PyTorch Week 2——transforms图像增强
系列文章目录
PyTorch Week 2——Dataloader与Dataset
PyTorch Week 1
PyTorch Week 2——transforms图像增强
- 系列文章目录
- 一、transforms初体验
-
- transforms.Compose 有序组合数据增强方法,并依次执行
- 二、transforms.Normalize——逐个channel对图像进行标准化
-
- 1.步入代码查看实现
- 2.原理——训练数据分布对于训练效果有影响
- 三、二十二种图像预处理方法
-
- transform_invert可视化代码解读
- Crop
-
- 1 transforms.CenterCrop
- 2 transforms.RandomCrop随机选择一个角进行剪切
- 3 transforms.RandomCrop随机大小、长宽比裁剪图片
- 4 transforms.FiveCrop() 5 transforms.TenCrop()
- Flip翻转
-
- 6 RandomHorizontalFlip(),7 RandomVerticalFlip()
- Rotation旋转
-
- 8 RandomRotation
- 图像变换
-
- 9 Pad
- 10 ColorJitter 调整亮度、对比度、饱和度和色相
- 11 Grayscale、12 RandomGrayscale将图片转化为灰度图,可以设置输出通道数
- 13 RandomAffine仿射变换,旋转、平移、缩放、错切和翻转
- 15 RandomErasing 随机遮挡
- 16 Lambda 用户自定义lambda方法
- 17 Resize 18 Totensor 19 Normalize
- 四、transforms的操作,如何选择
-
-
- 20 RandomChoice 随机选择一个操作执行
- 21 RandomApply 依照概率,执行所有操作
- 22 RandomOrder 随机顺序执行所有操作
-
- 五、自定义transforms
-
- 注意
- 自定义transforms增加椒盐噪声
- 六、 数据增强实战应用
-
- RMB分类实战
- 七、作业
-
- 1
- 2.
- 1.
- 总结
tansform初体验,二十二种图像增强方法,以及图像增强的使用原则
一、transforms初体验
transforms.Compose 有序组合数据增强方法,并依次执行
train_transform = transforms.Compose([
transforms.Resize((32, 32)),#图像缩放至32*32
transforms.RandomCrop(32, padding=4),#随机裁剪
transforms.ToTensor(),#转化为张量并归一化
transforms.Normalize(norm_mean, norm_std),#标准化
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),#验证集不需要做数据增强
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
Dataset的__getitem__中调用了transform方法,每次只传入一张图片
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
进入transform.compose的__call__
def __call__(self, img):
for t in self.transforms:#循环transform.compose组合的每一个transform方法,依次执行
img = t(img)
return img
二、transforms.Normalize——逐个channel对图像进行标准化
1.步入代码查看实现
if not inplace:
tensor = tensor.clone()
dtype = tensor.dtype
mean = torch.as_tensor(mean, dtype=dtype, device=tensor.device)
std = torch.as_tensor(std, dtype=dtype, device=tensor.device)
if (std == 0).any():
raise ValueError('std evaluated to zero after conversion to {}, leading to division by zero.'.format(dtype))
if mean.ndim == 1:
mean = mean.view(-1, 1, 1)
if std.ndim == 1:
std = std.view(-1, 1, 1)
tensor.sub_(mean).div_(std)#减去均值,除以标准差
return tensor
2.原理——训练数据分布对于训练效果有影响
如图红框中,红色数据的均值为1.71+1 = 2.7 ,蓝色数据的均值为-1.71+1=-0.7,两数据的方差均为1
训练在380epoch时停止,accracy=99.5%
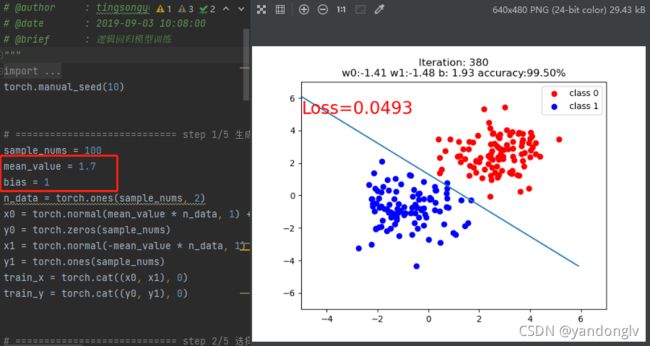
当改变数据分布,红色数据均值为1.71+5=6.7,蓝色数据为-1.71+5=3.3。
与上图相比,训练数据与(0,1)分布偏离的更远。在580epoch,accuracy=98%,可以看出接近(0,1)分布的数据更容易分类

三、二十二种图像预处理方法
数据增强:对训练集进行变换,让模型具有泛化能力
transform_invert可视化代码解读
def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):#反标准化
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
img_.mul_(std[:, None, None]).add_(mean[:, None, None])#乘以std加上mean
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C
if 'ToTensor' in str(transform_train) or img_.max() < 1:#将tensor转化为numpy
img_ = img_.detach().numpy() * 255
if img_.shape[2] == 3:#RGB图像,将numpy转化为图像
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
elif img_.shape[2] == 1:#灰度图像,将numpy转化为图像
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_#返回经过transform后的图片
Crop
1 transforms.CenterCrop
transforms.CenterCrop(112)
transforms.CenterCrop(512)#超出自动填充0
2 transforms.RandomCrop随机选择一个角进行剪切
transforms.RandomCrop(224, padding=16)#在左右方向填充16像素,上下方向填充16像素
transforms.RandomCrop(224, padding=(16, 64))#在左右方向填充16像素,上下方向填充64像素。
transforms.RandomCrop(224, padding=(16, 64,8,32))#在左方向填充16像素,上方向填充64像素,右方向填充8像素,下方向填充32像素
transforms.RandomCrop(224, padding=16, fill=(255, 0, 0))#在左右方向填充16像素,上下方向填充16像素,填充颜色为红色
