sklearn实战之逻辑回归与制作评分卡
sklearn实战系列:
(1) sklearn实战之决策树
(2) sklearn实战之随机森林
(3) sklearn实战之数据预处理与特征工程
(4) sklearn实战之降维算法PCA与SVD
(5) sklearn实战之逻辑回归与制作评分卡
(6) sklearn实战之聚类算法
五、逻辑回归与评分卡
0、概述
0.1 名为“回归”的分类器
在之前的4篇文章中,我们接触了不少带“回归”二字的算法,回归树,随机森林的回归,无一例外他们都是区分与于分类的算法,用来处理和预测连续型标签的算法。然而逻辑回归,是一种名为“回归”的线性分类器,其本质是由线性回归变化而来的,一种广泛使用于分类问题中的广义线性回归算法。要理解逻辑回归从何而来,得要先理解线性回归。线性回归是机器学习中最简单的回国算法,它写作一个几乎人人都知道的方程:
z = θ 0 + θ 1 x 1 + θ 2 x 2 + … + θ n x n z=\theta_0+\theta_1x_1+\theta_2x_2+…+\theta_nx_n z=θ0+θ1x1+θ2x2+…+θnxn
θ \theta θ被统称为模型的参数,其中 θ 0 \theta_0 θ0被称为截距(intercept), θ 1 ∼ θ n \theta_1\sim\theta_n θ1∼θn被称为系数(coefficient),这个表达式,其实就是我们小学时就无比熟悉的 y = a x + b y=ax+b y=ax+b是同样的性质。我们可以使用矩阵来表示这个方程,其中x和 θ \theta θ都可以被看作一个列矩阵,则有:
z = [ θ 0 , θ 1 , θ 2 , … , θ n ] ∗ [ x 0 x 1 x 2 … x n ] = θ T x ( x 0 = 1 ) z=[\theta_0,\theta_1,\theta_2,…,\theta_n]* \begin{bmatrix} x_0 \\ x_1 \\ x_2 \\ … \\ x_n \end{bmatrix}=\theta^Tx(x_0=1) z=[θ0,θ1,θ2,…,θn]∗⎣⎢⎢⎢⎢⎡x0x1x2…xn⎦⎥⎥⎥⎥⎤=θTx(x0=1)
线性回归的任务,就是构造一个预测函数
z来映射特征矩阵x和标签纸y的线性关系,而构造预测函数就是找出模型的参数:$ \theta^T和\theta_0 $,最著名的最小二乘法就是用来求解线性回归中参数的数学方法。
通过函数z,线性回归使用输入的特征矩阵X来输出一组连续行的标签纸y_pred,以完成各种预测连续型变量的任务(比如预测产品销量,预测股价等)。那如果我们的标签是离散型变量,尤其是,如果是满足0-1分布的离散型变量,我们要怎么办?我们可以通过引入联系函数(link function),将线性回归方程z变换为g(z),并且令g(z)的值分布在(0,1)之间,且当g(z)接近0时样本的标签为类别0,当g(z)接近1时样本的标签为类别1,这样就得到了一个分类模型,而这个练习函数对于逻辑回归来说,就是sigmoid函数:
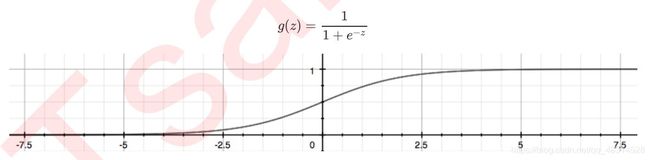
面试高危问题:Sigmoid函数的公式和性质:
Sigmoid函数是一个S型的函数,当自变量z趋近正无穷时,因变量g(z)趋近于1,而当z趋近于负无穷时,g(z)趋近于0,他能够将任何将任何实数映射到(0,1)区间,使其可用于将任意值函数转换为更适合二分类的函数。
因为这个性质,sigmoid也可以被当作归一化的一种方法,与我们之前学过的MinMaxScaler同理,是属于数据预处理的“缩放”功能,可以将数据压缩到[0,1]之间。区别在于,MinMaxScaler归一化之后,是可以取到0和1 的(最大值归一化后就是1,最小值是0),但Sigmoid只是无线趋近于0和1。
线性回归中的 z = θ T x z=\theta^Tx z=θTx,于是我们将z带入,就得到了二元逻辑回归模型的一般形式:
g ( z ) = y ( x ) = 1 1 + e − θ T x g(z)=y(x)=\frac{1}{1+e^{-\theta^Tx}} g(z)=y(x)=1+e−θTx1
而y(x)就是我们逻辑回归返回的标签值。此时,y(x)的取值都在[0,1]之间,因此y(x)和1-y(x)相加必然为1。如果我们令y(x)除以1-y(x)得到形似几率(oods)的 y ( x ) 1 − y ( x ) \frac{y(x)}{1-y(x)} 1−y(x)y(x),在此基础上取对数,可以很容易得到:
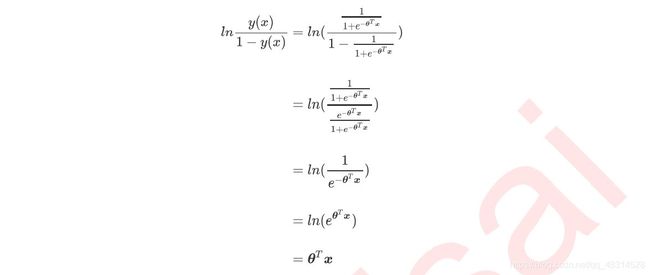
不然发现,y(x)的形似几率对数的本质其实就是我们的线性回归z,我们实际上是在对线性回归模型的预测结果取对数几率来让其的结果无线逼近0和1。因此,其对应的模型被称为“对数几率回归"(logisitic Regression),也就是我们的逻辑回归,这个名为”回归“确实做分类工作的分类器。
之前我们提到过,线性回归的核心任务是通过求解 θ \theta θ构建z这个预测函数,并希望预测函数z能够尽量拟合数据,因此逻辑回归的核心任务也是类似的:构建 θ \theta θ来构建一个能够尽量拟合数据的预测函数y(x),并通过向预测函数中输入特征矩阵来获取相应的标签值y。
思考:y(x)代表了样本为某一类标签的概率吗?
l n y ( x ) 1 − y ( x ) ln \frac{y(x)}{1-y(x)} ln1−y(x)y(x)是形似对数几率的一种变化。而几率oods的本质其实是 p 1 − p \frac{p}{1-p} 1−pp,其中p是时间A发生的概率,而1-p是实现A不会发生的概率,并且p+(1-p)=1。并且,很多人在理解逻辑回归中,都对y(x)作出如下的解释:我们让线性回归的结果逼近0和1,此时y(x)和1-y(x)之和为1,因此他们可以被我们看作是一堆正反例发生的概率,即y(x)是某样本i的标签被预测为1 的概率而 是i的标签被预测为0的概率, 就是样本i的 标签被预测为1的相对概率。基于这种理解,我们使用最大似然法和概率分布函数推到出逻辑回归的损失函 数,并且把返回样本在标签取值上的概率当成是逻辑回归的性质来使用,每当我们诉求概率的时候,我们都会 使用逻辑回归。
然而这种理解是正确的吗?概率是度量偶然事件发生可能性的数值,尽管逻辑回归的取值在(0,1)之间,并且 和 之和的确为1,但光凭这个性质,我们就可以认为 代表了样本x在标签上取值为1的概率 吗?设想我们使用MaxMinScaler对特征进行归一化后,任意特征的取值也在[0,1]之间,并且任意特征的取值 和 也能够相加为1,但我们却不会认为0-1归一化后的特征是某种概率。逻辑回归返回了概率这个命题,这种说法严谨吗?
但无论如何,长年以来人们都是以”返回概率“的方式来理解逻辑回归,并且这样使用它的性质。可以说,逻辑 回归返回的数字,即便本质上不是概率,却也有着概率的各种性质,可以被当成是概率来看待和使用。
0.2 为什么需要逻辑回归?
线性回归对数据的要求很严格,比如标签必须满足正态分布,特征之间的多重共线性需要消除等等,然而现实中很多真实情景的数据无法满足这些眼球,因此线性回归在很多显示情景的应用效果是有限的。逻辑回归是由线性回归变化而来,一次它对数据也有一些要求,而我们之前已经学过了强大的分类模型决策树和随机森林,他们的分类效力很强,并且不需要对数据做任何预处理。
何况,逻辑回归的原理其实并不简单。一个人要理解逻辑回归,必须要有一定的数学基础,必须理解损失函数,正则化,梯度下降,海森矩阵等等这些复杂的概念,才能够对逻辑回归进行调优。其涉及到的数学理念,不比支持向量机少多少。况且,要计算概率,朴素贝特斯可以计算真正意义上的概率,要进行分类,机器学习中能够完成二分类类功能的模型简直多如牛毛。因此,在数据挖掘,人工智能所涉及到的医疗,教育,人脸识别,语音识别这些领 域,逻辑回归没有太多的出场机会。
甚至,在我们的各种机器学习经典书目中,周志华的《机器学习》400页仅有一页纸是关于逻辑回归的(还是一页 数学公式),《数据挖掘导论》和《Python数据科学手册》中完全没有逻辑回归相关的内容,sklearn中对比各种 分类器的效应也不带逻辑回归玩,可见业界地位。
但是,无论机器学习领域如何折腾,逻辑回归依然是一个受工业商业热爱,使用广泛的模型,因为它有着不可替代 的优点:
1、逻辑回归对线性关系的拟合效果好到丧心病狂,特征与标签之间的线性关系极强的数据,比如金融领域中的 信用卡欺诈,评分卡制作,电商中的营销预测等等相关的数据,都是逻辑回归的强项。虽然现在有了梯度提 升树GDBT,比逻辑回归效果更好,也被许多数据咨询公司启用,但逻辑回归在金融领域,尤其是银行业中的 统治地位依然不可动摇(相对的,逻辑回归在非线性数据的效果很多时候比瞎猜还不如,所以如果你已经知 道数据之间的联系是非线性的,千万不要迷信逻辑回归)
2、逻辑回归计算快:对于线性数据,逻辑回归的拟合和计算都非常快,计算效率优于SVM和随机森林,亲测表 示在大型数据上尤其能够看得出区别
3、逻辑回归返回的分类结果不是固定的0,1,而是以小数形式呈现的类概率数字:我们因此可以把逻辑回归返 回的结果当成连续型数据来利用。比如在评分卡制作时,我们不仅需要判断客户是否会违约,还需要给出确 定的”信用分“,而这个信用分的计算就需要使用类概率计算出的对数几率,而决策树和随机森林这样的分类 器,可以产出分类结果,却无法帮助我们计算分数(当然,在sklearn中,决策树也可以产生概率,使用接口 predict_proba调用就好,但一般来说,正常的决策树没有这个功能)。
另外,逻辑回归还有抗噪能力强的优点。福布斯杂志在讨论逻辑回归的优点时,甚至有着“技术上来说,最佳模型 的AUC面积低于0.8时,逻辑回归非常明显优于树模型”的说法。并且,逻辑回归在小数据集上表现更好,在大型的 数据集上,树模型有着更好的表现。
由此,我们已经了解了逻辑回归的本质,它是一个返回对数几率的,在线性数据上表现优异的分类器,它主要被应 用在金融领域。其数学目的是求解能够让模型对数据拟合程度最高的参数的值,以此构建预测函数 ,然后将特征矩阵输入预测函数来计算出逻辑回归的结果y。注意,虽然我们熟悉的逻辑回归通常被用于处理二分类问题, 但逻辑回归也可以做多分类。
1、sklearn中的逻辑回归
| 逻辑回归相关的类 | 说明 |
|---|---|
| linear_model.LogisticRegression | 逻辑回归分类器(又叫做logit回归,最大熵分类器) |
| linear_model.LogisticRegressionCV | 带交叉验证的逻辑回归分类器 |
| linear_model.Logistic_regression_path | 计算Logistic回归模型以获得正则化参数的列表 |
| linear_model.SGDClassifier | 利用梯度下降求解的线性分类器(SVM,逻辑回归等等) |
| linear_model.SGDRegressor | 利用梯度下降最小化正则化后的损失函数的线性回归模型 |
| 其他会涉及的类 | |
| metrics.Confusion_matrix | 混淆矩阵,模型评估指标之一 |
| metrics.roc_auc_score | ROC曲线,模型评估指标之一 |
| metrics.accuracy_score | 精确性,模型评估指标之一 |
2、linear_model.LogisticRegression
class sklearn.linear_model.LogisticRegression (penalty=’l2’, dual=False, tol=0.0001, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=’warn’, max_iter=100,
multi_class=’warn’, verbose=0, warm_start=False, n_jobs=None)
2.1 二元逻辑回归的损失函数
2.1.1 损失函数的概念和解惑
在学习决策树和随机森林时,我们曾经提到过两种模型表现:在训练集上的表现,在测试集上的表现。我们建模,是追求模型在测试集上的表现最优,因此模型的评估指标往往是用来衡量模型再次测试集上的表现的。然而,逻辑回归有着基于训练数据追求求解参数 θ \theta θ的需求,并且希望训练出来的模型能够尽可能地拟合训练数据,即模型在训练集上地预测准确率越靠近100%越好。
因此,我们使用“损失函数”这个评估指标,**来衡量参数为$ \theta 的 模 型 拟 合 训 练 集 时 产 生 的 信 息 损 失 的 大 小 , 并 以 此 衡 量 参 数 的模型拟合训练集时产生的信息损失的大小,并以此衡量参数 的模型拟合训练集时产生的信息损失的大小,并以此衡量参数\theta 的 优 劣 ∗ ∗ 。 如 果 用 一 组 参 数 建 模 后 , 模 型 在 训 练 集 上 表 现 良 好 , 那 我 们 就 说 模 型 拟 合 过 程 的 饿 损 失 很 小 , 损 失 函 数 的 值 很 小 , 这 一 组 参 数 就 优 秀 , 相 反 。 如 果 模 型 在 测 试 集 上 表 现 糟 糕 , 损 失 函 数 就 会 很 大 , 模 型 就 训 练 不 足 , 效 果 较 差 , 这 一 组 参 数 也 就 比 较 差 。 即 是 说 , 我 们 在 求 解 参 数 的优劣**。如果用一组参数建模后,模型在训练集上表现良好,那我们就说模型拟合过程的饿损失很小,损失函数的值很小,这一组参数就优秀,相反。如果模型在测试集上表现糟糕,损失函数就会很大,模型就训练不足,效果较差,这一组参数也就比较差。即是说,我们在求解参数 的优劣∗∗。如果用一组参数建模后,模型在训练集上表现良好,那我们就说模型拟合过程的饿损失很小,损失函数的值很小,这一组参数就优秀,相反。如果模型在测试集上表现糟糕,损失函数就会很大,模型就训练不足,效果较差,这一组参数也就比较差。即是说,我们在求解参数\theta$时,追求损失函数最小,让模型在训练数据集上的那你和效果最优,即预测准确率尽量靠近100%。
关键概念:损失函数:
衡量参数 θ \theta θ优劣的评估指标,用来求解最优参数工具。
损失函数小,模型在训练集上表现优异。拟合充分,参数优秀。
损失函数大,模型在训练集上表现差劲,拟合不足,参数糟糕。
我们追求,能够让损失函数最小化的参数组合。
注意:没有求解参数需求的模型没有损失函数,比如KNN,决策树等。
逻辑回归的损失函数是由极大似然估计推到出来的,具体结果可以写做:
J ( θ ) = − ∑ i = 1 m ( y i ∗ l o g ( y θ ( x i ) ) + ( 1 − y i ) l o g ( 1 − y θ ( x i ) ) ) J(\theta)=-\sum_{i=1}^m(y_i*log(y_{\theta}(x_i))+(1-y_i)log(1-y_{\theta}(x_i))) J(θ)=−i=1∑m(yi∗log(yθ(xi))+(1−yi)log(1−yθ(xi)))
其中, θ \theta θ表示求解出来的一组参数,m是样本的个数, y i y_i yi是样本i上真实的标签, y θ ( x i ) y_{\theta}(x_i) yθ(xi)是样本i上,基于参数 θ \theta θ计算出来的逻辑回归返回值, x i x_i xi是样本i各个特征的取值。我们的目标,就是求解出使 J θ J{\theta} Jθ最小的 θ \theta θ值。注意,在逻辑回归的本质函数 y ( x ) y(x) y(x)里,特征矩阵x是自变量,参数是 θ \theta θ。但在损失函数中,参数 θ \theta θ是损失函数的自变量,x和y都是已知的特征矩阵和标签,相当于损失函数的参数,不同的函数中,自变量和参数各有不同,因此大家需要在数据计算中,尤其是求导的时候避免混淆。
由于我们追求损失函数的最小值,让模型在训练集上表现最优,可能会引发另一个问题:如果模型在训练集上表现优秀,却在测试集上表现糟糕,模型就会过拟合。虽然逻辑回归和线性回归是天生欠拟合的模型,但我们还是需要 控制过拟合的技术来帮助我们调整模型,对逻辑回归中过拟合的控制,通过正则化来实现。
2.1.2 二元逻辑回归损失函数的数学解释,公式推导与解惑
虽然我们质疑过”逻辑回归返回概率“这样的说法,但不可否认逻辑回归的整个理论基础都是建立在这样的理解上 的。在这里,我们基于极大似然法来推导二元逻辑回归的损失函数,这个推导过程能够帮助我们了解损失函数怎么 得来的,以及为什么 的最小化能够实现模型在训练集上的拟合最好。
请时刻记得我们的目标:让模型对训练数据的效果好,追求损失最小。
二元逻辑回归的标签服从伯努利分布(即0-1分布),因此我们可以将一个特征向量为x ,参数为 θ \theta θ的模型中的一个样本i的预测情况表现为如下形式:
P 1 = P ( y i ^ = 1 ∣ x i , θ ) = y θ ( x i ) P_1=P(\hat{y_i}=1|x_i,\theta)=y_{\theta}(x_i) P1=P(yi^=1∣xi,θ)=yθ(xi)
样本i在由特征向量和参数组成的预测函数中,样本标签被预测为0的概率为:
P 0 = P ( y i ^ = 0 ∣ x i , θ ) = 1 − y θ ( x i ) P_0=P(\hat{y_i}=0|x_i,\theta)=1-y_{\theta}(x_i) P0=P(yi^=0∣xi,θ)=1−yθ(xi)
当 P 1 P_1 P1的值为1 的时候,代表样本i的标签被预测为1,当 P 0 P_0 P0的值为1的时候,代表样本i的标签被预测为0。
我们假设样本i的真实标签 y i y_i yi为1,此时如果 P 1 P_1 P1为1, P 0 P_0 P0为0,就代表样本i的标签被预测为1,与真实值一样,此时对于单样本i来说,模型的预测就是完全正确的,拟合程度很优秀,完全没有任何信息损失,相关,如果此时 P 1 P_1 P1为0, P 0 P_0 P0为1 ,就代表样本i的标签被预测为0,与真实情况完全相反。对于单样本来说,模型的预测就是完全错误的,拟合程度就很差,所有的信息都损失了。当 y i y_i yi为0时,也是同样的道理。所以,当 y i y_i yi为1的时候,我们希望 P 1 P_1 P1非常接近1,当 y i y_i yi为0的时候,我们希望 P 0 P_0 P0非常接近1,这样模型的效果就很好,信息损失就很少。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-88uOM5aS-1629700561180)(D:typora/picture/损失函数.jpg)]
将两种取值的概率整合,我们可以定义如下等式:
P ( y i ^ ∣ x i , θ ) = P 1 y i ∗ P 0 1 − y i P(\hat{y_i}|x_i,\theta)=P_1^{y_i}*P_0^{1-y_i} P(yi^∣xi,θ)=P1yi∗P01−yi
