OCR文字识别经典论文详解
OCR文字识别综述合集:
1️⃣OCR系列第一章:OCR文字识别技术总结(一)
2️⃣OCR系列第二章:OCR文字识别技术总结(二)
3️⃣OCR系列第三章:OCR文字识别技术总结(三)
4️⃣OCR系列第四章:OCR文字识别技术总结(四)
5️⃣OCR系列第五章:OCR文字识别技术总结(五)
OCR文字识别领域论文详解系列:
1️⃣CRNN:CRNN文字识别
2️⃣ASTER:ASTER文本识别详解
导读:本篇将介绍文字识别经典论文,内容包括文字检测、文字识别、端到端识别等方法,具体将分别对论文算法简介、思路、代码等几个部分展开介绍。目前各部分只举例经典论文,算法没有全部写完,后续会将在此部分基础上更新更多论文综述及代码实战部分。
➡️OCR经典论文介绍
一、文本识别
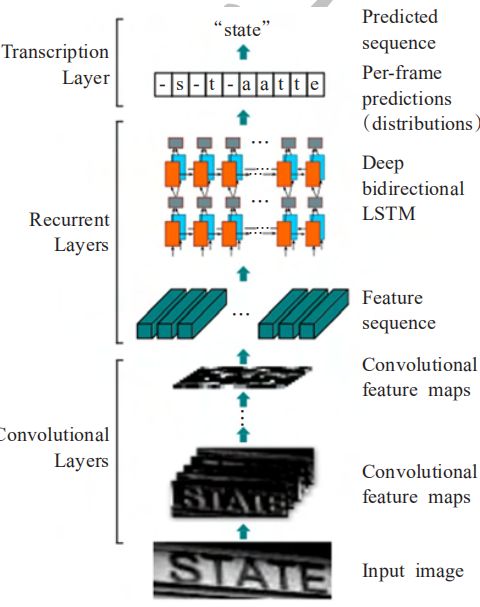
1.CRNN (重要)
最常用的识别网络,任意长度输入,模型小,参数少
论文链接 : https://arxiv.org/pdf/1507.05717.pdf
期刊日期 TPAMI 2017
论文名称:
《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition》
CRNN详解及实战参考我的这两篇文章:
CRNN文字识别_GoAI的博客-CSDN博客_crnn
基于CRNN的文本字符交易验证码识别--Paddle实战
论文思路和方法:
1)问题范围:单词识别;
2)CNN层:使用标准CNN提取图像特征,利用Map-to-Sequence表示成特征向量;
3)RNN层:使用双向LSTM识别特征向量,得到每列特征的概率分布;
4)Transcription层:利用CTC和前向后向算法求解最优的label序列;
亮点和创新点:
1)端到端可训练(把CNN和RNN联合训练);
2)任意长度的输入(图像宽度任意,单词长度任意);
3)训练集无需有字符的标定;
4)带字典和不带字典的库(样本)都可以使用;
5)性能好,而且模型小(参数少)
2.Attention_OCR
该方法处理普通文本,不针对弯曲文本,后续方法都针对弯曲文本。
论文链接 :https://arxiv.org/abs/1704.03549
代码:https://github.com/tensorflow/models
期刊日期 IEEE,2017
论文名称
《Attention-based Extraction of Structured Information from Street View Imagery》
描述
提出了一种神经网络模型-基于卷积神经网络,回归神经网络和一种新颖的注意机制-在具有挑战性的法国街道名称标志(FSNS)数据集上达到84.2%的准确率,明显优于先前的技术水平(Smith')16),达到72.46%。此外,我们的新方法比以前的方法更简单,更通用。为了证明我们模型的一般性,我们证明它在从Google街景视图中衍生的更具挑战性的数据集上也表现良好,其目标是从商店前端提取商业名称。最后,我们研究了使用不同深度的CNN特征提取器产生的速度/准确度权衡。令人惊讶的是,我们发现更深层次并不总是更好(在准确性和速度方面)。我们生成的模型简单,准确,快速,可以在各种具有挑战性的真实文本提取问题上大规模使用。
3.ASTER (重要)
