3D-LaneNet+: Anchor Free Lane Detection using a Semi-Local Representation
动机:
对3D-LaneNet的改进; 特点 semi-local tile representation: breaks down lanes into simple lane segments whose parameters can be learnt
【CC】网格化,基于每个网格去学习Lane的特征;最后再通过NN合起来;这样天然就是Anchorfree的,并且支持不规则的/没有封闭的曲线
技术点:
3D-LaneNet: The first is a CNN architecture with integrated Inverse Perspective Mapping (IPM) to project feature maps to Bird Eye View (BEV)
【CC】NN网络集成IPM功能,这个还没看过,需要进一步看看
the second is an anchor based representation which allows casting the lane detection problem to a single stage object detection problem.
【CC】在这片文章了里面已经弃用了,不看了
not compact objects with easily defined centers. Therefore, instead of predicting the entire lane as a whole, we detect small lane segments that lie within the cell and their attributes
【CC】没法预测Lane的中心点,就基于Cell去做检测和attributives的预测
learn for each cell a global embedding that allows clustering the small lane segments together into full 3D lanes
【CC】合起来,没什么好说
相关论文参考
Towards End-to-End Lane Detection: an Instance Segmentation Approach
【CC】先切分再聚合的方式做检测;有点像M公司的做法
A Mixed Classification-Regression Framework for 3D Pose Estimation from 2D Images
【CC】参考 分类-回归的混合框架
网络结构:

each tile holds a line segment parameterized by an offset from the tile center, an orientation and a height offset from the BEV plane
【CC】每个CELL基于中心点去估计LANE在本CELL的“形状参数”,具体参数见下
Learning 3D lane segments with Semi-local tile representation
an Inverse Perspective Mapping (IPM) module to project feature maps to BEV. The projection applies a homography, defifined by camera pitch angle ϕcam and height hcam, that maps the image plane to the road plane
【CC】根据camera的位姿去IPM
We assume that through each tile gij ∈ GW×H can pass a single line segment which can be approximated by a straight line.
【CC】感觉不是很合理,CELL是可能存在多个lINE相交的可能的情况,不知道怎么处理;但是从后面LOSS函数的设计感觉是允许一个CELL的特征属于多个LANE,只需要把掩码改成概率即可???
the network also predicts a binary classifification score cij indicating the probability that a lane intersects a particular tile
【CC】预测是否有线通过这个CELL
the network regresses, per each tile gij , three parameters: lateral offset distance relative to tile center rij , line angle φij , (see Local tiles in Fig. 1) and height offset ∆zij
【CC】NN去估计每个CELL关于LANE三个参数:关于中心点的距离,方向,高度差
Position and z offsets are trained using an L1 loss:
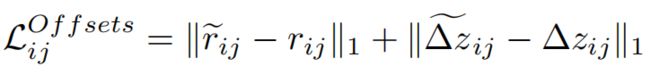
【CC】距离和高度差使用L1 LOSS
Predicting the line angle φij:
we classify the angle φ (omitting tile indexing for brevity) to be in one of Nα bins, centered at α = { 2π/Nα · i} .we regress a vector ∆α, corresponding to the residual offset relative to each bin center
【CC】先对2π进行bin化(此时做分类),然后基于每个bin做offset的回归
angle bin estimation is optimized using a soft multi-label objective, and the GT
probabilities are calculated as

【CC】仔细看这个式子,其实就是每个BIN的累计占有的概率,画个图就清楚了
The angle loss is the sum of the classifification and offset regression losses:
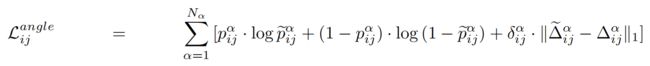
where δαij is the indicator function masking the relevant bins for the offset learning.
【CC】估计这个LOSS函数是从第二篇论文里面抄出来的;前面两项就像是一个二分类的交叉熵
The lane tile probability cij is trained using a binary cross entropy loss:

the overall tile loss is the sum over all the tiles in the BEV grid

【CC】上面两个LOSS FUNC就没啥好说的
Global embedding for lane curve clustering
we learn an embedding vector fij for each tile such that vectors representing tiles belonging to the same lane would reside close in embedded space while vectors epresenting tiles of different lanes would reside far apart.
【CC】从CELL中学习到向量f,f代表CELL属于同一个LANE/属于不同LANE的“距离”,参看下面的LOSS设计
The discriminative push-pull loss is a combination of two losses:
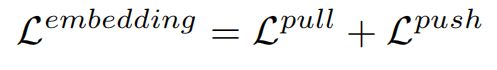
A pull loss aimed at pulling the embeddings of the same lane tiles closer together:
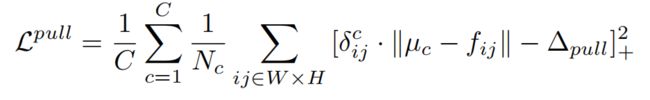
【CC】属于同一根LANE的LOSS FUNC,对均值的误差项补偿上同类的最大距离的L2范数;比较好奇C是如何可变的,另这个∆pul如何设计?
a push loss aimed at pushing the embedding of tiles belonging to different lanes farther apart:
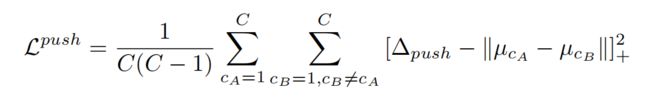
【CC】属于不同LANE的LOSS FUNC, 计算“俩-俩LANE间的2范数距离”然后求平均:属于LANE A与LANE B均值差 与最小距离的差的2范数,整体的设计思路跟PULL差不多;同样,好奇这个∆push如何设计?
where C is the number of lanes (can vary),
【CC】LANE的个数,可变
Nc is the number of tiles belonging to lane c,
【CC】属于某条LANE的CELL数目
δc ij indicates if tile i, j belongs to lane c,
【CC】一个掩码,标明当前CELL是不是属于某个LANE
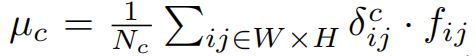
is the average of fij belonging to lane c,
【CC】一条LANE上所有CELL关于特征f的均值
∆pull constraints the maximal intra-cluster distance
【CC】同属于一条LANE的特征空间的最大距离
∆push is the inter-cluster minimal required distance.
【CC】属于不同LANE的特征空间的最小距离
【CC】对这个LOSS:如果使得整体Loss越小,即使得PULL的LOSS变小,那意味着CELL的特征f大于∆pull这个门限的同时更接近µc,即我们期望得到NN网络,提器CEL的特征后使得属于同一条LANE的特征均值的方差越小越好;同时这个PUSH的LOSS变小,对其取负数,变成LANE A/B间均值的距离 减去 门限后 越大越好,即我们期望得到NN网络,提取CELL的特征使得属于不同LANE的特征均值的距离(2范数)超过门限越大越好
We adopted the clustering methodology from Neven et al. [16] which
uses mean-shift to find the clusters centers and set a threshold around each center to get the cluster members. We set the threshold to ∆push/2
【CC】聚类参数的设计的描述,整体沿用了第一篇参考论文的做法,没啥可说的