如何用Python操作Excel自动化办公?一个案例教会你openpyxl——读取数据
![]()
欢迎大家关注我,我是拾陆,关注同名“二八Data”
数据分析工作最难搞的是处理数据的过程,不然不会有专门的ETL(数据抽取、转换、加载)工程师了。如果是企业级数据处理可能数据库直接搞定。不过对于日常办公人士来说就会有点麻烦,常常需要处理各种CSV/Excel表格。
如果数据量比较小、一次性事务处理的话,手动处理Excel表格就好,用程序或软件的话反而比较麻烦。但是如果数据量比较大、涉及多表操作、数据经常刷新、任务具有重复性,该怎么办呢?还手动吗,手会断掉吧?这个时候就需要借助自动化处理工具来帮忙高效解决问题。
通常自动化办公工具有哪些呢?第一种是Excel插件自动化,就是VBA,VBA可以封装函数和过程,加载之后可以重复调用,但是VBA比较难学,也常常会出现问题,我用过之后就放弃了;第二种是编程语言自动化,比如openpyxl、xlwings、pandas等Python第三方库操作Excel自动化增删改,相对来说比较好学点,DIY程度比较高,操作灵活,其实也是Python的强大之处,Python解决万物,不像VBA你苦心巴力学会了也只能用在Excel中用;第三种是RPA工具模拟人来物理操作Excel,RP是机器人流程自动化(Robotic process automation)的缩写,不仅可以操作Excel也可以实现其他流程的自动化,这也是我比较推崇的,后续会详细介绍,重点推荐大家了解相关知识,是提高生产力的神器。
这里要介绍的是openpyxl这个操作Excel的库。实际上用Python操作Excel的库有很多,时间上有先后,一些是在改进另一些的基础上产生的,但是这些包在不同的场景下各有其优势,所以没有好坏之分,需要用哪个就用哪个。
下面是一个简单的对比:
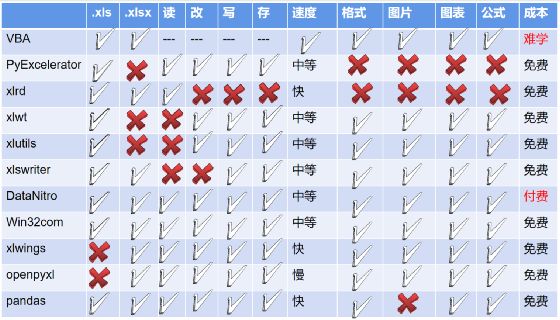
除了Pandas(pandas是专门处理大量表格数据的强大工具,openpyxl的很多功能如果使用pandas可以很轻易完成,但是openpyxl的好处是能细化到单元格处理,跟excel融合的很好,这两点是pandas无法比的),我用的最多的就是openpyxl,功能齐全,比较好理解。本篇的目的就是通过一个案例简单展示如何通过openpyxl读取Excel数据,(后续会通过各子篇完成如何修改数据、汇总数据、变换格式、添加图表、保存文件等整个数据分析流程),既学习了如何处理Excel,也完成一个完整的数据分析项目。
需要说明的是,openpyxl虽然操作Excel的功能强大,但读写性能过于糟糕,尤其是写大表时,会占用大量内存,开启read_only和write_only模式后对其性能有大幅提升。
一、安装openpyxl
安装的过程很简单,在anaconda环境里或者CMD命令行里都可以输入以下安装代码:
pip install openpyxl
二、打开Excel文件并读取
对于初学者,这里需要说明的是openpyxl优秀之处在于它利用我们对Excel的基本概念和习惯来操作,而不像其他库那样有自己的术语和操作习惯。
Excel中有工作簿(workbook)、工作表(sheet)、行(row)、列(column)、单元格(cell),我们操作Excel一般都是打开工作簿(workbook),选择一个工作表(sheet),对某一行某一列的单个单元格(cell)或者单元格区域进行数据的增删改查。仔细想想是不是这个过程?
