one-hot理解
一、基础知识
one-hot是比较常用的文本特征特征提取的方法。
one-hot编码,又称“独热编码”。其实就是用N位状态寄存器编码N个状态,每个状态都有独立的寄存器位,且这些寄存器位中只有一位有效,说白了就是只能有一个状态。
假设有四个样本,每个样本有三种特征:
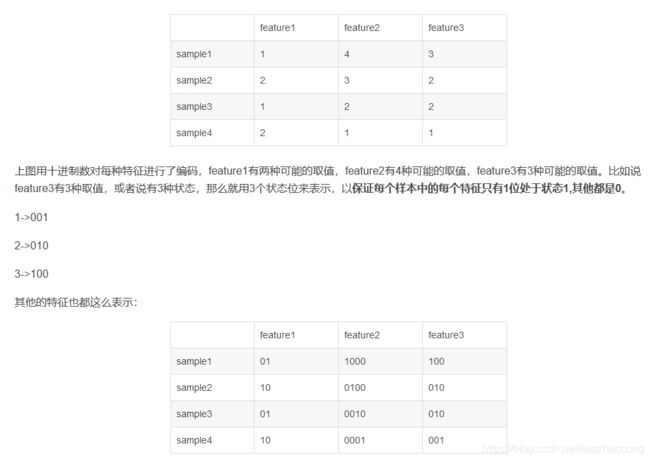
这样,4个样本的特征向量就可以这么表示:
sample1 -> [0,1,1,0,0,0,1,0,0]
sample2 -> [1,0,0,1,0,0,0,1,0]
sample3 -> [0,1,0,0,1,0,0,1,0]
sample4 -> [1,0,0,0,0,1,0,0,1]
举个例子


在举个例子
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(handle_unknown='ignore')
X = [['Male', 1], ['Female', 3], ['Female', 2]]
enc.fit(X)## fit来学习编码
enc.categories_
特征1为male和female两种类型,特征2为1/2/3三种类型,也即

用fit训练

enc.transform([['Female', 1], ['Male', 4]]).toarray() # 将one-hot encode转换成数组(顺转换)
enc.inverse_transform([[0, 1, 1, 0, 0], [0, 0, 0, 1, 0]]) #逆转换

再举个例子
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder()
X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
enc.fit(X),
enc.transform([['female', 'from US', 'uses Safari'],
['male', 'from Europe', 'uses Safari']]).toarray()
enc.categories_

二、完整示例
1)方法一
1、导包、导入数据
from sklearn import datasets
import numpy as np
iris = datasets.load_iris()
X = iris.data
y = iris.target
2、预处理OneHotEncoder编码
from sklearn import preprocessing
cat_encoder = preprocessing.OneHotEncoder()
cat_encoder.fit_transform(y.reshape(-1,1)).toarray()[:5]
cat_encoder.transform(np.ones((3, 1))).toarray()
3、导入模型、并实例化
from sklearn.linear_model import Ridge
ridge_inst = Ridge()
from sklearn.multioutput import MultiOutputRegressor
multi_ridge = MultiOutputRegressor(ridge_inst, n_jobs=-1) #Instantiate 将实例作为参数
4、OneHotEncoder编码
用OneHotEncoder()将y转换成y_multi三个变量
from sklearn import preprocessing
cat_encoder = preprocessing.OneHotEncoder()
y_multi = cat_encoder.fit_transform(y.reshape(-1,1)).toarray()
5、划分数据集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_multi, stratify=y, random_state= 7)
6、训练数据集
multi_ridge.fit(X_train, y_train)
7、预测多输出目标
y_multi_pre = multi_ridge.predict(X_test)
y_multi_pre[:5]
8、利用binarize转换
from sklearn import preprocessing
y_multi_pred = preprocessing.binarize(y_multi_pre,threshold=0.5)
y_multi_pred[:5]
9.打分
from sklearn.metrics import roc_auc_score
roc_auc_score(y_test, y_multi_pre)
或者
from sklearn.metrics import accuracy_score
print ("Multi-Output Scores for the Iris Flowers: ")
for column_number in range(0,3):
print ("Accuracy score of flower " + str(column_number),accuracy_score(y_test[:,column_number], y_multi_pred[:,column_number]))
print ("AUC score of flower " + str(column_number),roc_auc_score(y_test[:,column_number], y_multi_pre[:,column_number]))
print ("")
1)方法二
from sklearn.feature_extraction import DictVectorizer
dv = DictVectorizer()
my_dict = [{'species': iris.target_names[i]} for i in y]
dv.fit_transform(my_dict).toarray()[:5]
参考文献
1、one-hot理解
2、预处理数据的方法总结
3、官网
4、scikit-learn cookbook