这个等式同时代表了 P 1 P_1 P1和 P 0 P_0 P0。当样本i的真实标签 y i y_i yi为1的时候, 1 − y i 1-y_i 1−yi就等于0, P 0 P_0 P0的0次方就是1.所以 P ( y i ^ ∣ x i , θ ) P(\hat{y_i}|x_i,\theta) P(yi^∣xi,θ)就等于 P 1 P_1 P1,这个时候,如果 P 1 P_1 P1为1,模型的效果就很好,损失就很小。同理,样本i的真实标签 y i y_i yi为0的时候, P ( y i ^ ∣ x i , θ ) P(\hat{y_i}|x_i,\theta) P(yi^∣xi,θ)就等于 P 0 P_0 P0,这个时候,如果 P 0 P_0 P0为1,模型的效果就很好,损失就很小。所以,为了达成让模型拟合很好,损失小的目的,我们每时每刻都希望 P ( y i ^ ∣ x i , θ ) P(\hat{y_i}|x_i,\theta) P(yi^∣xi,θ)的值等于1.而 P ( y i ^ ∣ x i , θ ) P(\hat{y_i}|x_i,\theta) P(yi^∣xi,θ)的本质就是样本i由特征向量 x i x_i xi和参数 θ \theta θ组成的 P ( y i ^ ∣ x i , θ ) P(\hat{y_i}|x_i,\theta) P(yi^∣xi,θ)的最大值。着九江模型拟合中的“最小化损失”问题,转换乘了对函数求极值得问题。
P ( y i ^ ∣ x i , θ ) P(\hat{y_i}|x_i,\theta) P(yi^∣xi,θ)对单个样本i而言得函数,对一个训练集的m个样本来说,我们可以定义如下等式来表达所有样本在特征矩阵X和参数 θ \theta θ组成的预测函数中,预测出所有的 y i ^ \hat{y_i} yi^的概率P为:
P = ∏ i = 1 m P ( y i ^ ∣ x i , θ ) = ∏ i = 1 m ( P 1 y i ∗ P 0 1 − y i ) = ∏ i = 1 m ( y θ ( x i ) y i ∗ ( 1 − y θ ( x i ) ) 1 − y i ) P=\prod_{i=1}^mP(\hat{y_i}|x_i,\theta) \\ =\prod_{i=1}^m(P_1^{y_i}*P_0^{1-y_i})\\ =\prod_{i=1}^m(y_{\theta}(x_i)^{y_i}*(1-y_{\theta}(x_i))^{1-y_i}) P=i=1∏mP(yi^∣xi,θ)=i=1∏m(P1yi∗P01−yi)=i=1∏m(yθ(xi)yi∗(1−yθ(xi))1−yi)
对该概率P求对数,再由 l o g ( A ∗ B ) = l o g A + l o g B log(A*B)=logA+logB log(A∗B)=logA+logB和 l o g A B = B l o g A logA^B=BlogA logAB=BlogA可得到:
l o g P = l o g ∏ i = 1 m ( y θ ( x i ) y i ∗ ( 1 − y θ ( x i ) ) 1 − y i ) = ∑ i = 1 m l o g ( y θ ( x i ) y i ∗ ( 1 − y θ ( x i ) ) 1 − y i ) = ∑ i = 1 m ( l o g y θ ( x i ) y i + l o g ( 1 − y θ ( x i ) ) 1 − y i ) = ∑ i = 1 m ( y i ∗ l o g y θ ( x i ) + ( 1 − y i ) ∗ l o g ( 1 − y θ ( x i ) ) logP=log\prod_{i=1}^m(y_{\theta}(x_i)^{y_i}*(1-y_{\theta}(x_i))^{1-y_i})\\ =\sum_{i=1}^mlog(y_{\theta}(x_i)^{y_i}*(1-y_{\theta}(x_i))^{1-y_i})\\ =\sum_{i=1}^m(logy_{\theta}(x_i)^{y_i}+log(1-y_{\theta}(x_i))^{1-y_i})\\ =\sum_{i=1}^m(y_i*logy_{\theta}(x_i)+(1-y_i)*log(1-y_{\theta}(x_i)) logP=logi=1∏m(yθ(xi)yi∗(1−yθ(xi))1−yi)=i=1∑mlog(yθ(xi)yi∗(1−yθ(xi))1−yi)=i=1∑m(logyθ(xi)yi+log(1−yθ(xi))1−yi)=i=1∑m(yi∗logyθ(xi)+(1−yi)∗log(1−yθ(xi))
这就是我们的交叉熵函数。为了数学上的便利以及更好地定义”损失”的含义,我们希望将极大值问题转换为极小值 问题,因此我们对 l o g P logP logP取负,并且让参数 θ \theta θ作为函数的自变量,就得到了我们的损失函数 :
J ( θ ) = − ∑ i = 1 m ( y i ∗ l o g y θ ( x i ) + ( 1 − y i ) ∗ l o g ( 1 − y θ ( x i ) ) J(\theta)=-\sum_{i=1}^m(y_i*logy_{\theta}(x_i)+(1-y_i)*log(1-y_{\theta}(x_i)) J(θ)=−i=1∑m(yi∗logyθ(xi)+(1−yi)∗log(1−yθ(xi))
这就是一个,基于逻辑回归的返回值 y θ ( x i ) y_{\theta}(x_i) yθ(xi)的概率性质得出的损失函数。在这个函数上,我们只要追求最小值,就能让模型在训练数据上的拟合效果最好,损失最低。这个推导过程,其实就是“极大似然法”的推导过程。
关键概念:似然与概率
似然与概率是一组非常相似的概念,他们都代表某件事发生的可能性,但他们在统计学和机器学习中有着微妙的不同。以样本i为例,我们有表达式:
P ( y i ^ ∣ x i , θ ) P(\hat{y_i}|x_i,\theta) P(yi^∣xi,θ)
对这个表达式而言,如果参数 θ \theta θ已知,特征向量 x i x_i xi是未知的,我们便称P是在探索不同特征取值下获取所有的 y i ^ \hat{y_i} yi^的可能性,这种可能性就被称为概率,研究的是自变量和因变量之间的关系。
如果特征向量 x i x_i xi是已知的,参数 θ \theta θ是未知的,我们便称P是在探索获取所有可能的 y i ^ \hat{y_i} yi^的可能性,这种可能性就被称为似然,研究的是参数取值和因变量之间的关系。
在逻辑回归的建模过程中,我们的特征矩阵是已知的,参数是位置的,因此我们讨论的所有“概率”其实严格来说都应该是“似然”。我们追求 P ( y i ^ ∣ x i , θ ) P(\hat{y_i}|x_i,\theta) P(yi^∣xi,θ)的最大值(换算成损失韩式之后就取负了,所以是最小值),所以就是在追求“极大似然”,所以逻辑回归的损失函数的推到方法叫做“极大似然”。也因此,以下式子又被称为“极大似然函数”:
P ( y i ^ ∣ x i , θ ) = y θ ( x i ) y i ∗ ( 1 − y θ ( x i ) ) 1 − y i P(\hat{y_i}|x_i,\theta)=y_{\theta}(x_i)^{y_i}*(1-y_{\theta}(x_i))^{1-y_i} P(yi^∣xi,θ)=yθ(xi)yi∗(1−yθ(xi))1−yi
2.2 重要参数penalty & C
2.2.1 正则化
正则化是用来防止模型过拟合的过程,常用的正则化有L1正则化和L2正则化两种选项,分别通过在损失函数后加上参数向量 θ \theta θ的L1范式和L2范式的倍数来实现。这个增加的范式,被称为“正则项”,也被称为“惩罚项”。损失函数改变,基于损失函数的最优化来求解的参数取值也必然改变,我们以此来调节模型拟合的程度。其中L1范式表现为参数向量中每个参数的绝对值之和,L2范数表现为参数向量中每个参数的平方和的开方值。
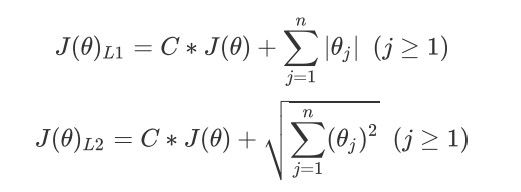
其中 J ( θ ) J(\theta) J(θ)是我们之前提过的损失函数,C是用来控制正则化程度的超参数,n是方程中特征总数,也是方程中参数的总数,j代表每个参数。在这里,j要大于等于1,是因为我们的参数写作向量 θ \theta θ,第一参数是 θ \theta θ,第一个参数是 θ 0 \theta_0 θ0,是我们的截距,它通常是不参与正则化的。
在许多书籍和博客中,大家可能也会见到如下的写法:
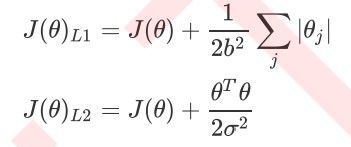
其实和上面我们展示的式子的本质是一摸一样的。不过在大多数教材和博客中,乘数项时乘以正则化,通过调控正则化来调节对模型的惩罚。而在sklearn,中,常数项C是在损失函数的前面,通过调控损失函数本身的大小,来调节对模型的惩罚。
| 参数 | 说明 |
|---|---|
| penalty | 可以输入"l1"或者"l2"来指定使用哪种正则化的范式,不填默认"l2" 注意:若选择"l1"正则化,参数solver仅能够使用求解方式"liblinear"和"saga",若使用"l2"正则化,参数solver中所有的求解方式都可以使用 |
| C | C正则化的强度的倒数,必须是一个大于0 的浮点数,不填默认1.0,即默认正则化项和损失函数的比值是1:1。C越小,损失函数会越小,模型对损失函数大而惩罚越重,正则化的效力越强,参数 θ \theta θ会逐渐被压缩得越来越小。 |
L1正则化和L2正则化虽然都可以控制过拟合,但它们的效果并不像听。当作正则化强度逐渐增大(即C逐渐变小),参数 θ \theta θ的取值会逐渐变小,但L1正则化会将参数压缩到0,L2正则化只会让参数尽量小,不会取到0。
在L1正则化逐渐加强的过程中,携带信息量小的,对模型贡献不大的特征的参数,回避携带大量信息的,对模型有巨大贡献的特征的参数更快变成0,所以L1正则化本质就是一个特征选择的过程,掌管了参数的“稀疏性”。L1正则化越强,参数向量中就越多的参数会变为0,参数就越稀疏,选出来的特征就越小,以此来防止过拟合。因此,如果特征量很大,数据维度很高,我们会倾向于使用L1正则化,由于L1正则化的这个性质,逻辑回归的特征选择可以使用Embedded嵌入法来完成。
相对的,L2正则化在加强的过程中,会尽量让每个特征对模型都有一些小的贡献,但携带信息少,对模型贡献不大的而特征的参数就会非常接近于0。通常来说,如果我们的主要目的只是为了防止过拟合,选择L2正则化就足够了。但是如果选择L2正则化后还是过拟合,模型在未知数据集上的标新很差,就可以考虑L1正则化。
而两种正则化下C的取值,都可是通过学习曲线来调整。
建立两个逻辑回归,L1正则化和L2正则化的差别就一目了然了:
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_breast_cancer()
X = data.data
y = data.target
data.data.shape
lrl1 = LR(penalty="l1",solver="liblinear",C=0.5,max_iter=1000)
lrl2 = LR(penalty="l2",solver="liblinear",C=0.5,max_iter=1000)
#逻辑回归的重要属性coef_,查看每个特征所对应的参数
lrl1 = lrl1.fit(X,y)
lrl1.coef_
(lrl1.coef_ != 0).sum(axis=1)
>>>10(即有2/3的特征的参数被处理为0!)
lrl2 = lrl2.fit(X,y)
lrl2.coef_
(lrl2.coef_ == 0).sum()
>>>0(所有特征的参数都不为0)
可以看见,当我们选择L1正则化的时候,许多特征的参数都被设置为了0,这些特征在真正建模的时候,就不会出 现在我们的模型当中了,而L2正则化则是对所有的特征都给出了参数。 究竟哪个正则化的效果更好呢?还是都差不多?
