创新项目实训:数据爬取
宝可梦数据爬取
- 数据爬取
-
- 爬取中遇到的问题及解决
-
- AttributeError: 'NoneType' object has no attribute 'encoding'
- IndexError: list index out of range
- 宝可梦大葱鸭的英文名读取错误
数据爬取
爬虫简介:
网络爬虫是编写脚本来模拟浏览器,向网站服务器发出请求,让服务器返回网页信息,然后解析网页并提取需要的数据保存。
爬取目标:宝可梦主页链接
爬取结果:

爬取实现:代码如下:
import os
import pandas as pd
import requests
#第一步:获取所有宝可梦的编号和名字
#爬虫优化,超时重试
def get_html(url):
i = 0
#最多重连5次
while i <= 5:
try:
#最大连接等待时间30秒,最大响应等待时间60秒
resp = requests.get(url,timeout=(30,60))
resp.encoding = 'utf-8'
return resp
except requests.exceptions.RequestException:
i += 1
print('超时{}次'.format(i))
#生成宝可梦列表(按全国图鉴编号)简单版页面后,可以注释这段代码,然后需要对data.html进行部分修改(下面会提及)
#url = 'https://wiki.52poke.com/wiki/宝可梦列表(按全国图鉴编号)/简单版'
#data = get_html(url)
#f = open('C:/Users/dell/PycharmProjects/pythonProject1/helloworld/HTML/data.html','w',encoding='utf-8')
#data.encoding='utf-8'
#f.write(data.text)
#f.close()
#读取data.html,获取完善的编号和名字
import re
f = open('C:/Users/dell/PycharmProjects/pythonProject1/helloworld/HTML/data.html','r',encoding='utf-8')
#data.html的读取
data_html = f.read()
f.close()
#只获取编号和名字,多余内容过滤
data_html = data_html.split('#001')[1]
data_html = data_html.split('Enamorus')[0]
data_html = ' #001' + data_html + 'Enamorus'
#编号
ids = re.findall(' #(.*?)\n ',data_html)
#名字
names = re.findall('title="(.*?)"',data_html)
#去掉世代
def func(s):
return not '世代' in s
names = list(filter(func,names))
#第二步:爬取各宝可梦的页面,获取其属性、特性等
#数据写进列表里
l = []
#遍历ids,生成各宝可梦html,再各自爬取
for i in range(len(ids)):
#每只宝可梦数据写入字典中
D_data = {}
D_data['id'] = ids[i]
D_data['中文名'] = names[i * 3]
D_data['日文名'] = names[i * 3 + 1]
D_data['英文名'] = names[i * 3 + 2]
print(D_data)
html = ''
# 判断若存在ids号的html,打开读取
if os.path.exists('C:/Users/dell/PycharmProjects/pythonProject1/helloworld/HTML/{}.html'.format(ids[i])):
f = open('C:/Users/dell/PycharmProjects/pythonProject1/helloworld/HTML/' + ids[i] + '.html', 'r', encoding='utf-8')
html = f.read()
f.close()
# 若不存在,生成ids号的html
else:
url = 'https://wiki.52poke.com/wiki/' + D_data['中文名']
resp = get_html(url)
f = open('C:/Users/dell/PycharmProjects/pythonProject1/helloworld/HTML/' + ids[i] + '.html', 'w', encoding='utf-8')
resp.encoding = 'utf-8'
f.write(resp.text)
html = resp.text
f.close()
#正则表达式,获取属性
type = re.findall('title="(.*?)(属性)">', html)
print(type)
D_data['属性1'] = type[0]
D_data['属性2'] = len(type) > 1 and type[1] or ''
if len(D_data['属性1']) > 5 or D_data['属性1'] == '':
D_data['属性1'] = D_data['属性2']
if len(D_data['属性2']) > 5 or D_data['属性2'] == '':
D_data['属性2'] = D_data['属性1']
try:
#开始无法获取,列表为空的时候跳过
skill = re.findall('title="(.*?)(特性)">', html)
print(skill)
D_data['特性1'] = skill[0]
D_data['特性2'] = len(skill) > 1 and skill[1] or ''
if len(D_data['特性2']) > 5 or D_data['特性2'] == '':
D_data['特性2'] = D_data['特性1']
D_data['特性3'] = len(skill) > 2 and skill[2] or ''
if len(D_data['特性3']) > 5 or D_data['特性3'] == '':
D_data['特性3'] = D_data['特性2']
D_data['HP'] = re.findall('title="HP">HP:爬取中遇到的问题及解决
AttributeError: ‘NoneType’ object has no attribute ‘encoding’
首先在过滤掉多余的内容只获取编号和名字,再通过中文名字获取每个宝可梦角色的网页,最后以其编号命名形式生成各自的html。
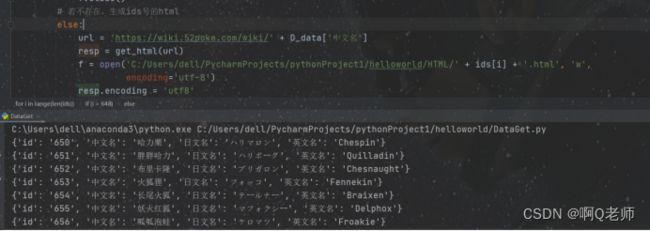
在生成到649.html后停止,报错:AttributeError: ‘NoneType’ object has no attribute ‘encoding’。
解决办法是将代码中的resp.encoding = 'utf-8'改为resp.encoding = 'utf8'
成功执行,如图:
IndexError: list index out of range
获取完html后,再通过保存下来的各个宝可梦html去爬取宝可梦的特性、属性等
但无法执行,报错:IndexError: list index out of range,如图:

