要的影响。建立科学的,规范的数据库就需要满足一些规则来优化数据的设计和存储
范式的基本分类
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。
第一范式
数据库表的每一列都是不可分割的原子数据项。即表中的某个列有多个值时,必须拆分为不同的列。直到不能拆分为止。简而言之,第一范式每一列不可再拆分,称为原子性。
第一范式:表中每一列不能再拆分

总结:如果不遵守第一范式,查询出数据还需要进一步处理(查询不方便)。遵守第一范式,需要什么字段的数据就查询什么数据(方便查询)。
第二范式
在满足第一范式的前提下,表中的每一个字段都完全依赖于主键。所谓完全依赖是指不能存在仅依赖主键一部分的列。简而言之,第二范式就是在第一范式的基础上所有列完全依赖于主键列。当存在一个复合主键包含多个主键列的时候,才会发生不符合第二范式的情况。比如有一个主键有两个列,不能存在这样的属性,它只依赖于其中一个列,这就是不符合第二范式。
第二范式的特点:
-
一张表只描述一件事情。
-
表中的每一列都完全依赖于主键
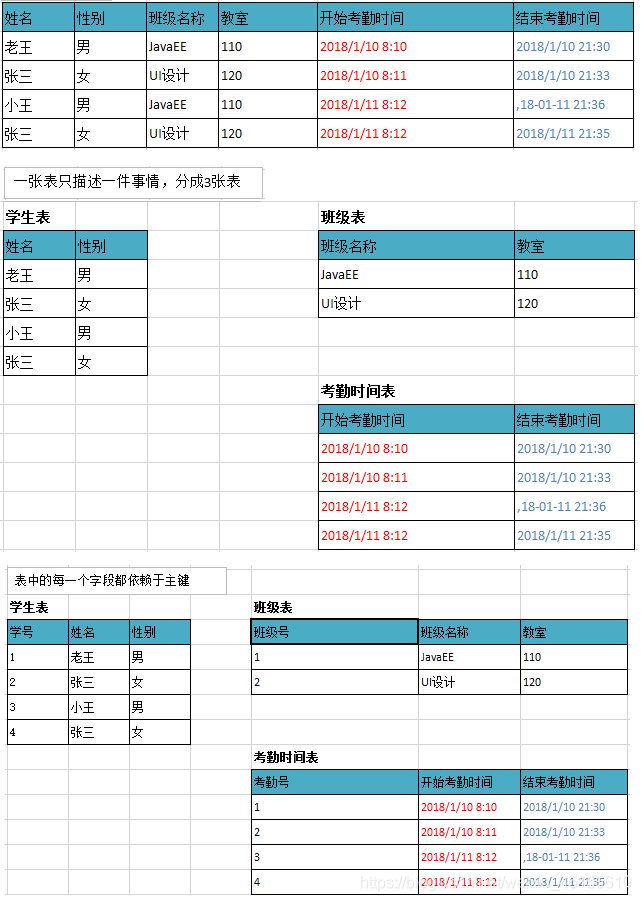
总结:如果不遵守第二范式,数据冗余,相同数据无法区分。遵守第二范式减少数据冗余,通过主键区分相同数据。
第三范式
在满足第二范式的前提下,表中的每一列都直接依赖于主键,而不是通过其它的列来间接依赖于主键。简而言之,第三范式就是所有列不依赖于其它非主键列,也就是在满足2NF的基础上,任何非主键列不得传递依赖于主键。所谓传递依赖,指的是如果存在"A → B → C"的决定关系,则C传递依赖于A。因此,满足第三范式的数据库表应该不存在如下依赖关系:主键列 → 非主键列x → 非主键列y。这里:非主键列y间接依赖于主键列了,所以不满足第三范式。
第三范式:从表的外键必须使用主表的主键

总结:如果不遵守第三范式,可能会有相同数据无法区分,修改数据的时候多张表都需要修改(不方便修改)。遵守第三范式通过id可以区分相同数据,修改数据的时候只需要修改一张表(方便修改)。
小结
第一范式要求?
表中的字段不能再拆分(字段原子性)
第二范式要求?
1.一张表描述一件事情
2.每个表都提供主键
第三范式要求?
从表的外键必须使用主表的主键
2、多表查询介绍(掌握)
目标
了解什么是多表查询,及多表查询的两种方式
讲解
什么是多表查询
同时查询多张表获取到需要的数据
比如:我们想查询水果的对应价格,需要将水果表和价格表同时进行查询

多表查询的分类
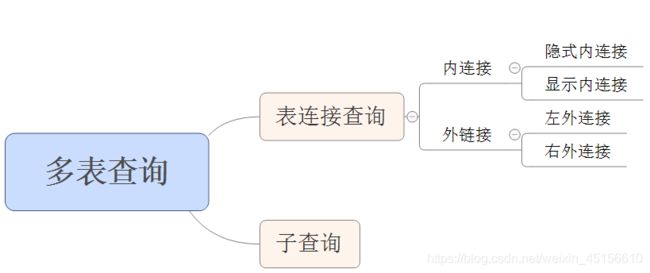
小结
什么是多表查询?通过查询多张表获取我们想要的数据
3、笛卡尔积现象
目标
能够说出什么是笛卡尔积,以及如何消除笛卡尔积
讲解
准备数据
有两张表,一张是水果表fruit,一张是价格表price。
建表:
create table price(
id int primary key auto_increment,
price double
);
create table fruit(
id int primary key auto_increment,
name varchar(20) not null,
price_id int,
foreign key(price_id) references price(id)
);
insert into price values(1,2.30);
insert into price values(2,3.50);
insert into price values(4,null);
insert into fruit values(1,'苹果',1);
insert into fruit values(2,'橘子',2);
insert into fruit values(3,'香蕉',null);
-- 一种水果有一个价格 一个价格对应多种水果
-- 价格 1 水果 n 水果将价格主键作为外键
什么是笛卡尔积现象
需求:查询两张表中关于水果的信息,要显示水果名称和水果价格。
具体操作:
多表查询语法:select * from fruit,price;
查询结果:

产生上述查询结果的原因:
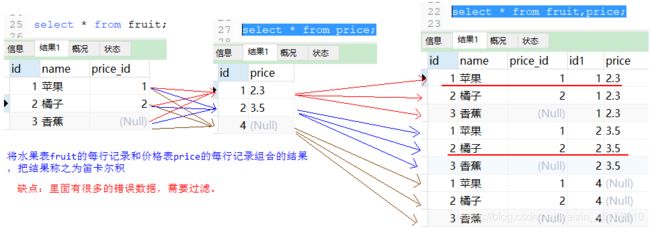
说明:
fruit表中的每一条记录,都和price表中的每一条进行匹配连接。所得到的最终结果是:fruit表中的条目数乘以price表中的数据的条目数。
将fruit表的每行记录和price表的每行记录组合的结果就是笛卡尔积。
笛卡尔积问题:把多张表放在一起,同时去查询,会得到一个结果,而这结果并不是我们想要的数据,这个结果称为笛卡尔积。
笛卡尔积缺点:查询到的结果冗余了,里面有很多错误的数据,需要过滤。
举例:上述的笛卡尔积结果中只有两行结果是正确的:
1 苹果 1 1 2.3
2 橘子 2 2 3.5
笛卡尔积的数据,对程序是没有意义的, 我们需要对笛卡尔积中的数据再次进行过滤。
对于多表查询操作,需要过滤出满足条件的数据,需要把多个表进行连接,连接之后需要加上过滤的条件。
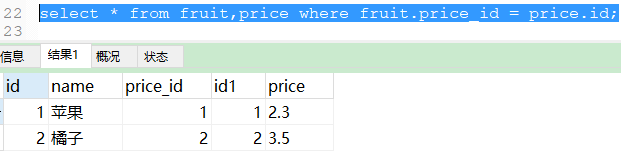
如何清除笛卡尔积现象的影响
解决上述查询的方案:在查询两张表的同时添加条件进行过滤,比如fruit表的id和必须和price表的id相同。
小结
- 能够说出什么是笛卡尔积?
左表的每条记录和右表的每条记录会组合起来 - 如何消除笛卡尔积
只查询满足要求的数据,通常都是外键等于主键
4、内连接
目标
能够掌握内连接的使用
讲解
什么是内连接
用左边表的记录去匹配右边表的记录,如果符合条件的则显示。内连接查询的结果:两表的公共部分。

隐式内连接
隐式内连接:看不到JOIN关键字,条件使用WHERE指定
语法:
select 列名 , 列名 .... from 表名1,表名2 where 表名1.列名 = 表名2.列名;
select * from fruit,price where fruit.price_id = price.id;
说明:在产生两张表的笛卡尔积的数据后,通过条件筛选出正确的结果。
显示内连接
显示内连接:使用INNER JOIN ... ON语句, 可以省略INNER
语法:
select * from 表名1 inner join 表名2 on 条件;
或者
select * from 表名1 join 表名2 on 条件
具体操作:
- 使用显示内连接解决上述笛卡尔积问题
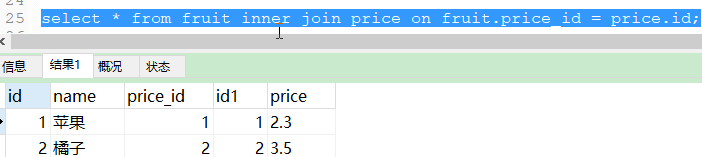
说明:显示的内连接,一般称为标准的内连接,有inner join,查询到的数据为两个表经过on条件过滤后的笛卡尔积。
小结
- 什么是隐式内连接和显示内连接?
隐式内连接:看不到JOIN:select 列名 , 列名 … from 表名1,表名2 where 表名1.列名 = 表名2.列名;
显示内连接:看得到JOIN:select * from 表名1 inner join 表名2 on 条件; - 内连接查询步骤?
1.确定查询几张表
2.确定表连接条件
3.根据需要在操作
5、左外连接
目标
能够掌握左外连接查询
讲解
左外连接原理如下所示:

左外连接可以理解为:用左边表去右边表中查询对应记录,不管是否找到,都将显示左边表中全部记录。
举例:上述案例中虽然右表没有香蕉对应的价格,也要把他查询出来。
左外连接:使用LEFT OUTER JOIN ... ON,OUTER可以省略
select * from 表1 left outer join 表2 on 条件;
把left 关键字之前的表,是定义为左侧。 left关键字之后的表,定义右侧。
查询的内容,以左侧的表为主,如果左侧有数据,右侧没有对应的数据,仍然会把左侧数据进行显示。
具体操作:
- 不管能否查到水果对应的价格,都要把水果显示出来。

分析:香蕉是没有价格的,但是由于香蕉位于左边的表中,所以即使香蕉的价格是null,也会将香蕉的信息显示出来。

小结
-
掌握左外连接查询格式?
select * from 表1 left outer join 表2 on 条件; -
左外连接查询特点?
在满足要求的基础上保证左表的数据全部显示
6、右外连接
目标
能够掌握右外连接查询
讲解
右外连接原理如下所示:
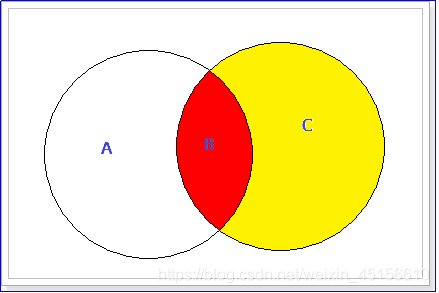
用右边表去左边表查询对应记录,不管是否找到,右边表全部记录都将显示。
举例:上述案例中不管在左方表能否找到右方价格对应的水果,都要把右方的价格显示出来。
右外连接:使用RIGHT OUTER JOIN ... ON,OUTER可以省略
语法:select * from 表1 right outer join 表2 on 条件;
说明:如果右侧有数据,左侧没匹配到,把右侧的数据显示出来。
right之前的是左侧,right之后的是右侧。
具体操作:
- 需求:不管能否查到价格对应的水果,都要把价格显示出来。