l1 = []
l2 = []
l1test = []
l2test = []
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3,random_state=420)
for i in np.linspace(0.05,1,19):
lrl1 = LR(penalty="l1",solver="liblinear",C=i,max_iter=1000)
lrl2 = LR(penalty="l2",solver="liblinear",C=i,max_iter=1000)
lrl1 = lrl1.fit(Xtrain,Ytrain)
l1.append(accuracy_score(lrl1.predict(Xtrain),Ytrain))
l1test.append(accuracy_score(lrl1.predict(Xtest),Ytest))
lrl2 = lrl2.fit(Xtrain,Ytrain)
l2.append(accuracy_score(lrl2.predict(Xtrain),Ytrain))
l2test.append(accuracy_score(lrl2.predict(Xtest),Ytest))
graph = [l1,l2,l1test,l2test]
color = ["green","black","lightgreen","gray"]
label = ["L1","L2","L1test","L2test"]
plt.figure(figsize=(6,6))
for i in range(len(graph)):
plt.plot(np.linspace(0.05,1,19),graph[i],color[i],label=label[i])
plt.legend(loc=4) #图例的位置在哪里?4表示,右下角
plt.show()
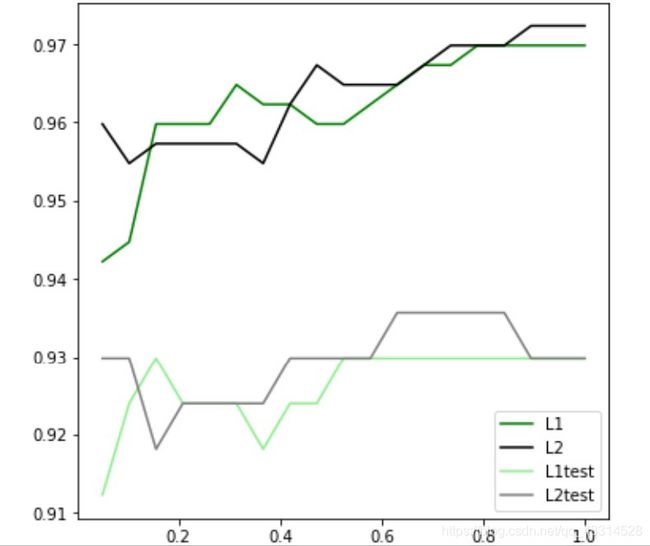
可见,至少在我们的乳腺癌数据集下,两种在正则化结果的区别不大。但随着C的逐渐增大,正则化的强度越来越大小,模型在训练集和测试集上的表现都成此案了上升趋势,知道C=0.8左右,训练集的表现依然在走高,但模型在未知数据集上的表现开始下滑,这时候就是出现了过拟合。我们可以认为C设定为0.8会比较好。在实际使用时,基本就默认使用L2正则化,如果感觉模型的效果不好,那就换L1试试看。
2.2.2 逻辑回归中的特征工程
当特征的数量很多的时候,我们出于业务考虑,也出于计算量的考虑,希望逻辑回归进行特征选择来降维。比如,在判断一个人是否会患乳腺癌的时候,医生如果看5~8个指标,会比需要看30个指标来确诊容易得多。
- 业务选择
说到降维和特征选择,首先要想到是利用自己的特务能力进行选择,肉眼可见明显和标签有关的特征就是需要留下来的。当然我如果我们并不了解业务,或者有成千上万的特征,那我们也可以使用算法来帮助我们。或者,可以让算法先帮我们筛选一遍特征,然后再少量的特征中,我们再根据业务尝试来选择更少量的特征。
- PCA和SVD一般不用
说到降维,我们首先想到的是之前提过的高效降维算法,PCA和SVD,遗憾的是,这两种方法大多数时候不适用于 逻辑回归。逻辑回归是由线性回归演变而来,线性回归的一个核心目的是通过求解参数来探究特征X与标签y之间的 关系,而逻辑回归也传承了这个性质,我们常常希望通过逻辑回归的结果,来判断什么样的特征与分类结果相关, 因此我们希望保留特征的原貌。PCA和SVD的降维结果是不可解释的,因此一旦降维后,我们就无法解释特征和标 签之间的关系了。当然,在不需要探究特征与标签之间关系的线性数据上,降维算法PCA和SVD也是可以使用的。
- 统计方法可以使用,但不是非常必要
既然降维算法不能使用,我们要用的就是特征选择方法。逻辑回归对数据的要求低于线性回归,由于我们不是使用 最小二乘法来求解,所以逻辑回归对数据的总体分布和方差没有要求,也不需要排除特征之间的共线性,但如果我 们确实希望使用一些统计方法,比如方差,卡方,互信息等方法来做特征选择,也并没有问题。过滤法中所有的方 法,都可以用在逻辑回归上。 在一些博客中有这样的观点:多重共线性会影响线性模型的效果。对于线性回归来说,多重共线性会影响比较大, 所以我们需要使用方差过滤和方差膨胀因子VIF(variance inflation factor)来消除共线性。但是对于逻辑回归,其实 不是非常必要,甚至有时候,我们还需要多一些相互关联的特征来增强模型的表现。当然,如果我们无法通过其他 方式提升模型表现,并且你感觉到模型中的共线性影响了模型效果,那懂得统计学的你可以试试看用VIF消除共线 性的方法,遗憾的是现在sklearn中并没有提供VIF的功能。
- 高效的嵌入法Embedded
但更有效的方法,毫无疑问会是我们的embedded嵌入法。我们已经说明了,由于L1正则化会使得部分特征对应的参数为0,因此L1正则化可以用来做特征选择,结合嵌入法的Select FromModel,我们可以很容易就筛选出让模型十分高效的特征。注意,此时我们的目的是,尽量保留原数据上的信息,让模型再降维后的数据上的拟合效果保持优秀,因此我们不考虑吧训练集测试集的问题,把所有数据都放入模型中进行降维。
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectFromModel
data = load_breast_cancer()
data.data.shape
LR_ = LR(solver="liblinear",C=0.9,random_state=420)
cross_val_score(LR_,data.data,data.target,cv=10).mean()
X_embedded = SelectFromModel(LR_,norm_order=1).fit_transform(data.data,data.target)
X_embedded.shape
cross_val_score(LR_,X_embedded,data.target,cv=10).mean()
看看结果,特征数量被减小到个位数,并且模型的效果却没有下降太多,如果我们要求不高,在这里其实就可以停 下了。但是,能否让模型的拟合效果更好呢?在这里,我们有两种调整方式:
1)调节SelectFromModel这个类中的参数threshold,这是嵌入法的阈值,表示删除所有参数的绝对值低于这个阈值的特征。现在threshold默认为None,所以SelectFromModel只根据L1正则化的结果选择了参数,即选择了所 有L1正则化后参数不为0的特征。我们此时,只要调整threshold的值(画出threshold的学习曲线),就可以观察到不同的threshold下模型的效果如何变化。一旦调整threshold,就不是在使用L1正则化选择参数,而是使用模型属性.coef _ 中生成的各个特征的系数来选择。coef _ 虽然返回的是特征的系数,但是系数的大小和决策树中的feature_importances _ 以及降维算法中的可解释性方差explained_variance _ 概念相似,其实都是衡量特征的重要程度和贡献率,因此SelectFromModel中的参数threshold可以设置为coed _ 的阈值,即可剔除系数小于threshold中输入的数字的所有特征。
fullx = []
fsx = []
threshold = np.linspace(0,abs((LR_.fit(data.data,data.target).coef_)).max(),20)
k=0
for i in threshold:
X_embedded = SelectFromModel(LR_,threshold=i).fit_transform(data.data,data.target)
fullx.append(cross_val_score(LR_,data.data,data.target,cv=5).mean())
fsx.append(cross_val_score(LR_,X_embedded,data.target,cv=5).mean())
print((threshold[k],X_embedded.shape[1]))
k+=1
plt.figure(figsize=(20,5))
plt.plot(threshold,fullx,label="full")
plt.plot(threshold,fsx,label="feature selection")
plt.xticks(threshold)
plt.legend()
plt.show()

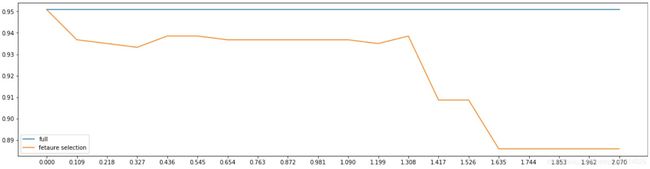
然而,这种方法其实是比较无效的,大家可以用学习曲线来跑一跑:当threshold越来越大,被删除的特征越来越 多,模型的效果也越来越差,模型效果最好的情况下需要保证有17个以上的特征。实际上我画了细化的学习曲线, 如果要保证模型的效果比降维前更好,我们需要保留25个特征,这对于现实情况来说,是一种无效的降维:需要 30个指标来判断病情,和需要25个指标来判断病情,对医生来说区别不大。
2)第二种调整方法,是调逻辑回归的类LR _ ,通过画C的学习曲线来实现:
fullx = []
fsx = []
C=np.arange(0.01,10.01,0.5)
for i in C:
LR_ = LR(solver="liblinear",C=i,random_state=420)
fullx.append(cross_val_score(LR_,data.data,data.target,cv=10).mean())
X_embedded = SelectFromModel(LR_,norm_order=1).fit_transform(data.data,data.target)
fsx.append(cross_val_score(LR_,X_embedded,data.target,cv=10).mean())
print(max(fsx),C[fsx.index(max(fsx))])
plt.figure(figsize=(20,5))
plt.plot(C,fullx,label="full")
plt.plot(C,fsx,label="feature selection")
plt.xticks(C)
plt.legend()
plt.show()
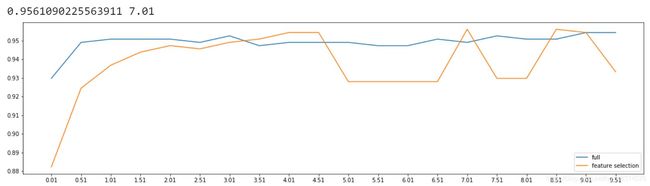
继续细化学习曲线:
fullx = []
fsx = []
C=np.arange(6.05,7.05,0.005)
for i in C:
LR_ = LR(solver="liblinear",C=i,random_state=420)
fullx.append(cross_val_score(LR_,data.data,data.target,cv=10).mean())
X_embedded = SelectFromModel(LR_,norm_order=1).fit_transform(data.data,data.target)
fsx.append(cross_val_score(LR_,X_embedded,data.target,cv=10).mean())
print(max(fsx),C[fsx.index(max(fsx))])
plt.figure(figsize=(20,5))
plt.plot(C,fullx,label="full")
plt.plot(C,fsx,label="feature selection")
#plt.xticks(C)
plt.legend()
plt.show()
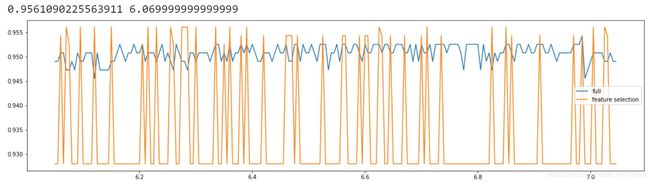
再 看一下降维后模型的表现能力
#验证模型效果:降维之前
LR_ = LR(solver="liblinear",C=6.069999999999999,random_state=420)
cross_val_score(LR_,data.data,data.target,cv=10).mean()
>>>0.9473057644110275
#验证模型效果:降维之后
LR_ = LR(solver="liblinear",C=6.069999999999999,random_state=420)
X_embedded = SelectFromModel(LR_,norm_order=1).fit_transform(data.data,data.target)
cross_val_score(LR_,X_embedded,data.target,cv=10).mean()
>>>0.9561090225563911
X_embedded
>>>(569, 11)
这样我们就实现了在特征选择的前提下,保持模型拟合的高效,现在,如果有一位医生可以来为我们指点迷津,看 看剩下的这些特征中,有哪些是对针对病情来说特别重要的,也许我们还可以继续降维。当然,除了嵌入法,系数 累加法或者包装法也是可以使用的。
- 比较麻烦的系数累加法
系数累加法的原理非常简单。在PCA中,我们通过绘制累积可解释方差贡献率曲线来选择超参数,在逻辑回归中我 们可以使用系数coef_来这样做,并且我们选择特征个数的逻辑也是类似的:找出曲线由锐利变平滑的转折点,转 折点之前被累加的特征都是我们需要的,转折点之后的我们都不需要。不过这种方法相对比较麻烦,因为我们要先 对特征系数进行从大到小的排序,还要确保我们知道排序后的每个系数对应的原始特征的位置,才能够正确找出那 些重要的特征。如果要使用这样的方法,不如直接使用嵌入法来得方便。
- 简单快速的包装法
相对的,包装法可以直接设定我们需要的特征个数,逻辑回归在现实中运用时,可能会有”需要5~8个变量”这种需 求,包装法此时就非常方便了。不过逻辑回归的包装法的使用和其他算法一样,并不具有特别之处,因此在这里就 不在赘述,具体大家可以参考(3) sklearn实战之数据预处理与特征工程。
2.3 梯度下降:重要参数max_iter
逻辑回归的数学目的是求解能够让模型最优化,拟合程度最好的参数 θ \theta θ的值,即求解能够让损失函数 J ( θ ) J(\theta) J(θ)最小化的 θ \theta θ的值。对于二元逻辑回归来说,有多种方法可以用来求解 θ \theta θ,最常见的有梯度下降法(Gradient Descent),坐标下降(Coordinate Descent),牛顿法(Newton-Raphson method)等,其中又以梯度下降法最为著名。每种方法都 涉及复杂的数学原理,但这些计算在执行的任务其实是类似的。
2.3.1 梯度下降求解逻辑回归
2.5 样本不平衡与参数class_weight
样本不平衡是指在一组数据集中,标签的一类天生占有很大的比例,或误分类的代价很高,即我们想要捕捉出某种 特定的分类的时候的状况。
什么情况下误分类的代价很高?例如,我们现在要对潜在犯罪者和普通人进行分类,如果没有能够识别出潜在犯罪 者,那么这些人就可能去危害社会,造成犯罪,识别失败的代价会非常高,但如果,我们将普通人错误地识别成了 潜在犯罪者,代价却相对较小。所以我们宁愿将普通人分类为潜在犯罪者后再人工甄别,但是却不愿将潜在犯罪者 分类为普通人,有种"宁愿错杀不能放过"的感觉。
再比如说,在银行要判断“一个新客户是否会违约”,通常不违约的人vs违约的人会是99:1的比例,真正违约的人 其实是非常少的。这种分类状况下,即便模型什么也不做,全把所有人都当成不会违约的人,正确率也能有99%, 这使得模型评估指标变得毫无意义,根本无法达到我们的“要识别出会违约的人”的建模目的。
因此我们要使用参数class_weight对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类, 向捕获少数类的方向建模。该参数默认None,此模式表示自动给与数据集中的所有标签相同的权重,即自动1: 1。当误分类的代价很高的时候,我们使用”balanced“模式,我们只是希望对标签进行均衡的时候,什么都不填就 可以解决样本不均衡问题。
但是,sklearn当中的参数class_weight变幻莫测,大家用模型跑一跑就会发现,我们很难去找出这个参数引导的模 型趋势,或者画出学习曲线来评估参数的效果,因此可以说是非常难用。我们有着处理样本不均衡的各种方法,其 中主流的是采样法,是通过重复样本的方式来平衡标签,可以进行上采样(增加少数类的样本),比如SMOTE, 或者下采样(减少多数类的样本)。对于逻辑回归来说,上采样是最好的办法。在案例中,会给大家详细来讲如何 在逻辑回归中使用上采样。
3 案例:用逻辑回归制作评分卡
在银行借贷场景中,评分卡是一种以分数形式来衡量一个客户的信用风险大小的手段,它衡量向别人借钱的人(受 信人,需要融资的公司)不能如期履行合同中的还本付息责任,并让借钱给别人的人(授信人,银行等金融机构) 造成经济损失的可能性。一般来说,评分卡打出的分数越高,客户的信用越好,风险越小。
这些”借钱的人“,可能是个人,有可能是有需求的公司和企业。对于企业来说,我们按照融资主体的融资用途,分 别使用企业融资模型,现金流融资模型,项目融资模型等模型。而对于个人来说,我们有”四张卡“来评判个人的信 用程度:A卡,B卡,C卡和F卡。而众人常说的“评分卡”其实是指A卡,又称为申请者评级模型,主要应用于相关融 资类业务中新用户的主体评级,即判断金融机构是否应该借钱给一个新用户,如果这个人的风险太高,我们可以拒 绝贷款。
一个完整的模型开发,需要有以下流程:
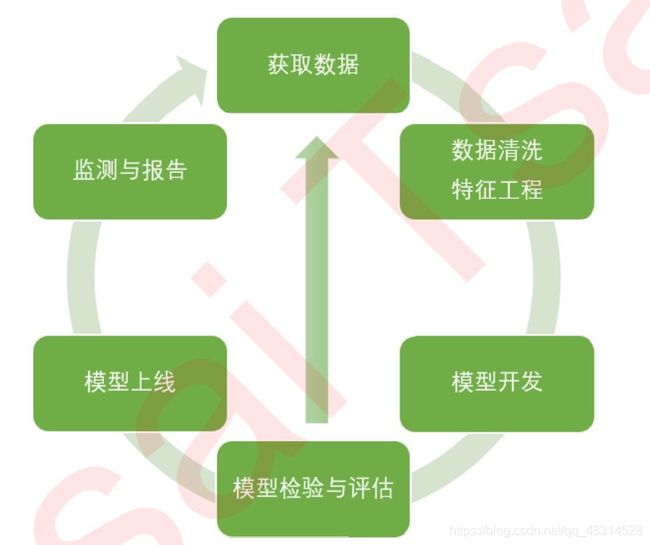
今天我们以个人消费类贷款数据,来为大家简单介绍A卡的建模和制作流程,由于篇幅有限,我们的核心会在”数据 清洗“和“模型开发”上。模型检验与评估也非常重要,但是在今天的课中,内容已经太多,我们就不再去赘述了。
3.1 导库,获取数据
%matplotlib inline
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
#其实日常在导库的时候,并不是一次性能够知道我们要用的所有库的。通常都是在建模过程中逐渐导入需要的库。
在银行系统中,这个数据通常是来自于其他部分的同事的收集,因此千万别忘记抓住给您数据的人,问问她/他各个项都是什么含义。通常来说,当特征非常多的时候(比如几百个),都会有一个附带的exce或pdf文档给你,备注了各个特征都是什么含义。这种情况下其实要一个一个去看还是非常困难的,如果特征很多,建议先做降维,具体参考“2.2.2 逻辑回归中的特征工程”。
data = pd.read_csv(r"C:\work\learnbetter\micro-class\week 5 logit regression\ranking
card\card\data\rankingcard.csv",index_col=0)
3.2 探索数据与数据预处理
在这一步我们要样本总体的大概情况,比如查看缺失值,量纲是否统一,是否需要做哑变量等等。其实数据的探索 和数据的预处理并不是完全分开的,并不一定非要先做哪一个,因此这个顺序只是供大家参考。
#观察数据类型
data.head()
#观察数据结构
data.shape()
data.info()

3.2.1 去除重复值
现实数据,尤其是银行业数据,可能会存在的一个问题就是样本重复,即有超过一行的样本所显示的所有特征都一 样。有时候可能时人为输入重复,有时候可能是系统录入重复,总而言之我们必须对数据进行去重处理。可能有人 会说,难道不可能出现说两个样本的特征就是一模一样,但他们是两个样本吗?比如,两个人,一模一样的名字, 年龄,性别,学历,工资……当特征量很少的时候,这的确是有可能的,但一些指标,比如说家属人数,月收入,已借有的房地产贷款数量等等,几乎不可能都出现一样。尤其是银行业数据经常是几百个特征,所有特征都一样的 可能性是微乎其微的。即便真的出现了如此极端的情况,我们也可以当作是少量信息损失,将这条记录当作重复值除去。
#去除重复值
data.drop_duplicates(inplace=True)
data.info()
#删除之后千万不要忘记,恢复索引
data.index = range(data.shape[0])
data.info()
3.2.2 填补缺失值
#探索缺失值
data.info()
data.isnull().sum()/data.shape[0]
#data.isnull().mean()
第二个要面临的问题,就是缺失值。在这里我们需要填补的特征是“收入”和“家属人数”。“家属人数”缺失很少,仅缺 失了大约2.5%,可以考虑直接删除,或者使用均值来填补。“收入”缺失了几乎20%,并且我们知道,“收入”必然是 一个对信用评分来说很重要的因素,因此这个特征必须要进行填补。在这里,我们使用均值填补“家属人数”。
data["NumberOfDependents"].fillna(int(data["NumberOfDependents"].mean()),inplace=True)
#如果你选择的是删除那些缺失了2.5%的特征,千万记得恢复索引哟~
data.info()
data.isnull().sum()/data.shape[0]
那字段"收入"怎么办呢?对于银行数据来说,我们甚至可以有这样的推断:一个来借钱的人应该是会知道,“高收 入”或者“稳定收入”于他/她自己而言会是申请贷款过程中的一个助力,因此如果收入稳定良好的人,肯定会倾向于 写上自己的收入情况,那么这些“收入”栏缺失的人,更可能是收入状况不稳定或收入比较低的人。基于这种判断, 我们可以用比如说,四分位数来填补缺失值,把所有收入为空的客户都当成是低收入人群。当然了,也有可能这些 缺失是银行数据收集过程中的失误,我们并无法判断为什么收入栏会有缺失,所以我们的推断也有可能是不正确 的。具体采用什么样的手段填补缺失值,要和业务人员去沟通,观察缺失值是如何产生的。在这里,我们使用随机 森林填补“收入”。
还记得我们用随机森林填补缺失值的案例么?随机森林利用“既然我可以使用A,B,C去预测Z,那我也可以使用 A,C,Z去预测B”的思想来填补缺失值。对于一个有n个特征的数据来说,其中特征T有缺失值,我们就把特征T当 作标签,其他的n-1个特征和原本的标签组成新的特征矩阵。那对于T来说,它没有缺失的部分,就是我们的 Y_train,这部分数据既有标签也有特征,而它缺失的部分,只有特征没有标签,就是我们需要预测的部分。
特征T不缺失的值对应的其他n-1个特征 + 本来的标签:X_train 特征T不缺失的值:Y_train 特征T缺失的值对应的其 他n-1个特征 + 本来的标签:X_test 特征T缺失的值:未知,我们需要预测的Y_test
这种做法,对于某一个特征大量缺失,其他特征却很完整的情况,非常适用。更具体地,大家可以回到随机森林的文章中去复习。
之前我们所做的随机森林填补缺失值的案例中,我们面临整个数据集中多个特征都有缺失的情况,因此要先对特征 排序,遍历所有特征来进行填补。这次我们只需要填补“收入”一个特征,就无需循环那么麻烦了,可以直接对这一 列进行填补。我们来写一个能够填补任何列的函数:
def fill_missing_rf(X,y,to_fill):
"""
使用随机森林填补一个特征的缺失值的函数
参数:
X:要填补的特征矩阵
y:完整的,没有缺失值的标签
to_fill:字符串,要填补的那一列的名称
"""
#构建我们的新特征矩阵和新标签
df = X.copy()
fill = df.loc[:,to_fill]
df = pd.concat([df.loc[:,df.columns != to_fill],pd.DataFrame(y)],axis=1)
#找出我们的训练集和测试集
Ytrain = fill[fill.notnull()]
Ytest = fill[fill.isnull()]
Xtrain = df.iloc[Ytrain.index,:]
Xtest = df.iloc[Ytest.index,:]
#用随机森林回归来填补缺失值
from sklearn.ensemble import RandomForestRegressor as rfr
rfr = rfr(n_estimators=100)
rfr = rfr.fit(Xtrain, Ytrain)
Ypredict = rfr.predict(Xtest)
return Ypredict
X = data.iloc[:,1:]
y = data["SeriousDlqin2yrs"]
X.shape
#=====【TIME WARNING:1 min】=====#
y_pred = fill_missing_rf(X,y,"MonthlyIncome")
#确认我们的结果合理之后,我们就可以将数据覆盖了
data.loc[data
接下来,我们来创造函数需要的参数,将参数导入函数,产出结果:
X = data.iloc[:,1:]
y = data["SeriousDlqin2yrs"]
X.shape
#=====【TIME WARNING:1 min】=====#
y_pred = fill_missing_rf(X,y,"MonthlyIncome")
#确认我们的结果合理之后,我们就可以将数据覆盖了
data.loc[data.loc[:,"MonthlyIncome"].isnull(),"MonthlyIncome"] = y_pred
3.2.3 描述性统计处理异常值
现实数据永远都会有一些异常值,首先我们要去把他们捕捉出来,然后观察他们的性质。注意,我们并不是要排除 掉所有异常值,相反很多时候,异常值是我们的重点研究对象,比如说,双十一中购买量超高的品牌,或课堂上让 很多学生都兴奋的课题,这些是我们要重点研究观察的。
日常处理异常值,我们使用箱线图或者 法则来找到异常值(千万不要说依赖于眼睛看,我们是数据挖掘工程师, 除了业务理解,我们还要有方法)。但在银行数据中,我们希望排除的“异常值”不是一些超高或超低的数字,而是 一些不符合常理的数据:比如,收入不能为负数,但是一个超高水平的收入却是合理的,可以存在的。所以在银行 业中,我们往往就使用普通的描述性统计来观察数据的异常与否与数据的分布情况。注意,这种方法只能在特征量 有限的情况下进行,如果有几百个特征又无法成功降维或特征选择不管用,那还是用 比较好。
#描述性统计
data.describe([0.01,0.1,0.25,.5,.75,.9,.99]).T
#异常值也被我们观察到,年龄的最小值居然有0,这不符合银行的业务需求,即便是儿童账户也要至少8岁,我们可以
查看一下年龄为0的人有多少
(data["age"] == 0).sum()
#发现只有一个人年龄为0,可以判断这肯定是录入失误造成的,可以当成是缺失值来处理,直接删除掉这个样本
data = data[data["age"] != 0]
"""
另外,有三个指标看起来很奇怪:
"NumberOfTime30-59DaysPastDueNotWorse"
"NumberOfTime60-89DaysPastDueNotWorse"
"NumberOfTimes90DaysLate"
这三个指标分别是“过去两年内出现35-59天逾期但是没有发展的更坏的次数”,“过去两年内出现60-89天逾期但是没
有发展的更坏的次数”,“过去两年内出现90天逾期的次数”。这三个指标,在99%的分布的时候依然是2,最大值却是
98,看起来非常奇怪。一个人在过去两年内逾期35~59天98次,一年6个60天,两年内逾期98次这是怎么算出来的?
我们可以去咨询业务人员,请教他们这个逾期次数是如何计算的。如果这个指标是正常的,那这些两年内逾期了98次的
客户,应该都是坏客户。在我们无法询问他们情况下,我们查看一下有多少个样本存在这种异常:
"""
data[data.loc[:,"NumberOfTimes90DaysLate"] > 90].count()
#有225个样本存在这样的情况,并且这些样本,我们观察一下,标签并不都是1,他们并不都是坏客户。因此,我们基
本可以判断,这些样本是某种异常,应该把它们删除。
data = data[data.loc[:,"NumberOfTimes90DaysLate"] < 90]
#恢复索引
data.index = range(data.shape[0])
data.info()
3.2.4 为什么不统一量纲,也不标准化数据分布?
在描述性统计结果中,我们可以观察到数据量纲明显不统一,而且存在一部分极偏的分布,虽然逻辑回归对于数据 没有分布要求,但是我们知道如果数据服从正态分布的话梯度下降可以收敛得更快。但在这里,我们不对数据进行 标准化处理,也不进行量纲统一,为什么?
无论算法有什么样的规定,无论统计学中有什么样的要求,我们的最终目的都是要为业务服务。现在我们要制作评 分卡,评分卡是要给业务人员们使用的基于新客户填写的各种信息为客户打分的一张卡片,而为了制作这张卡片, 我们需要对我们的数据进行一个“分档”,比如说,年龄20 ~ 30为一档,年龄30 ~ 50岁为一档,月收入1W以上为一 档,5000 ~ 1W为一档,每档的分数不同。
一旦我们将数据统一量纲,或者标准化了之后,数据大小和范围都会改变,统计结果是漂亮了,但是对于业务人员 来说,他们完全无法理解,标准化后的年龄在0.00328~0.00467之间为一档是什么含义。并且,新客户填写的信 息,天生就是量纲不统一的,我们的确可以将所有的信息录入之后,统一进行标准化,然后导入算法计算,但是最 终落到业务人员手上去判断的时候,他们会完全不理解为什么录入的信息变成了一串统计上很美但实际上根本看不 懂的数字。由于业务要求,在制作评分卡的时候,我们要尽量保持数据的原貌,年龄就是8~110的数字,收入就是 大于0,最大值可以无限的数字,即便量纲不统一,我们也不对数据进行标准化处理。
3.2.5 样本不均衡问题
#探索标签的分布
X = data.iloc[:,1:]
y = data.iloc[:,0]
y.value_counts()
n_sample = X.shape[0]
n_1_sample = y.value_counts()[1]
n_0_sample = y.value_counts()[0]
print('样本个数:{}; 1占{:.2%}; 0占
{:.2%}'.format(n_sample,n_1_sample/n_sample,n_0_sample/n_sample))
可以看出,样本严重不均衡。虽然大家都在努力防范信用风险,但实际违约的人并不多。并且,银行并不会真的一 棒子打死所有会违约的人,很多人是会还钱的,只是忘记了还款日,很多人是不愿意欠人钱的,但是当时真的很困 难,资金周转不过来,所以发生逾期,但一旦他有了钱,他就会把钱换上。对于银行来说,只要你最后能够把钱还 上,我都愿意借钱给你,因为我借给你就有收入(利息)。所以,对于银行来说,真正想要被判别出来的其实 是”恶意违约“的人,而这部分人数非常非常少,样本就会不均衡。这一直是银行业建模的一个痛点:我们永远希望 捕捉少数类。
之前提到过,逻辑回归中使用最多的是上采样方法来平衡样本。
#如果报错,就在prompt安装:pip install imblearn
import imblearn
#imblearn是专门用来处理不平衡数据集的库,在处理样本不均衡问题中性能高过sklearn很多
#imblearn里面也是一个个的类,也需要进行实例化,fit拟合,和sklearn用法相似
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=42) #实例化
X,y = sm.fit_sample(X,y)
n_sample_ = X.shape[0]
pd.Series(y).value_counts()
n_1_sample = pd.Series(y).value_counts()[1]
n_0_sample = pd.Series(y).value_counts()[0]
print('样本个数:{}; 1占{:.2%}; 0占
{:.2%}'.format(n_sample_,n_1_sample/n_sample_,n_0_sample/n_sample_))
如此,我们就实现了样本平衡,样本量也增加了。
3.2.6 分训练集和测试集
from sklearn.model_selection import train_test_split
X = pd.DataFrame(X)
y = pd.DataFrame(y)
X_train, X_vali, Y_train, Y_vali = train_test_split(X,y,test_size=0.3,random_state=420)
model_data = pd.concat([Y_train, X_train], axis=1)
model_data.index = range(model_data.shape[0])
model_data.columns = data.columns
vali_data = pd.concat([Y_vali, X_vali], axis=1)
vali_data.index = range(vali_data.shape[0])
vali_data.columns = data.columns
model_data.to_csv(r"C:\work\learnbetter\micro-class\week 5 logit
regression\model_data.csv")
vali_data.to_csv(r"C:\work\learnbetter\micro-class\week 5 logit regression\model_data.csv")
3.3 分箱
前面提到过,我们要制作评分卡,是要给各个特征进行分档,以便业务人员能够根据新客户填写的信息为客户打 分。因此在评分卡制作过程中,一个重要的步骤就是分箱。可以说,分箱是评分卡最难,也是最核心的思路,分箱 的本质,其实就是离散化连续变量,好让拥有不同属性的人被分成不同的类别(打上不同的分数),其实本质比较 类似于聚类。那我们在分箱中要回答几个问题:
- 首先,要分多少个箱子才合适?