我们借用外部工具来帮助我们处理Excel其实也是在模拟这个过程,目的是看中了它的自动化和反复调用能力使我们从重复性工作中解脱出来。所以使用openpyxl你不必记住太多概念,只要按照你平常的操作习惯写代码就好了。
1.首先要调用Excel就需要导入openpyxl包:
from openpyxl import Workbook,load_workbook
from openpyxl.utils import get_column_letter,column_index_from_string
Workbook是openpyxl库中的一个类,我们的操作就是基于Workbook对象来执行的,通过它可以创建新的工作簿,也可以对工作簿里的工作表进行操作,需要特别注意的是这里W一定要大写,否则会出错;load_workbook是用来导入已有的工作簿的类;utils顾名思义就是openpyxl包的辅助工具,它里面有很多操作Excel的辅助工具,比如get_column_letter就是将列号转换为字母,为什么要这样呢?因为有时候需要获取Excel文件里有数据的单元格最大列是多少,这个时候得到的列往往是数字,而我们要再次使用这个列号时需要把它转换成字母才能用,比如"BT32"、“AW41"里的”BT"、“AW”就是列号;相反,也会遇到把字母转换成数字的,那就使用column_index_from_string。
2.打开我们需要操作的Excel文件(也就是使用load_workbook来导入已有的工作簿):
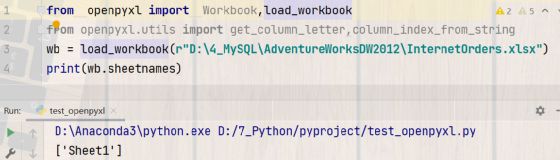
wb = load_workbook(r"D:\FactInternetSales.xlsx")
括号里传入的是你想打开的Excel文件存储路径,可以是相对路径(就是excel文件和你的程序文件在同一个目录下),也可以是绝对路径(找到文件存储位置,按“shift+右键”就可以看到复制文件路径),文件名最好不要是中文或特殊字符,否则会出现问题,小写字母r是为了防止转义符号“\”起作用,如果不加,需要把“\”换成“/”或者“\\”。这一句代码的意思是通过load_workbook这个类的调用功能把Excel里的数据导入程序,并赋值给wb变量,这个wb变量就是我们接下来要操作的对象。
3.选择要处理数据的工作表sheet
在选择工作表之前还需要知道有几张工作表:
3.1 查看工作表
#方法一
print(wb.sheetnames)
#方法二
for sheet in wb:
print(sheet.title)
这里显示只有一个sheet,我想创建一张新的sheet怎么办呢?
3.2 创建新工作表sheet
ws = wb.create_sheet('sheet2lu',0)
ws = wb.create_sheet(title="sheet2lu",index=1)
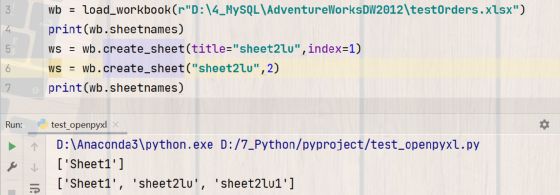
上面两行代码就是创建了两张工作表,第一行代码创建了sheet2lu,放在第一张表后1个位置;第二行代码还是创建sheet2lu,但是因为有了sheet2lu,所以自动加后缀1,这和我们手动操作Excel一样,不允许同名sheet。括号里的数字表示的是新建表格放置的位置。如果还需要对表进行命名、添加颜色和复制怎么办呢?