分析:在price表中id为4到fruit表中查询是没有对应水果描述的,但是使用右外连接也会将price表中的价格查询出来。

**注意:**其实关于左外连接和右外连接只记住一种就可以,只需将表的前后位置换一下就可以达到互换。
需求:使用左外连接达到上述右外连接的效果。

小结
-
掌握右外连接查询格式?
select * from 表1 right outer join 表2 on 条件; -
右外连接查询特点?
在满足要求的基础上,保证右表的数据全部显示.
7、子查询
目标
能够掌握子查询的概念
能够理解子查询的三种情况
讲解
准备数据:
-- 创建部门表
CREATE TABLE dept (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
INSERT INTO dept (NAME) VALUES ('开发部'),('市场部'),('财务部');
-- 创建员工表
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
gender CHAR(1), -- 性别
salary DOUBLE, -- 工资
join_date DATE, -- 入职日期
dept_id INT
);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('孙悟空','男',7200,'2013-02-24',1);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('猪八戒','男',3600,'2010-12-02',2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('唐僧','男',9000,'2008-08-08',2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('白骨精','女',5000,'2015-10-07',3);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('蜘蛛精','女',4500,'2011-03-14',1);
什么是子查询
一条查询语句结果作为另一条查询语法一部分。
SELECT 查询字段 FROM 表 WHERE 条件;
举例:
SELECT * FROM employee WHERE salary=(SELECT MAX(salary) FROM employee);
![]()
说明:子查询需要放在()中
子查询结果的三种情况
- 子查询的结果是单行单列的时候
![[外链图片转存失败(img-aYXRisy0-1562506426317)(img/%E5%AD%90%E6%9F%A5%E8%AF%A202.png)]](http://img.e-com-net.com/image/info8/75a5adeeefa7418fa15e72bf12283013.jpg)
- 子查询的结果是多行单列的时候
![[外链图片转存失败(img-GH1MwJna-1562506426318)(img/%E5%AD%90%E6%9F%A5%E8%AF%A203.png)]](http://img.e-com-net.com/image/info8/705d3fcc04d24faca876478281bc3100.png)
- 子查询的结果是多行多列
![[外链图片转存失败(img-StF79nfd-1562506426318)(img/%E5%AD%90%E6%9F%A5%E8%AF%A204.png)]](http://img.e-com-net.com/image/info8/279101a81f1c435caab939c872ae9d46.png)
小结
- 什么是子查询?
一个查询的结果作为另一个查询语句的一部分 - 子查询结果的三种情况?
单行单列
多行单列
多行多列
8、子查询的结果是单行单列的时候
目标
能够掌握子查询的结果是单行单列的查询
讲解
子查询结果是单列,在WHERE后面作为条件
SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
-
查询工资最高的员工是谁?
- 查询最高工资是多少
SELECT MAX(salary) FROM emp;![[外链图片转存失败(img-qhksXVdO-1562506426318)(img/%E5%AD%90%E6%9F%A5%E8%AF%A205.png)]](http://img.e-com-net.com/image/info8/a706bb7d84d24c0aa7493ab03d7879d9.jpg)
- 根据最高工资到员工表查询到对应的员工信息
SELECT * FROM emp WHERE salary=(SELECT MAX(salary) FROM emp);![[外链图片转存失败(img-txp7xnBM-1562506426318)(img/%E5%AD%90%E6%9F%A5%E8%AF%A206.png)]](http://img.e-com-net.com/image/info8/942d51f19739456fa3b511d613272427.png)
-
查询工资小于平均工资的员工有哪些?
- 查询平均工资是多少
SELECT AVG(salary) FROM emp;![[外链图片转存失败(img-ACiULQqL-1562506426319)(img/%E5%AD%90%E6%9F%A5%E8%AF%A207.png)]](http://img.e-com-net.com/image/info8/ca736053102c4e15b16bd2ac415c5242.png)
- 到员工表查询小于平均的员工信息
SELECT * FROM emp WHERE salary < (SELECT AVG(salary) FROM emp);![[外链图片转存失败(img-GeNkfPe8-1562506426319)(img/%E5%AD%90%E6%9F%A5%E8%AF%A208.png)]](http://img.e-com-net.com/image/info8/e32b0efd6ebd418a8aaba5417e05cd31.png)
小结
子查询的结果是单行单列时父查询如何处理?
SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
通常作为父查询的条件
9、子查询结果是多行单列的时候
目标
能够掌握子查询的结果是多行单列的查询
讲解
子查询结果是多行单列,结果集类似于一个数组,在WHERE后面作为条件,父查询使用IN运算符
SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
-
查询工资大于5000的员工,来自于哪些部门的名字
- 先查询大于5000的员工所在的部门id
SELECT dept_id FROM emp WHERE salary > 5000;[外链图片转存失败(img-K2PHI73e-1562506426319)(img/%E5%AD%90%E6%9F%A5%E8%AF%A209.png)]
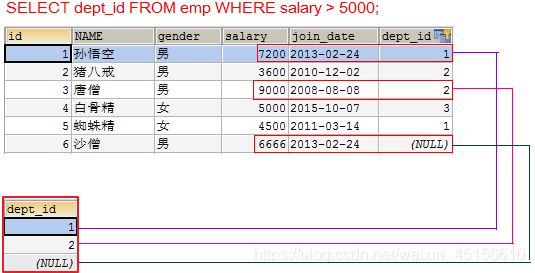
- 再查询在这些部门id中部门的名字
SELECT dept.name FROM dept WHERE dept.id IN (SELECT dept_id FROM emp WHERE salary > 5000);
-
查询开发部与财务部所有的员工信息
- 先查询开发部与财务部的id
SELECT id FROM dept WHERE NAME IN('开发部','财务部');
- 再查询在这些部门id中有哪些员工
SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE NAME IN('开发部','财务部'));
小结
子查询的结果是多行单列时父查询如何处理?
放在父查询的条件位置,使用in
10、子查询的结果是多行多列
目标
能够掌握子查询的结果是多行多列的查询
讲解
子查询结果是多列,在FROM后面作为表
SELECT 查询字段 FROM (子查询) 表别名 WHERE 条件;
