Python数据结构与算法—基础知识
文章目录
- 一、数据结构与算法(python)
- 二、算法效率衡量
-
- 1.时间复杂度
- 2.最坏时间复杂度
- 3.时间复杂度的基本计算规则
- 4.常见时间复杂度
- 5.常见时间复杂度之间的关系
- 三、数据结构
-
- 1.概念
- 2.算法与数据结构的区别
- 3.数据之间的结构关系
- 四、什么是递归
- 五、汉诺塔问题
-
- 1。问题引入
- 2.算法分析
- 3.总结
一、数据结构与算法(python)
数据结构是以某种形式将数据组织在一起的集合,它不仅存储数据,还支持访问和处理数据的操作。算法是为求解一个问题需要遵循的、被清楚指定的简单指令的集合。
二、算法效率衡量
执行时间反应算法效率,实现算法程序的执行时间可以反应出算法的效率,即算法的优劣。
1.时间复杂度
我们假定计算机执行算法每一个基本操作的时间是固定的一个时间单位,那么有多少个基本操作就代表会花费多少时间单位。算然对于不同的机器环境而言,确切的单位时间是不同的,但是对于算法进行多少个基本操作(即花费多少时间单位)在规模数量级上却是相同的,由此可以忽略机器环境的影响而客观的反应算法的时间效率。
对于算法的时间效率,我们可以用“大O记法”来表示。
“大O记法”:对于单调的整数函数f,如果存在一个整数函数g和实常数c>0,使得对于充分大的n总有f(n)<=c*g(n),就说函数g是f的一个渐近函数(忽略常数),记为f(n)=O(g(n))。也就是说,在趋向无穷的极限意义下,函数f的增长速度受到函数g的约束,亦即函数f与函数g的特征相似。
时间复杂度:假设存在函数g,使得算法A处理规模为n的问题示例所用时间为T(n)=O(g(n)),则称O(g(n))为算法A的渐近时间复杂度,简称时间复杂度,记为T(n)
对于算法进行特别具体的细致分析虽然很好,但在实践中的实际价值有限。对于算法的时间性质和空间性质,最重要的是其数量级和趋势,这些是分析算法效率的主要部分。而计量算法基本操作数量的规模函数中那些常量因子可以忽略不计。例如,可以认为3n2和100n2属于同一个量级,如果两个算法处理同样规模实例的代价分别为这两个函数,就认为它们的效率“差不多”,都为n2级。
2.最坏时间复杂度
分析算法时,存在几种可能的考虑:
算法完成工作最少需要多少基本操作,即最优时间复杂度
算法完成工作最多需要多少基本操作,即最坏时间复杂度
算法完成工作平均需要多少基本操作,即平均时间复杂度
对于最优时间复杂度,其价值不大,因为它没有提供什么有用信息,其反映的只是最乐观最理想的情况,没有参考价值。
对于最坏时间复杂度,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作。
对于平均时间复杂度,是对算法的一个全面评价,因此它完整全面的反映了这个算法的性质。但另一方面,这种衡量并没有保证,不是每个计算都能在这个基本操作内完成。而且,对于平均情况的计算,也会因为应用算法的实例分布可能并不均匀而难以计算。
因此,我们主要关注算法的最坏情况,亦即最坏时间复杂度。
3.时间复杂度的基本计算规则
1.基本操作,即只有常数项,认为其时间复杂度为O(1)
2.顺序结构,时间复杂度按加法进行计算
3.循环结构,时间复杂度按乘法进行计算
4.分支结构,时间复杂度取最大值
5.判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略
6.在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度
4.常见时间复杂度
| 执行次数函数举例 | 阶 |
|---|---|
| 12 | O(1) |
| 2n+3 | O(n) |
| 3n2+2n+1 | O(n2) |
| 5log2n+20 | O(logn) |
| 2n+3nlog2n+19 | O(nlogn) |
| 6n3+2n2+3n+4 | O(n3) |
| 2n | O(2n) |
注意:经常将log2n(以2为底的对数)简写成logn
5.常见时间复杂度之间的关系
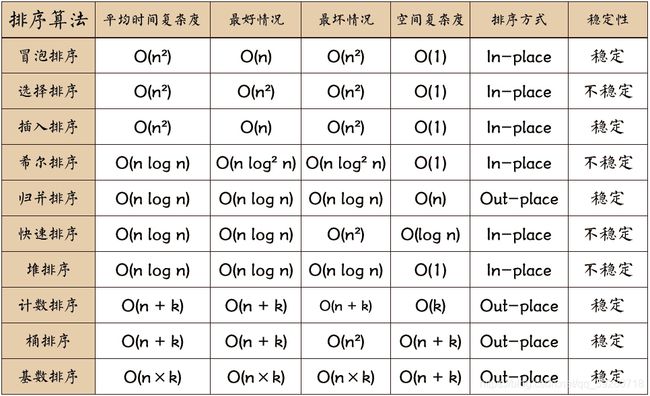

所消耗的时间从小到大
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
三、数据结构
1.概念
数据是一个抽象的概念,将其进行分类后得到程序设计语言中的基本类型。如:int,float,char等。数据元素之间不是独立的,存在特定的关系,这些关系便是结构。数据结构指数据对象中数据元素之间的关系。
Python给我们提供了很多现成的数据结构类型,这些系统自己定义好的,不需要我们自己去定义的数据结构叫做Python的内置数据结构,比如列表、元组、字典。而有些数据组织方式,Python系统里面没有直接定义,需要我们自己去定义实现这些数据的组织方式,这些数据组织方式称之为Python的扩展数据结构,比如栈,队列等。
2.算法与数据结构的区别
数据结构只是静态的描述了数据元素之间的关系。
高效的程序需要在数据结构的基础上设计和选择算法。
程序 = 数据结构 + 算法
总结:算法是为了解决实际问题而设计的,数据结构是算法需要处理的问题载体
3.数据之间的结构关系

一、逻辑结构:表示数据之间的抽象关系(如邻接关系、从属关系等),按每个元素可能具有的直接前趋数和直接后继数将逻辑结构分为“线性结构”和“非线性结构”两大类。
1.特点:
只是描述数据结构中数据元素之间的联系规律。
是从具体问题中抽象出来的数学模型,是独立于计算机存储器的(与机器无关)。
2.逻辑结构分类:集合,线性结构,非线性结构
1)线性结构是n个数据元素的有序(次序)集合。
集合中必存在唯一的一个"第一个元素";
集合中必存在唯一的一个"最后的元素";
除最后元素之外,其它数据元素均有唯一的"后继";
除第一元素之外,其它数据元素均有唯一的"前驱"。
2)树形结构(层次结构)
树形结构指的是数据元素之间存在着“一对多”的树形关系的数据结构,是一类重要的非线性数据结构。在树形结构中,树根结点没有前驱结点,其余每个结点有且只有一个前驱结点。叶子结点没有后续结点,其余每个结点的后续节点数可以是一个也可以是多个。
3)图状结构(网状结构)
图是一种比较复杂的数据结构。在图结构中任意两个元素之间都可能有关系,也就是说这是一种多对多的关系。
4)其他结构
除了以上几种常见的逻辑结构外,数据结构中还包含其他的结构,比如集合等。有时根据实际情况抽象的模型不止是简单的某一种,也可能拥有更多的特征。

二、存储结构:逻辑结构在计算机中的具体实现方法,分为顺序存储方法、链接存储方法、索引存储方法、散列存储方法。
1.特点:
是数据的逻辑结构在计算机存储器中的映象(或表示)
存储结构是通过计算机程序来实现的,因而是依赖于具体的计算机语言的。
2.存储结构分类:顺序存储结构、链式存储结构、索引存储结构、散列存储结构
1)顺序存储(Sequential Storage):将数据结构中各元素按照其逻辑顺序存放于存储器一片连续的存储空间中。
2)链式存储(Linked Storage):将数据结构中各元素分布到存储器的不同点,用记录下一个结点位置的方式建立它们之间的联系,由此得到的存储结构为链式存储结构。
3)索引存储(Indexed Storage):在存储数据的同时,建立一个附加的索引表,即索引存储结构=数据文件+索引表。
4)散列存储:根据节点的关键字直接计算出该节点的存储地址的一种存储方式。
四、什么是递归
递归就是不断的调用自己
示例1:
import sys
# print(sys.getrecursionlimit()) # 默认最大递归限制:1000
# sys.setrecursionlimit(999999999) # 不管数值多大,最多到20963册
def recursion(n):
print(n)
recursion(n + 1)
1.必须有一个明确的结束条件,要不就会变成死循环了,最终撑爆系统
2.每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3.递归执行效率不高,递归层次过多会导致栈溢出
实列2:
def func1(x):
if x > 0:
print(x)
func1(x - 1)
def func2(x):
if x > 0:
func2(x - 1)
print(x)
func1(3)
print("——————")
func2(3)
输出
3
2
1
——————
1
2
3
五、汉诺塔问题
1。问题引入
汉诺塔问题源于印度一个古老传说。相传大梵天创造世界的时候做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着64片黄金圆盘。大梵天命令婆罗门把圆盘从下面开始按大小顺序重新摆放在另一根柱子上。并且规定,任何时候,在小圆盘上都不能放大圆盘,且在三根柱子之间一次只能移动一个圆盘。问应该如何操作?

2.算法分析
n个盘子时:
1.把n-1个盘子从a经过c移动到b
2.把第n个盘子从a移动到c
3.把n-1个盘子从b经过a移动到c
代码如下(示例):
def hanoi(n, a, b, c):
if n > 0:
hanoi(n - 1, a, c, b)
print("从%s移动到%s" % (a, c))
hanoi(n - 1, b, a, c)
hanoi(5, "A", "B", "C")
—————————————————————————————————————————————————————————————————————————
从A移动到C
从A移动到B
从C移动到B
从A移动到C
从B移动到A
从B移动到C
从A移动到C
3.总结
1.汉诺塔移动次数的递推式:h(x)=2h(x-1)+1
2.h(64)=18446744073709551615
3.假设婆罗门每秒搬一个盘子则总共需要5800亿年!