神经网络与深度学习理论教程二,tensorflow2.0教程,rnn
*免责声明:
1\此方法仅提供参考
2\搬了其他博主的操作方法,以贴上路径.
3*
场景一:RNN循环神经网络
场景二:RNN的改进
场景三:seq2seq与attention机制
场景四:集束搜索 Beam Search
场景五:词嵌入与NLP
场景六:谷歌开源算力
场景七:高级主题-GAN/自动编码器/CappsuleNet
. . .
场景一:RNN循环神经网络
参考课程一:
参考课程二:
1.1 前导



1.2 序列表示法











在这里,我们可以利用h5的结果去分类效果要很多,因为h5,已经包含了h4,h3,h2,h1.的语境。
1.3 循环神经网络–理解方式一
参考课程




例子:
对于一个句子,在整个序列中,开始输入s,输出的应该是下一个最可能的词。





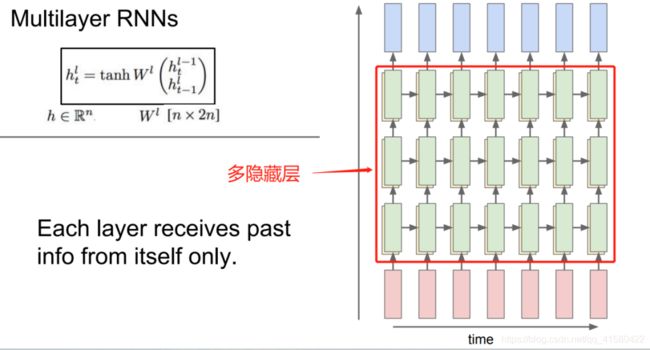
1.4 循环神经网络–理解方式二
参考课程
输入x进入神经网络进行处理,处理后一部分的信息输出y,一部分的信息,重新返回神经网络。







参考博文一: RNN前向传播、反向传播与并行计算(非常详细)
参考博文二: RNN、LSTM反向传播推导详解
1.5 交叉熵损失和时序反向传播算法(BPTT)



1.6 梯度消失和梯度爆炸

1.7 手写一个RNN案例,体现前向传播和反向传播

单个cell的前向传播
import numpy as np
import tensorflow as tf
# 单个cell的前向传播过程
# 两个输入,x_t,s_prev,parameters
def rnn_cell_forward(x_t, s_prev, parameters):
'''
单个cell的前向传播过程
x_t : 当期T时刻的输入
s_prev : 上一个cell的隐藏层输入
parameters : cell中的参数
return : s_next,out_pred,cache
'''
# 获取参数
U = parameters["u"]
W = parameters["w"]
V = parameters["v"]
ba = parameters["ba"]
by = parameters["by"]
# 根据公式计算
# 隐藏输出计算
# 公式s^t = tanh( U * x^t + W * s^(t-1) + ba)
s_next = np.tanh(np.dot(U, x_t) + np.dot(W, s_prev) + ba)
# 计算cell的输出
# o^t = softmax( V * s^t + by)
out_pred = tf.nn.softmax(np.dot(V, s_next) + by)
# 记录每一层的值,用于反向传播
cache = (s_next, s_prev, x_t, parameters)
return s_next, out_pred, cache
if __name__ == '__main__':
np.random.seed(1)
# 测试前向传播过程,创建下面的形状进行测试,m=3是词的个数,n=5是自定义数字
x_t = np.random.randn(3, 1)
s_prev = np.random.randn(5, 1)
U = np.random.randn(5, 3)
W = np.random.randn(5, 5)
V = np.random.randn(3, 5)
ba = np.random.randn(5, 1)
by = np.random.randn(3, 1)
parameters = {"u": U, "w": W, "v": V, "ba": ba, "by": by}
s_next, out_pred, cache = rnn_cell_forward(x_t, s_prev, parameters)
print("s_next", s_next, "s_next.shape=", s_next.shape)
print("out_pred=", out_pred, "out_pred.shape=", out_pred.shape)

import numpy as np
import tensorflow as tf
# 单个cell的前向传播过程
# 两个输入,x_t,s_prev,parameters
def rnn_cell_forward(x_t, s_prev, parameters):
'''
单个cell的前向传播过程
x_t : 当期T时刻的输入
s_prev : 上一个cell的隐藏层输入
parameters : cell中的参数
return : s_next,out_pred,cache
'''
# 获取参数
U = parameters["u"]
W = parameters["w"]
V = parameters["v"]
ba = parameters["ba"]
by = parameters["by"]
# 根据公式计算
# 隐藏输出计算
# 公式s^t = tanh( U * x^t + W * s^(t-1) + ba)
s_next = np.tanh(np.dot(U, x_t) + np.dot(W, s_prev) + ba)
# 计算cell的输出
# o^t = softmax( V * s^t + by)
out_pred = tf.nn.softmax(np.dot(V, s_next) + by)
# 记录每一层的值,用于反向传播
cache = (s_next, s_prev, x_t, parameters)
return s_next, out_pred, cache
# 定义所有的cell进行前向传播
def rnn_forward(x, s0, parameters):
'''
x :输入序列,形状(m ,1,T)T序列长度
s0 :初始状态输入,0
parameters :所有cell共享的参数,U,W,V,ba,by
return :s,y,caches
'''
caches = []
# 获取序列的长度,时刻数
m, _, T = x.shape
# 获取输入的N,定义隐藏层输出大小状态
m, n = parameters["v"].shape
# 获取s0的值,保存到s_next里面,以便于前向传播传入到cell
s_next = s0
# 定义s,y保留所有cell的隐藏层状态以及输出
s = np.zeros((n, 1, T))
y = np.zeros((m, 1, T))
# 循环对每一个cell进行前向传播计算
for t in range(T):
# 对于t时刻的cell进行输出
s_next, out_pred, cache = rnn_cell_forward(x[:, :, t], s_next, parameters)
# 放入数组当中
s[:, :, t] = s_next
y[:, :, t] = out_pred
# 放入所有的缓存到列表当中
caches.append(cache)
return s, y, caches
if __name__ == '__main__':
# forward测试
np.random.seed(1)
# 定义了4个cell.每个词条现状(3,1) ,m=3 ,n=5
x = np.random.randn(3, 1, 4)
s0 = np.random.randn(5, 1)
W = np.random.randn(5, 5)
U = np.random.randn(5, 3)
V = np.random.randn(3, 5)
ba = np.random.randn(5, 1)
by = np.random.randn(3, 1)
parameters = {"u": U, "w": W, "v": V, "ba": ba, "by": by}
s, y, caches = rnn_forward(x, s0, parameters)
print("s=", s, "s.shape=", s.shape)
print("y=", y, "y.shape=", y.shape)