引入注意力机制,整合矫正和识别,改善大规则文字识别
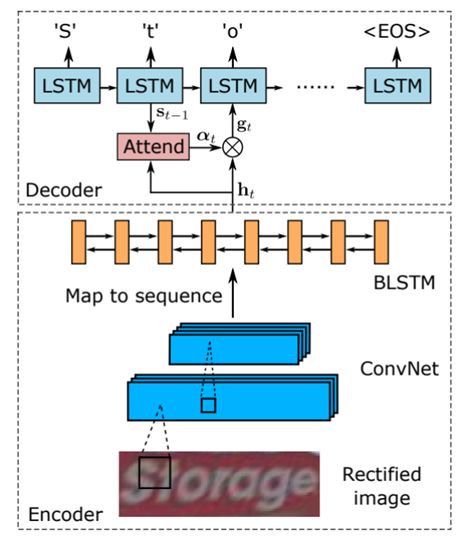 ASTER结构图
ASTER结构图
论文链接 :http://122.205.5.5:8071/UpLoadFiles/Papers/ASTER_PAMI18.pdf
代码: https://github.com/bgshih/aster
期刊日期 TPAMI 2018
论文名称
《An Attentional scene text recognizer with flexible rectification》
描述
场景文本识别的一个具有挑战性的方面是处理扭曲或不规则布局的文本。尤其是透视文字和曲线文字在自然场景中比较常见,难以识别。
在这项工作中,我们引入了 ASTER,这是一种端到端的神经网络模型,包括一个整流网络和一个识别网络。修正网络自适应地将输入图像转换为新图像,修正其中的文本。它由灵活的 Thin-Plate Spline 转换提供支持,该转换可处理各种文本不规则性,并在没有人工注释的情况下进行训练。
识别网络是一种注意力序列到序列模型,它直接从校正后的图像中预测字符序列。整个模型是端到端的训练,只需要图像和它们的真实文本。
通过大量实验,我们验证了整改的有效性,并展示了 ASTER 最先进的识别性能。此外,我们证明 ASTER 是端到端识别系统中的一个强大组件,因为它具有增强检测器的能力。
4.MORAN
加入了注意力机制的文本识别
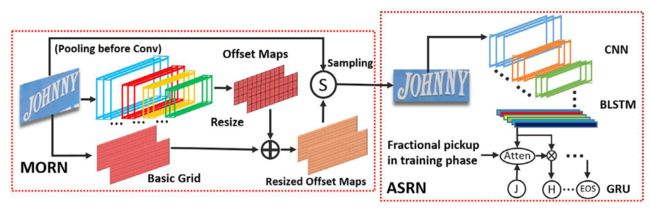
期刊日期PR 2019
论文名称
《A Multi-Object Rectified Attention Network for Scene Text Recognition》
描述
MORAN分为两部分一个是对形变input image的校正网络MORN(multi-object rectification network)和对矫正后照片的识别网络ASRN(attention-based sequence network)。
除了整体架构,作者还强调了两种提升训练效果的方法,因为这个端到端的网络比较难训练。一个是fractional pickup method用于提升ASRN的训练效果,一个是curriculum learning用于训练MORAN这个端到端的网络。
论文链接:https://arxiv.org/abs/1901.03003
代码:https://github.com/Canjie-Luo/MORAN_v2
MORAN算法详解:
OCR–MORAN
5.RARE
RARE实现了对不规则文本的end-to-end的识别,算法包括两部分:
- 基于STN[2]的不规则文本区域的矫正:与STN不同的是,RARE在Localisation部分预测的并不是仿射变换矩阵,而是K个TPS(Thin Plate Spines)[3][4]的基准点,其中TPS基于样条(spines)的数据插值和平滑技术。
- 基于SRN的文字识别:SRN(Sequence Recognition Network)是基于Attention [5]的序列模型,包括有CNN和LSTM构成的编码(Encoder)模块和基于Attention和GRU的解码(Decoder)模块构成。

算法详解:
OCR之RARE
文本识别方法总结 :

二、文本检测
1.CTPN
实现端到端检测,改进RPN

期刊日期 ECCV 2016
论文名称
《Detecting Text in Natural Image withConnectionist Text Proposal Network》
描述
我们提出了一种新颖的 Connectionist Text Proposal Network (CTPN),可以准确定位自然图像中的文本行。CTPN 直接在卷积特征图中检测一系列精细文本提议中的文本行。我们开发了一种垂直锚点机制,可以联合预测每个固定宽度提议的位置和文本/非文本分数,从而显着提高定位精度。顺序提议由循环神经网络自然连接,循环神经网络无缝地合并到卷积网络中,从而形成端到端的可训练模型。这使得 CTPN 能够探索图像的丰富上下文信息,使其能够强大地检测极其模糊的文本。CTPN 在多尺度和多语言文本上可靠地工作,无需进一步的后处理,与以前需要多步后处理的自下而上的方法不同。它在 ICDAR 2013 和 2015 基准上实现了 0.88 和 0.61 F-measure,大大超过了最近的结果 [8, 35]。通过使用非常深的 VGG16 模型 [27],CTPN 的计算效率为 0:14s/image。
论文链接 https://arxiv.org/abs/1609.03605
在线演示:http://textdet.com/
算法详解:
OCR之CTPN
2.EAST & AdvancedEAST
全卷积网络+非极大值抑制,缩短检测时间
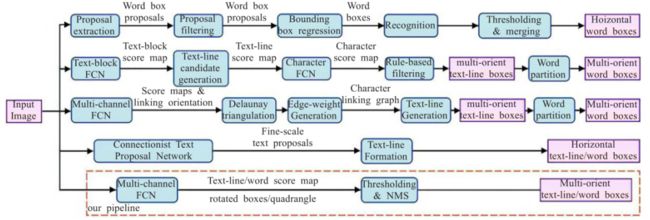
期刊日期 CVPR 2017
论文名称
《EAST: An Efficient and Accurate Scene Text Detector 》
描述
以前的场景文本检测方法已经在各种基准测试中取得了有希望的性能。
然而,即使配备了深度神经网络模型,它们在处理具有挑战性的场景时通常也表现不佳,因为整体性能取决于管道中多个阶段和组件的相互作用。在这项工作中,我们提出了一个简单而强大的管道,可以在自然场景中进行快速准确的文本检测。
管道直接预测完整图像中任意方向和四边形形状的单词或文本行,使用单个神经网络消除不必要的中间步骤(例如,候选聚合和单词分区)。
我们管道的简单性允许集中精力设计损失函数和神经网络架构。在包括 ICDAR 2015、COCO-Text 和 MSRA-TD500 在内的标准数据集上的实验表明,所提出的算法在准确性和效率方面都明显优于最先进的方法。
在 ICDAR 2015 数据集上,所提出的算法在 720p 分辨率下以 13.2fps 获得了 0.7820 的 F-score。
论文链接 https://arxiv.org/pdf/1704.03155.pdf
算法详解:
场景文字检测之EAST
3.PSENet
多个尺度预测结果,准确检测区分临近文本行
期刊日期 CVPR 2019
论文名称
《PSENet: Shape Robust Text Detection with Progressive Scale Expansion Network 》
描述
文章认为其提出的方法能避免现有bounding box回归的方法产生的对弯曲文字的检测不准确的缺点(如下图b所示),也能避免现有的通过分割方法产生的对于文字紧靠的情况分割效果不好的缺点(如下图c所示)。