解决步骤是:
1.调试,打印print(skill),发现是空列表;
2.利用try:
代码段
except IndexError:
pass
测试;
部分结果如图:

我们发现第一行数据为空,说明001.html并没有爬取到我们的数据;经比较法发现,生成的001.html不对。
#删除001.html,重新写入:
import requests
url = 'https://wiki.52poke.com/wiki/妙蛙种子'
resp = requests.get(url)
f = open('C:/Users/dell/PycharmProjects/pythonProject1/helloworld/HTML/' + '001' + '.html', 'w',encoding='utf-8')
resp.encoding = 'utf-8'
f.write(resp.text)
html = resp.text
f.close()
问题成功解决。执行到649.html停止,报错:IndexError: list index out of range

按上述经验查找649.html,发现为空(可能跟第一个问题有些关联)
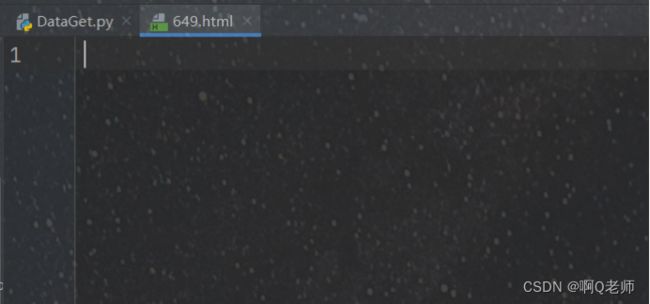
按上述经验再次生成649.html
import requests
url = 'https://wiki.52poke.com/wiki/盖诺赛克特'
resp = requests.get(url)
f = open('C:/Users/dell/PycharmProjects/pythonProject1/helloworld/HTML/' + '649' + '.html', 'w',encoding='utf-8')
resp.encoding = 'utf-8'
f.write(resp.text)
html = resp.text
f.close()
成功执行,部分结果如图:

宝可梦大葱鸭的英文名读取错误
后来在爬取宝可梦图片中发现,083.png并不能显示出来。经发现英文名不符,实际上是:Farfetch’d
而结果是:
![]()
单引号(’)的字符实体是'。ASCII是用来表示英文字符的一种编码规范。要使ASCII编码表所对应的字符被浏览器识别,就需要使用到HTML字符实体。
解决方法:
打开data.html,在041行中将 title=”Farfetch’d” 改为 title=”Farfetch’d”。删除BKM.csv,同时在重新运行时,要注释生成data.html的代码。
![]()
![]()
csv文件结果如图:
![]()