最优的纯文本模型?GPT-4蓄势待发

作者|Alberto Romero
来源|机器之心
2020 年 5 月,在 GPT-2 发布一年后,GPT-3 正式发布,而 GPT-2 也是在原始 GPT 论文发表一年后发布的。按照这种趋势, GPT-4 早在一年前就该发布了,但至今尚未面世。
OpenAI 的首席执行官 Sam Altman 几个月前表示即将推出 GPT-4 ,预计将在 2022 年 7 月至 8 月发布。
GPT-3 的强大性能让人们对 GPT-4 的期望颇高。然而关于 GPT-4 的公开信息甚少,Altman 在去年的一次 Q&A 中就 OpenAI 对 GPT-4 的想法给出了一些提示。他明确表示,GPT-4 不会有 100T 参数。
正因为 GPT-4 的公开信息很少,人们对其做出诸多预测。近期,一位分析师 Alberto Romero 基于 OpenAI 和 Sam Altman 透露的信息,以及当前趋势和语言 AI 的最新技术,对 GPT-4 作出了一番新的预测,以下是他的预测原文。
1
模型大小:GPT-4 不会非常大
GPT-4 不会成为最大的语言模型,Altman 曾说它不会比 GPT-3 大多少。它的大小可能在 GPT-3 和 Gopher 之间 (175B -280B)。
这个推测有充分的理由。
NVIDIA 和微软去年联合创建的威震天 - 图灵 NLG( MT-NLG)号称是拥有 530B 参数的最大密集神经网络,参数量已经是 GPT-3 的 3 倍,而最近谷歌的 PaLM 已有 540B 参数。但值得注意的是,在 MT-NLG 之后出现的一些较小的模型反而达到了更高的性能水平。
这意味着:更大不一定更好。
业内很多公司已经意识到模型大小不是性能的决定因素,扩大模型也不是提升性能的最好方法。2020 年,OpenAI 的 Jared Kaplan 及其同事得出结论:当增加的计算预算主要分配到增加参数的数量上时,性能的提高是最显著的,并且遵循幂律关系。
然而,以超大规模的 MT-NLG 为例,它在性能方面并不是最好的。事实上,甚至在任何单一类别的基准测试中都不是最好的。较小的模型,如 Gopher (280B)或 Chinchilla (70B) 在一些任务上比 MT-NLG 好得多。
显然,模型大小并不是实现更好的语言理解性能的唯一因素。
业内多家公司开始放弃「越大越好」的教条。拥有更多参数也会带来一些副作用,例如计算成本过高、性能进入瓶颈期。当能够从较小的模型中获得相似或更好的结果时,这些公司就会在构建巨大模型之前三思而后行。
Altman 表示,他们不再专注于让模型变得更大,而是让更小的模型发挥最大的作用。OpenAI 是扩展假设(scaling hypothesis)的早期倡导者,但现在已经意识到其他未探索的路径也能改进模型。
因此,GPT-4 不会比 GPT-3 大很多。OpenAI 将把重点转移到其他方面,例如数据、算法、参数化和价值对齐(alignment)等,这可能会带来更显著的改进。关于 100T 参数模型的功能,我们只能等待了。
2
优化:GPT追求“最优”
语言模型在优化方面存在一个关键限制,即训练成本非常高。以至于研发团队不得不在准确性和成本之间进行权衡。这通常会导致模型明显欠优化。
GPT-3 只训练了一次,当在一些用例中出现错误时就要重新进行训练。OpenAI 决定,GPT-4 不会采取这种方式,因为成本太高,研究人员无法找到模型的最佳超参数集(例如学习率、批大小、序列长度等)。
高训练成本的另一个后果是,对模型行为的分析要受到限制。Kaplan 的团队得出模型大小是提高性能最相关的变量时,他们并没有考虑训练 token 的数量,这需要大量的计算资源。
不得不承认,一些大型公司依照 Kaplan 团队的结论,在扩大模型上「浪费」了数百万美元。现在,以 DeepMind 和 OpenAI 为首的公司正在探索其他方法。他们试图找到最优的模型,而不仅仅是更大的模型。
优化参数
上个月,微软和 OpenAI 证实用优化后的超参数进行训练,GPT-3 能够获得较大的改进。他们发现,6.7B 版本的 GPT-3 性能大幅提升,可与最初的 13B GPT-3 相媲美。超参数调优带来的性能提升,相当于参数量增加了一倍。
他们利用一种称为μP 的新型参数化方式,其中小模型的最佳超参数同样适用于同类型的大模型。因此,μP 能够以一小部分训练成本优化任意大小的模型,几乎毫无成本地将超参数迁移到更大的模型中。
优化计算模型
几周前,DeepMind 重新审视了 Kaplan 等人的发现,并意识到:与人们认为的相反,训练 token 的数量对性能的影响与模型大小的影响一样大。DeepMind 得出结论:计算预算应该平均分配给扩展参数和数据。他们用大型语言模型 4 倍的数据量(1.4T token)训练 Chinchilla(70B)证明了这个假设。
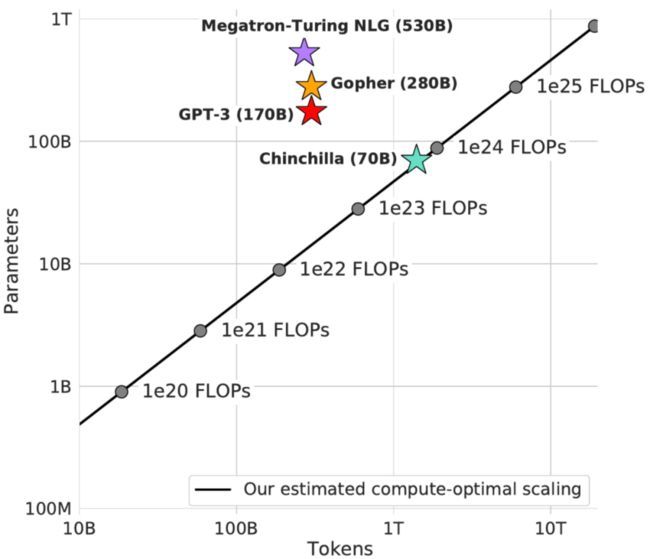
图源:DeepMind
结果很明确,Chinchilla 在许多语言基准测试中「显著」优于 Gopher、GPT-3、MT-NLG 等语言模型,这表明当前的大模型训练不足且规模过大。
考虑到 GPT-4 将比 GPT-3 略大,根据 DeepMind 的发现,它达到计算最优所需的训练 token 数量将约为 5 万亿,比当前数据集高出一个数量级。为了最小化训练损失,训练 GPT-4 所需的 FLOP 将是 GPT-3 的约 10-20 倍(参照 Gopher 的计算量)。
Altman 曾在 Q&A 中表示 GPT-4 的计算量将比 GPT-3 更大,他可能指的就是这一点。
可以肯定的是,OpenAI 将致力于优化模型大小以外的其他变量。找到最佳的超参数集以及最佳的计算模型大小和参数数量,这可能会让模型在所有基准测试中获得令人难以置信的提升。
3
多模态:GPT-4 将是纯文本模型
人类的大脑是多感官的,因为我们生活在一个多模态的世界中。一次只以一种模态感知世界,极大地限制了人工智能理解世界的能力。因此,人们认为深度学习的未来是多模态模型。
然而,良好的多模态模型比良好的纯语言或纯视觉模型更难构建。将视觉和文本信息组合成单一的表征是一项非常艰巨的任务。我们对大脑如何做到这一点的认知还非常有限,难以在神经网络中实现它。
大概也是出于此原因,Altman 在 Q&A 中也表示,GPT-4 不会是多模态的,而是纯文本模型。我猜测在转向下一代多模态 AI 之前,他们正试图通过调整模型和数据集大小等因素达到语言模型的极限。
4
稀疏性:GPT-4 将是一个密集模型
近来,稀疏模型利用条件计算,使用模型的不同部分来处理不同类型的输入,取得了巨大成功。这些模型可以轻松扩展到超过 1T 的参数 mark 上,而不会导致过高的计算成本,从而在模型大小和计算预算之间构建出正交关系。然而,这种 MoE 方法的优势在非常大的模型上会有所减弱。
鉴于 OpenAI 一直专注于密集语言模型,我们有理由预期 GPT-4 也将是一个密集模型。
不过,人类的大脑严重依赖于稀疏处理,稀疏性与多模态类似,很可能会主导未来几代神经网络。
5
GPT-4 将比 GPT-3 更加对齐
OpenAI 为解决 AI 价值观对齐(alignment)的问题付出了诸多努力:如何让语言模型遵循我们的意图并遵守我们的价值观。这不仅需要数学上让 AI 实现更准确的理解,而且需要在哲学方面考量不同人类群体之间的价值观。OpenAI 已尝试在 InstructGPT 上接受人工反馈训练以学会遵循指令。
InstructGPT 的主要突破在于,无论其在语言基准上的结果如何,它都被人类评估者一致认为是一比 GPT-3 更好的模型。这表明,使用基准测试作为评估 AI 能力的唯一指标是不合适的。人类如何看待模型同样重要,甚至更重要。
鉴于 Altman 和 OpenAI 对有益 AGI 的承诺,我相信GPT-4将实现并构建他们从InstructGPT中发现的成果。
他们将改进对齐模型的方式,因为 GPT-3 只采用了英文语料和注释。真正的对齐应该包含来自不同性别、种族、国籍、宗教等方面的信息特征。这是一个巨大的挑战,朝着这个目标迈进意义重大。
6
总结
综上,我关于 GPT-4 的预测大致包括以下几个方面:
模型大小:GPT-4 会比 GPT-3 大,但不会很大。模型大小不会是其显著特征;
优化:GPT-4 将使用比 GPT-3 更多的计算,它将在参数化(最优超参数)和扩展定律(训练 token 的数量与模型大小一样重要)方面做出新的改进;
多模态:GPT-4 将是纯文本模型,OpenAI 正试图将语言模型发挥到极致,然后再转变成像 DALL·E 这样的多模态模型;
稀疏性:GPT-4 遵循 GPT-2 和 GPT-3 的趋势,它将是一个密集模型,但稀疏性未来将占据主导地位;
对齐:GPT-4 将比 GPT-3 更符合人们的价值要求,它将应用从 InstructGPT 中学到的经验。
Alberto Romero 根据 Altman 和 OpenAI 给出的信息作出了有理有据的推测,期待这些预测在几个月后在即将面世的 GPT-4 中得到印证。
(本文经授权后发布,原文:https://towardsdatascience.com/gpt-4-is-coming-soon-heres-what-we-know-about-it-64db058cfd45)
其他人都在看
-
CUDA优化之PReLU性能调优
-
25倍性能加速,OneFlow“超速”了
-
一个GitHub史上增长最快的AI项目
-
天才制造者:独行侠、科技巨头和AI
-
DeepMind爆发史:决定AI高峰的“游戏玩家”
-
解读Pathways(二):向前一步是OneFlow
-
OneFlow v0.7.0发布:全新分布式接口,LiBai、Serving等一应俱全
欢迎下载体验OneFlow v0.7.0:GitHub - Oneflow-Inc/oneflow: OneFlow is a performance-centered and open-source deep learning framework. https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/