[Style Transfer]——GANs for Medical Image Analysis
论文阅读之GANs for Medical Image Analysis
Abstract
生成对抗网络及其变体在医学图像去噪、重建、分割、生成、检测及分类等任务中均有诸多应用,此外,GAN强大的生成能力可以生成更为逼真的图样,很大程度上减轻了医学图像样本稀缺的问题。
本文主要对GAN在医学图像领域的一些应用进行综述,截止到2018年末,对于各种方法的优点和不足以图表的形式罗列出来方便对比。
Section I Introduction
在医学图像分析的早期阶段,机器学习和人工智能算法就一直是一些复杂决策任务中的关键部分,研究人员的不懈努力聚焦于如何在更精细的粒度上进行决策,如特征工程、以监督方式训练CNN作为功能强大的分类器。
在医学图像分析领域(MIA,Medical Image Analsis)的研究焦点一直在与监督学习决策边界,而生成模型一直不是研究热点。随着GAN的横空出世,昔日的冷板凳翻身了,GAN强大的生成能力可以更好的模拟数据分布,弥补了监督学习与图像生成之间的巨大差距。
GAN的强大之处源自以下特点:
(1)GAN通过间接监督利用密度比估计,从而最大化数据分布上的概率密度
(2)GAN可以捕捉到数据在高维隐空间中的视觉特征表达,从而显著提升模型性能
本文对2018年末之前GAN在医学图像处理方面的相关研究进行综述,分成了7大类:图像合成、图像分割、图像重建、图像检测、图像去噪、图像配准、图像分类。
主要涉及的图像格式有:MRI、CT、OCT、X-Ray、Dermoscopy(皮肤镜)、超声、PET和显微镜图像。
![[Style Transfer]——GANs for Medical Image Analysis_第1张图片](http://img.e-com-net.com/image/info8/21d326c30c1c422882c96c15b04502b6.jpg)
Fig1展示了GAN用于上述7类应用各自所占比重,共涉及77篇论文,对以上工作进行总结分析旨在为进一步的研究提供一定的参考方向。
Section 3主要介绍GAN的基础知识及相关变体;
Section 4分别总结GAN在上述47大方向中的具体研究进展;
Section 5总结分析,并未进一步的研究指明方向。
Section II Opportunities for Medical Image Analysis
监督学习目前在许多计算机视觉和医学图像分析任务中取得了SOTA的结果,但每一种框架的成功都依赖于大规模的带标签的训练数据。而在医学领域最稀缺的恰恰是可用的训练数据,因为训练数据的采集、标注十分费时费力;另一方面医学图像数据集与自然图像数据集相比,还有很严重的类别不均衡问题(class imbalance).借助GAN强大的生成能力可以有效解决上述两大问题,根据是否有约束条件的参与分成(1)无条件和(2)条件生成两大类别。
GAN提出之初是一个无条件、无监督的生成模型,用于对生成的数据影响有限;而条件GAN允许基于一些先验信息(如类别标签、图像属性或图像本身)来约束数据生成。
考虑到带标签数据难以获取,但不带标签的数据往往获取较为容易,因此近年来也提出了所谓的半监督方法(Semi-Supervised Deep Learning),可以基于带标签和任意不带标签的未标记数据联合进行分类器或分割网络的训练。
GAN应用还有一个常见问题就是域迁移问题(domain shift),由于训练数据和测试数据分布之间的差异,使得模型在训练数据之外的数据上泛化能力很差,会有一些潜在的不可预测的行为。比如来自不同设备的MR图像或者由于不同采集批次导致染色不同的组织学病理图像,都会由于域迁移影响模型性能。
通过引入GAN进行对抗学习,可以学习到更加丰富的相似性度量,与传统的l1,l2距离相比他们缺乏空间信息的参与,最后产生的是一个模糊的度量结果,而GAN可以在像素级别以外的图像概念层面进行相似性度量。
GAN也为一些时间复杂度高的算法提供了另一种解决思路,如图像重建、配准,这些任务在数学上已经建立了很好的模型,就是迭代优化的成本太高;GAN是直接学习原始输入到重建后或配准图像的映射,仅经过一次前向传播过程,因此大大减少了时间成本。
Section III Basic GAN Models
