李宏毅机器学习课程总结(1)
回归(Regression)
回归是一种数学模型,主要用于分析因变量与自变量之间的函数关系,如果因变量和自变量之间的关系是线性关系,那么该回归就是线性回归。在机器学习领域,回归的主要功能是预测,即通过使用在已知的数据集上训练并总结出来的因变量与自变量之间的函数规律,对未知的或没有统计到的数据进行预测推断。主要应用场景在:股市预测、自动驾驶和推荐系统等。
在课程中李宏毅老师用预测宝可梦进化后的CP值进行回归问题的解释。进化前的宝可梦可能会影响进化后CP值的因素是:①宝可梦进化前的CP值![]() ;②宝可梦的种类
;②宝可梦的种类![]() ;③宝可梦的生命值
;③宝可梦的生命值![]() ;④宝可梦的体重
;④宝可梦的体重![]() ;⑤宝可梦的身高
;⑤宝可梦的身高![]() 。需要解决的问题是,需要找到一个函数f,输入进化前的宝可梦的已知数据x,输出预测的进化后的CP值y。
。需要解决的问题是,需要找到一个函数f,输入进化前的宝可梦的已知数据x,输出预测的进化后的CP值y。
首先假设进化后的CP值只与进化前的CP值有关,并成线性关系。在这个假设条件下可以写出函数f:
![]()
其中b和w是未知,b被称为偏置(Bias),w被称为权重(Weight)。需要通过训练数据(Training Data)来选择出好的f,即挑选出好的b和w的组合,使得通过f预测出来的宝可梦进化后的CP值与真实值最接近。此时就需要引入一个评估f好与坏的函数——损失函数(Loss Funtion),损失函数的输入是一个f,输出的是这个f有多不好。由于一组b和w就可以表示一个f,所以输入f可以用输入b和w代替,如下
![]()
所以损失函数也可以看做是用于衡量一组参数的好坏。
在这里损失函数可以使用
![]()
表示,其中![]() 为真实值。该损失函数统计了所有的n个数据中,真实值和预测值的差值,可以起到有效的评估作用,总差值越大,预测的结果就越不好,f也就越不好。
为真实值。该损失函数统计了所有的n个数据中,真实值和预测值的差值,可以起到有效的评估作用,总差值越大,预测的结果就越不好,f也就越不好。
如何找到最佳的w和b的组合,使得损失函数的值最小,是要讨论的重点。
梯度下降(Gradient descent)
梯度下降法需要先前定义的损失函数L可微分,对于损失函数L(w),具体步骤是:
①随机选取一个起始点![]() ;
;
②计算当![]() 时L的微分,微分为负则增大w,微分为正则减小w。增大和减小的幅度取决于计算出来的微分值和一个超参数学习率(Learning Rate)
时L的微分,微分为负则增大w,微分为正则减小w。增大和减小的幅度取决于计算出来的微分值和一个超参数学习率(Learning Rate)![]() ,即w的更新公式为
,即w的更新公式为
![]()
通过多次迭代后,不断地往微分值较低的方向移动,最后达到微分值为0的点,即最优点,这个最优点可能是局部最优(Local Optimum)而不是全局最优(Global Optimum),要考虑损失函数的具体形式。在线性回归中loss函数没有局部最优。
同理,对于多参数的损失函数L(w, b):
①随机选取一个起始点![]() 和
和![]() ;
;
②计算当![]() ,
,![]() 时L对w和b的偏导数,即w和b的更新公式为
时L对w和b的偏导数,即w和b的更新公式为
通过上述方法计算出了预测函数中了w和b参数。
分析与优化
得到了w和b参数后,将测试数据集输入到预测函数f,表现不佳。
选择另外一个模型
![]()
提升了模型的复杂度,进一步拟合训练集数据,在测试集上loss有所下降。
