AI识别教程 yolov5 (穿越火线,csgo等FPS游戏识别)
目录
一、前言
二、视频识别
三、版本和配置环境
四、准备工作
1.yolov5 模板下载
2.安装所需库
(1)安装pytorch(建议安装gpu版本cpu版本太慢)
3.运行检测
五、数据集
1.制作标签
2.转格式(json转txt)
六、配置文件
1.mydata.yaml
2.mydata_1.yaml
七、训练模型
八、测试视频
九、总结
一、前言
1.代码在我的资源里下载。
2.本文不会讲解关于yolov5的理论问题,只是教大家实操,这篇文章可以帮助大家学会yolov5的训练与识别,本文使用穿越火线(cf)为例。
二、视频识别
我们先看视频效果。
yolov5 穿越火线角色识别
三、版本和配置环境
# pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
# Logging -------------------------------------
tensorboard>=2.4.1
# wandb
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=4.1 # CoreML export
# onnx>=1.9.0 # ONNX export
# onnx-simplifier>=0.3.6 # ONNX simplifier
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TFLite export
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev # OpenVINO export
# Extras --------------------------------------
# albumentations>=1.0.3
# Cython # for pycocotools https://github.com/cocodataset/cocoapi/issues/172
# pycocotools>=2.0 # COCO mAP
# roboflow
thop # FLOPs computation
四、准备工作
1.yolov5 模板下载
第一步:将整个代码从github上下载下来,
网址:GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
也可以直接到GitHub上搜yolov5

然后点code(绿色) 最后点下面的Download ZIP (最好不要下到C盘,如果C盘够用也没关系)
2.安装所需库
主要是安装版本与配置声明中所需在库。
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
tensorboard>=2.4.1
seaborn>=0.11.0
pandas
pycocotools>=2.0 # COCO mAP
albumentations>=1.0.2
(1)安装pytorch(建议安装gpu版本cpu版本太慢)
这些库中可能就pytorch比较难安装,其他库用pip install 基本能实现。
可直接在Anaconda Prompt里输入:
pip install torch==1.7.0+cu101 torchvision==0.8.1+cu101 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html很大几率会不成功
如果不成功,可以参考一下下面的网址。安装Pytorch-gpu版本(第一次安装 或 已经安装Pytorch-cpu版本后)_js_dxx的博客-CSDN博客_pytorchgpu版本
3.运行检测
下载完yolov5后,运行detect,可以帮助我们检查上面的环境是不是安装成功。
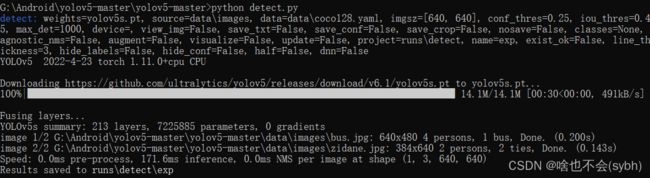
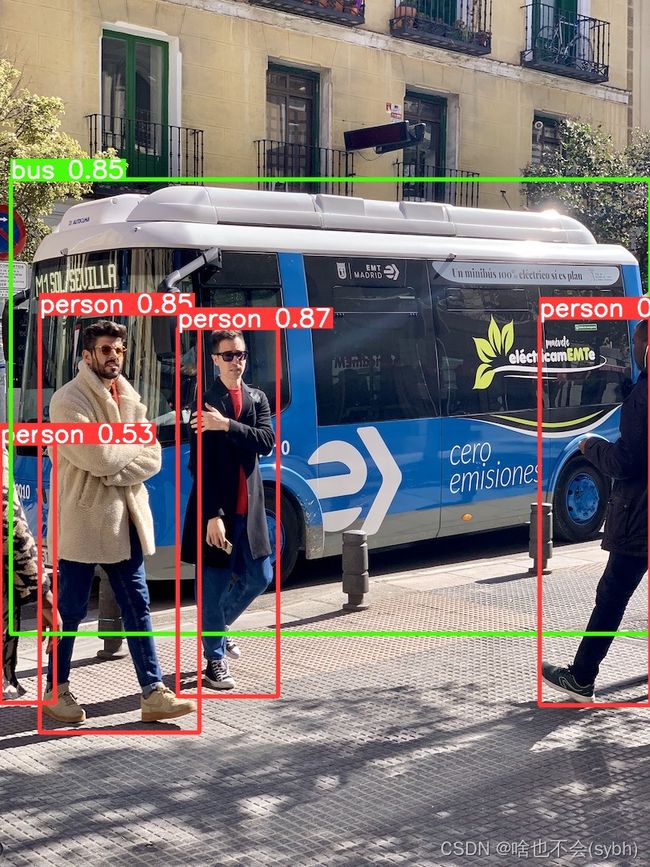
如果运行不报错,我们会在runs//detect//exp 文件夹下看到两张已经预测出的照片。

如果报错,问题也不大,看就是安装的环境版本比较低或者没安装,我们稍微调试一下就OK了。
五、数据集
我们先要创建几个文件夹用来存放数据和模型。
在yolov5-master如下图所示文件夹

1.制作标签
这里我是以穿越火线为例,提供100个已经标记好的数据(放在文末)。你也可以自己标记,一百张效果不是很好,可以多标记几张。
(1)安装labelme
在Anaconda Prompt里pip install labelme
(2)使用labelme
在Anaconda Prompt里输入labelme,会弹出一个窗口。