本节主要介绍GAN及相关变体:DCGAN,Markovian GAN,CycleGAN,Auxiliary GAN,WGAN,Least Squares GAN。
在此之前,还需要理解以下概念:
对抗攻击:Adversarial attack指的是对图像进行一些细微修改,使得分类器产生分类错误;
对抗训练:Adversarial training是Szegedy等人提出的,通过训练过程中引入正常训练样本和对抗攻击的样本从而提升模型的鲁棒性。
GAN
GAN的结构不再赘述,由生成器和判别器构成,其中生成器是一个多层网络负责学习真实训练数据的分布,从而生成以假乱真的生成样本判别器则是一个二分类网络用于区分真实样本和生成样本。
其中G根据D反向传播的梯度进行参数更新;x,z和x^之前没有显式关系因此不必担心G会显式记住输入;损失函数其实是在优化真实数据分布与合成数据分布之间的JS散度。
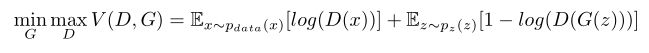
尽管GAN的理论基础很完备,但实际中GAN训练较难收敛,需要微调各种超参,防止梯度消失或爆炸;还很容易导致mode collapse,也就是仅学习到真实分布的一部分导致生成的模式局限在一定范围,还会导致跳模(mode hopping)。因此为了避免上述问题,对GAN 进行了一系列改进;
DCGAN:
为了提升GAN的稳定性以及生成图像的分辨率,2015年Radford等人提出了DeepConvolutional GAN(DCGAN),DCGAN中不管是生成器还是判别器都是用了卷积神经网络来代替原始GAN中的多层感知机,从而有效地学习层次特征;为了提升训练的稳定性还是用了BN,LeakyReLU,但仍未完全解决模式崩溃的问题。
cGAN:
2014年Mirza等人提出Conditional GAN从而可以通过用户影响生成的数据。CGAN具体结构参见Fig3,可以看到与原始GAN相比,D和G的输入均加入了额外的conditional信息c。
![]()
MGAN:
Markovian GAN是另一种条件生成网络,主要用于加速、提升风格迁移的效果。MGAN结构如Fig4所示,可以看到D和G前面都经过了一个预训练的VGG19网络用于提取特征图谱,此外还是用了额外的感知损失函数(perceptual loss)。
Pix2Pix:
2017年Isola提出的Pix2Pix是一款非常成功的用于高分辨率图像变换的框架,Pix2Pix的生成网络参照UNet,判别网络参照MGAN,UNet中的跳跃连接(skip connections)对于保持生成图像的一致性非常有效;需要注意的是Pix2Pix输入的不再是随机噪声,而是原始图像,因此训练过程是基于图像对的。
CycleGAN:
为了完成域迁移任务,模型应该能够学习两个域(源域和目标域)的特征以及两个域之间的映射关系,2017年提出的CycleGAN通过两个域的循环一致性变化有效地学习两个域之间的映射关系,Fig5具体展示了两个方向的循环学习。
![]()
![]()
AC-GAN:
Auxiliary Classifier GAN是2017年Google提出的,主要用于进行多分类的数据增强。与原始GAN不同之处在于,输入除了随机噪声外还多了一个额外的类别信息,而判别网络的输出除了判别fake or real还多了一项类别判断,从Fig6也能看出,D的输出多了一项额外的分类网络,这样判别器部分可以使用预训练好的网络,也会是的训练更稳定。
WGAN:
前述GAN的变体,其生成数据和原始数据分布通过JS散度来度量其相似度,WGAN则是使用Wasserstrin距离来作为相似性度量的,研究表明这样模型鲁棒性更佳,但实际应用中迭代优化进行的比较慢。
LSGAN:
2017年Mao等人提出了最小二乘生成对抗网络(Least Square GAN),主要改进就是将交叉熵损失函数替换为最小二乘损失函数,从而提升生成图像的质量,同时增加训练稳定性。
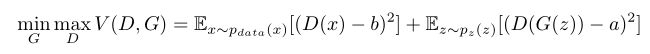
![[Style Transfer]——GANs for Medical Image Analysis_第2张图片](http://img.e-com-net.com/image/info8/3bfdc4256e5e40acb2947f20553790d7.jpg)
