李宏毅机器学习2016 第十一讲 半监督学习
视频链接:李宏毅机器学习(2016)(11)_演讲•公开课_科技_bilibili_哔哩哔哩
课程资源:Hung-yi Lee
课程相关PPT已经打包命名好了:链接:https://pan.baidu.com/s/1c3Jyh6S 密码:77u5
我的第十讲笔记:李宏毅机器学习2016 第十讲 为什么是“深度”学习
Semi-supervised Learning
本章主要讲述了半监督学习的原理及实现方法。
1.半监督学习
了解半监督学习之前需要首先知道监督学习(Supervised Learning)的概念,监督学习指训练样本都是带标签的。然而在现实中,数据数据是容易的,但是收集到带标签的数据却是非常昂贵的。
半监督学习指的是既包含部分带标签的数据也有不带标签的数据,通过这些数据来进行学习。
直推学习(Transductive Learning):不带标签的数据是测试数据。很多人说用了测试数据是一种作弊行为,实则不然,因为这里只是用了测试数据的特征,而其标签我们是不知道的。
归纳学习(Inductive Learning):不带标签的数据不是测试数据。
为什么说半监督学习是有用的呢?
这是因为不带标签的数据的分布是可以告诉我们一些东西,里面是蕴含知识的。
2.实现方法
主要有四种:生成模型、低密度分离假设、平滑性假设、更好的表达。

3.生成模型中的半监督学习(Semi-supervised Learning for Generative Model)
由之前的知识我们已经对生成模型有一定的了解。可以将其运用到半监督学习实现中。

首先根据带标签的数据初始化参数,接着计算不带标签的数据每个类别的后验概率,接着进行参数更新,再返回到第一步,不断的进行迭代。这个算法是收敛的,但是初始值会影响结果。
原先假设只有带标签的数据时,最大化一个似然函数值,每一个样本的值都可计算出;现在存在不带标签的数据,其中每一个样本属于某个类的几率是可以计算出,将其相加得到这个样本的概率值。然后使得损失函数不断减小通过迭代方法。

4.低密度分离(Low-density Separation)
自训练指通过带标签的数据训练处一个模型,然后将不带标签的数据应用到模型上,得到伪标签。接着移除一部分(例如权值大的)不带标签的数据,并将其加入到带标签的数据上。接着再重新进行模型训练,不断的进行迭代。
Q:这个方法在回归(regression)上有用吗?
A:没有用。回归指预测出一个具体的数值,将自身模型训练出的数据加入到训练数据中不会影响原模型。
Hard label 还是Soft label?

显然选hard label,这也是我们的“非黑即白”思想。
进阶版 基于熵的正则化(Entropy-based Regularization)
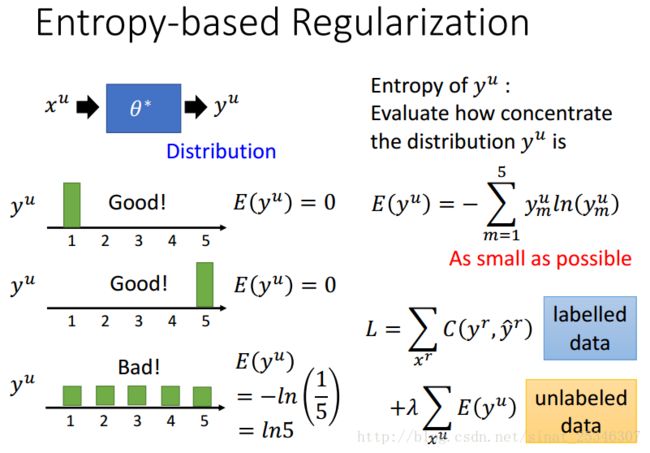
“低密度分离”的思想要求交界处的密度低,基于熵的正则化方法可以选择出“非黑即白”的分布。
5.平滑性假设(Smoothness Assumption)
平滑性假设的主要思想是“近朱者赤近墨者黑”。
“相似的x具有相同的y”这是不精确的,因为精确来说,x不是平均的,当x1和x2非常接近,并且其中有一个高密度区的话,可以说y1和y2是相同的。

在图中x1和x2通过一个高密度的路径连接在一起。
还有其他的理解。

这些都是“connected by a high density path”的体现。上图1可以理解为最左边的2可经由一定的路径到中间的2,因此是相似的,这是种间接相似。
怎么实现呢?
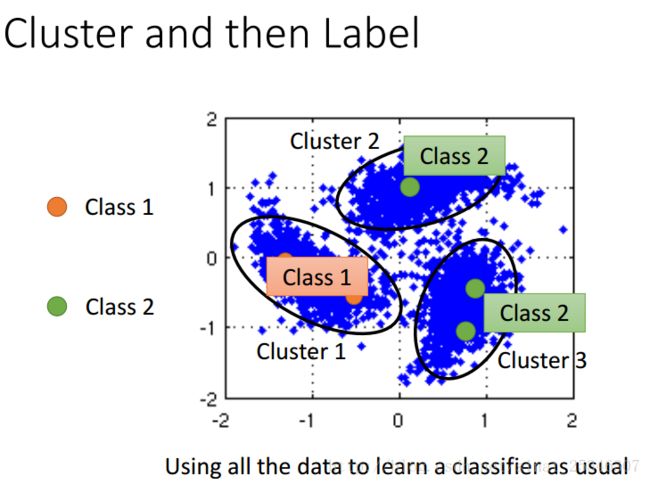
一种方法是先聚类再打上标签。
下面介绍一种基于图的方法(Graph-based Approach)。
怎样来定义出某些样本是通过高密度路径连接的呢?基于图的方法是建立能够表达数据点的图。构建图的方法可以用径向基函数来定义其相似性。

带标签的数据通过图来影响与其相邻的点。定义标签的平滑度。

计算方法可由下得:


S是基于y的,y是基于网络参数的,将其作为正则化项加入到损失函数中,最小化新的损失函数,不断更新参数。此外,smooth是可以放置在网络的任意位置的。
6.更好的表达(Better Representation)
主要思想是“去芜存菁,化繁为简”。指的是要抓住重点,得到更好的表达。

找到在观察(observation)下的潜在因素(latent factor),这些潜在的因素(通常更简单)是更好的表达(better represevtation)。上图漫画中,胡子是观察,头才是重点是更好的表达。
关于这方面的内容在非监督学习中将会重点讲解。
7.总结
本章讲述了半监督学习:生成模型中的半监督学习(Semi-supervised Learning for Generative Model)、低密度分离(Low-density Separation)、平滑性假设(Smoothness Assumption)、更好的表达(Better Representation)