继续引入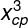 、
、![]() 的模型,随着次数的增加,模型在训练集上表现得越来越好,但是在测试集上表现得越来越糟。因此,复杂度高的模型会在训练集上表现得更好,但是在测试集上表现不一定好,这种现象称为过拟合(Overfitting)现象。相反,当模型过于简单时,在训练集上的表现有时还不如训练集,这种现象称为欠拟合(Underfitting)现象。因此在模型选择上,要选择综合表现最好的模型。
的模型,随着次数的增加,模型在训练集上表现得越来越好,但是在测试集上表现得越来越糟。因此,复杂度高的模型会在训练集上表现得更好,但是在测试集上表现不一定好,这种现象称为过拟合(Overfitting)现象。相反,当模型过于简单时,在训练集上的表现有时还不如训练集,这种现象称为欠拟合(Underfitting)现象。因此在模型选择上,要选择综合表现最好的模型。
优化问题可以大致分为两类:①重新设计模型;②重新定义损失函数。
对于重新设计模型,李宏毅老师引入了新的特征——宝可梦的物种![]() 。对于不同的宝可梦物种,使用不同的预测模型,结果在训练集和测试集上都有着良好的表现。继续寻找可能的其他因素,比如宝可梦的体重、身高和HP值等。
。对于不同的宝可梦物种,使用不同的预测模型,结果在训练集和测试集上都有着良好的表现。继续寻找可能的其他因素,比如宝可梦的体重、身高和HP值等。
对于重新定义损失函数,通过定义更适合的损失函数,来帮助寻找到最好的f。原损失函数只考虑了预测值和真实值的偏差,在这里引入正则化(Regularization)的概念。正则化是在损失函数中增加一个正则化参数![]() :
:
![]()
加入了正则化参数后,损失函数的大小还会受到参数![]() 大小的影响,期待找到参数更小的模型,参数越小,函数f就越平滑。对于相同的输入变化
大小的影响,期待找到参数更小的模型,参数越小,函数f就越平滑。对于相同的输入变化![]() ,参数较小的函数f输出所受到的影响
,参数较小的函数f输出所受到的影响![]() 就越小,即模型对输入不敏感,对噪声的抵抗力提升了。正则化同时抑制了模型的过拟合现象,正则化参数越大,训练集上的表现越差。平滑的模型在测试集上会表现得更好,可以通过调整正则化参数调整模型的平滑程度。在做正则化时不用考虑偏置b,b的大小不影响模型的平滑程度,调整b的大小只会让曲线上下移动。
就越小,即模型对输入不敏感,对噪声的抵抗力提升了。正则化同时抑制了模型的过拟合现象,正则化参数越大,训练集上的表现越差。平滑的模型在测试集上会表现得更好,可以通过调整正则化参数调整模型的平滑程度。在做正则化时不用考虑偏置b,b的大小不影响模型的平滑程度,调整b的大小只会让曲线上下移动。
误差分析
误差主要来自偏差(Bias)和方差(Variance)两个方面,在进行模型优化时要准确找到误差的来源,才能对模型进行提升。偏差用![]() 表示,方差用
表示,方差用![]() 表示。
表示。
计算![]() 时,在数据集x中任意取出n个点
时,在数据集x中任意取出n个点![]() ,计算出来的均值m不一定是
,计算出来的均值m不一定是![]() ,但是不断得从x中取出多个数据计算均值
,但是不断得从x中取出多个数据计算均值![]() ,所有m的期望值就是
,所有m的期望值就是![]() 。方差屈居于样本的数量n,
。方差屈居于样本的数量n,
![]()
即n越大估计就越准,就越接近![]() 。
。
经过多次提取不同数据,训练出来多个不同的函数![]() ,所有的
,所有的![]() 的期望值与正确函数
的期望值与正确函数![]() 之间的距离就是偏差。每次训练出来的