Section IV Applications in MIA
Part A Synthesis
GAN作为无监督的生成模型,通过学习真实数据的分布可以将输入的随机噪声生成逼真的图像,而cGAN通过conitional information的加入使得用户可以以监督学习的方式影响数据生成,因此可以分为supervised synthesis和nsupervised synthesis两类。
Unsupervised GAN
无监督学习的GAN主要用于数据扩增以及训练数据的类别不均衡问题。如DCGAN被用于合成肺结节、视网膜及皮肤损伤图像用于数据增强;缺点在于如果要生成不同类别的样本则需要训练多个生成模型。而考虑到训练用的数据集规模都不大,因此在不同GAN的训练中都需要先进行数据扩增,在利用DCGAN进行肝脏损伤检测的研究中已经证利用合成的样本扩充数据集可大大提升分类器的性能。
Bernudez等人还将DCGAN用于在样本量较少的情况下学习高分辨率MR图像的数据分布,在训练1500个epoch后就可以生成以假乱真的MR图像;类似的思想还有Baur等人采用progressiveGAN的方法合成高分辨率的皮肤损伤图像。
Supervised GAN
上一小节的Unsupervised GAN用户无法干预图像的生成,而通过加入额外的条件信息可以对GAN生成的图像施加约束,即supervised GAN.
CT from MR:
临床上很多疾病的诊断需要借助CT图像,但CT拍摄的辐射剂量使得患者暴露在细胞损伤或患癌的风险之中,这就使得依据MR图像生成CT图像变得很有必要。
Nie等人率先基于级联的3D全卷积网络完成了MR图到CT图的合成,首先切patch,随后通过像素级别的损失函数和对抗训练提供的信息优化生成的MR图像,值得注意的是训练需要MR-CT图像对。如果想摆脱图像对的限制,Wolterink等人使用的CycleGAN完成这一转换,像素级损失函数也换成了perceptual loss。
MR from CT:
与Wolterink等人的工作相近,Chartsias等人也基于CycleGAN完成了CT到MR图像的生成,同时辅助的分割mask考科一提升16%的分割性能。这种image-to-image translation中需要注意的一个关键问题是,在图像变换这一过程中,关注的肿瘤/病灶区域的信息有多少被保留下来,至今没有一个很好的衡量方式。
Retinal Image Synthesis
Costa等人则使用Pix2Pix框架从血管的二值图进行了视网膜图像合成,后续还是用AAE(Adversarial autoencoder)将血管树压缩为多元正态分布,在不断迭代优化这一分布完成高分辨率视网膜图像的合成;类似的Guibas等人也采用一个两阶段的框架,第一步利用GAN将随机噪声生成vessel tree图像,第二步利用Pix2Pix将vessel tree生成视网膜图像;随后盖文作者还比较了生成的视网膜图像与真实图像均送入UNet进行血管分割的效果。
Zhao等人也用Pix2Pix模仿生成丝状结构(视盘图像以及神经元的二值分割。为了保证风格迁移的效果,在判别器的训练中使用了VGG,而且不是通过随机失活引入噪声,而是选择在编解码网络的bottleneck部分引入噪声。
PET from CT:
临床上常用PET图像结合CT图像诊断肿瘤分期、检测药物疗效等,但PET设备昂贵且有一定放射性,对病人有一定风险。所以根据CT数据合成PET图像也是很有必要的。
Ben Cohen等人率先使用cGAN完成了CT合成PET图像,但用于肿瘤诊断的效果不是很好;如果使用全卷积神经网络生成的图像又很模糊,因此将cGAN和FCN结合就可以获得清晰的图像用于肿瘤检测;Bi等人则加入了额外的辅助信息:binary labelmap来提升PET图像的分辨率。
PET from MRI:
测量人脑PET图像中髓鞘的含量对监测疾病进展、了解生理病理和评价多发性硬化(MS)的治疗效果具有重要意义)。 但MS的PET成像需要使用放射性追踪剂,是昂贵和侵入性的。Wei等人于2018年率先使用两个级联的cGAN通过MRI生成PET图像,其中生成器使用3D-UNet,判别器使用了3D CNN;作者还表明仅使用一个cGANs生成的结果较为模糊,通过将图像的合成划分为子问题可以显著提升合成效果。
Ultrasound:
Hu等人根据3D体素信息使用cGAN生成胎儿的超声图像,该文的作者发现有必要将像素信息转换为特征映射,辅助生成器的训练。Tom等人则使用了多阶段GANs进行血管内US(IVUS)图像生成。 第一个生成器以实际物理的组织图为条件,产生speckle图像。 第二个生成器将speckle映射为64×64像素大小低分辨率的US图像。 第三个生成器将这些低分辨率图像转换为高分辨率样本,分辨率为256×256像素。
Stain Normalization
cGAN也常用来解决组织病理图像染色不一致的问题,进行染色归一化。Cho等人提出,训练好的肿瘤分类器在不同染色的图像中泛化性能很差,而且目前的染色归一化方法也不能很好的保留图像的特征信息。为此Cho等人提出了一种特征保留式cGAN,首先将HE病理图像转化为统一的灰度模式,在将灰度图转为统一的RGB形式,通过增加的feature preserving loss辅助哦判别器的训练,从而跟高的进行染色病理图像的风格迁移。
Bayramoglu等人则用Pix2Pix对未染色的高光谱显微镜贴片进行虚拟H&E染色。
以及Bentaieb等人尝试使用AC-GAN同时训练一个cGAN用于HE染色的风格迁移,训练另一个网络解决实际任务(如分割、分类),两者联合训练使得生成的图像更适合后续的实际任务。
前文提及的都需要成对图像参与,二者的配准就是个很大的问题,Shaban等人使用CycleGAN避免了图像对的使用。
Microscopy
Han等人提出了一个类似于Pix2Pix的框架完成显微镜图像中的相位对比度(PC)和差分干涉对比度(DIC)转换拿。 训练一个基于U-net的生成器,负责根据源域和和相应的单元掩码合成某一模态的图像。 有趣的是鉴别网络,使用两个鉴别器来区分(真实源、真实目标)vs(真实源、合成目标)和(II)对(细胞掩模真实源)对(细胞掩模、合成目标)。
Blood Vessel
机器学习可用来检测冠状动脉CT血管造影(CCTA)的动脉粥样硬化斑块或血管狭窄但缺乏足够的训练数据。 为了解决缺乏标记数据的问题,Wolterink等人将噪声和属性向量输入WGAN来合成有效的三维血管图像。首先本文会生成一维参数化的血管描述以方便合成合成高分辨率的3D图像。此外磁共振血管造影(MRA)已经成为可视化血管结构的重要工具。Olut等人提出了steerable-GAN从T1和T2加权MR扫描合成MRA图像,可以减轻额外MR扫描的需要。 steerable-GAN结合了一个像ResNet一样的生成器和一个patch-GAN作为鉴别器。 此外,他们还提出了可引导的过滤器损失,以忠实的重建血管结构。
Table 2总结了无监督GAN的模型汇总,Table3,4总结的是监督GAN的相关信息,如基础框架、使用的图像、生成图像的分辨率、基于的数据集、是否提供源码等信息。
![[Style Transfer]——GANs for Medical Image Analysis_第3张图片](http://img.e-com-net.com/image/info8/33c733e39229498f89c8228f451608f1.jpg)
![[Style Transfer]——GANs for Medical Image Analysis_第4张图片](http://img.e-com-net.com/image/info8/e98313d57c7a46d098cb36f829238dfd.jpg)
![[Style Transfer]——GANs for Medical Image Analysis_第5张图片](http://img.e-com-net.com/image/info8/79f841856d4b4ebf9a902c3fc4d6f3ca.jpg)
可以看到,不管是监督学习还是无监督学习都提出了一系列方法,但实际的有效性还有待进一步验证。此外,还需要仔细辨别是否出现了mode collapse问题,以及制定一个统一的平判别准,来评价生成图像的真实性。
Part B Segmentation
对医学图像中的组织、器官进行切割是进行病灶检测、诊断、分类等一系列任务的基础,但人工分割费时费力,因此借助深度学习自动完成分割在MIA中大有用途。
Litjens等人基于传统的pixel_loss进行优化但不足以学习足够的结构化特征,因此后续陆续有基于CRF,SSM等进行优化。下面根据具体分割的部位进行分类总结。