然后打开图片所在的文件夹
点击rectangle,标记想要识别的东西。
我们这里用了两个标签(保卫者:'Global Risk' 、潜伏者: 'Black List')
标记完后保存到一个新的文件夹下,保存的文件格式是.json
2.转格式(json转txt)
要修改代码中标签名称,存放json文件的绝对路径和保存txt文件的绝对路径。
我们将生成的txt放在my_dates//labels//train中
将原来的图片放在my_dates//images//train中
import json
import os
name2id = {'Global Risk':0,'Black List':1} #标签名称
def convert(img_size, box):
dw = 1. / (img_size[0])
dh = 1. / (img_size[1])
x = (box[0] + box[2]) / 2.0 - 1
y = (box[1] + box[3]) / 2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def decode_json(json_floder_path, json_name):
txt_name = 'C:\\img \\' + json_name[0:-5] + '.txt'
#存放txt的绝对路径
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='gb2312',errors='ignore'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label']
if (i['shape_type'] == 'rectangle'):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
json_floder_path = 'G:\\img\\'
#存放json的文件夹的绝对路径
json_names = os.listdir(json_floder_path)
for json_name in json_names:
decode_json(json_floder_path, json_name)六、配置文件
1.mydata.yaml
copy一下coco128.yaml文件到my_dates下并改名为mydata

然后修改里面的参数:
(1)先将path注释掉(别忘记注释) ,然后将train和val改为存放训练集图片的位置
train: my_dates/images/train val: my_dates/images/train
(2)然后将nc 改为标签个数(我们这里是2),names里面改为我们的标签名。
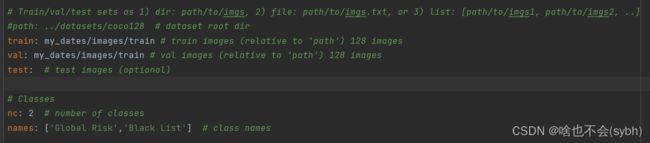
别忘了注释path
2.mydata_1.yaml
copy一下yolov5s.yaml文件到my_dates下并改名为mydata_1。(yolov5s效果最差但速度最快我们可以根据自己的情况选择模型)
然后修改里面的参数:
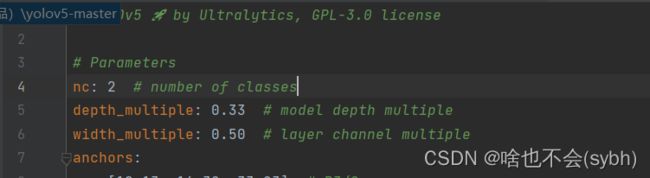
这里只需要将第四行的nc改为2(标签个数) 。
七、训练模型
我们要对train.py文件进行修改。
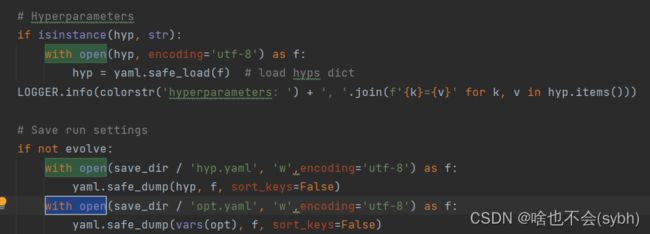
1.为了防止编码出错,with open后面要加上encoding='utf-8',要改好几处,可以用ctrl+F查找with open。
2.我们还要改多处default的值,在代码的480行左右。(改的全是default的值)。
一共要修改六处,最后一处稍微靠下一点。
第四处如果电脑配置好的话可以不用修改。


最后运行:
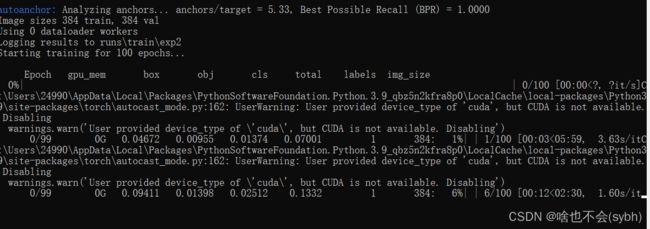
时间有点长(一小时左右)!!!!
如果报错根据实际情况修改一下就ok
结果会放在下面路径下

八、测试视频
我们只需修改detect.py文件夹下的权重路径和测试路径。(210行左右)

只需要将需要预测的视频或图片放在下面文件夹下,
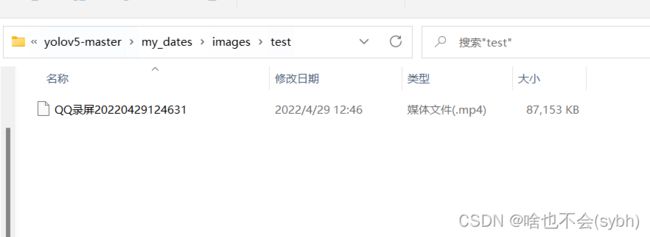
然后运行detect.py就ok了!!!!!!

结果放在 (每次运行都会生成一个新的exp,所以我这是exp7)

九、总结
我们本次只是识别穿越火线中的人物,还没有实现自动瞄准,我只用了一百张图片进行预测,预测效果不是很好,你可以增加些图片进行训练。
后期还会更新!!!!!!!!!!!!!!!!!!!