ws.title = "New Title" #给表进行命名
ws.sheet_properties.tabColor = "1072BA" #对表标签添加颜色
source = wb.active
ws2 = wb.copy_worksheet(wb.active) #对源表进行复制
如果想一次性创建很多sheet怎么办呢?可以通过循环列表创建,比手动快很多。
sheetlist = ['sheet3','sheet4','sheet5','sheet6','sheet7','sheet8']
for sheet in sheetlist:
wb.create_sheet(sheet)
3.3 指定工作sheet:
一张工作簿workbook有多个sheet,但总会有一个正在激活的sheet,默认都会有一个,我们打开excel时候就自动定位在上次保存的sheet,这样我们就可以在具体的sheet里工作了:
# ws = wb.active() 错误写法
ws = wb.active 正确写法
这里我之前犯过一个错误,给active后面加了一个括号,结果老是报错说’Worksheet’ object is not callable,所以一定要注意没有括号。当然,出了默认sheet我们也可以指定需要的sheet:
ws2 = wb["sheet2lu"]
ws3 = wb.get_sheet_by_name("sheet2lu1")
把sheet当做workbook的一个调用对象,可以用中括号直接调用,也可以通过sheet名字调用。
好了,我们获取了指定的工作表sheet,那接下来就看有什么数据啦!因为到目前为止我们虽然操作步骤都是按照平常操作Excel那样的,但是却没有直观的给我们显示数据,这就是Excel软件的好处,很直观。但其实Excel里的单元格实际是不存在的,因为它没有数据,但是为了让你直观的操作所以设定显示单元格网格。所以我们接下来就是要显示数据了。
4.显示Excel文件中的数据
4.1 获取单元格数据
获取第一个单元格数据:
#方法一
print(ws['A1'].value)
#方法二
a = ws['A1']
print(a.value)
#方法三
b = ws.cell(row=1,column=1)
print(b.value)
#方法四 format用来格式化字符串,字符串里留中括号,然后后面调用对于的变量
c = ws.cell(row=1,column=1)
print('Row {},Column {} is {}'.format(c.row,c.column,c.value))
#方法五 coordinate是单元格地址属性,包括行号和列号
c = ws.cell(row=1,column=1)
print('Cell {} is {}'.format(c.coordinate,c.value))
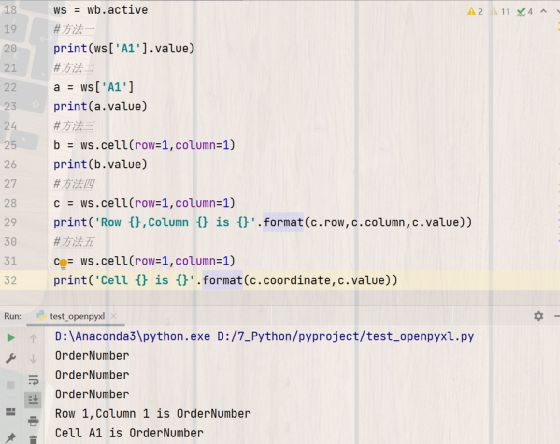
你看五种方法读到的值都是同一个内容“OrderNumber”,到底对不对呢?我们到现在还没有看到表格内容,接下来打开Excel文件来看一下:

单元格A1的内容的确是“OrderNumber”,这里需要解释的是.value的意思是取出单元格的值,如果直接写ws[‘A1’]返回的是一个对象而没有内容,因为这个对象有很多属性,.value只是其中一个属性。
4.2 单元格属性
单元格还有哪些属性呢?下面只是部分常用的,如果有其它需要可以查询官网,可以说把你所需要的的关于单元格的功能都涉及到了。
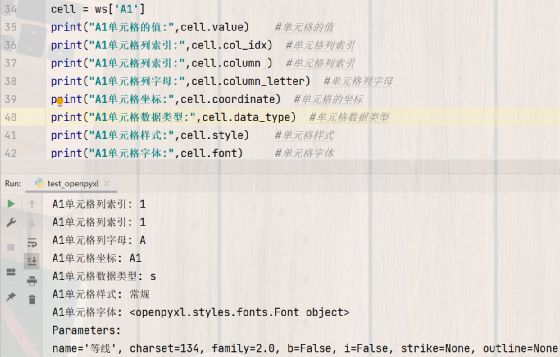
cell = ws['A1']
print("A1单元格的值:",cell.value) #单元格的值
print("A1单元格列索引:",cell.col_idx) #单元格列索引
print("A1单元格列索引:",cell.column ) #单元格列索引
print("A1单元格列字母:",cell.column_letter) #单元格列字母
print("A1单元格坐标:",cell.coordinate) #单元格的坐标
print("A1单元格数据类型:",cell.data_type) #单元格数据类型
print("A1单元格样式:",cell.style) #单元格样式
print("A1单元格字体:",cell.font)
4.3 获取单元格区域数据
再接着上面的问题,那我要是想取出单元格区域,比如说’A1:F10’,怎么办呢?