注意:子查询作为表需要取别名,否则这张表没用名称无法访问表中的字段
-
查询出2011年以后入职的员工信息,包括部门名称
- 在员工表中查询2011-1-1以后入职的员工
SELECT * FROM emp WHERE join_date > '2011-1-1';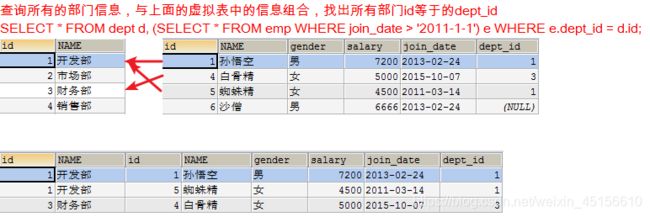
- 查询所有的部门信息,与上面的虚拟表中的信息组合,找出所有部门id等于dept_id
SELECT * FROM dept d, (SELECT * FROM emp WHERE join_date > '2011-1-1') e WHERE e.dept_id = d.id;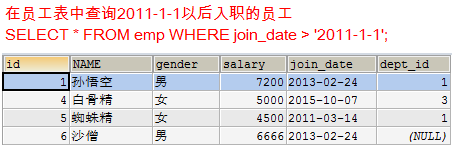
使用表连接:
SELECT d.*, e.* FROM dept d INNER JOIN emp e ON d.id = e.dept_id WHERE e.join_date > '2011-1-1';
小结
三种子查询情况:单行单列,多行单列,多行多列
单行单列:作为父查询的条件
多行单列:作为父查询的条件,通常使用 IN
多行多列:作为父查询的一张表(虚拟表)
11、多表查询案例
我们在公司开发中,根据不同的业务需求往往需要通过2张及以上的表中去查询需要的数据。所以我们有必要学习2张及以上的表的查询。其实不管是几张表的查询,都是有规律可循的。
准备数据
重新新建一个数据库,然后在新建的数据库中创建如下数据表,并插入数据:
teacher 教师表
student 学生表
cource 课程表
studentcource 选课表 学生和课程的关系表
create table teacher (
id int(11) not null primary key auto_increment,
name varchar(20) not null unique
);
create table student (
id int(11) not null primary key auto_increment,
name varchar(20) NOT NULL unique,
city varchar(40) NOT NULL,
age int
) ;
create table course(
id int(11) not null primary key auto_increment,
name varchar(20) not null unique,
teacher_id int(11) not null,
foreign key(teacher_id) references teacher (id)
);
create table studentcourse (
student_id int NOT NULL,
course_id int NOT NULL,
score double NOT NULL,
foreign key (student_id) references student (id),
foreign key (course_id) references course (id)
);
insert into teacher values(null,'关羽');
insert into teacher values(null,'张飞');
insert into teacher values(null,'赵云');
insert into student values(null,'小王','北京',20);
insert into student values(null,'小李','上海',18);
insert into student values(null,'小周','北京',22);
insert into student values(null,'小刘','北京',21);
insert into student values(null,'小张','上海',22);
insert into student values(null,'小赵','北京',17);
insert into student values(null,'小蒋','上海',23);
insert into student values(null,'小韩','北京',25);
insert into student values(null,'小魏','上海',18);
insert into student values(null,'小明','广州',20);
insert into course values(null,'语文',1);
insert into course values(null,'数学',1);
insert into course values(null,'生物',2);
insert into course values(null,'化学',2);
insert into course values(null,'物理',2);
insert into course values(null,'英语',3);
insert into studentcourse values(1,1,80);
insert into studentcourse values(1,2,90);
insert into studentcourse values(1,3,85);
insert into studentcourse values(1,4,78);
insert into studentcourse values(2,2,53);
insert into studentcourse values(2,3,77);
insert into studentcourse values(2,5,80);
insert into studentcourse values(3,1,71);
insert into studentcourse values(3,2,70);
insert into studentcourse values(3,4,80);
insert into studentcourse values(3,5,65);
insert into studentcourse values(3,6,75);
insert into studentcourse values(4,2,90);
insert into studentcourse values(4,3,80);
insert into studentcourse values(4,4,70);
insert into studentcourse values(4,6,95);
insert into studentcourse values(5,1,60);
insert into studentcourse values(5,2,70);
insert into studentcourse values(5,5,80);
insert into studentcourse values(5,6,69);
insert into studentcourse values(6,1,76);
insert into studentcourse values(6,2,88);
insert into studentcourse values(6,3,87);
insert into studentcourse values(7,4,80);
insert into studentcourse values(8,2,71);
insert into studentcourse values(8,3,58);
insert into studentcourse values(8,5,68);
insert into studentcourse values(9,2,88);
insert into studentcourse values(10,1,77);
insert into studentcourse values(10,2,76);
insert into studentcourse values(10,3,80);
insert into studentcourse values(10,4,85);
insert into studentcourse values(10,5,83);
分析4张表的关系:

练习1
目标
查询获得最高分的学生信息。
讲解
具体操作:
分析:
1)在中间表中找最高分;
2)在中间表中找最高分对应的学生编号;
3)在学生表中根据学生编号找学生信息;

练习2
目标
查询编号是2的课程比编号是1的课程最高成绩高的学生信息。
讲解
具体操作:
课程编号和对应的成绩的部分数据:

分析:
1)在中间表中 找编号是1的课程的最高成绩;
2)在中间表中 找编号是2的成绩 > 编号1最高成绩 的学生id;
3)在学生表中 根据学生的编号 找对应的学生信息;
Sql语句如下所示:
-- 需求2:查询编号2课程 比 编号1课程最高成绩高学生信息:
-- 2.1 在中间表 找编号1课程的最高成绩
select max(score)
from studentcourse
where course_id=1;
-- 2.2 在中间表 编号2的成绩 > 编号1最高成绩 的学生id
select student_id
from studentcourse
where course_id=2 and score>(select max(score)
from studentcourse
where course_id=1);
-- 2.3 在学生表 根据编号 找对应的学生信息
select *
from student
where id in (select student_id
from studentcourse
where course_id=2 and score>(select max(score)
from studentcourse
where course_id=1));
查询结果:
![[外链图片转存失败(img-APeLpPH9-1562506426321)(img/子查询练习3.bmp)]](http://img.e-com-net.com/image/info8/38b8f1d2ec964d56968d45026ffbd7f9.png)
练习3
目标
查询编号是2的课程比编号是1的课程最高成绩高的学生姓名和成绩(借助于临时表)。
讲解
具体操作:
分析:
1)在中间表中 找编号是1的课程的最高成绩;
2)在中间表中 找编号是2的成绩 > 编号1最高成绩 的学生id和成绩;
3)将上述查询出来的内容作为临时表 和 学生表关联, 查询姓名和成绩
-- 需求3:查询编号2课程比编号1课程最高成绩高学生姓名和成绩 (临时表)
-- 2.1 在中间表 找编号1课程的最高成绩
select max(score)
from studentcourse
where course_id=1;
-- 2.2 在中间表 编号2的成绩 > 编号1最高成绩 的学生id,成绩
select student_id,score
from studentcourse
where course_id=2 and score>(select max(score)
from studentcourse
where course_id=1);
-- 2.3 将上述查询出来的内容作为临时表 和 学生表关联, 查询姓名和成绩
select student.name, temp.score
from student, (select student_id,score
from studentcourse
where course_id=2 and score>(select max(score)
from studentcourse
where course_id=1)) as temp
where student.id=temp.student_id;
练习4
目标
查询每个同学的学号、姓名、选课数、总成绩。
讲解
分析:
1)、在中间表中查询每个学生的选课数和总成绩,遇到每个,分组,按照学生学号进行分组;
2)、由于还得显示学号和姓名,并且姓名在student表中,所以我们将上述结果作为临时表和学生表关联。
目的是查找临时表和student表中学号相等时查找学号,姓名,选课数,总成绩。
-- 2、查询所有同学的学号、姓名、选课数、总成绩
-- 2.1 在中间表 查询每个学生的选课数和总成绩
select student_id,count(*),sum(score)
from studentcourse
group by student_id;
-- 2.2 将2.1的结果作为临时表和学生表关联,
-- 目的: 显示 学号、姓名、选课数、总成绩
select student.id,student.name,temp.cou,temp.sumScore
from student,(select student_id,count(*) as cou,sum(score) as sumScore
from studentcourse
group by student_id) as temp
where student.id=temp.student_id;
注意:
如果我们想使用聚合函数作为查找的结果,并且聚合函数存在子查询语句中,那么我们不能直接将聚合函数写在select后面,我们此时应该给聚合函数取别名。
12、事务的概念
目标
能够理解事务的概念
讲解
事务的应用场景说明
关于事务在实际中的应用场景:
假设我在淘宝买了一部手机,然后当我付完款,钱已经从我的账户中扣除。正当此时,淘宝转账系统崩溃了,那么此时淘宝还没有收到钱,而我的账户的钱已经减少了,这样就会导致我作为买家钱已经付过,而卖家还没有收到钱,他们不会发货物给我。这样做显然是不合理。实际生活中是如果淘宝出问题,作为用户的账户中钱是不应该减少的。这样用户就不会损失钱。
还有种情况,就是当我付完款之后,卖家看到我付款成功,然后直接发货了,我如果有权限操作,我可以撤销,这样就会导致我的钱没有减少,但是卖家已经发货,同样这种问题在实际生活中也是不允许出现的。
关于上述两种情况,使用数据库中的事务可以解决。具体解决方案如下图所示:
说明:在数据库中查询不会涉及到使用事务,都是增删改。
什么是事务
在实际的业务开发中,有些业务操作要多次访问数据库。一个业务要发送多条SQL语句给数据库执行。需要将多次访问数据库的操作视为一个整体来执行,要么所有的SQL语句全部执行成功。如果其中有一条SQL语句失败,就进行事务的回滚,所有的SQL语句全部执行失败。
简而言之,事务指的是逻辑上的一组操作,组成这组操作的各个单元要么全都成功,要么全都失败。
事务作用:保证在一个事务中多次操作数据库表中数据时,要么全都成功,要么全都失败。
小结
什么是事务?多条SQL组合再一起完成某个功能.
13、手动提交事务
目标
能够使用手动的方式提交事务
讲解
MYSQL中可以有两种方式进行事务的操作:
- 手动提交事务:先开启,再提交
- 自动提交事务(默认的):即执行一条sql语句提交一次事务。
事务有关的SQL语句:
| SQL语句 | 描述 |
|---|---|
| start transaction; | 开启手动控制事务 |
| commit; | 提交事务 |
| rollback; | 回滚事务 |
手动提交事务使用步骤
第1种情况:开启事务 -> 执行SQL语句 -> 成功 -> 提交事务
第2种情况:开启事务 -> 执行SQL语句 -> 失败 -> 回滚事务

准备数据:
# 创建一个表:账户表.
create database day03_db;
# 使用数据库
use day03_db;
# 创建账号表
create table account(
id int primary key auto_increment,
name varchar(20),
money double
);
# 初始化数据
insert into account values (null,'a',1000);
insert into account values (null,'b',1000);
案例演示1:需求:演示提交事务,a给b转账100元。

案例演示2:演示回滚事务,a给b转账100元。(失败)
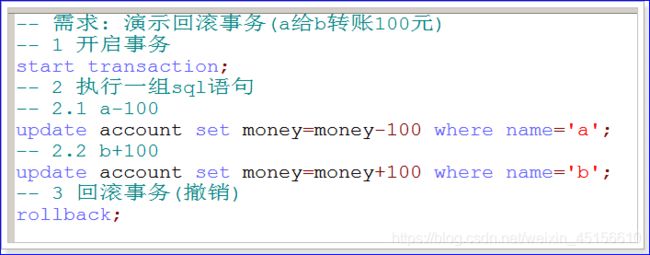
注意:
事务是如何处理正常情况的呢?
a=1000 b=1000
开启事务(start transaction;)
update account set money = money -100 where name=‘a’;
update account set money = money +100 where name=‘b’;
提交事务(commit;) (事务提交之后,sql语句对数据库产生的操作才会被永久的保存)
事务是如何处理异常情况的呢?
a=1000 b=1000
开启事务(start transaction;)
update t_account set money = money -100 where name=‘a’; a=900
出现异常
update t_account set money = money +100 where name=‘b’;
事务的回滚(rollback;)(撤销已经成功执行的sql语句,回到开启事务之前的状态)
a=1000 b=1000;
注意:只要提交事务,那么数据就会长久保存了,就不能回滚事务了。即提交或者回滚事务都是代表结束当前事务的操作。
小结
- 如何开启事务: start transaction;
- 如何提交事务: commit;
- 如何回滚事务: rollback;
14、自动提交事务
目标
了解自动提交事务
能够关闭自动提交事务
讲解
MySQL的每一条DML(增删改)语句都是一个单独的事务,每条语句都会自动开启一个事务,执行完毕自动提交事务,MySQL默认开始自动提交事务。自动提交,通过修改mysql全局变量“autocommit”进行控制。
1.通过以下命令可以查看当前autocommit模式:
show variables like '%commit%';
![[外链图片转存失败(img-r7Ue0al3-1562506426323)(img/自动提交事务.bmp)]](http://img.e-com-net.com/image/info8/d6495725dfc74fe2a25ffcbe313cc3e0.png)
2.设置自动提交的参数为OFF:
set autocommit = 0; -- 0:OFF 1:ON
小结
1)MySql默认自动提交。即执行一条sql语句提交一次事务。
2)设置autocommit为off状态,只是临时性的,下次重新启动mysql,autocommit依然变为on状态。
3)如果设置autocommit为off状态,那么当我们执行一条sql语句,就不会自动提交事务,重新启动可视化工具,数据并没有改变。
4)如果设置autocommit为on状态,如果我们先执行 start transaction; 然后在执行修改数据库的语句:
update account set money = money-100 where name=‘a’;
update account set money = money+100 where name=‘b’;
那么此时就表示上述修改数据库的sql语句都在同一个事务中,此时必须手动提交事务,即commit;
换句话说,如果我们手动开启事务 start transaction; 那么此时mysql就不会自动提交事务,必须手动提交事务。
5)如果设置autocommit为on状态,如果我们不执行 start transaction; 直接执行修改数据库的语句:
update account set money = money-100 where name=‘a’;
update account set money = money+100 where name=‘b’;
那么此时mysql就会自动提交事务。即上述每条sql语句就是一个事务。
6)l Oracle数据库事务不自动提交
课堂代码演示:
show variables like '%commit%';
set autocommit = 0;
start transaction;
update account set money = money-100 where name='a';
update account set money = money+100 where name='b';
commit;
rollback;
15、事务原理
目标
能够理解事务原理
讲解
事务开启之后, 所有的操作都会临时保存到事务日志, 事务日志只有在得到commit命令才会同步到数据表中,其他任何情况都会清空事务日志(rollback,断开连接)

小结
说出事务原理?
开启事务后,SQL语句会放在临时的日志文件中,如果提交事务,将日志文件中SQL的结果放在数据库中
如果回滚事务清空日志文件.
| 事务的操作 | MySQL操作事务的语句 |
|---|---|
| 开启事务 | start transaction |
| 提交事务 | commit |
| 回滚事务 | rollback |
| 查询事务的自动提交情况 | show variables like ‘%commit%’; |
| 设置事务的自动提交方式 | set autocommit = 0 – 关闭自动提交 |
16、事务的四大特性(ACID)(面试)
目标
了解事务的四大特性
讲解
数据库的事务必须具备ACID特性,ACID是指 Atomicity(原子性)、Consistensy(一致性)、Isolation(隔离型)和Durability(持久性)的英文缩写。
1、隔离性(Isolation)
多个用户并发的访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间要相互隔离。
一个事务的成功或者失败对于其他的事务是没有影响。2个事务应该相互独立。
举例:
a 给b转账 -----》叫做事务A
c 给d 转账 -----》叫做事务B
事务A和事务B之间不会相互影响。
2、持久性(Durability)
指一个事务一旦被提交,它对数据库的改变将是永久性的,哪怕数据库发生异常,重启之后数据亦然存在。
举例:
a=1000、b=1000转账
开启事务
a-100
b+100
提交
结果: a 900 b 1100
即使事务提交以后再发生异常,a和b的数据依然不会变。a就是900 b就是1100。
3、原子性(Atomicity)
原子性是指事务包装的一组sql(一组业务逻辑)是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
4、一致性(Consistency)
一个事务在执行之前和执行之后 数据库都必须处于一致性状态。
如果事务成功的完成,那么数据库的所有变化将生效。
如果事务执行出现错误,那么数据库的所有变化将会被回滚(撤销),返回到原始状态。
事务的成功与失败,最终数据库的数据都是符合实际生活的业务逻辑。一致性绝大多数依赖业务逻辑和原子性。
举例1: a=1000、b=1000 转账 100
a - 100
b + 100
结果: a + b = 2000
如果a转账失败了,那么b也得失败。不能因为a失败了,a依然是1000.但是b却成功了,b却变成了1100.那么结果是2100了,这样是不符合事务的一致性的。
小结
事务四个特性?
原子性
一致性
隔离性
持久性
| 事务特性 | 含义 |
|---|---|
| 原子性(Atomicity) | 事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 |
| 一致性(Consistency) | 事务前后数据的完整性必须保持一致 |
| 隔离性(Isolation) | 是指多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离,不能相互影响。 |
| 持久性(Durability) | 指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响 |
17、事务的并发访问引发的三个问题(面试)
目标
能够理解并发访问的三个问题
讲解
事务在操作时的理想状态:多个事务之间互不影响,如果隔离级别设置不当就可能引发并发访问问题。
| 并发访问的问题 | 含义 |
|---|---|
| 脏读 | 一个事务读取到了另一个事务中尚未提交的数据。最严重,杜绝发生。 |
| 不可重复读 | 一个事务中两次读取的数据内容不一致,要求的是一个事务中多次读取时数据是一致的,这是事务update时引发的问题 |
| 幻读 | 一个事务内读取到了别的事务插入的数据,导致前后读取记录行数不同。这是insert或delete时引发的问题 |
1.脏读:指一个事务读取了另外一个事务未提交的数据。(非常危险)
脏读具体解释如下图所示:注意脏读的前提是没有事务的隔离性。

说明:事务a首先执行转账操作,然后事务a还没有提交数据的情况下,事务b读取了数据库的数据。紧接着事务a执行回滚操作,导致事务b读取的结果和数据库的实际数据是不一样的。
一个事务读取了另一个事务未提交的数据叫做脏读。
举例:
a 转账 给b 100,未提交
b 查询账户多了100
a 回滚
b 查询账户那100不见了。
一个事务读取了另一个事务没有提交的数据,非常严重,必须避免脏读。
2.不可重复读:在一个事务内多次读取表中的数据,多次读取的结果不同。

说明:事务b首先读取数据库的数据,然后事务a对数据修改并提交。之后事务b对数据库再次进行读取。这时发现在事务b中2次读取的结果不一致。
一个事务内读取了另一个事务提交的数据。这个叫做不可重复读。
不可重复读和脏读的区别:
脏读:强调的是读取了未提交的数据。
不可重复读:一个事务内2次读取,其中一次读取了另一个事务提交了的数据。
例如: 银行想查询A账户的余额,第一次查询的结果是200元,A向账户中又存了100元。此时,银行再次查询的结果变成了300元。两次查询的结果不一致,银行就会很困惑,以哪次为准。
和脏读不同的是:脏读读取的是前一事务未提交的数据,不可重复度 读取的是前一事务已提交的事务。
很多人认为这有啥好困惑的,肯定是以后面的结果为准了。我们需要考虑这样一种情况,查询A账户的余额,一个打印到控制台,一个输出到硬盘上,同一个事务中只是顺序不同,两次查询结果不一致,到底以哪个为准,你会不会困惑呢?
当前事务查询A账户的余额为100元,另外一个事务更新余额为300元并提交,导致当前事务使用同一查询结果却变成了300元。
3.幻读(虚读):一个事务内读取到了别的事务插入或者删除的数据,导致前后读取记录行数不同

说明:事务b首先读取数据的数量,然后事务a添加了一条数据,并且提交了。接着事务b再次读取了数据的数量。2次读取不一致。
同一个事务内,2次读取的数据的数量不一致,叫做幻读或者虚读。
虚读(幻读)和不可重复读的区别:
不可重复读:强调的是数据内容的不一致。另一个事务是update操作。
虚读(幻读):强调的数据的数量(记录数)的不一致。另一个事务是insert或者delete操作。
注意:
指在一个事务中 读取 另一个事务 插入或删除 数据记录,导致当前事务读取数据的记录数前后不一致。
一个事务读取另一个事务已经提交的数据,强调的是记录数的变化,常用sql类型为 insert和 delete。
小结
- 能够理解并发访问的三个问题
赃读:一个事务读取另一个事务还没有提交的数据
不可重复读:一个事务读取多次数据内容不一样
幻读:一个事务读取多次数量不一样
18、事务的隔离级别
目标
能够说出mysql的四种隔离级别
讲解
1、通过以上问题演示,我们发现如果不考虑事务的隔离性,会遇到脏读、不可重复读和虚读等问题。所以在数据库中我们要对上述三种问题进行解决。MySQL数据库规范规定了4种隔离级别,分别用于描述两个事务并发的所有情况。
上面的级别最低,下面的级别最高。“是”表示会出现这种问题,“否”表示不会出现这种问题。
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 | 数据库默认隔离级别 |
|---|---|---|---|---|---|---|
| 1 | 读未提交 | read uncommitted | 是 | 是 | 是 | |
| 2 | 读已提交 | read committed | 否 | 是 | 是 | Oracle和SQL Server |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是 | MySQL |
| 4 | 串行化 | serializable | 否 | 否 | 否 |
2、安全和性能对比
安全性:serializable > repeatable read > read committed > read uncommitted
性能 : serializable < repeatable read < read committed < read uncommitted
3、注意:其实三个问题,开发中最严重的问题就是脏读,这个问题一定要避免,而关于不可重复读和虚读其实只是感官上的错误,并不是逻辑上的错误。就是数据的时效性,所以这种问题并不属于很严重的错误。如果对于数据的时效性要求不是很高的情况下,我们是可以接受不可重复读和虚读的情况发生的。
小结
能够说出mysql的四种隔离级别
读未提交:read uncommitted
读已提交:read committed
可重复读:repeatable read
串行化:serializable
19、脏读的演示
目标
- 能够设置mysql的隔离级别
- 能够解决赃读
讲解
查询和设置隔离级别
-
查询全局事务隔离级别
show variables like '%isolation%'; -- 或 select @@tx_isolation;
-
设置事务隔离级别,需要退出MSQL再进入MYSQL才能看到隔离级别的变化
set global transaction isolation level 隔离级别; -- 如: set global transaction isolation level read uncommitted;
脏读的演示
脏读:一个事务读取到了另一个事务中尚未提交的数据。
- 打开一个窗口,设置为A窗口,登录MySQL,设置全局的隔离级别为最低
-- 设置窗口名字A title A -- 登录mysql数据库 mysql -u root -p 1234 -- 设置事务隔离级别 set global transaction isolation level read uncommitted; -- 查询隔离级别 select @@tx_isolation;
注意:设置事务隔离级别,需要重新打开一个窗口才能看到隔离级别的变化.
2.重新打开一个新的窗口,设置为B窗口,登录mysql
-- 设置窗口名字B
title B;
-- 登录mysql数据库
mysql -u root -p
1234
3.AB窗口都开启事务
use day05_db;
start transaction;

4.A窗口更新2个人的账户数据,未提交
update account set money=money-500 where id=1;
update account set money=money+500 where id=2;
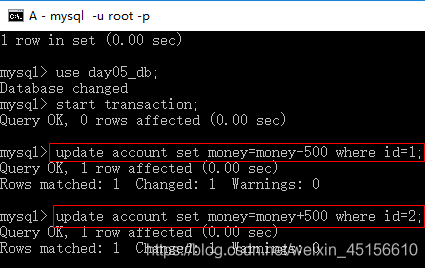
5.B窗口查询账户
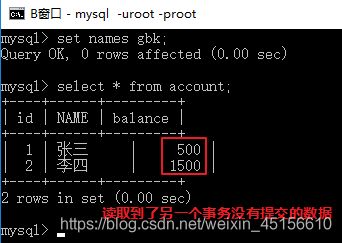
select * from account;
6.A窗口回滚
rollback;

7.B窗口查询账户,钱没了

脏读非常危险的,比如张三向李四购买商品,张三开启事务,向李四账号转入500块,然后打电话给李四说钱已经转了。李四一查询钱到账了,发货给张三。张三收到货后回滚事务,李四的再查看钱没了。
解决脏读的问题:将全局的隔离级别进行提升
- 在A窗口设置全局的隔离级别为
read committedset global transaction isolation level read committed;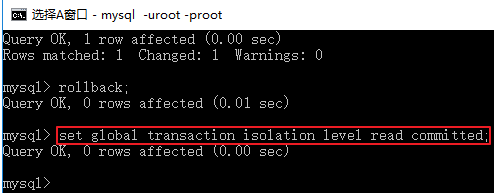
- B窗口退出MySQL,B窗口再进入MySQL
- AB窗口同时开启事务

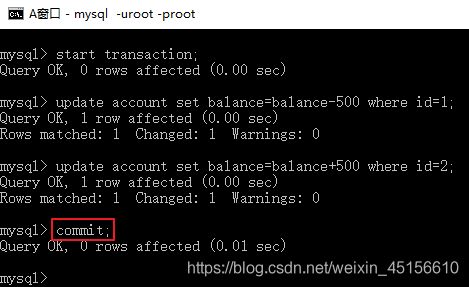
- A更新2个人的账户,未提交
update account set money=money-500 where id=1; update account set money=money+500 where id=2;
- B窗口查询账户
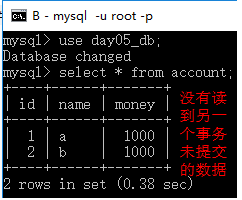
- A窗口commit提交事务
- B窗口查看账户
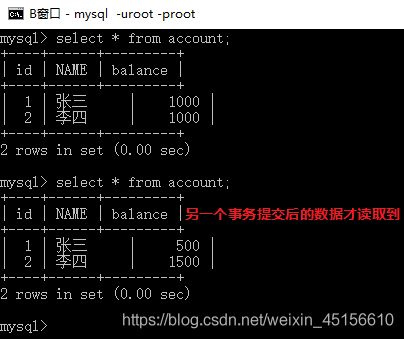
结论:read committed的方式可以避免脏读的发生
小结
- 查询全局事务隔离级别?
show variables like ‘%isolation%’;
select @@tx_isolation; - 设置全局事务隔离级别?
set global transaction isolation level 隔离级别字符串; - 如何解决赃读?
将隔离级别设置为:read committed
总结
-
能够理解三大范式
1NF: 表中的字段不能再拆分
2NF:一个表做一件事情,表中添加主键,所有字段依赖主键
3NF:多张表之间使用其他表的主键 -
能够使用内连接进行多表查询
隐式: SELECT 字段 FROM 左表, 右表 WHERE 条件;显示: SELECT 字段 FROM 左表 INNER JOIN 右表 ON 条件;
-
能够使用左外连接和右外连接进行多表查询
左外连接: SELECT 字段 FROM 左表 LEFT OUTER JOIN 右表 ON 条件;
右外连接: SELECT 字段 FROM 左表 RIGHT OUTER JOIN 右表 ON 条件; -
能够使用子查询进行多表查询
SELECT 字段 FROM 表名 WHERE 字段=(SELECT MAX(age) FROM 表名); -
能够理解多表查询的规律
1.明确查询哪些表
2.明确表之间的连接条件,外键=主键
3.根据需求 -
能够理解事务的概念
多条SQL语句组成一个功能,要么一起成功,要么一起失败. -
能够说出事务的原理
当开始事务后,执行的SQL会放在临时日志文件中.提交数据时,日志文件中的数据就会放到数据库中,如果回滚事务,清空日志文件 -
能够在MySQL中使用事务
开启事务: start transaction;
提交事务: commit;
回滚事务: rollback;
查看是否自动提交事务: show variables like ‘%commit%’;
关闭事务自动提交: set autocommit = 0; -
能够理解脏读,不可重复读,幻读的概念及解决办法
脏读: 一个事务读到另一个事务还没有提交的数据, 将隔离级别设置为 read commited;
不可重复读:一个事务多次读取,每次数据不一样,将隔离级别设置为 repeatable read;
幻读: 一个事务多次读取,数量不一样,将隔离级别设置为 serializable;