# 单个cell的反向传播
# 计算哪些梯度值:3个参数和其他的梯度值
def rnn_cell_backward(ds_next, cache):
'''
ds_netx : s_next的梯度值
cache : 当前cell的缓存
return : gradients :改cell的6个梯度值
'''
# 获取cache当中的缓存以及参数
(s_next, s_prev, x_t, parameters) = cache
# 获取参数
U = parameters["u"]
W = parameters["w"]
# V=parameters["v"]
# ba=parameters["ba"]
# by=parameters["by"]
# 根据公式进行反向传播计算
# 1 计算tanh的导数
dtanh = (1 - s_next ** 2) * ds_net
# 2 计算U的梯度值
dU = np.dot(dtanh, x_t.T)
# 3 计算W的梯度值
dW = np.dot(dtanh, s_prev.T)
# 4 计算ba的梯度值
# 保持计算之后的u的维度不变
dba = np.sum(dtanh, axis=1, keepdims=1)
# 5 计算x_t的导数
dx_t = np.dot(U.T, dtanh)
# 6 计算s_prev的导数
ds_prev = np.dot(W.T, dtanh)
# 把所有的导数保存到字典中返回
gradients = {"dtanh": dtanh, "dU": dU, "dW": dW, "dba": dba, "dx_t": dx_t, "ds_prev": ds_prev}
return gradients
多个cell的反向传播
这里我们假设知道了所有时刻相当于损失的ds梯度值。
# 多个cell的反向传播
# 假设知道了所有时刻相当于损失的ds梯度值
# 每个cell的s^t,两部分组成
# 不同时刻,对于U,W,ba这些参数需要相加
def rnn_backward(ds , caches):
'''
ds :每个时刻的损失对于s的梯度值(假设已知的),(n,1,4)
caches :每个cell的输出值
return :
'''
# 取出cache当中的值
(s1 ,s0 ,x_1 ,parameters ) =cache[0]
# 获取输入数据的总共序列长度
n, _, T =ds.shape
m, _ = x_1.shape
# 存储所有一次更新后的参数的梯度值
dU = np.zeros((n, m))
dW = np.zeros((n, n))
dba = np.zeros((n, 1))
# 初始化一个为0的s第二部分的梯度值
ds_prevt = np.zeros((n, 1))
# 保存其他不需要更新的梯度
dx = np.zeros((m, 1, T))
# 循环从后往前进行计算梯度
for t in reversed(range(T)):
# 从3时刻开始
gradients = rnn_cell_backward(ds[:, :, t] + ds_prevt, caches[t])
# u,w,ba,x_t,s_prev梯度
# 共享参数需要相加
dU += gradients["dU"]
dW += gradients["dW"]
dba += gradients["dba"]
# 保存每一层的x_t,s_prev的梯度值
dx[:, :, t] = gradients["dx_t"]
# 返回所有更新参数的梯度以及其他变量的梯度值
gradients = {"dU": dU, "dW": dw, "dba": dba, "dx": dx}
return dradients
# 测试
if __name__ == '__main__':
np.random.seed(1)
# 定义了4个cell.每个词条现状(3,1) ,m=3 ,n=5
x = np.random.randn(3, 1, 4)
s0 = np.random.randn(5, 1)
W = np.random.randn(5, 5)
U = np.random.randn(5, 3)
V = np.random.randn(3, 5)
ba = np.random.randn(5, 1)
by = np.random.randn(3, 1)
parameters = {"u": U, "w": W, "v": V, "ba": ba, "by": by}
s, y, caches = rnn_forward(x, s0, parameters)
# 随机给每个4个cell的隐藏层输出的导数结果(真实需要计算损失的导数)
ds = np.random.randn(5, 1, 4)
gradients = rnn_backward(ds, caches)
print(gradients)
场景二:RNN的改进
1.1 GRU(门控循环单元) 14年提出
参考博文:



GRU的内部结构







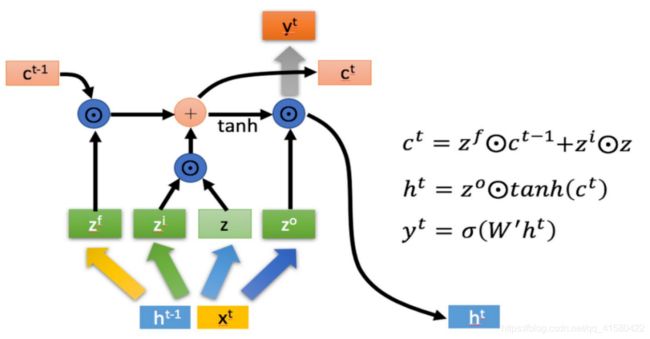
1.2 LSTM (Long-short term memory) 1997年
参考博文