#方法一 直接切片,用单元格地址圈出一个区域,就像在Excel表格里用鼠标圈一个框框
Cellarea1 = ws['A1:F10']
for col in Cellarea1:
for cell in col:
print(cell.value,end=",")
#方法二 用迭代行循环打印
for row in ws.iter_rows(min_row=1,max_row=10,max_col=6):
for cell in row:
print(cell.value)
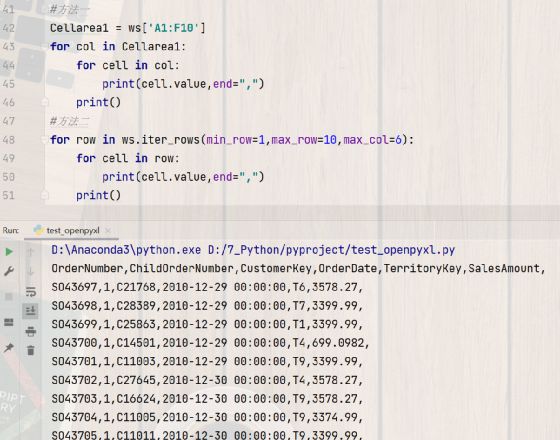
这里两种方式都需要循环逐一打印出单元格的值。得到的是不是就是上面表中的写法呢?
4.4 获取最后一个单元格值
接下来我想知道这个Excel表格有数据的最大行最大列是哪里呢?因为IDE里不像在Excel软件里可以拖动直接看到最后,所以需要代码获取:
print(ws.max_column)
print(ws.max_row)
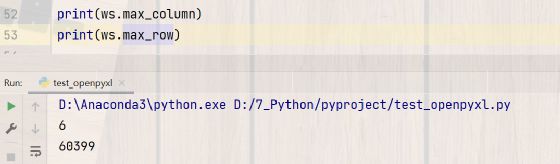
这样就知道了数据表的大小,有6列60399行。看它返回的就是数字,不会返回字母,但是要是想知道最后一个单元格的值是什么怎么办呢?
lastcelladdress = get_column_letter(ws.max_column)+str(ws.max_row)
lastcell = ws[lastcelladdress]
print(lastcell.value)
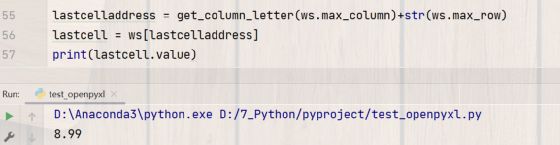
第一行代码表示的是用get_column_letter转换获取到的最大列号为字母,单元格地址是字母加数字组成,又因为行号是数字不能直接跟字母拼接,所以需要转换成字符串,得到的单元格地址赋值给lastcell,就得到最后一个单元格的数据。
以上就使用openpyxl获取已有的Excel文件的内容了,接下来会讲解如何修改数据、汇总数据、变换格式、添加图表、保存文件,完成整个数据分析流程。
最后欢迎大家关注我,我是拾陆,关注同名“二八Data”,更多技术干货持续奉献。