transforms.RandomCrop(512, pad_if_needed=True), # pad_if_needed=True当size大于输入图片尺寸,要打开填充
transforms.RandomCrop(224, padding=64, padding_mode='edge')#边缘像素点填充
transforms.RandomCrop(224, padding=64, padding_mode='reflect')#镜像填充,最边缘像素不镜像
transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric')#镜像填充,边缘像素镜像
3 transforms.RandomCrop随机大小、长宽比裁剪图片
transforms.RandomResizedCrop(size, #所需裁剪图片尺寸
scale=(0.08, 1.0),#随机裁剪面积比例
ratio=(3/4,4/3),#随机长宽比
interpolation#插值方法
)
transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5))#长宽为224,
4 transforms.FiveCrop() 5 transforms.TenCrop()
transforms.FiveCrop(112)
transforms.TenCrop(112, vertical_flip=False)#在FiveCrop基础上反转
Flip翻转
6 RandomHorizontalFlip(),7 RandomVerticalFlip()
transforms.RandomHorizontalFlip(p=1)#概率
transforms.RandomVerticalFlip(p=0.5)
Rotation旋转
8 RandomRotation
transforms.RandomRotation(90),#旋转角度,为a时,在(-a,a), 若为(a,b), 在(a,b)之间随机选择角度旋转
transforms.RandomRotation((90), expand=True),#旋转可能会使图片不完整,打开expand,保留完整图片旋转,这会导致图片变大,使每一张图片的大小不一致,注意后面跟resize
transforms.RandomRotation(30, center=(0, 0)),
transforms.RandomRotation(30, center=(0, 0), expand=True),
图像变换
9 Pad
transforms.Pad(padding=32, fill=(255, 0, 0), padding_mode='constant'),
transforms.Pad(padding=(8, 64), fill=(255, 0, 0), padding_mode='constant'),
transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='constant'),
transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='symmetric'),
10 ColorJitter 调整亮度、对比度、饱和度和色相
transforms.ColorJitter(brightness=0.5),#亮度
transforms.ColorJitter(contrast=0.5),#对比度
transforms.ColorJitter(saturation=0.5),#饱和度
transforms.ColorJitter(hue=0.3),#色相
11 Grayscale、12 RandomGrayscale将图片转化为灰度图,可以设置输出通道数
transforms.Grayscale(num_output_channels),#num_output_channels只能是1或3
transforms.RandomGrayscale(num_output_channels,p=0.1)
13 RandomAffine仿射变换,旋转、平移、缩放、错切和翻转
transforms.RandomAffine(degrees=30),#中心旋转角度,随机(-30,30),degrees必须设置,不旋转设置为0
transforms.RandomAffine(degrees=0, translate=(0.2, 0.2), fillcolor=(255, 0, 0)),#(a=0.2,b=0.2),和RandomCrop有类似的效果
transforms.RandomAffine(degrees=0, scale=(0.7, 0.7)),#缩放比例,缩放至原图的70%,并填充整体保持大小不变
transforms.RandomAffine(degrees=0, shear=(0, 0, 0, 45)),#错切方向与角度
transforms.RandomAffine(degrees=0, shear=90, fillcolor=(255, 0, 0)),
15 RandomErasing 随机遮挡
对张量操作,
transforms.ToTensor(),#RandomErasing对张量操作
transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=(254/255, 0, 0)),#不是0,255,是0,1.所以
transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value='1234'),
16 Lambda 用户自定义lambda方法
transforms.TenCrop(200, vertical_flip=True),
transforms.Lambda(lambda crops:torch.stack([transforms.Totensor()(crop) for crop in crops]))
#lambda函数,输入为crops
#[transforms.Totensor()(crop) for crop in crops],结果为列表:从crops中取出一个crop,作transforms.Totensor()操作,形成列表。
#torch.stack()对上式的列表进行操作
17 Resize 18 Totensor 19 Normalize
四、transforms的操作,如何选择
20 RandomChoice 随机选择一个操作执行
transforms.RandomChoice([transforms.RandomVerticalFlip(p=1),
transforms.RandomHorizontalFlip(p=1)]),
21 RandomApply 依照概率,执行所有操作
transforms.RandomApply([transforms.RandomAffine(degrees=0, shear=45, fillcolor=(255, 0, 0)),
transforms.Grayscale(num_output_channels=3)], p=0.5),
22 RandomOrder 随机顺序执行所有操作
transforms.RandomOrder([transforms.RandomRotation(15),
transforms.Pad(padding=32),
transforms.RandomAffine(degrees=0, translate=(0.01, 0.1), scale=(0.9, 1.1))]),
五、自定义transforms
注意
- 仅接受一个参数,返回一个参数
- 上下游的输出和输入匹配
- 通过类实现多参数传入
class YourTransforms(object):
def __init__(self, ...):
...
def __call__(self, img):
...
return img
自定义transforms增加椒盐噪声
class AddPepperNoise(object):
"""增加椒盐噪声
Args:
snr (float): Signal Noise Rate信噪比
p (float): 概率值,依概率执行该操作
"""
def __init__(self, snr, p=0.9):#__init__定义传入的参数
assert isinstance(snr, float) and (isinstance(p, float)) # 2020 07 26 or --> and
self.snr = snr
self.p = p
def __call__(self, img):#我的任务需要对训练数据和标签同时变换,这里可以把img替换成词典{'grav': x, 'box': y}
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
if random.uniform(0, 1) < self.p:#设置一个概率
img_ = np.array(img).copy()#传入的是img数据,转化为numpy
h, w, c = img_.shape
signal_pct = self.snr
noise_pct = (1 - self.snr)
mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2., noise_pct/2.])
mask = np.repeat(mask, c, axis=2)
img_[mask == 1] = 255 # 盐噪声
img_[mask == 2] = 0 # 椒噪声
return Image.fromarray(img_.astype('uint8')).convert('RGB')#将numpy转化回img数据
else:
return img
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等,我的任务需要同时对训练数据和标签操作,
#在这里传入transform的img应该是一个词典{'grav': x, 'box': y}
return img, label
六、 数据增强实战应用
原则:让训练集与测试集更接近
RMB分类实战
训练集为第四套 RMB ,识别第五套 RMB

第一次训练采用的数据增强方法如下:
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),#随机裁剪
# transforms.RandomGrayscale(p=0.9),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
除常规方法外,仅有随机裁剪
结果:第四套正确,第五套分类全错

考虑到第五套的100元与第四套的1元颜色相似,所以在第二次训练中添加RandomGrayscale,排除颜色的干扰
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),#随机裁剪
transforms.RandomGrayscale(p=0.9),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
预测结果:全部正确
七、作业
1
采用步进(Step into)的调试方法从 for i, data in enumerate(train_loader) 这一行代码开始,进入到每一个被调用函数,直到进入RMBDataset类中的__getitem__函数,记录从 for循环到RMBDataset的__getitem__所设计的类与函数?(使用的DCDataset)
例如:
第一步:for i, data in enumerate(train_loader)
第二步:DataLoader类,iter()函数,self._get_iterator()函数
第三步: _SingleProcessDataLoaderIter类, ***函数
第四步:class _DatasetKind类,def create_fetcher函数
第五步:_MapDatasetFetcher类,
第六步:DataLoader类,__next__函数,_next_data函数
第七步:BatchSampler类,__iter__函数,
第八步:class _MapDatasetFetcher类,fetch函数,
第九步:DCDataset类,__getitem__函数
2.
训练RMB二分类模型,熟悉数据读取机制,并且从kaggle中下载猫狗二分类训练数据,自己编写一个DogCatDataset,使得pytorch可以对猫狗二分类训练集进行读取。
1.
class DCDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"cat": 0, "dog": 1}
self.data_info = self.get_img_info(data_dir)
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = DC_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
总结
- 初步了解了tansform进行数据增强的机制,并了解了Nomarlize方法的原理
- 二十二中图像增强方法,包括1、Crop、Flip、Rotation;2、Pad、ColorJitter、Grayscale、Affine、Erasing自定义Lambda函数;3、Choice随机选一个、Apply按概率随机应用一组、Order随机顺序应用一组。
- 自定义的transform,注意输入个数和格式,重写Dataset类和transform类,可以实现自己的任务
- 数据增强实战方法,观察测试集与训练集的不同,并针对训练集进行数据增强