Part A Brain
对于脑部图像的分割依旧可分为监督学习和无监督学习两类。Moeskops等人的研究发现借助GAN的对抗学习策略不仅可以提升语义分割网络的性能,还能提升非语义分割部分的性能。Xue等人提出Segan用于脑肿瘤的分割,其中以UNet作为生成网络,还发现使用多级对抗损失可以更好的学习像素之间的依赖关系。上述监督学习算法的局限在于对于一些从未见过的图像,模型的性能往往不是那么尽人意。
Kanistsas等人则以无监督域迁移的方式进行脑部损伤部位的分割,因此使用了一个域识别网络(domain discriminator network)来辨别来自不同域的输入图像,这样根据来自不同域的图像外形可以进行多模态的分割;还有Zhao等人提出的Deep-subGAN网络首先借助GAN完成MRI到CT图像的生成,再利用两个模态的图像联合作为分割网络的输入,因此涉及到的损失有:对抗损失,体素损失,3类感知损失(由VGG网络提取的不同层次特征计算得到)
Part B Chest
对于X光胸片进行分割的主要难点在于:图像质量、局部伪影、肺部和心脏相互重叠。而早期的分割方法不能很好地在全局特征和局部特征之间保持一致性,因此Dai等人提出了SCAN框架,在生成器网络中使用了一个预训练网络以及像素级别的损失函数进行优化,最终取得了接近人类的分割水平。
Part C Eye
在视网膜血管分割方面,许多分割算法已经取得了接近甚至超过专家分割的水平,但在毛细血管处的模糊以及假阳分割仍然是两大难题,因此Son、Lahiri等人分别借助GAN来提升2D彩图的视盘分割效果。
Part D Abdomen
Yang等人依旧用UNet作为生成网络进行3D肝脏部位的分割,Kim等人采用CycleGAN进行肝部肿瘤的分割时也借助改进的UNet(polyphase UNet)作为生成器减少对微小肿瘤分割错误的发生。
Part E Microscopic image
对于显微图像的分割,由于形状、大小、纹理的差异性是一大难点。为此有改进损失函数的、提出带权重的损失函数进行训练;还有设计特出的conv block结构提升判别器的判别能力;Zhang等人提出的DAN更是将DCAN和VGG16结合在一起,分别使用监督和无监督的策略训练从而提升对未知图像的分割效果。
Part F Cardiology
对于心脏图像,难点在于:对比度低、大量噪声以及心室的不停运动,都使得心室分割效果不尽人意。Dong等人提出VoxelAtlasGAN用于低对比度的左心室分割(LV),其中生成网络以V-Net为基础;Chartsias等人则是基于图像特征进行了一定重建,利用non-RoI部分信息使得结果分割结果更加逼真。而在半监督/无监督类别依旧是基于CycleGAN和LSGAN。
Part G Spine
至于脊柱分割,机器学习的方法主要因为难以正确地学习椎骨的解剖结构以进行分割和定位而受到影响。Sekuboyina等人提出了一种蝶形的GAN来分割两个视角下的脊柱。
Table 5-11分别按照上述类别对相关工作进行了总结,包括使用的模型、
损失函数等。训练样本从10-1000不等。但也能看出不同方法使用的评价指标并不一致,因此难以相互比较。
![[Style Transfer]——GANs for Medical Image Analysis_第6张图片](http://img.e-com-net.com/image/info8/6267a6fc49194d20bab6183afd76fa5a.jpg)
![[Style Transfer]——GANs for Medical Image Analysis_第7张图片](http://img.e-com-net.com/image/info8/5bf866f9bcd843acbfa0f36f20430d66.jpg)
![[Style Transfer]——GANs for Medical Image Analysis_第8张图片](http://img.e-com-net.com/image/info8/bab5eeb25e8f41209cec6796c3e085c7.jpg)
从GAN和普通语义分割模型取得的分割性能对比来看,有一点可以明确,GAN在保留全局和局部特征上接近语义分割模型,尤其在显微图像上GAN的性能更是高出一大截。
Part C Reconstruction
如何在不丢失细节的前提下快速重建MR图像是医学图像中一个亟待解决的问题,传统算法通常直接学习映射到k空间的映射关系,而GAN强大的生成能力可以快速生成逼真的图像,因此是MR重建的一种备选方案,目前主要研究焦点采用一些经典的网络框架,并与适当的损失函数相结合。
DAGAN
早期的MR重建基于DAGAN框架,Yang等人的研究中还加入了perceptual loss,最终的损失函数长这样:
![]()
Seizer等人随后又在DAGAN的基础上增加了一个精炼网络(refinement network)分别聚焦于pixel loss和perceptual loss。
3D超分辨率重建
Sanchez等人将SRGAN用于3D医学图像的超分重建,损失函数结合了pixel loss和Gradient-Based Loss,来抑制重建图像的模糊效应;随后Li提出了3DSRGAN分别使用两种损失函数来控制插值和避免过拟合,其他的还有Chen等人提出的多级密集连接GAN(mDCSRN),结合了WGAN和DenseNet。
OtherMethods
其他一些基于GAN的重建算法多半通过改进损失函数来实现,其中额外的损失函数可用来更好地保持细节的纹理特征。
Table12,13,14分别罗列了基于DAGAN,基于3D超分辨率和其他算法用于图像重建的研究情况,鉴于GAN强大的生成能力,与其他重建算法相比,GAN在图像重建方面更加快速高效,但问题在于缺乏一个通用的评价指标来评判对于一些特征信息的保留情况。
![[Style Transfer]——GANs for Medical Image Analysis_第9张图片](http://img.e-com-net.com/image/info8/eb3f1c2421274056bd5152850ab6e70e.jpg)
![[Style Transfer]——GANs for Medical Image Analysis_第10张图片](http://img.e-com-net.com/image/info8/c254f680aa914b9ca66be3441c2c4cd5.jpg)
Part D Detection
如果通过监督学习来完成医学图像中的异常检测,需要大量的训练数据参与,从而GAN可以通过生成图像来扩充训练数据集,也可以通过学习数据分布发现分布不一致的异常数据。比如Udrea等人提出用UNet做GAN的生成网络进行癌症检测,Mitra等人用cGAN进行皮肤损伤检测。
第二种途径则是GAN以无监督的方式学习正常数据的分布情况,从而检测出异常数据。比如Ano等人就提出了AnoGAN来检测眼底视网膜病变。Chen和Konukoglu等人则是用于脑部MR图像的异常检测,Baumgartner等人提出了VA-GAN进行阿兹海默症的检测,在低对比度的图像中也照样可行。
![[Style Transfer]——GANs for Medical Image Analysis_第11张图片](http://img.e-com-net.com/image/info8/98689be328c94961b0f466eadcfb44c1.jpg)
具体的研究总结在Table15中,可以看到用于检测的GAN网络比前面用于合成、重建的网络在结构上更为复杂,主要是用于检测任务的判别网络更为重要。
Part E De-noising
图像去噪对医学图像处理也十分重要,因为很多医学图像采集过程中图像的对比度清晰程度需要与所售的辐射剂量相权衡,但减少辐射强度又会导致图像对比度不够,信噪比不够。因此可以借助GAN完成图像的对比度增强还不会引起图像模糊。
比如Wolterink等人利用GAN仅需要通过学习少量成对训练样本的纹理信息就可以有效的减少图像模糊;Wang等人使用cGAN来减少CT图像中的伪影;Yi等人则是提出了SAGANA(Sharpness Aware Generative Adversarial Network)。
![[Style Transfer]——GANs for Medical Image Analysis_第12张图片](http://img.e-com-net.com/image/info8/337375662c4147fcb6d013b8f0a0a51c.jpg)
