mariadb spider存储引擎初体验
一 spider概述
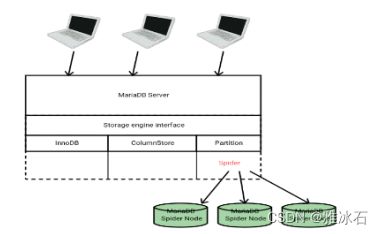
Spider存储引擎是一个具有内置分片功能的存储引擎。它支持分区和xa事务,并允许处理不同MariaDB实例的表,就像它们在同一个实例上一样。
使用Spider存储引擎创建表时,该表链接到远程服务器上的表,操作起来就像操作本地的表一样。远程表可以是任何存储引擎的表。表链接具体是通过建立从本地MariaDB服务器到远程MariaDB服务器的连接来实现的。该引擎对业务是完全透明的。
使用Spider时要设置的一些服务器变量:
MariaDB从10.3.4开始
如果在复制中使用Spider,可以通过将slave_transaction_retry_errors设置为以下值来扩展要重试的事务错误列表,以避免网络问题:
- 1158: Got an error reading communication packets
- 1159: Got timeout reading communication packets
- 1160: Got an error writing communication packets
- 1161: Got timeout writing communication packets
- 1429: Unable to connect to foreign data source
- 2013: Lost connection to MySQL server during query
- 12701: Remote MySQL server has gone away
修改my.cnf,添加:
slave_transaction_retry_errors="1158,1159,1160,1161,1429,2013,12701"
MariaDB 10.4.5及之后的版本,上述内容包括在默认值中。
先来说两个我们 DBA 经常遇到的场景:
场景 1:有两个分布在不同实例上的多张不同的表,想要通过某个字段关联,做一个统计,或者想将分布在不同实例的表,合并到一个实例中来做一些查询。
场景 2:由于数据库容量的瓶颈或者是由于数据库访问性能的瓶颈,将一某一个大库、大表或者访问量非常大的表进行拆分,然后分布到不同的实例中。
这两种场景覆盖了我们 DBA 经常接触的垂直拆分和水平拆分,在这种场景下往往面临着如下几个窘境:
1、这些表的访问和存取需要额外的路由规则,复杂度很高
2、需要做数据汇总或者统计的时候,非常麻烦
Spider 的优势:
a、对业务完全透明,业务不需要做任何的修改
b、方便横向扩展,能解决单台 mysql 得性能和存储瓶颈问题
c、对后端的存储引擎没有限制
d、间接实现垂直拆分和水平拆分功能
通过 spider 和后端的数据库连接,可以是独立的表,也可以是基于分区表,分区表支持哈希、范围、列表等算法。
e、完全兼容 mysql 协议
由于 MySQL 特殊的插件式存储引擎架构,server 层负责 SQL 解析、SQL 优化、数据库对象(视图、存储过程等)管理;存储引擎层负责数据存储、索引支持、事务、buffer 等,两者之间通过约定好的 handler 接口进行交互。SQL 解析、优化与执行交给 server 层处理,几乎支持执行任意类型 SQL 访问。
Spider 的劣势:
a、spider 的表本身不支持查询缓存和全文索引,不过可以将全文索引添加在后端数据库中;
b、如果采用物理备份,spider 无法备份后端的数据,因为数据本身是存放在后端。可以对后端的 mysql 一一做物理备份
c、spider 本身是单点,需要自己做容灾机器,比如通过 VIP 的方式
d、多了一层网络,性能上会有一些损耗,尤其是跨分区、跨表查询性能会差一些
二 安装spider
有两种方式安装:
方式1:
MariaDB [(none)]> INSTALL SONAME "ha_spider";
Query OK, 0 rows affected (0.044 sec)
方式2:
mysql -u root -p < /usr/share/mysql/install_spider.sql
#验证是否能看到spider引擎
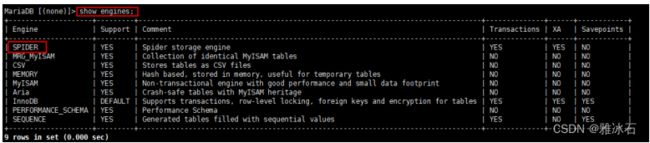
三 spider使用示例
3.1 spider节点+多个后端节点示例
实验环境:
| IP |
角色 |
备注 |
操作系统配置 |
