Pytorch下基于lstm的股价预测
一、库准备
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import akshare as ak
import torch
from torch import nn二、构造
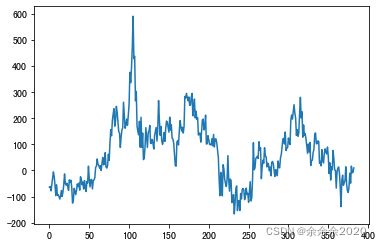
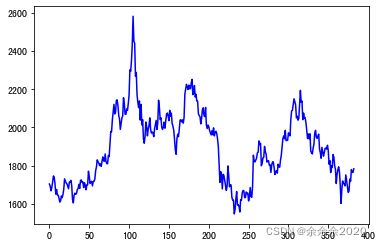
1.把茅台2017年到今天的股价画出来
share_prices=ak.stock_zh_a_hist(symbol='600519',start_date='20170101',end_date='20220410',adjust='qfq')['收盘'].values
share_prices = share_prices.astype('float32') # 转换数据类型: obj ->float
plt.plot(share_prices)
2.数据normalization
# 将数据集标准化到 [-1,1] 区间
scaler = MinMaxScaler(feature_range=(-1, 1)) # train data normalized
share_prices = scaler.fit_transform(share_prices.reshape(-1, 1)) 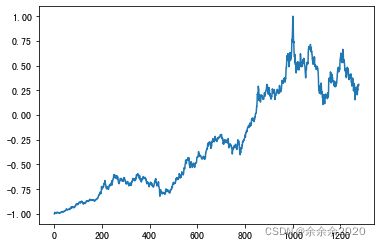
3.构造一个数据切分函数
def create_dataset(data, days_for_train=5) -> (np.array, np.array):
"""
根据给定的序列data,生成数据集。
数据集分为输入和输出,每一个输入的长度为days_for_train,每一个输出的长度为1。
也就是说用days_for_train天的数据,对应下一天的数据。
若给定序列的长度为d,将输出长度为(d-days_for_train)个输入/输出对
"""
dataset_x, dataset_y = [], []
for i in range(len(data) - days_for_train):
_x = data[i:(i + days_for_train)]
dataset_x.append(_x)
dataset_y.append(data[i + days_for_train])
return (np.array(dataset_x), np.array(dataset_y))dataset_x, dataset_y = create_dataset(share_prices, DAYS_FOR_TRAIN)以5个数为例,相当于X=[[0,1,2,3,4],[1,2,3,4,5]........[n-5,n-4,n-3,n-2,n-1]],Y=[[5],[6],[7],.....[n]]
在这里我们一共有1279个数,因此最后就切分成:
dataset_x:[1274,5,1]——即1274个五行一列的数组
dataset_y:[1274,1]——1274行一列的数组
4.分训练和验证
train_size = int(len(dataset_x) * 0.7)
train_x = dataset_x[:train_size]
train_y = dataset_y[:train_size]
test_x = dataset_x[train_size:]
test_y = dataset_y[train_size:]5.train改成[891,1,5]的size
seq代表单个序列的长度,batch_size代表一次喂入的序列个数,feature_size代表特征维度,
# 改变数据集形状,RNN 读入的数据维度是 (seq_size, batch_size, feature_size)
train_x = train_x.reshape( -1, 1,DAYS_FOR_TRAIN)
train_y = train_y.reshape(-1, 1, 1)
# 数据集转为pytorch的tensor对象
train_x = torch.from_numpy(train_x)
train_y = torch.from_numpy(train_y)6.用lstm训练
# train model
model = LSTM_Regression(DAYS_FOR_TRAIN, 32, output_size=1, num_layers=3) # 网络初始化
loss_function = nn.MSELoss() # 损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2) # 优化器
for epoch in range(EPOCHS):
out = model(train_x)
loss = loss_function(out, train_y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if (epoch + 1) % 100 == 0:
print('Epoch: {}, Loss:{:.5f}'.format(epoch + 1, loss.item()))class LSTM_Regression(nn.Module):
"""
使用LSTM进行回归
参数:
- input_size: feature size
- hidden_size: number of hidden units
- output_size: number of output
- num_layers: layers of LSTM to stack
"""
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, _x):
x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size)
s, b, h = x.shape # x is output, size (seq_len, batch, hidden_size)
x = x.view(s * b, h)
x = self.fc(x)
x = x.view(s, b, -1) # 把形状改回来
return xEpoch: 100, Loss:0.00137
Epoch: 200, Loss:0.00094
Epoch: 300, Loss:0.00067
Epoch: 400, Loss:0.00048
Epoch: 500, Loss:0.00036
Epoch: 600, Loss:0.00072
Epoch: 700, Loss:0.00026
Epoch: 800, Loss:0.00024
Epoch: 900, Loss:0.00023
Epoch: 1000, Loss:0.00022
Epoch: 1100, Loss:0.00034
Epoch: 1200, Loss:0.00022
Epoch: 1300, Loss:0.00055
Epoch: 1400, Loss:0.00020
Epoch: 1500, Loss:0.00048
Epoch: 1600, Loss:0.00020
Epoch: 1700, Loss:0.00021
Epoch: 1800, Loss:0.00019
Epoch: 1900, Loss:0.00026
Epoch: 2000, Loss:0.00019
7.数据验证
model = model.eval() # 转换成测试模式
test_x = test_x.reshape(-1,1, DAYS_FOR_TRAIN)
pred_y = model(torch.from_numpy(test_x))
pred_y = pred_y.view(-1).data.numpy()1)只喂test数据(红色为预测,蓝色为真实)
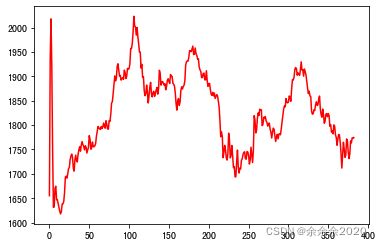

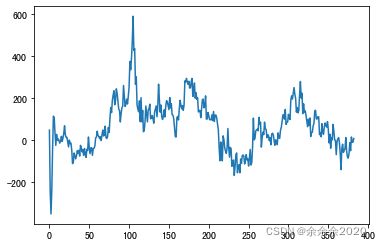
误差:
2)喂全量数据
dataset_x = dataset_x.reshape(-1, 1, DAYS_FOR_TRAIN) # (seq_size, batch_size, feature_size)
dataset_x = torch.from_numpy(dataset_x) # 转为pytorch的tensor对象
pred_y = model(dataset_x) # 全量数据集的模型输出 (seq_size, batch_size, output_size)
pred_y = pred_y.view(-1).data.numpy()# 对标准化数据进行还原
actual_pred_y = scaler.inverse_transform(pred_y.reshape(-1, 1))
actual_pred_y = actual_pred_y.reshape(-1, 1).flatten()
test_y = scaler.inverse_transform(test_y.reshape(-1, 1))
test_y = test_y.reshape(-1, 1).flatten()
actual_pred_y = actual_pred_y[-len(test_y):]
test_y = test_y.reshape(-1, 1)
assert len(actual_pred_y) == len(test_y)表现:

误差: