python爬虫实战系列:(二)爬取整个网页数据
python爬虫实战系列
本系列主要学习python爬虫的实战项目,需要源码欢迎关注留言私信
文章目录
- python爬虫实战系列
- 1.爬取某租房软件下网页所有信息
- 2.爬取某快餐店地址信息
- 3.小结
requests爬取网页信息具体如下
- 1.指定url
- 2.UA伪装
- 3.发出请求
- 4.获取数据
- 5.保存数据
1.爬取某租房软件下网页所有信息
首先打开网页选择要租房的区域。打开抓包工具(F12),找到network。从中找到我们需要的信息
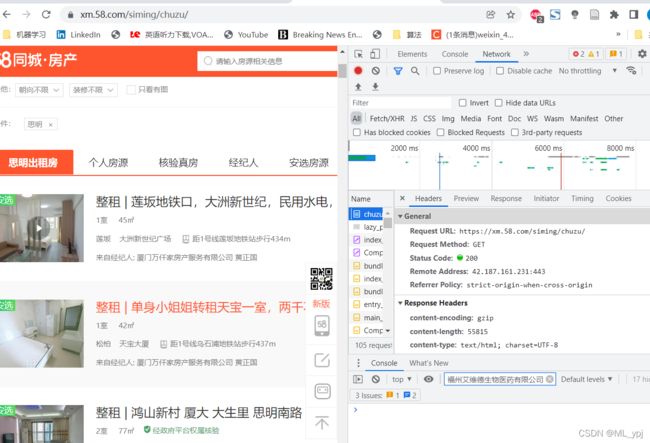
1.URL从request URL中寻找
2.请求方式,本例为get
3.参数从playload中找
4.数据类型找到content-type:本例为text数据
下面我们开始爬取
#author = 'ml_ypj'
#date:2022-03-30 15:42
import requests
if __name__ == '__main__':
# 指定url
url = 'https://xm.58.com/siming/chuzu/'
# ua伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
# 发出请求
response = requests.get(url=url, headers=headers)
page_text = response.text # 刚刚我们看到了此网站的数据形式为text
# 存储数据为html文件
with open('./fangjia.html','w',encoding='utf-8') as fp:
fp.write(page_text)
这样就生成了fangjia.html的一个文件
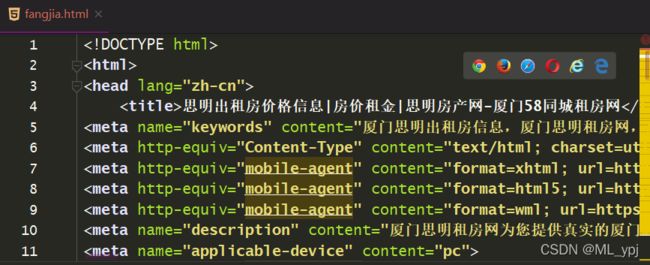
在浏览器打开html文件得到如下页面:
下面我们看一个动态访问的网页,此时是一个ajax请求。我们看看如何爬取
2.爬取某快餐店地址信息
首先打开网站,选择network中的Fetch/XHR,可以看到一个ajax请求,我们点进去可以发现其具体的信息。
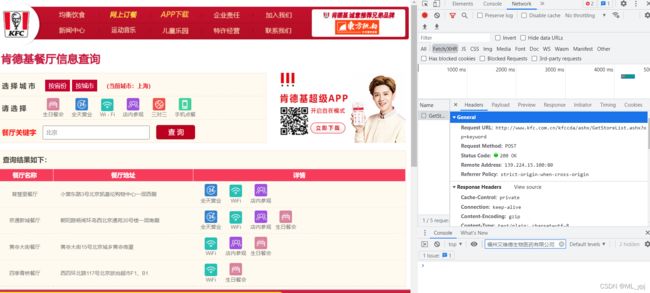
1.URL从request URL中寻找
2.请求方式,本例为Post
3.参数从playload中找
4.数据类型找到content-type:本例为text数据
下面我们开始爬取
#author = 'ml_ypj'
#date:2022-03-30 19:23
import requests
import json
if __name__ == '__main__':
# 指定url
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
# ua伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
# 自己手动输入区域
word = input('请输入一个单词')
# 定义参数
param = {
'cname':'',
'pid':'',
'keyword': word,#表示区域
'pageIndex': '1',#表示第几页
'pageSize': '10'#表示一页几行
}
# 发出请求
response = requests.post(url=url,params=param,headers=headers)#通过抓包工具看request method判断是post还是get
text = response.text #通过抓包工具看content-type看是text还是json
with open('./kfc.json','w',encoding='utf-8') as fp:
json.dump(text,fp,ensure_ascii=False)
print('结束')
得到一个kfc.json文件,将其格式化转换后得到下面结果:

3.小结
本章介绍的是爬虫中最基本的通用爬取,我们只是爬取了每个网页的整个页面的内容,在实际应用中,我们可能更多地是要获取网页的某一部分信息,在后续文章中,我们会进行爬取页面的某一部分内容。例如:爬取房子的地址,价格并将其存入文本文件中。