该文章的网络框架是从FPN中受到启发采用了U形的网络框架,先通过将网络提取出的特征进行融合然后利用分割的方式将提取出的特征进行像素的分类,最后利用像素的分类结果通过一些后处理得到文本检测结果。

论文链接 :https://arxiv.org/pdf/1903.12473.pdf
代码:https://github.com/whai362/PSENet
4.PANNET
号称PSENet的二代
期刊日期 ICCV 2019
论文名称
《Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network》
描述
有低计算成本的分割部分和可学习的后处理。分割分割部分由特征金字塔增强模块(FPEM)和特征融合模块(FFM)组成。FPEM是可级联的U形模块,可以引入多级信息来指导更好的分割。
FFM可以将不同深度的FPEM提供的特征收集到最终特征中进行分割。可学习的后处理是通过像素聚合(PA)实施的,该算法可以通过预测的相似度矢量精确地聚合文本像素。
论文链接
https://arxiv.org/pdf/1908.05900.pdf
代码
https://github.com/whai362/pan_pp.pytorch
5.DBNet
将二值化融入网络,速度极快
期刊日期 AAAI 2020
论文名称
《Real-time Scene Text Detection with Differentiable Binarization》
描述
由于分割网络的结果可以准确描述诸如扭曲文本的场景,因而基于分割的自然场景文本检测方法变得流行起来。基于分割的方法其中关键的步骤是其后处理部分,这步中将分割的结果转换为文本框或是文本区域。
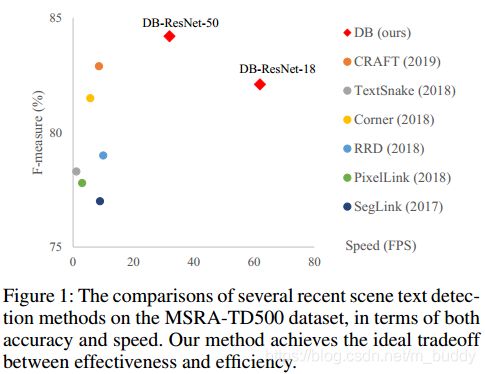
这篇文章的文本检测方法也是基于分割的,但是通过提出Differenttiable Binarization module(DB module)来简化分割后处理步骤(加了一个边的预测),并且可以设定自适应阈值来提升网络性能。文章的方法在现有5个数据上在检测精度与速度上均表现为state-of-art。
在换用轻量级的backbone(ResNet-18)之后可以将检测帧率提升到62FPS,其与其它一些文本检测算法的性能与速率关系见图1所示。
论文链接: https://arxiv.org/pdf/1911.08947.pdf
代码:https://github.com/MhLiao/DB
算法详解:
DBNet论文详解
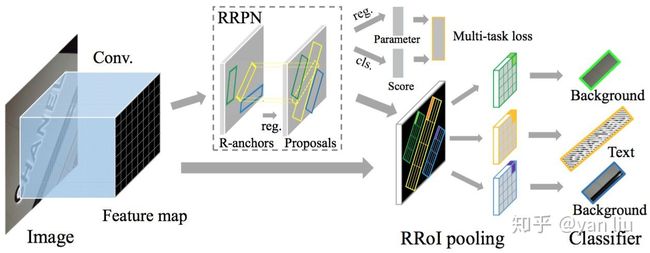
6.RRPN
论文:Arbitrary-Oriented Scene Text Detection via Rotation Proposals
在场景文字检测中一个最常见的问题便是倾斜文本的检测,现在基于候选区域的场景文字检测方法,例如CTPN[2],DeepText[3]等,其检测框均是与坐标轴平行的矩形区域,其根本原因在于数据的标签采用了 。另外一种方法是基于语义分割,例如HMCP[4],EAST[5]等,但是基于分割算法的场景文字检测效率较低且并不擅长检测长序列文本。
文字检测算法总结
注:上述方法与图表部分不匹配,此部分后续将补充!

三、端到端文字识别
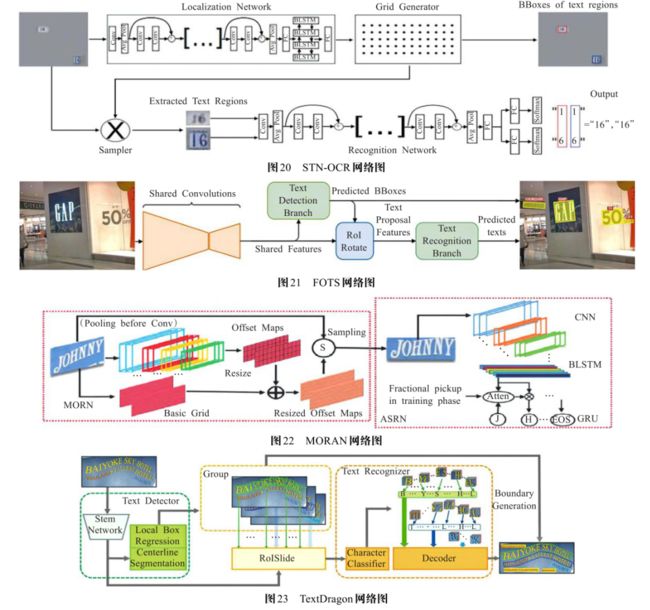
1.FOTS
识别检测端到端的网络,解决了角度文本端到端识别的问题
期刊日期 CVPR 2018
论文名称
《FOTS: Fast Oriented Text Spotting with a Unified Network》
描述
偶然场景文本识别被认为是文档分析社区中最困难和最有价值的挑战之一。大多数现有方法将文本检测和识别视为单独的任务。
在这项工作中,我们提出了一个统一的端到端可训练快速定向文本识别 (FOTS) 网络,用于同时检测和识别,在两个互补任务之间共享计算和视觉信息。特别地,引入了 RoIRotate 以在检测和识别之间共享卷积特征。
受益于卷积共享策略,我们的 FOTS 与基线文本检测网络相比计算开销很小,并且联合训练方法学习了更多的通用特征,使我们的方法比这些两阶段方法表现更好。
论文链接 https://arxiv.org/pdf/1801.01671.pdf
识别检测端到端的网络(工程应用场景较少)
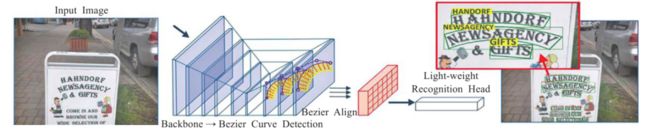
2.ABCnet
ABCNet网络是一个端到端的场景文本检测识别网络。该网络首次通过参数化的贝塞尔曲线自适应拟合任意形状文本,其计算成本可忽略;其中的BezierAlign层可以准确地提取卷积特征使得识别精度显著提高。该网络由贝塞尔曲线检测分支、贝塞尔曲线Align和识别分支两个部分组成。但是该网络用合成数据进行训练在实际较复杂场中的识别效果不好。
端到端文字识别方法总结
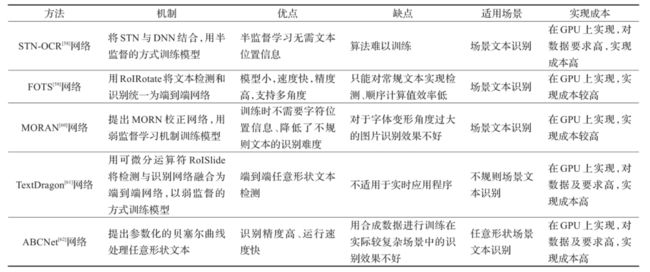
通用检测算法总结

优秀文章推荐:
文字识别方法整理(2015~2019)
一文读懂CRNN+CTC文字识别
本文参考:
场景文字识别技术研究综述
此篇未完待续,后续继续更新!