| 192.168.144.249 |
spider节点+sysbench |
后端连接了两个节点 |
Centos 7.6 1G内存 |
| 192.168.144.250 |
Backend1 |
后端节点1 |
|
| 192.168.144.251 |
Backend2 |
后端节点2 |
3.1.1 在后端节点上建表
#在两个后端节点上建表
CREATE DATABASE backend;
CREATE TABLE backend.sbtest1 (
id int(10) unsigned NOT NULL AUTO_INCREMENT,
k int(10) unsigned NOT NULL DEFAULT '0',
c char(120) NOT NULL DEFAULT '',
pad char(60) NOT NULL DEFAULT '',
PRIMARY KEY (id),
KEY k (k)
) ENGINE=InnoDB;
3.1.2 在spider节点上建表
3.1.2.1 建server
CREATE SERVER backend1
FOREIGN DATA WRAPPER mysql
OPTIONS(
HOST '192.168.144.250',
DATABASE 'backend',
USER 'root',
PASSWORD '123456',
PORT 3306
);
CREATE SERVER backend2
FOREIGN DATA WRAPPER mysql
OPTIONS(
HOST '192.168.144.251',
DATABASE 'backend',
USER 'root',
PASSWORD '123456',
PORT 3306
);
select * from mysql.servers;

3.1.2.2 建表
CREATE DATABASE IF NOT EXISTS backend;
CREATE TABLE backend.sbtest1
(
id int(10) unsigned NOT NULL AUTO_INCREMENT,
k int(10) unsigned NOT NULL DEFAULT '0',
c char(120) NOT NULL DEFAULT '',
pad char(60) NOT NULL DEFAULT '',
PRIMARY KEY (id),
KEY k (k)
) ENGINE=spider COMMENT='wrapper "mysql", table "sbtest1"'
PARTITION BY KEY (id)
(
PARTITION pt1 COMMENT = 'srv "backend1"',
PARTITION pt2 COMMENT = 'srv "backend2"'
) ;
3.1.3 验证分片
#在spider节点上插入数据
MariaDB [(none)]> use backend;
MariaDB [backend]> insert into sbtest1(id,k,c,pad) values(1,1,'a','a');
Query OK, 1 row affected (0.006 sec)
MariaDB [backend]> insert into sbtest1(id,k,c,pad) values(2,2,'a','a');
Query OK, 1 row affected (0.007 sec)
select * from backend.sbtest1;
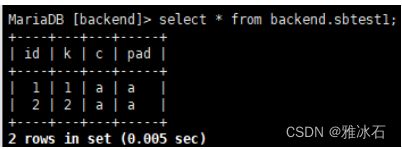
#在后端节点上查询,发现两条数据分布在两个后端节点上了
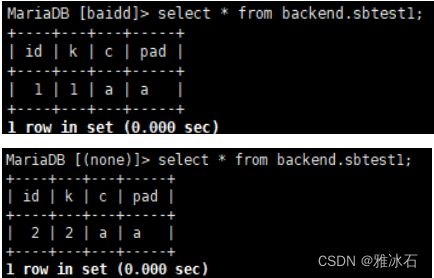
/*
测试过程中发现10.3.18版本的spider不稳定,select *及count(*)的结果不准确,有时是汇总后的数据,有时是第一个节点的数据,有时是第二个节点的数据,不知道是什么情况。
这数据怪得很。
我在10.5.7版本上测试的倒是没发现这个问题。
*/

本篇文章参考了Spider - MariaDB Knowledge Base
Spider 引擎分布式数据库解决方案(最全的 spider 教程) - 云+社区 - 腾讯云
来了,腾讯游戏分布式数据库TenDB Cluster开源啦_老叶茶馆_的博客-CSDN博客
Spider Use Cases - MariaDB Knowledge Base