小明在上海一所大学读书,当后面出现东川路男子职业技术大学时候,前面的一所大学的信息就可以被抹掉或者更新。





LSTM的内部结构


1.3 Sentiment Classification情感分类实战rnn做的

方式一:

# 影评情感分类
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import tensorflow_datasets as tfds
# pip install tensorflow-datasets
# tensorflow-datasets的使用参考https://blog.csdn.net/mao_hui_fei/article/details/89520947
import matplotlib.pyplot as plt
# h画迭代次数和准确率的关系
def plot_graphs(history, metric):
plt.plot(history.history[metric])
plt.plot(history.history['val_' + metric], '')
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend([metric, 'val' + metric])
plot.show()
# 数据集的加载与划分
# 下载以后的地址在c下 如我的C:\Users\weeks\tensorflow_datasets\imdb_reviews
dataset, info = tfds.load('imdb_reviews/subwords8k', with_info=True, as_supervised=True)
train_examples, test_examples = dataset['train'], dataset['test']
encoder = info.features['text'].encoder # 编码换成词
print("Vocabulary size:{}".format(encoder.vocab_size)) # 查看词汇量的大小 比如8000多个
'''
例如
sample_string="hello tensorflow."
encoded_string = encoder.encode(sample_string) #编码
print("Encoded string is {}".format(encoded_string)) #Encoded string is[4025,222,6307,2327,4043,2120,7975]
original_string = encoder.decode(encoded_string) #解码
print('The original string: "{}" '.format(original_string)) #The original string:"hello tensorflow"
assert original_string == sample_string #判断解码的和编码的是不是一样
for index in encoded_string:
print( '{}---->{} '.format(index,encoder.decode([index] )) ) #可以查看具体的编码信息
'''
# 准备数据集
BUFFER_SIZE = 10000
BATCH_SIZE = 64
train_dataset = (train_examples.shuffle(BUFFER_SIZE).padded_batch(BATCH_SIZE, padded_shapes=([None], [])))
# 这里用的方法shuffle(BUFFER_SIZE)从上面的你的数据集中每次选buffer_size条即上面的10000条中的一条如第34条,
# 把每次选择的10000区间的下一条10001加入到前面选走的位置,加到第34条位置
# padded_batch就是填充的意思,填充batch_size的大小 如元素[[1,2],[3,4,5],[6,7],[8]]
# padded_batch(2,) 结果为:以每两个划分上面的数据,对齐补0, [[1,2,0],[3,4,5]], [ [6,7],[8,0] ]
test_dataset = (test_examples.shuffle(BUFFER_SIZE).padded_batch(BATCH_SIZE, padded_shapes=([None], [])))
train_dataset = (train_examples.shuffle(BUFFER_SIZE).padded_batch(BATCH_SIZE))
test_dataset = (test_examples.padded_batch(BATCH_SIZE))
model = tf.keras.Sequential([
tf.keras.layers.Embedding(encoder.vocab_size, 64), # 上面划分出来有8000多个单词,输入8000多维one-hot编码的向量
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'), # 加上一个全连接层,用relu函数激活一下
tf.keras.layers.Dense(1)
])
model.summary()
# 模型优化器
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accracy'])
# 训练模型
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
test_loss, test_acc = model.evaluate(test_dataset)
print("Test Loss:{}".format(test_loss))
print("Test Accuracy:{}".format(test_acc))
![]()
# 填充
def pad_to_size(vec ,size):
zero s =[0] + (size - len(vec))
vec.extend(zeros)
return vec
# 简单预测
def sample_predict(sample_pred_text ,pad):
encoded_sample_pred_text = encoder.encode(sample_pred_text)
if pad:
encoded_sample_pred_text = pad_to_size(encoded_sample_pred_text ,64)
encoded_sample_pred_text = tf.cast(encoded_sample_pred_text, tf.float32)
predictions = model.predict(tf.expand_dims(encoded_sample_pred_text ,0))
return (predictions)
# 预测 on a sample text without padding
sample_pred_text = ('The movie was cool.The animation and the graphics '
'were out of this world, I would recommend this movie.'
)
predictions = sample_predict(sample_pred_text ,pad=False)
print(predictions)
plot_graphs(history , 'accuracy')

方式二:
#低级api
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL' ] ='2 ' # 屏蔽通知和Warning
assert tf.__version__.startswith('2.' ) # 判断是否是tensorflow2的版本
batchsz = 128
# 载入数据
total_words = 10000
max_review_len = 80
embedding_len = 100
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# x_train:[b, 80]
# x_test: [b, 80]
# 填充句长,使其都为80
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
# 去掉最后一个不满批量的数据
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x_test shape:', x_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# [b, 64],h memory状态变量
self.state0 = [tf.zeros([batchsz, units])]
self.state1 = [tf.zeros([batchsz, units])]
# 词向量表示
# [b, 80] => [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# [b, 80, 100] , h_dim: 64
# RNN: cell1 ,cell2, cell3
# SimpleRNN双层RNN
self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.5)
self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.5)
# fc, [b, 80, 100] => [b, 64] => [b, 1]
# 全连接层输出结果
self.outlayer = layers.Dense(1)
def call(self, inputs, training=None):
"""
net(x) net(x, training=True) :train mode
net(x, training=False): test
:param inputs: [b, 80]
:param training:
:return:
"""
# [b, 80]
x = inputs
# embedding: [b, 80] => [b, 80, 100]
x = self.embedding(x)
# rnn cell compute
# [b, 80, 100] => [b, 64]
state0 = self.state0
state1 = self.state1
for word in tf.unstack(x, axis=1): # word: [b, 100]
# h1 = x*wxh+h0*whh
# out0: [b, 64]
out0, state0 = self.rnn_cell0(word, state0, training)
# out1: [b, 64]
out1, state1 = self.rnn_cell1(out0, state1, training)
# out: [b, 64] => [b, 1]
x = self.outlayer(out1)
# p(y is pos|x)
prob = tf.sigmoid(x)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
# 装载
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics=['accuracy'] ,experimental_run_tf_function=False)
# 训练
model.fit(db_train, epochs=epochs, validation_data=db_test)
# 输出测试函数的评价
model.evaluate(db_test)
if __name__ == '__main__':
main()

#高级api
import os
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
batchsz = 128
# the most frequest words
total_words = 10000
max_review_len = 80
embedding_len = 100
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# x_train:[b, 80]
# x_test: [b, 80]
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x_test shape:', x_test.shape)
class MyRNN(keras.Model):
def __init__(self, units):
super(MyRNN, self).__init__()
# transform text to embedding representation
# [b, 80] => [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# [b, 80, 100] , h_dim: 64
self.rnn = keras.Sequential([
layers.SimpleRNN(units, dropout=0.5, return_sequences=True, unroll=True),
layers.SimpleRNN(units, dropout=0.5, unroll=True)
])
# fc, [b, 80, 100] => [b, 64] => [b, 1]
self.outlayer = layers.Dense(1)
def call(self, inputs, training=None):
"""
net(x) net(x, training=True) :train mode
net(x, training=False): test
:param inputs: [b, 80]
:param training:
:return:
"""
# [b, 80]
x = inputs
# embedding: [b, 80] => [b, 80, 100]
x = self.embedding(x)
# rnn cell compute
# x: [b, 80, 100] => [b, 64]
x = self.rnn(x)
# out: [b, 64] => [b, 1]
x = self.outlayer(x)
# p(y is pos|x)
prob = tf.sigmoid(x)
return prob
def main():
units = 64
epochs = 4
model = MyRNN(units)
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics=['accuracy'])
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
if __name__ == '__main__':
main()

场景三:seq2seq与attention机制
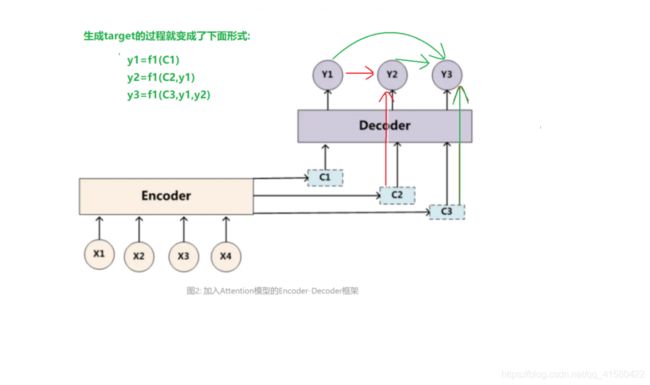
1.1 Encoder–Decoder


1.2 seq2seq 2014年






1.3 attention注意力机制
参考博文







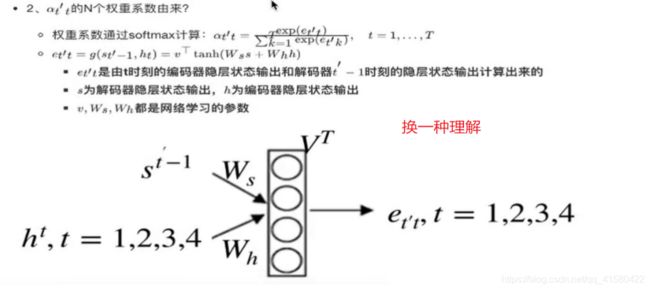
1.4 attention机制本质思想





1.5 其他attention模型







场景四:集束搜索 Beam Search
参考博文:
1.1 问题引入
选出的句子并不一定是最佳的答案,还有其他的选择。

1.2 集束搜索流程




场景五:词嵌入与NLP
NLP学习路径参考博文一:
学习路径参考博文二:
1.1 问题引入

1.2 词嵌入




1.3 Word2Vec案例

搜狗新闻中文语料


训练模型语句,命令行切换到上面的文件下执行:
python 上面的文件.py 要训练的语料 模型保存路径
例如:python a.py ./corpus_seg.txt 要保存的路径



场景六:谷歌开源算力


开源算力网址: (如果打不开,则需要)



这个notebook又可以执行linux下的一些命令,因为这其实是一台linux的虚拟机,只不过执行linux命令的时候前面要加!,比如:!ls , !pwd.


场景七:高级主题-GAN/自动编码器/CappsuleNet
参考课程:
1.1 GAN用途

1.2 GAN原理


1.3 GAN代码实现

#利用an网络生成自己的数据集
# MNIST 手写数字的 图片生成#MNIST 手写数字的 图片生成
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import Input , Dense ,Reshape, Flatten ,Dropout
from tensorflow.keras.layers import BatchNormalization , Activation ,ZeroPadding2D ,Conv2D,LeakyReLU,UpSampling2D
from tensorflow.keras.models import Sequential ,Model
import matplotlib.pyplot as plt
import numpy as np
# 第一步: 定义模型类
class GCGAN(object):
def __init__(self):
# 输入图片的形状
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols ,self.channels)
# 第四步: 初始化GAN模型结构
# 建立d 判断器CNN结构,初始化判别器训练优化参数
# 联合建立g生成器CNN结构,初始化生成器训练优化参数
# * 输入噪点数据,输出预测的类别概率
# * 注意生成器训练时,判断器不进行训练
# 来自keras.optimizers导入ADam
def init_model(self):
# 定义原始噪点数据向量长度大小
self.latent_dim = 100
# 获取定义好的优化器
optimizer = Adam(0.0002 , 0.5)
# 1: 建立判别器结构参数
# 选择损失,优化器,以及衡量准确率
self.discriminator = self.build_discriminator() # 获取判别器
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy']) # 判别器的交叉熵损失,accuracy是衡量准确率的一个指标
# 2: 建立生成器结构参数,指定生成器损失
self.generator = self.build_generator() # 获取生成器
z=Input(shape=(self.latent_dim,)) # 加入噪点数据
img=self.generator(z) # 张图片
# 合并模型的损失,并且之后只训练生成器,判别器不训练
self.discriminator.trainable = False # 限制判 训练
# *********这句重点******* 判别器不训练才让生成器更好的拟合真实样本分布概率,要不然2个都在变,没有参考依据
valid = self.discriminator(img) # img是上 生成器返回的 ,加入已经训练好的判别器去判别,得到的valid的是正反样本的概率
# 训练生成器欺骗判别器
self.combined = Model(z,valid) # 输入是z,输出是valid
self.combined.compile(loss= 'binary_crossentropy',optimizer= optimizer ) # loss趋向于1比较好
# 第二步:定义一个判别器
def build_discriminator(self):
model = Sequential( )
model.add(Conv2D(32,kernel_size=3,strides=2, input_shape=self.img_shape,padding='same'))
model.add(LeakyReLU(alpha = 0.2))
model.add(Dropout(0.25))
model.add(Conv2D(64,kernel_size=3,strides=2, padding='same' ))
model.add(ZeroPadding2D(padding=((0,1),(0,1))) )
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(128,kernel_size=3,strides=2, padding='same' ))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(256,kernel_size=3,strides=1, padding='same' ))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1,activation ='sigmoid'))
model.summary()
img = Input(shape = self.img_shape)
validity = model(img)
return Model(img,validity)
# 第三步: 定义模型的生成器 CNN结构
def build_generator(self):
model = Sequential( )
model.add(Dense(128*7*7, activation='relu', input_dim=self.latent_dim ))
model.add(Reshape((7,7,128)))
model.add(UpSampling2D( ))
model.add(Conv2D(128,kernel_size=3,padding='same' ))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D( ))
model.add(Conv2D(64,kernel_size=3,padding='same' ))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(Conv2D(self.channels,kernel_size=3,padding='same' ))
model.add(Activation('tanh'))
model.summary()
noise = Input(shape = (self.latent_dim, ))
img = model(noise)
return Model(noise, img)
# 第五步 : 训练D.G
# 加载数据集并处理,建立正负样本目标值,迭代训练识别器,训练生成器
def train(self ,epochs ,batch_size=32 ):
# 加载手写数字
(X_train ,_), (_ ,_ )= mnist.load_data()
# 进行归一化处理
X_train = X_train /127.5 - 1. # 这里的数据形状是0,1,2 [60000,28,28]
X_train = np.expand_dims(X_train, axis=3) # 扩充维度,在最后的维度去扩充[60000,28,28,1]
# 正负样本的目标值建立
valid = np.ones((batch_size, 1)) # 真实样本的目标值为1
fake = np.zeros((batch_size, 1)) # 假样本的目标值为0
for epoch in range(epochs):
# 1: 训练判别器
# 选择随机的一些真实样本
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# 生成器产生假样本
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
gen_imgs = self.generator.predict(noise) # 生成假图片
# 训练判别器过程
d_loss_real =self.discriminator.train_on_batch(imgs, valid)
d_loss_fake =self.discriminator.train_on_batch(gen_imgs, fake)
# 计算平均两部分的损失
loss_avg = np.add(d_loss_real, d_loss_fake) / 2
# 2: 训练生成器,停止判别器
# 就是去训练前面指定的conbined模型
# 用目标值为1去训练,目的使得生成器生成的样本越来越接近真实样本
g_loss = self.combined.train_on_batch(noise, valid)
# 打印结果
print("迭代次数:%d , 判别器损失: %f, 生成器损失: %f" % (epoch, loss_avg[0], g_loss))
# 保存生成的图片
if epoch % 3 == 0:
self.save_imgs(epoch)
# 保存图片
def save_imgs(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, self.latent_dim))
gen_imgs = self.generator.predict(noise)
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray')
axs[i, j].axis('off')
cnt += 1
fig.savefig('./images/mnist_%d.png' % epoch)
plt.close()
if __name__ == '__main__':
dc = GCGAN()
dc.init_model()
dc.train(epochs=5, batch_size=32)
这里主要讲思想,这里会遇到以下问题,我是没有去解决的。
可能出现的问题


命令行pip list 查看到 我的keras版本是2.2.4, tf的版本是2.3.0.
版本对应查看

除此以外,如果不想改自己的库对应的版本,还可以把上面的代码直接复制到场景六中的谷歌开源算力上去计算。(当然访问要)
这是我找到的其他作者的GAN实现mnist数据集的方法,用上面的思想查看下面代码的实现。
参考博文:[深度学习-实践]GAN基于手写体Mnist数据集生成新图片
效果:

import tensorflow as tf
import tensorflow.keras as keras
import numpy as np
import matplotlib.pyplot as plt
# define the standalone discriminator model
def define_discriminator(in_shape=(28,28,1)):
model = keras.models.Sequential()
# normal
model.add(keras.layers.Conv2D(64, (3,3), padding='same', input_shape=in_shape))
model.add(keras.layers.LeakyReLU(alpha=0.2))
# downsample
model.add(keras.layers.Conv2D(128, (3,3), strides=(2,2), padding='same'))
model.add(keras.layers.LeakyReLU(alpha=0.2))
# downsample
model.add(keras.layers.Conv2D(128, (3,3), strides=(2,2), padding='same'))
model.add(keras.layers.LeakyReLU(alpha=0.2))
# downsample
model.add(keras.layers.Conv2D(256, (3,3), strides=(2,2), padding='valid'))
model.add(keras.layers.LeakyReLU(alpha=0.2))
# classifier
model.add(keras.layers.Flatten())
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(1, activation='sigmoid'))
# compile model
opt = keras.optimizers.Adam(lr=0.0002, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy'])
model.summary()
return model
# load and prepare cifar10 training images
def load_real_samples():
# load cifar10 dataset
(trainX, _), (_, _) = tf.keras.datasets.mnist.load_data()
# convert from unsigned ints to floats
#X = trainX.astype('float32')
X = trainX.reshape(trainX.shape[0], 28, 28, 1).astype('float32')
# scale from [0,255] to [-1,1]
X = (X - 127.5) / 127.5
return X
# select real samples
def generate_real_samples(dataset, n_samples):
# choose random instances
ix = np.random.randint(0, dataset.shape[0], n_samples)
# retrieve selected images
X = dataset[ix]
# generate 'real' class labels (1)
y = np.ones((n_samples, 1))
return X, y
def generate_fake_samples1(n_samples):
# generate uniform random numbers in [0,1]
X = np.random.rand(28 * 28 * 1 * n_samples)
# update to have the range [-1, 1]
X = -1 + X * 2
# reshape into a batch of color images
X = X.reshape((n_samples, 28, 28, 1))
# generate 'fake' class labels (0)
y = np.zeros((n_samples, 1))
return X, y
# train the discriminator model
def train_discriminator(model, dataset, n_iter=20, n_batch=128):
half_batch = int(n_batch / 2)
# manually enumerate epochs
for i in range(n_iter):
# get randomly selected 'real' samples
X_real, y_real = generate_real_samples(dataset, half_batch)
# update discriminator on real samples
_, real_acc = model.train_on_batch(X_real, y_real)
# generate 'fake' examples
X_fake, y_fake = generate_fake_samples1(half_batch)
# update discriminator on fake samples
_, fake_acc = model.train_on_batch(X_fake, y_fake)
# summarize performance
print('>%d real=%.0f%% fake=%.0f%%' % (i+1, real_acc*100, fake_acc*100))
def test_train_discriminator():
# define the discriminator model
model = define_discriminator()
# load image data
dataset = load_real_samples()
# fit the model
train_discriminator(model, dataset)
# define the standalone generator model
def define_generator(latent_dim):
model = keras.models.Sequential()
# foundation for 4x4 image
n_nodes = 256 * 3 * 3
model.add(keras.layers.Dense(n_nodes, input_dim=latent_dim))
model.add(keras.layers.LeakyReLU(alpha=0.2))
model.add(keras.layers.Reshape((3, 3, 256)))
# upsample to 8x8
model.add(keras.layers.Conv2DTranspose(128, (3,3), strides=(2,2), padding='valid'))
model.add(keras.layers.LeakyReLU(alpha=0.2))
# upsample to 16x16
model.add(keras.layers.Conv2DTranspose(128, (3,3), strides=(2,2), padding='same'))
model.add(keras.layers.LeakyReLU(alpha=0.2))
# upsample to 32x32
model.add(keras.layers.Conv2DTranspose(64, (3,3), strides=(2,2), padding='same'))
model.add(keras.layers.LeakyReLU(alpha=0.2))
# output layer
model.add(keras.layers.Conv2D(1, (3,3), activation='tanh', padding='same'))
return model
# generate points in latent space as input for the generator
def generate_latent_points(latent_dim, n_samples):
# generate points in the latent space
x_input = np.random.randn(latent_dim * n_samples)
# reshape into a batch of inputs for the network
x_input = x_input.reshape(n_samples, latent_dim)
return x_input
# use the generator to generate n fake examples, with class labels
def generate_fake_samples(g_model, latent_dim, n_samples):
# generate points in latent space
x_input = generate_latent_points(latent_dim, n_samples)
# predict outputs
X = g_model.predict(x_input)
# create 'fake' class labels (0)
y = np.zeros((n_samples, 1))
return X, y
def show_fake_sample():
# size of the latent space
latent_dim = 100
# define the discriminator model
model = define_generator(latent_dim)
# generate samples
n_samples = 49
X, _ = generate_fake_samples(model, latent_dim, n_samples)
# scale pixel values from [-1,1] to [0,1]
X = (X + 1) / 2.0
# plot the generated samples
for i in range(n_samples):
# define subplot
plt.subplot(7, 7, 1 + i)
# turn off axis labels
plt.axis('off')
# plot single image
plt.imshow(X[i])
# show the figure
plt.show()
# define the combined generator and discriminator model, for updating the generator
def define_gan(g_model, d_model):
