Python爬虫实战(二):爬取快代理构建代理IP池
目录
- 前言
- 构建IP池的目的
- 爬取目标
- 准备工作
- 代码分析
-
- 第一步
- 第二步
- 第三步
- 第四步
- 第五步
- 完整代码
- 使用方法
前言
博主开始更新爬虫实战教程了,期待你的关注!!!
第一篇:Python爬虫实战(一):翻页爬取数据存入SqlServer
第二篇:Python爬虫实战(二):爬取快代理构建代理IP池
点赞收藏博主更有创作动力哟,以后常更!!!

构建IP池的目的
使用爬虫时,大部分网站都有一定的反爬措施,有些网站会限制每个 IP 的访问速度或访问次数,超出了它的限制你的 IP 就会被封掉。对于访问速度的处理比较简单,只要间隔一段时间爬取一次就行了,避免频繁访问;而对于访问次数,就需要使用代理 IP 来帮忙了,使用多个代理 IP 轮换着去访问目标网址可以有效地解决问题。
目前网上有很多的代理服务网站提供代理服务,也提供一些免费的代理,但可用性较差,如果需求较高可以购买付费代理,可用性较好。当然我们也可以自己构建代理池,从各种代理服务网站中免费获取代理 IP,并检测其可用性(去访问百度),再保存到文件中,需要使用的时候再调用。

爬取目标
我们要爬取的网页是:https://www.kuaidaili.com/free/inha/
红色框就是我们要爬取的内容:

博主爬取最后实现的效果如下:
准备工作
我用的是python3.8,VScode编辑器,所需的库有:requests、etree、time
开头导入所需用到的导入的库:
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import time # 防止爬取过快可以睡眠一秒
准备就绪开始代码分析!
代码分析

先讲讲我的整体思路在逐步分析:
- 第一步:构造主页url地址,发送请求获取响应
- 第二步:解析数据,将数据分组
- 第三步:将数组的数据提取出来
- 第四步:检测代理IP的可用性
- 第五步:保存到文件中
第一步
构造主页的url地址,发送请求获取响应
# 1.发送请求,获取响应
def send_request(self,page):
print("=============正在抓取第{}页===========".format(page))
# 目标网页,添加headers参数
base_url = 'https://www.kuaidaili.com/free/inha/{}/'.format(page)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
# 发送请求:模拟浏览器发送请求,获取响应数据
response = requests.get(base_url,headers=headers)
data = response.content.decode()
time.sleep(1)
return data
这会就有小伙伴不明白了,你headers什么意思啊?
- 防止服务器把我们认出来是爬虫,所以模拟浏览器头部信息,向服务器发送消息
- 这个 “装” 肯定必须是要装的!!!

第二步
解析数据,将数据分组
从下图可以看出,我们需要的数据都在tr标签中:

所以分组取到tr标签下:
# 2.解析数据
def parse_data(self,data):
# 数据转换
html_data = etree.HTML(data)
# 分组数据
parse_list = html_data.xpath('//table[@class="table table-bordered table-striped"]/tbody/tr')
return parse_list
第三步
提取分组中我们需要的数据,IP,类型和端口号
parse_list = self.parse_data(data)
for tr in parse_list:
proxies_dict = {}
http_type = tr.xpath('./td[4]/text()')
ip_num = tr.xpath('./td[1]/text()')
port_num = tr.xpath('./td[2]/text()')
http_type = ' '.join(http_type)
ip_num = ' '.join(ip_num)
port_num = ' '.join(port_num)
proxies_dict[http_type] = ip_num + ":" + port_num
proxies_list.append(proxies_dict)
这里做了拼接,{'HTTP': '36.111.187.154:8888'}这种形式存入列表,方便我们使用!

第四步
检测IP的可用性,因为是免费的IP所以有一些可能用不了,有一些访问速度较慢,这里我们让拼接好的ip去访问某度
0.1秒能访问成功的保存在另一个列表中!
def check_ip(self,proxies_list):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
can_use = []
for proxies in proxies_list:
try:
response = requests.get('https://www.baidu.com/',headers=headers,proxies=proxies,timeout=0.1)
if response.status_code == 200:
can_use.append(proxies)
except Exception as e:
print(e)
return can_use

第五步
将访问速度不错的ip保存在文件中,方便我们调用
def save(self,can_use):
file = open('IP.txt', 'w')
for i in range(len(can_use)):
s = str(can_use[i])+ '\n'
file.write(s)
file.close()
完整代码
import requests
from lxml import etree
import time
class daili:
# 1.发送请求,获取响应
def send_request(self,page):
print("=============正在抓取第{}页===========".format(page))
# 目标网页,添加headers参数
base_url = 'https://www.kuaidaili.com/free/inha/{}/'.format(page)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
# 发送请求:模拟浏览器发送请求,获取响应数据
response = requests.get(base_url,headers=headers)
data = response.content.decode()
time.sleep(1)
return data
# 2.解析数据
def parse_data(self,data):
# 数据转换
html_data = etree.HTML(data)
# 分组数据
parse_list = html_data.xpath('//table[@class="table table-bordered table-striped"]/tbody/tr')
return parse_list
# 4.检测代理IP
def check_ip(self,proxies_list):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
can_use = []
for proxies in proxies_list:
try:
response = requests.get('https://www.baidu.com/',headers=headers,proxies=proxies,timeout=0.1)
if response.status_code == 200:
can_use.append(proxies)
except Exception as e:
print(e)
return can_use
# 5.保存到文件
def save(self,can_use):
file = open('IP.txt', 'w')
for i in range(len(can_use)):
s = str(can_use[i])+ '\n'
file.write(s)
file.close()
# 实现主要逻辑
def run(self):
proxies_list = []
# 实现翻页,我这里只爬取了四页(可以修改5所在的数字)
for page in range(1,5):
data = self.send_request(page)
parse_list = self.parse_data(data)
# 3.获取数据
for tr in parse_list:
proxies_dict = {}
http_type = tr.xpath('./td[4]/text()')
ip_num = tr.xpath('./td[1]/text()')
port_num = tr.xpath('./td[2]/text()')
http_type = ' '.join(http_type)
ip_num = ' '.join(ip_num)
port_num = ' '.join(port_num)
proxies_dict[http_type] = ip_num + ":" + port_num
proxies_list.append(proxies_dict)
print("获取到的代理IP数量:",len(proxies_list))
can_use = self.check_ip(proxies_list)
print("能用的代理IP数量:",len(can_use))
print("能用的代理IP:",can_use)
self.save(can_use)
if __name__ == "__main__":
dl = daili()
dl.run()
启动后的效果如下:
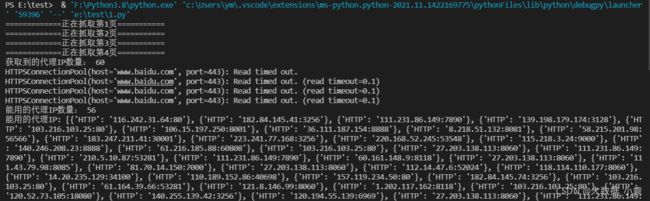
并生成文件:
O了O了!!!

使用方法
IP保存在文件中了,可有一些小伙伴还不知道怎么去使用?
这里我们需要实现,从文件中随机取出一个IP去访问网址,用到了random库
import random
import requests
# 打开文件,换行读取
f=open("IP.txt","r")
file = f.readlines()
# 遍历并分别存入列表,方便随机选取IP
item = []
for proxies in file:
proxies = eval(proxies.replace('\n','')) # 以换行符分割,转换为dict对象
item.append(proxies)
proxies = random.choice(item) # 随机选取一个IP
url = 'https://www.baidu.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
response = requests.get(url,headers=headers,proxies=proxies)
print(response.status_code) # 输出状态码 200,表示访问成功
有讲的不对的地方,希望各位大佬指正!!!,如果有不明白的地方评论区留言回复!兄弟们来个点赞收藏有空就更新爬虫实战!!!
