基于ricequant的lstm时间序列股价预测(pytorch)
import pandas as pd
import matplotlib.pyplot as plt
import datetime
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import Dataset, DataLoader
# 确定每月日期 2014-01-01~2016-01-01
dates = get_trading_dates(start_date="2018-11-01", end_date="2021-12-15")
#stock = index_components("000065.XSHE")
x = get_price(["000065.XSHE"], start_date=dates[0], end_date=dates[-1], fields='close')
T = len(x)
//用到的函数
def generate_df_affect_by_n_days(series, n, index=False):
if len(series) <= n:
raise Exception("The Length of series is %d, while affect by (n=%d)." % (len(series), n))
df = pd.DataFrame()
for i in range(n):
df['c%d' % i] = series.tolist()[i:-(n - i)]
df['y'] = series.tolist()[n:]
if index:
df.index = series.index[n:]
return df
def readData(column='close', n=30, all_too=True, index=False, train_end=-300):
#df = pd.read_csv("sh.csv", index_col=0)
#df.index = list(map(lambda x: datetime.datetime.strptime(x, "%Y-%m-%d"), df.index))
#df.index = x["date"]
global x
x = x.reset_index()
x = x.set_index(['date'])
df = x
df_column = df[column].copy()
df_column_train, df_column_test = df_column[:train_end], df_column[train_end - n:]
df_generate_from_df_column_train = generate_df_affect_by_n_days(df_column_train, n, index=index)
if all_too:
return df_generate_from_df_column_train, df_column, df.index.tolist()
return df_generate_from_df_column_train
class RNN(nn.Module):
def __init__(self, input_size):
super(RNN, self).__init__()
self.rnn = nn.LSTM(
input_size=input_size,
hidden_size=64,
num_layers=1,
batch_first=True
)
self.out = nn.Sequential(
nn.Linear(64, 1)
)
def forward(self, x):
r_out, (h_n, h_c) = self.rnn(x, None) # None 表示 hidden state 会用全0的 state
out = self.out(r_out)
return out
class TrainSet(Dataset):
def __init__(self, data):
# 定义好 image 的路径
self.data, self.label = data[:, :-1].float(), data[:, -1].float()
def __getitem__(self, index):
return self.data[index], self.label[index]
def __len__(self):
return len(self.data)
//提取数据和数据处理
n = 30
LR = 0.0001
EPOCH = 100
train_end = -300
# 数据集建立
df, df_all, df_index = readData('close', n=n, train_end=train_end)
df_all = np.array(df_all.tolist())
plt.plot(df_index, df_all, label='real-data')
df_numpy = np.array(df)
df_numpy_mean = np.mean(df_numpy)
df_numpy_std = np.std(df_numpy)
df_numpy = (df_numpy - df_numpy_mean) / df_numpy_std
df_tensor = torch.Tensor(df_numpy)
trainset = TrainSet(df_tensor)
trainloader = DataLoader(trainset, batch_size=10, shuffle=True)
//模型训练
rnn = RNN(n)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.MSELoss()
for step in range(EPOCH):
for tx, ty in trainloader:
output = rnn(torch.unsqueeze(tx, dim=0))
loss = loss_func(torch.squeeze(output), ty)
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # back propagation, compute gradients
optimizer.step()
print(step, loss)
if step % 10:
torch.save(rnn, 'rnn.pkl')
torch.save(rnn, 'rnn.pkl')
//股价预测
generate_data_train = []
generate_data_test = []
test_index = len(df_all) + train_end
df_all_normal = (df_all - df_numpy_mean) / df_numpy_std
df_all_normal_tensor = torch.Tensor(df_all_normal)
for i in range(n, len(df_all)):
x = df_all_normal_tensor[i - n:i]
x = torch.unsqueeze(torch.unsqueeze(x, dim=0), dim=0)
y = rnn(x)
if i < test_index:
generate_data_train.append(torch.squeeze(y).detach().numpy() * df_numpy_std + df_numpy_mean)
else:
generate_data_test.append(torch.squeeze(y).detach().numpy() * df_numpy_std + df_numpy_mean)
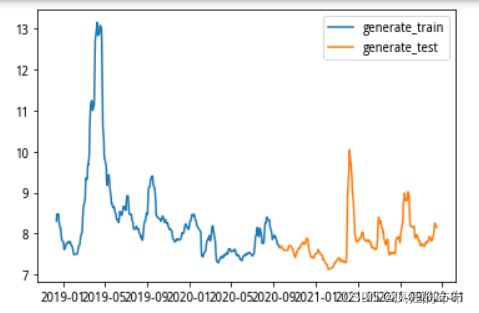
plt.plot(df_index[n:train_end], generate_data_train, label='generate_train')
plt.plot(df_index[train_end:], generate_data_test, label='generate_test')
plt.legend()
plt.show()
plt.cla()
plt.plot(df_index[train_end:-400], df_all[train_end:-400], label='real-data')
plt.plot(df_index[train_end:-400], generate_data_test[:-400], label='generate_test')
plt.legend()
plt.show()
效果图