# make weights in the discriminator not trainable
d_model.trainable = False
# connect them
model = tf.keras.models.Sequential()
# add generator
model.add(g_model)
# add the discriminator
model.add(d_model)
# compile model
opt = tf.keras.optimizers.Adam(lr=0.0002, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=opt)
return model
def show_gan_module():
# size of the latent space
latent_dim = 100
# create the discriminator
d_model = define_discriminator()
# create the generator
g_model = define_generator(latent_dim)
# create the gan
gan_model = define_gan(g_model, d_model)
# summarize gan model
gan_model.summary()
# train the composite model
def train_gan(gan_model, latent_dim, n_epochs=200, n_batch=128):
# manually enumerate epochs
for i in range(n_epochs):
# prepare points in latent space as input for the generator
x_gan = generate_latent_points(latent_dim, n_batch)
# create inverted labels for the fake samples
y_gan = np.ones((n_batch, 1))
# update the generator via the discriminator's error
gan_model.train_on_batch(x_gan, y_gan)
# evaluate the discriminator, plot generated images, save generator model
def summarize_performance(epoch, g_model, d_model, dataset, latent_dim, n_samples=150):
# prepare real samples
X_real, y_real = generate_real_samples(dataset, n_samples)
# evaluate discriminator on real examples
_, acc_real = d_model.evaluate(X_real, y_real, verbose=0)
# prepare fake examples
x_fake, y_fake = generate_fake_samples(g_model, latent_dim, n_samples)
# evaluate discriminator on fake examples
_, acc_fake = d_model.evaluate(x_fake, y_fake, verbose=0)
# summarize discriminator performance
print('>Accuracy real: %.0f%%, fake: %.0f%%' % (acc_real * 100, acc_fake * 100))
# save plot
#save_plot(x_fake, epoch)
# save the generator model tile file
filename = 'minst_generator_model_%03d.h5' % (epoch + 1)
g_model.save(filename)
# train the generator and discriminator
def train(g_model, d_model, gan_model, dataset, latent_dim, n_epochs=200, n_batch=128):
bat_per_epo = int(dataset.shape[0] / n_batch)
half_batch = int(n_batch / 2)
# manually enumerate epochs
for i in range(n_epochs):
# enumerate batches over the training set
for j in range(bat_per_epo):
# get randomly selected 'real' samples
X_real, y_real = generate_real_samples(dataset, half_batch)
# update discriminator model weights
d_loss1, _ = d_model.train_on_batch(X_real, y_real)
# generate 'fake' examples
X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
# update discriminator model weights
d_loss2, _ = d_model.train_on_batch(X_fake, y_fake)
# prepare points in latent space as input for the generator
X_gan = generate_latent_points(latent_dim, n_batch)
# create inverted labels for the fake samples
y_gan = np.ones((n_batch, 1))
# update the generator via the discriminator's error
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# summarize loss on this batch
print('>%d, %d/%d, d1=%.3f, d2=%.3f g=%.3f' %
(i + 1, j + 1, bat_per_epo, d_loss1, d_loss2, g_loss))
# evaluate the model performance, sometimes
if (i + 1) % 10 == 0:
summarize_performance(i, g_model, d_model, dataset, latent_dim)
def test_train_gan():
# size of the latent space
latent_dim = 100
# create the discriminator
d_model = define_discriminator()
# create the generator
g_model = define_generator(latent_dim)
# create the gan
gan_model = define_gan(g_model, d_model)
# load image data
dataset = load_real_samples()
# train model
train(g_model, d_model, gan_model, dataset, latent_dim)
# generate points in latent space as input for the generator
def generate_latent_points(latent_dim, n_samples):
# generate points in the latent space
x_input = np.random.randn(latent_dim * n_samples)
# reshape into a batch of inputs for the network
x_input = x_input.reshape(n_samples, latent_dim)
return x_input
# plot the generated images
def create_plot(examples, n):
# plot images
for i in range(n * n):
# define subplot
plt.subplot(n, n, 1 + i)
# turn off axis
plt.axis('off')
# plot raw pixel data
plt.imshow(examples[i, :, :], cmap='gray')
plt.show()
def show_imgs_for_final_generator_model():
# load model
model = tf.keras.models.load_model('minst_generator_model_010.h5')
# generate images
latent_points = generate_latent_points(100, 100)
# generate images
X = model.predict(latent_points)
# scale from [-1,1] to [0,1]
X = (X + 1) / 2.0
# plot the result
X = X.reshape(X.shape[0], 28,28)
create_plot(X, 10)
def show_single_imgs():
model = tf.keras.models.load_model('minst_generator_model_010.h5')
# all 0s
vector = np.asarray([[0.75 for _ in range(100)]])
# generate image
X = model.predict(vector)
# scale from [-1,1] to [0,1]
X = (X + 1) / 2.0
# plot the result
plt.imshow(X[0, :, :])
plt.show()
if __name__ == '__main__':
#define_discriminator()
#test_train_discriminator()
# show_fake_sample()
#show_gan_module()
test_train_gan()
#g_module = define_generator(100)
#print(g_module.summary())
show_imgs_for_final_generator_model()
# define the size of the latent space
1.4 自动编码器用途