以上的对比信息请参见Table 16.常规图像去噪的主要评价指标有PSNR,MSE,SSIM,SD等,但对于细节部分的评判还需要有一个计算更加高效的评价指标。
Part F Registration
常规的图像配准方法需要依赖于各种参数的设置和优化方案,而神经网络仅需要经过一次前向传播过程,因此GAN在医学图像配准方便也大有可为。Table17罗列了一些代表研究。
![[Style Transfer]——GANs for Medical Image Analysis_第13张图片](http://img.e-com-net.com/image/info8/88d398a08cf74a87bd315046b795235a.jpg)
Part G Classification
众所周知,CNN是性能绝佳的分类器,但它的训练离不开海量的训练数据,而医学图像本身的稀缺限制了CNN对医学图像的分类效果,因此GAN可以从数据扩充和学习域无关的图像特征。Zhang等人提出了SCGAN用来区分超声图像中的有用信息和无用信息部分,这样就可以有目的性的进行相关和无关数据的扩充;Ren等人则利用GAN对前列腺病理图像的两个Gleason等级进行分类,分别对每一类的patch进行特征提取和学习。
以上工作罗列在Table18中。
![[Style Transfer]——GANs for Medical Image Analysis_第14张图片](http://img.e-com-net.com/image/info8/2d8fe629f1b44037b930862f447d2092.jpg)
![[Style Transfer]——GANs for Medical Image Analysis_第15张图片](http://img.e-com-net.com/image/info8/ac7b44b3025244e49ba9c30cd625dd55.jpg)
![[Style Transfer]——GANs for Medical Image Analysis_第16张图片](http://img.e-com-net.com/image/info8/4deb584075cc4f2f89ad2c14f6ca0ad0.jpg)
Section V Discussion
从医学图像分析的相关论文的发布情况就可以看出,GAN广受关注。
Part A Advantages
GAN最显著的一点优势就是通过学习样本的数据分布生成逼真的合成图像从而用于提升网络的性能。
因为大多数情况下带有标注信息的医学图像是十分稀缺且价值昂贵的,这就大大限制了监督学习算法的性能;此外医学图像通常是高度类别不均衡的,通过GAN有目的性的生成训练样本可以使得训练以半监督甚至无监督的方式进行;还可以利用GAN进行多模态的数据转换,从而有效减少病人的拍片成本、所受的辐射剂量等;以及通过学习正常数据的分布情况来进行异常检测。
Rich Feature Extraction:
GAN强大的一点在于,可以学习pixel-loss学习不到的丰富的语义信息,因此非常适于分割、图像配准好图像去噪。
Part B Drawbacks
本文总结了GAN三方面的局限:
生成样本的可信程度:
这是应用于临床检验最重要的一个方面,即生成的图像是否可信,尤其是现阶段对于神经网络的内部机制仍然未完全理解的情况下。
训练的不稳定性:
GAN的训练过程也不容易收敛,很容易就导致mode collapse或者modehopping,一般通过调整网络结构或者损失函数来改善这一问题。但还未有统一的评价指标来测评上述方法的有效性。
Evaluation:
无论是GAN用于图像重建、分类、分割对于图像的生成情况、去噪效果都还未有统一的评价指标,导致不同方法难以综合进行对比。
可解释性:虽然GAN在诸多MIA任务中取得了非常突出的成果,但和CNN有一样的问题,就是可解释性差,这也是当下一个很热门的研究方向。
# Summary
我们认为,在实际医学图像分析中,GAS需要先解决上述局限,然后才被认为是一种值得信赖的技术。为此,我们可以将GANs视为一步基石, 例如,在合成CT数据的情况下借助GAN和实际物理模型合成更加逼真的HU值。 训练的不稳定也需要解决,这意味着要进行严格的实验,以了解GANs在MIA下的收敛性。总之,GAN打开了一方广阔的研究天地,五如何正确的理解和回答前述问题是GAN在真正的临床场景中成功应用的关键。