最开始我们并不知道,但是既然是将连续型变量离散化,想也知道箱子个数必然不能太多,最好控制在十个以下。 而用来制作评分卡,最好能在4~5个为最佳。我们知道,离散化连续变量必然伴随着信息的损失,并且箱子越少, 信息损失越大。为了衡量特征上的信息量以及特征对预测函数的贡献,银行业定义了概念Information value(IV):
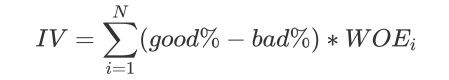
其中N是这个特征上箱子的个数,i代表每个箱子, 是这个箱内的优质客户(标签为0的客户)占整个特征中 所有优质客户的比例, 是这个箱子里的坏客户(就是那些会违约,标签为1的那些客户)占整个特征中所有坏 客户的比例,而这写做:
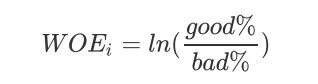
这是我们在银行业中用来衡量违约概率的指标,中文叫做证据权重(weight of Evidence),本质其实就是优质客户 比上坏客户的比例的对数。WOE是对一个箱子来说的,WOE越大,代表了这个箱子里的优质客户越多。而IV是对 整个特征来说的,IV代表的意义是我们特征上的信息量以及这个特征对模型的贡献,由下表来控制:
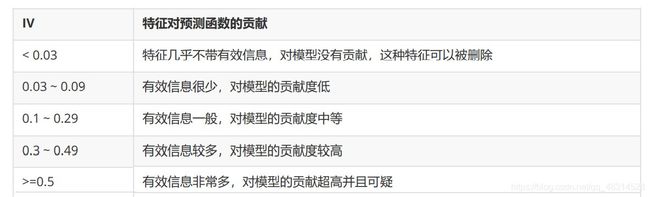
可见,IV并非越大越好,我们想要找到IV的大小和箱子个数的平衡点。箱子越多,IV必然越小,因为信息损失会非 常多,所以,我们会对特征进行分箱,然后计算每 个特征在每个箱子数目下的WOE值,利用IV值的曲线,找出合 适的分箱个数。
- 其次,分箱要达成什么样的效果?
我们希望不同属性的人有不同的分数,因此我们希望在同一个箱子内的人的属性是尽量相似的,而不同箱子的人的 属性是尽量不同的,即业界常说的”组间差异大,组内差异小“。对于评分卡来说,就是说我们希望一个箱子内的人 违约概率是类似的,而不同箱子的人的违约概率差距很大,即WOE差距要大,并且每个箱子中坏客户所占的比重( )也要不同。那我们,可以使用卡方检验来对比两个箱子之间的相似性,如果两个箱子之间卡方检验的P值很 大,则说明他们非常相似,那我们就可以将这两个箱子合并为一个箱子。
基于这样的思想,我们总结出我们对一个特征进行分箱的步骤:
1)我们首先把连续型变量分成一组数量较多的分类型变量,比如,将几万个样本分成100组,或50组
2)确保每一组中都要包含两种类别的样本,否则IV值会无法计算
3)我们对相邻的组进行卡方检验,卡方检验的P值很大的组进行合并,直到数据中的组数小于设定的N箱为止
4)我们让一个特征分别分成[2,3,4…20]箱,观察每个分箱个数下的IV值如何变化,找出最适合的分箱个数
5)分箱完毕后,我们计算每个箱的WOE值, b a d % bad\% bad%,观察分箱效果 这些步骤都完成后,我们可以对各个特征都进行分箱,然后观察每个特征的IV值,以此来挑选特征。
接下来,我们就以"age"为例子,来看看分箱如何完成。
3.3.1 等频分箱
#按照等频对需要分箱的列进行分箱
model_data["qcut"], updown = pd.qcut(model_data["age"], retbins=True, q=20)
"""
pd.qcut,基于分位数的分箱函数,本质是将连续型变量离散化
只能够处理一维数据。返回箱子的上限和下限
参数q:要分箱的个数
参数retbins=True来要求同时返回结构为索引为样本索引,元素为分到的箱子的Series
现在返回两个值:每个样本属于哪个箱子,以及所有箱子的上限和下限
"""
#在这里时让model_data新添加一列叫做“分箱”,这一列其实就是每个样本所对应的箱子
model_data["qcut"]
#所有箱子的上限和下限
updown
# 统计每个分箱中0和1的数量
# 这里使用了数据透视表的功能groupby
coount_y0 = model_data[model_data["SeriousDlqin2yrs"] == 0].groupby(by="qcut").count()
["SeriousDlqin2yrs"]
coount_y1 = model_data[model_data["SeriousDlqin2yrs"] == 1].groupby(by="qcut").count()
["SeriousDlqin2yrs"]
#num_bins值分别为每个区间的上界,下界,0出现的次数,1出现的次数
num_bins = [*zip(updown,updown[1:],coount_y0,coount_y1)]
#注意zip会按照最短列来进行结合
num_bins
3.3.2 【选学】确保每个箱子=中都有0和1
for i in range(20):
#如果第一个组没有包含正样本或负样本,向后合并
if 0 in num_bins[0][2:]:
num_bins[0:2] = [(
num_bins[0][0],
num_bins[1][1],
num_bins[0][2]+num_bins[1][2],
num_bins[0][3]+num_bins[1][3])]
continue
"""
合并了之后,第一行的组是否一定有两种样本了呢?不一定
如果原本的第一组和第二组都没有包含正样本,或者都没有包含负样本,那即便合并之后,第一行的组也还是没有
包含两种样本
所以我们在每次合并完毕之后,还需要再检查,第一组是否已经包含了两种样本
这里使用continue跳出了本次循环,开始下一次循环,所以回到了最开始的for i in range(20), 让i+1
这就跳过了下面的代码,又从头开始检查,第一组是否包含了两种样本
如果第一组中依然没有包含两种样本,则if通过,继续合并,每合并一次就会循环检查一次,最多合并20次
如果第一组中已经包含两种样本,则if不通过,就开始执行下面的代码
"""
#已经确认第一组中肯定包含两种样本了,如果其他组没有包含两种样本,就向前合并
#此时的num_bins已经被上面的代码处理过,可能被合并过,也可能没有被合并
#但无论如何,我们要在num_bins中遍历,所以写成in range(len(num_bins))
for i in range(len(num_bins)):
if 0 in num_bins[i][2:]:
num_bins[i-1:i+1] = [(
num_bins[i-1][0],
num_bins[i][1],
num_bins[i-1][2]+num_bins[i][2],
num_bins[i-1][3]+num_bins[i][3])]
break
#如果对第一组和对后面所有组的判断中,都没有进入if去合并,则提前结束所有的循环
else:
break
"""
这个break,只有在if被满足的条件下才会被触发
也就是说,只有发生了合并,才会打断for i in range(len(num_bins))这个循环
为什么要打断这个循环?因为我们是在range(len(num_bins))中遍历
但合并发生后,len(num_bins)发生了改变,但循环却不会重新开始
举个例子,本来num_bins是5组,for i in range(len(num_bins))在第一次运行的时候就等于for i in
range(5)
range中输入的变量会被转换为数字,不会跟着num_bins的变化而变化,所以i会永远在[0,1,2,3,4]中遍历
进行合并后,num_bins变成了4组,已经不存在=4的索引了,但i却依然会取到4,循环就会报错
因此在这里,一旦if被触发,即一旦合并发生,我们就让循环被破坏,使用break跳出当前循环
循环就会回到最开始的for i in range(20)中
此时判断第一组是否有两种标签的代码不会被触发,但for i in range(len(num_bins))却会被重新运行
这样就更新了i的取值,循环就不会报错了
"""
3.3.3 定义WOE和IV函数
#计算WOE和BAD RATE
#BAD RATE与bad%不是一个东西
#BAD RATE是一个箱中,坏的样本所占的比例 (bad/total)
#而bad%是一个箱中的坏样本占整个特征中的坏样本的比例
def get_woe(num_bins):
# 通过 num_bins 数据计算 woe
columns = ["min","max","count_0","count_1"]
df = pd.DataFrame(num_bins,columns=columns)
df["total"] = df.count_0 + df.count_1
df["percentage"] = df.total / df.total.sum()
df["bad_rate"] = df.count_1 / df.total
df["good%"] = df.count_0/df.count_0.sum()
df["bad%"] = df.count_1/df.count_1.sum()
df["woe"] = np.log(df["good%"] / df["bad%"])
return df
#计算IV值
def get_iv(df):
rate = df["good%"] - df["bad%"]
iv = np.sum(rate * df.woe)
return iv
3.3.4 卡方检验,合并箱体,画出IV曲线
num_bins_ = num_bins.copy()
import matplotlib.pyplot as plt
import scipy
IV = []
axisx = []
while len(num_bins_) > 2:
pvs = []
# 获取 num_bins_两两之间的卡方检验的置信度(或卡方值)
for i in range(len(num_bins_)-1):
x1 = num_bins_[i][2:]
x2 = num_bins_[i+1][2:]
# 0 返回 chi2 值,1 返回 p 值。
pv = scipy.stats.chi2_contingency([x1,x2])[1]
# chi2 = scipy.stats.chi2_contingency([x1,x2])[0]
pvs.append(pv)
# 通过 p 值进行处理。合并 p 值最大的两组
i = pvs.index(max(pvs))
num_bins_[i:i+2] = [(
num_bins_[i][0],
num_bins_[i+1][1],
num_bins_[i][2]+num_bins_[i+1][2],
num_bins_[i][3]+num_bins_[i+1][3])]
bins_df = get_woe(num_bins_)
axisx.append(len(num_bins_))
IV.append(get_iv(bins_df))
plt.figure()
plt.plot(axisx,IV)
plt.xticks(axisx)
plt.xlabel("number of box")
plt.ylabel("IV")
plt.show()
3.3.5 用最佳的分箱个数,并验证分箱结果
def get_bin(num_bins_,n):
while len(num_bins_) > n:
pvs = []
for i in range(len(num_bins_)-1):
x1 = num_bins_[i][2:]
x2 = num_bins_[i+1][2:]
pv = scipy.stats.chi2_contingency([x1,x2])[1]
# chi2 = scipy.stats.chi2_contingency([x1,x2])[0]
pvs.append(pv)
i = pvs.index(max(pvs))
num_bins_[i:i+2] = [(
num_bins_[i][0],
num_bins_[i+1][1],
num_bins_[i][2]+num_bins_[i+1][2],
num_bins_[i][3]+num_bins_[i+1][3])]
return num_bins_
afterbins = get_bin(num_bins,4)
afterbins
bins_df = get_woe(num_bins)
bins_df
3.3.6 将选取最佳分享个数的过程包装为函数
def graphforbestbin(DF, X, Y, n=5,q=20,graph=True):
"""
自动最优分箱函数,基于卡方检验的分箱
参数:
DF: 需要输入的数据
X: 需要分箱的列名
Y: 分箱数据对应的标签 Y 列名
n: 保留分箱个数
q: 初始分箱的个数
graph: 是否要画出IV图像
区间为前开后闭 (]
"""
DF = DF[[X,Y]].copy()
DF["qcut"],bins = pd.qcut(DF[X], retbins=True, q=q,duplicates="drop")
coount_y0 = DF.loc[DF[Y]==0].groupby(by="qcut").count()[Y]
coount_y1 = DF.loc[DF[Y]==1].groupby(by="qcut").count()[Y]
num_bins = [*zip(bins,bins[1:],coount_y0,coount_y1)]
for i in range(q):
if 0 in num_bins[0][2:]:
num_bins[0:2] = [(
num_bins[0][0],
num_bins[1][1],
num_bins[0][2]+num_bins[1][2],
num_bins[0][3]+num_bins[1][3])]
continue
for i in range(len(num_bins)):
if 0 in num_bins[i][2:]:
num_bins[i-1:i+1] = [(
num_bins[i-1][0],
num_bins[i][1],
num_bins[i-1][2]+num_bins[i][2],
num_bins[i-1][3]+num_bins[i][3])]