1.5 自动编码器的定义与原理
1.6 普通自编码器–基于mnist手写数字–全连接层


# 普通自编码器-- 基于mnist手写数字 --全连接层
from keras.layers import Input ,Dense
from keras.layers import Conv2D , MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
# 第一步: 初始化自编码器结构
# &&& 定义编码器 ; 输出32个神经元,使用relu激活函数,(32这个值可以自己制定)
# &&& 定义解码器 : 输出784个神经元,使用sigmoid函数,(784这个值是输出与原图片大小一致)
# 损失 : 每个像素值的交叉熵损失 (输出为sigmoid值(0,1),输入图片要进行归一化(0,1) )
class AutoEncoder (object):
# 自动编码器初始化
def __init__(self):
self.encoding_dim = 32 # 编码器向量的大小
self.decoding_dim = 784 # 解码器向量的大小
self.mode l =self.auto_encoder_model()
# 自编码器模型的定义
def auto_encoder_model(self):
# 自编码器的结构
input_img = Input(shape=(784,)) # 输入一张图片
encoder = Dense(self.encoding_dim ,activation='relu')(input_img) # 32大小进行编码,使用relu激活
decoder = Dense(self.decoding_dim ,activation='sigmoid')(encoder) # 解码得到784,采用sigmoid函数
# 定义完整的模型逻辑
auto_encoder = Model(inputs = input_img, outputs = decoder ) # 输入是input_img,输出是outputs
auto_encoder.compile(optimizer= "adam" , loss= 'binary_crossentropy')
return auto_encoder # 返回auto_encoder
###第二步: 模型的训练
def train(self):
(x_train ,_), (x_test ,_) = mnist.load_data()
# 进行归一化
x_train = x_train.astype("float32" ) /255.
x_test = x_test.astype('float32' ) /255.
# 由于全连接层的要求,需要将数据装换成二维的[batch , feature] 进行形状改变
x_train = np.reshape(x_train, (len(x_train), np.prod(x_train.shape[1:]) ))
x_test = np.reshape(x_test, (len(x_test), np.prod(x_test.shape[1:]) ))
print(x_train.shape)
print(x_test.shape)
# 训练
self.model.fit(x_train ,x_train ,epochs=5,
batch_size=256,
shuffle=True,
validation_data= (x_test ,x_test))
# 第三步 ; 显示模型生成的图片与原始图片进行对比 (可选操作)
def display(self):
(x_train ,_), (x_test ,_) = mnist.load_data()
x_test = np.reshape(x_test, (len(x_test), np.prod(x_test.shape[1:]) ) )
decoded_imgs = self.model.predict(x_test)
plt.figure(figsize= (20 ,4))
# 显示5张结果 n=5
for i in range(n):
# 显示编码前结果
ax=plt.sub p lot(2,n,i+1)
plt.imshow(x_test[i].reshape(28,28) )
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 显示编码后结果
ax=plt.sub p lot(2,n,i+n+1)
plt.imshow(decoded_imgs[i].reshape(28,28) )
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
if __name__ == '__main__':
ae = AutoEncoder()
ae.train()
ae.display()

1.7 多层自编码器–基于mnist手写数字–全连接层
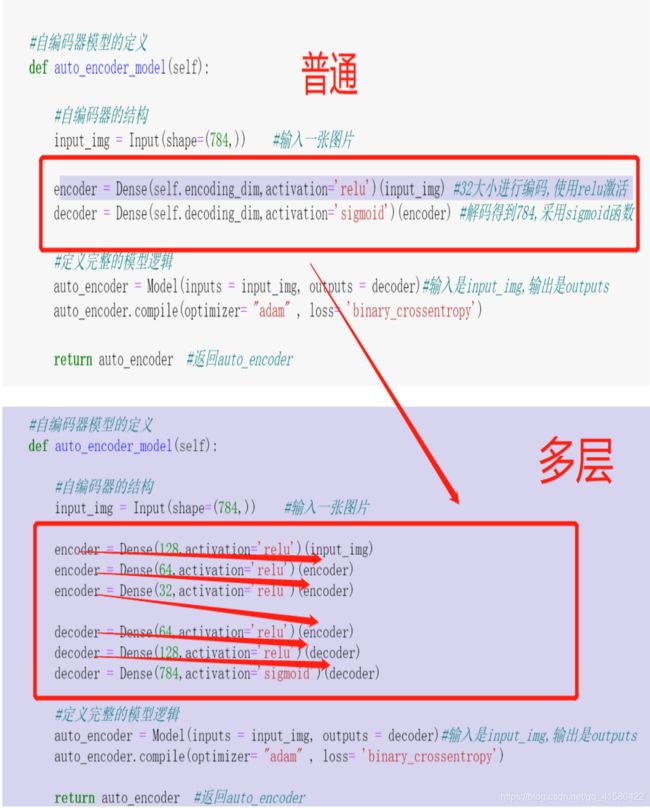
1.8 卷积自编码器–基于mnist手写数字–卷积结构


1.9 正则化自编码器–基于mnist手写数字–降噪自编码器


# 主要思想是在训练之前,对数据进行添加噪音处理
# 这里是在卷积自编码器的基础之上
def train(self):
(x_train ,_), (x_test ,_) = mnist.load_data()
# 进行归一化
x_train = x_train.astype("float32" ) /255.
x_test = x_test.astype('float32' ) /255.
# 由于卷积层的要求,由上面的输入的改变可知,[60000, 28,28,1]
x_train = np.reshape(x_train, (len(x_train) ,28 ,28 ,1 ))
x_test = np.reshape(x_test, (len(x_test), 28 ,28 ,1 ))
print(x_train.shape)
print(x_test.shape)
# 进行噪点数据处理
x_train_noisy = x_train + np.random.normal(loc=0.0 , scale=1.0 , size=x_train.shape)
x_test_noisy = x_test + np.random.normal(loc=0.0 , scale=1.0 , size=x_test.shape)
# 处理成0-1之间的数据
x_train_noisy = np.clip(x_train_noisy , 0. , 1.)
x_test_noisy = np.clip(x_test_noisy , 0. , 1.)
# 训练
self.model.fit(x_train_noisy ,x_train ,epochs=5,
batch_size=256,
shuffle=True,
validation_data= (x_test_noisy ,x_test)) # 训练的时候还是拿真实的样本x_train去训练,输入数据是x_train_noisy
# 第三步 ; 显示模型生成的图片与原始图片进行对比 (可选操作)
def display(self):
(x_train ,_), (x_test ,_) = mnist.load_data()
x_test = np.reshape(x_test, (len(x_test), 28 ,28 ,1 ) )
# 进行噪点数据处理
x_test_noisy = x_test + np.random.normal(loc=0.0 , scale=1.0 , size=x_test.shape)
decoded_imgs = self.model.predict(x_test)
plt.figure(figsize= (20 ,4))
# 显示5张结果 n=5
for i in range(n):
# 显示编码前结果
ax=plt . subplot(2,n,i+ 1)
plt.imshow(x_test_noisy[i].reshape(28,28) )
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
1.10 CapsuleNet胶囊神经网络(实验的效果不错/2017)





you did it