之间的距离就是偏差。每次训练出来的![]() ,与所有
,与所有![]() 的期望值之间的距离就是方差。我们所期待的函数f应该具有低偏差和低方差。需要做尽可能的事业,得到尽可能多的
的期望值之间的距离就是方差。我们所期待的函数f应该具有低偏差和低方差。需要做尽可能的事业,得到尽可能多的![]() ,这样就能更好的分析偏差和方差。
,这样就能更好的分析偏差和方差。
模型越复杂,每个![]() 就越惨,每个
就越惨,每个![]() 中参数的差距越大。模型简单会导致低方差,模型复杂会导致高方差。简单的模型不容易受到来自不同数据的影响,模型简单会导致高偏差,模型复杂会导致低偏差。模型简单会导致模型对数据的变化不敏感,导致所有的
中参数的差距越大。模型简单会导致低方差,模型复杂会导致高方差。简单的模型不容易受到来自不同数据的影响,模型简单会导致高偏差,模型复杂会导致低偏差。模型简单会导致模型对数据的变化不敏感,导致所有的![]() 直接的距离很小,方差就较小,同时模型简单会导致
直接的距离很小,方差就较小,同时模型简单会导致![]() 的范围较小,可能根本就没包含正确函数
的范围较小,可能根本就没包含正确函数![]() ,导致偏差较大;模型复杂会导致模型对数据的变化很敏感,不同的数据训练出来的
,导致偏差较大;模型复杂会导致模型对数据的变化很敏感,不同的数据训练出来的![]() 中的参数会差距很大,就会导致
中的参数会差距很大,就会导致![]() 的范围很大,训练出来的
的范围很大,训练出来的![]() 就会很散,方差较大,而
就会很散,方差较大,而![]() 的范围较大,包含正确函数
的范围较大,包含正确函数![]() 的可能性就越大,所有
的可能性就越大,所有![]() 的平均值与正确函数
的平均值与正确函数![]() 的距离就较小,偏差就较小。从拟合的角度来看,误差大来自方差很大,就是过拟合;误差大来自偏差很大,就是欠拟合。
的距离就较小,偏差就较小。从拟合的角度来看,误差大来自方差很大,就是过拟合;误差大来自偏差很大,就是欠拟合。
降低偏差时就要将模型:①增加更多的特征,②变为更为复杂的模型。由于模型本身不够好,收集更多的数据并不会有效降低偏差。增加模型的复杂度会导致![]() 的范围变大,覆盖到正确函数
的范围变大,覆盖到正确函数![]() 的可能性就更大,但是有可能会增大方差。
的可能性就更大,但是有可能会增大方差。
降低方差时就需要:①更多的数据,②正则化。由于模型复杂对数据的敏感度较高,收集更多的数据用于训练能够降低![]() 的范围,降低方差,但是现实实验中数据通常不容易收集,是个不实用的方法。正则化会使函数曲线变得更平滑,降低模型对数据的敏感度,降低
的范围,降低方差,但是现实实验中数据通常不容易收集,是个不实用的方法。正则化会使函数曲线变得更平滑,降低模型对数据的敏感度,降低![]() 的范围,降低方差,但是使用该方法可能会导致偏离正确函数
的范围,降低方差,但是使用该方法可能会导致偏离正确函数![]() ,增加偏差。
,增加偏差。
在模型的选择上希望在方差和偏差中做出平衡,这样才能得到最小的误差。
在训练的过程中,不推荐将模型在测试集上表现作为参考,来调整模型本身。可以将训练集分成两部分,一部分是真正的训练集,另一部分是用于选择和调整模型的验证集。
梯度下降补充说明
模型的训练是希望找到一个最好的f,定义了一个损失函数,用于评价当前f的参数![]() 有多么不好。随机选取起始参数
有多么不好。随机选取起始参数![]() ,计算偏导数进行参数的更新
,计算偏导数进行参数的更新
![]()