break
else:
break
def get_woe(num_bins):
columns = ["min","max","count_0","count_1"]
df = pd.DataFrame(num_bins,columns=columns)
df["total"] = df.count_0 + df.count_1
df["percentage"] = df.total / df.total.sum()
df["bad_rate"] = df.count_1 / df.total
df["good%"] = df.count_0/df.count_0.sum()
df["bad%"] = df.count_1/df.count_1.sum()
df["woe"] = np.log(df["good%"] / df["bad%"])
return df
def get_iv(df):
rate = df["good%"] - df["bad%"]
iv = np.sum(rate * df.woe)
return iv
IV = []
axisx = []
while len(num_bins) > n:
pvs = []
for i in range(len(num_bins)-1):
x1 = num_bins[i][2:]
x2 = num_bins[i+1][2:]
pv = scipy.stats.chi2_contingency([x1,x2])[1]
pvs.append(pv)
i = pvs.index(max(pvs))
num_bins[i:i+2] = [(
num_bins[i][0],
num_bins[i+1][1],
num_bins[i][2]+num_bins[i+1][2],
num_bins[i][3]+num_bins[i+1][3])]
bins_df = pd.DataFrame(get_woe(num_bins))
axisx.append(len(num_bins))
IV.append(get_iv(bins_df))
if graph:
plt.figure()
plt.plot(axisx,IV)
plt.xticks(axisx)
plt.xlabel("number of box")
plt.ylabel("IV")
plt.show()
return bins_df
3.3.7 对所有特征进行分箱选择
model_data.columns
for i in model_data.columns[1:-1]:
print(i)
我们发现,不是所有的特征都可以使用这个分箱函数,比如说有的特征,像家人数量,就无法分出20组。于是我们 将可以分箱的特征放出来单独分组,不能自动分箱的变量自己观察然后手写:
auto_col_bins = {"RevolvingUtilizationOfUnsecuredLines":6,
"age":5,
"DebtRatio":4,
"MonthlyIncome":3,
"NumberOfOpenCreditLinesAndLoans":5}
#不能使用自动分箱的变量
hand_bins = {"NumberOfTime30-59DaysPastDueNotWorse":[0,1,2,13]
,"NumberOfTimes90DaysLate":[0,1,2,17]
,"NumberRealEstateLoansOrLines":[0,1,2,4,54]
,"NumberOfTime60-89DaysPastDueNotWorse":[0,1,2,8]
,"NumberOfDependents":[0,1,2,3]}
#保证区间覆盖使用 np.inf替换最大值,用-np.inf替换最小值
hand_bins = {k:[-np.inf,*v[:-1],np.inf] for k,v in hand_bins.items()}
接下来对所有特征按照选择的箱体个数和手写的分箱范围进行分箱:
bins_of_col = {}
# 生成自动分箱的分箱区间和分箱后的 IV 值
for col in auto_col_bins:
bins_df = graphforbestbin(model_data,col
,"SeriousDlqin2yrs"
,n=auto_col_bins[col]
#使用字典的性质来取出每个特征所对应的箱的数量
,q=20
,graph=False)
bins_list = sorted(set(bins_df["min"]).union(bins_df["max"]))
#保证区间覆盖使用 np.inf 替换最大值 -np.inf 替换最小值
bins_list[0],bins_list[-1] = -np.inf,np.inf
bins_of_col[col] = bins_list
#合并手动分箱数据
bins_of_col.update(hand_bins)
bins_of_co
3.4 计算各箱的WOE并映射到数据中
我们现在已经有了我们的箱子,接下来我们要做的是计算各箱的WOE,并且把WOE替换到我们的原始数据 model_data中,因为我们将使用WOE覆盖后的数据来建模,我们希望获取的是”各个箱”的分类结果,即评分卡上 各个评分项目的分类结果。
data = model_data.copy()
#函数pd.cut,可以根据已知的分箱间隔把数据分箱
#参数为 pd.cut(数据,以列表表示的分箱间隔)
data = data[["age","SeriousDlqin2yrs"]].copy()
data["cut"] = pd.cut(data["age"],[-np.inf, 48.49986200790144, 58.757170160044694, 64.0,
74.0, np.inf])
data
#将数据按分箱结果聚合,并取出其中的标签值
data.groupby("cut")["SeriousDlqin2yrs"].value_counts()
#使用unstack()来将树状结构变成表状结构
data.groupby("cut")["SeriousDlqin2yrs"].value_counts().unstack()
bins_df = data.groupby("cut")["SeriousDlqin2yrs"].value_counts().unstack()
bins_df["woe"] = np.log((bins_df[0]/bins_df[0].sum())/(bins_df[1]/bins_df[1].sum()))
把以上过程包装成函数:
def get_woe(df,col,y,bins):
df = df[[col,y]].copy()
df["cut"] = pd.cut(df[col],bins)
bins_df = df.groupby("cut")[y].value_counts().unstack()
woe = bins_df["woe"] =
np.log((bins_df[0]/bins_df[0].sum())/(bins_df[1]/bins_df[1].sum()))
return woe
#将所有特征的WOE存储到字典当中
woeall = {}
for col in bins_of_col:
woeall[col] = get_woe(model_data,col,"SeriousDlqin2yrs",bins_of_col[col])
woeall
接下来,把所有WOE映射到原始数据中:
#不希望覆盖掉原本的数据,创建一个新的DataFrame,索引和原始数据model_data一模一样
model_woe = pd.DataFrame(index=model_data.index)
#将原数据分箱后,按箱的结果把WOE结构用map函数映射到数据中
model_woe["age"] = pd.cut(model_data["age"],bins_of_col["age"]).map(woeall["age"])
#对所有特征操作可以写成:
for col in bins_of_col:
model_woe[col] = pd.cut(model_data[col],bins_of_col[col]).map(woeall[col])
#将标签补充到数据中
model_woe["SeriousDlqin2yrs"] = model_data["SeriousDlqin2yrs"]
#这就是我们的建模数据了
model_woe.head()
3.5 建模验证
终于弄完了我们的训练集,接下来我们要处理测试集,在已经有分箱的情况下,测试集的处理就非常简单了,我们 只需要将已经计算好的WOE映射到测试集中去就可以了:
#处理测试集
vali_woe = pd.DataFrame(index=vali_data.index)
for col in bins_of_col:
vali_woe[col] = pd.cut(vali_data[col],bins_of_col[col]).map(woeall[col])
vali_woe["SeriousDlqin2yrs"] = vali_data["SeriousDlqin2yrs"]
vali_X = vali_woe.iloc[:,:-1]
vali_y = vali_woe.iloc[:,-1]
接下来,就可以开始顺利建模了:
X = model_woe.iloc[:,:-1]
y = model_woe.iloc[:,-1]
from sklearn.linear_model import LogisticRegression as LR
lr = LR().fit(X,y)
lr.score(vali_X,vali_y)
返回的结果一般,我们可以试着使用C和max_iter的学习曲线把逻辑回归的效果调上去。
c_1 = np.linspace(0.01,1,20)
c_2 = np.linspace(0.01,0.2,20)
score = []
for i in c_2:
lr = LR(solver='liblinear',C=i).fit(X,y)
score.append(lr.score(vali_X,vali_y))
plt.figure()
plt.plot(c_2,score)
plt.show()
lr.n_iter_
score = []
for i in [1,2,3,4,5,6]:
lr = LR(solver='liblinear',C=0.025,max_iter=i).fit(X,y)
score.append(lr.score(vali_X,vali_y))
plt.figure()
plt.plot([1,2,3,4,5,6],score)
plt.show()
尽管从准确率来看,我们的模型效果属于一般,但我们可以来看看ROC曲线上的结果。
import scikitplot as skplt
#%%cmd
#pip install scikit-plot
vali_proba_df = pd.DataFrame(lr.predict_proba(vali_X))
skplt.metrics.plot_roc(vali_y, vali_proba_df,
plot_micro=False,figsize=(6,6),
plot_macro=False)
3.6 制作评分卡
建模完毕,我们使用准确率和ROC曲线验证了模型的预测能力。接下来就是要讲逻辑回归转换为标准评分卡了。评
分卡中的分数,由以下公式计算:
S c o r e = A − B ∗ l o g ( o d d s ) Score = A-B*log(odds) Score=A−B∗log(odds)
其中A与B是常数,A叫做“补偿”,B叫做“刻度”, l o g ( o d d s ) log(odds) log(odds)代表了一个人违约的可能性。其实逻辑回归的结果取对 数几率形式会得到 θ T x \theta^Tx θTx,即我们的参数*特征矩阵,所以 l o g ( o d d s ) log(odds) log(odds) 其实就是我们的参数。两个常数可以通过两个假 设的分值带入公式求出,这两个假设分别是:
1、 某个特定的违约概率下的预期分值
2、 某个特定的违约概率下的预期分值
我们可以通过循环,将所有特征的评分卡内容全部一次性写往一个本地文件ScoreData.csv
file = "C:/work/learnbetter/micro-class/week 5 logit regression/ScoreData.csv"
#open是用来打开文件的python命令,第一个参数是文件的路径+文件名,如果你的文件是放在根目录下,则你只需要
文件名就好
#第二个参数是打开文件后的用途,"w"表示用于写入,通常使用的是"r",表示打开来阅读
#首先写入基准分数
#之后使用循环,每次生成一组score_age类似的分档和分数,不断写入文件之中
with open(file,"w") as fdata:
fdata.write("base_score,{}\n".format(base_score))
for i,col in enumerate(X.columns):
score = woeall[col] * (-B*lr.coef_[0][i])
score.name = "Score"
score.index.name = col
score.to_csv(file,header=True,mode="a")
至此,我们评分卡的内容就全部结束了。由于时间有限,我无法给大家面面俱到这个很难的模型,如果有时间,还 会给大家补充更多关于模型验证和评估的内容。其实大家可以发现,真正建模的部分不多,更多是我们如何处理数 据,如何利用统计和机器学习的方法将数据调整成我们希望的样子,所以除了算法,更加重要的是我们能够达成数 据目的的工程能力。这份代码也还有很多细节可以改进,大家在使用的时候可以多找bug多修正,敢于挑战现有的 内容,写出属于自己的分箱函数和评分卡模型。