进过多次迭代,可以达到最佳的参数。当学习效果不佳时,需要小心得调整学习率,学习率的大小对学习的效果有着决定性的作用,过小的学习率会导致到达最优点的时间过长,过大的学习率会导致直接“跨”过最优点,在最低点附近反复震荡。我们所期望的是,在训练刚开始时,离最优点较远,使用较大的学习率,而在接近最优点时使用较小的学习率,同时最好的是不同的参数使用不同的学习率。
Adagrad
Adagrad为我们提供了生成自适应学习率的方法,在训练中的每一次迭代中,

将之前计算的梯度的平方累加,实现自适应地调整学习率。其中,利用 来估计梯度中的最佳步长,如二次函数中的
来估计梯度中的最佳步长,如二次函数中的![]() ,分子即为当前梯度
,分子即为当前梯度![]() ,分母为二阶导数,在Adagrad中用
,分母为二阶导数,在Adagrad中用 来估计二阶导数,同时不会产生多余的计算。
来估计二阶导数,同时不会产生多余的计算。
随机梯度下降(Stochastic Gradient Descent,SGD)
在训练数据中随机选取一个数据,只计算这个数据的损失函数值,不进行求和,
![]()
即在计算步长时,只对这一个数据进行步长计算,就进行参数更新。这样能加快参数的更新速度,并且能实时更新,每计算一次数据,就进行一次参数更新。缺点是容易产生波动,需要较多的迭代次数。
特征归一化(Feature Scaling)
将不同的特征数据修改为用一个分布,使得每一个特征数据对预测结果y的影响变得相同,这样能统一的使用一个学习率,更新参数时始终指向最优点走。
梯度下降的理论基础
当损失函数可微时,我们在损失函数中随机取一个起始点![]() ,不知道全局最低点应该往哪个方向走,但是在以起始点为圆心的极小的圆(半径为d)中,我们能找到局部最低点,当d足够小时,由泰勒公式可以得到
,不知道全局最低点应该往哪个方向走,但是在以起始点为圆心的极小的圆(半径为d)中,我们能找到局部最低点,当d足够小时,由泰勒公式可以得到
由于d足够小,![]() 与
与![]() 的距离极小,泰勒公式中后续的
的距离极小,泰勒公式中后续的![]() 高次项就可以忽略不计。令
高次项就可以忽略不计。令
![]()
其中![]() 可以看成是向量
可以看成是向量![]() 和向量
和向量 的内积,想要得到最小的
的内积,想要得到最小的![]() ,则只需要让的方向与
,则只需要让的方向与![]() 的方向相反,模要尽可能大,即设置为d,所以有
的方向相反,模要尽可能大,即设置为d,所以有

而![]() 即是梯度下降中的梯度,d即使梯度下降中的学习率。所以从理论上学习率要越小越好,无穷小的学习率才能保证每次梯度下降都能朝着损失函数值下降的方向进行参数更新。但是在实践中学习率通常只会选择一个较小的值,并且在训练的过程中不断地调整,在学习率设置在一个不好的值时,上述泰勒公式就不会成立,无法保证损失函数会变小,由上述可证实学习率的选取是梯度下降中的关键。
即是梯度下降中的梯度,d即使梯度下降中的学习率。所以从理论上学习率要越小越好,无穷小的学习率才能保证每次梯度下降都能朝着损失函数值下降的方向进行参数更新。但是在实践中学习率通常只会选择一个较小的值,并且在训练的过程中不断地调整,在学习率设置在一个不好的值时,上述泰勒公式就不会成立,无法保证损失函数会变小,由上述可证实学习率的选取是梯度下降中的关键。
梯度下降算法并不一定能使损失函数变小,特殊情况有:①学习率过大,在最优点周围来回震荡;②在计算梯度时,一个参数的梯度为a,另一个参数的梯度为b,朝着向量a和向量b的方向都能是损失函数变小,但是朝着向量a和向量b之和的方向并不一定。梯度下降算法也不一定能最终达到最优点,特殊情况有:①有可能掉入局部最优;②有可能会卡在鞍点,微分值为0,同时在经过暗点时,梯度下降的速度也会变得很慢。