深度学习与CV教程(10) | 轻量化CNN架构 (SqueezeNet,ShuffleNet,MobileNet等)
优质资源分享
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| Python实战微信订餐小程序 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| Python量化交易实战 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |

- 作者:韩信子@ShowMeAI
- 教程地址:http://www.showmeai.tech/tutorials/37
- 本文地址:http://www.showmeai.tech/article-detail/269
- 声明:版权所有,转载请联系平台与作者并注明出处
- 收藏ShowMeAI查看更多精彩内容
前言
卷积神经网络的结构优化和深度加深,带来非常显著的图像识别效果提升,但同时也带来了高计算复杂度和更长的计算时间,实际工程应用中对效率的考虑也很多,研究界与工业界近年都在努力「保持效果的情况下压缩网络复杂度」,也诞生了很多轻量化网络。在本篇内容中,ShowMeAI对常见主流轻量级网络进行展开讲解。
本篇重点
- 神经网络参数与复杂度计算
- 轻量化网络
- SqueezeNet
- Xception
- ShuffleNet V1~V2
- MobileNet V1~V3
1.基础知识
我们先来做一点基础知识储备,本篇讲到的轻量化CNN框架,我们需要了解参数量和计算量的估测与计算方式。
1.1 复杂度分析
- 理论计算量(FLOPs):浮点运算次数(FLoating-point Operation)
- 参数数量(params):单位通常为 MMM,用 float32 表示。
1.2 典型结构对比
- 标准卷积层 std conv(主要贡献计算量)
- params:kh×kw×cin×coutkh×kw×cin×coutk_h\times k_w\times c_{in}\times c_{out}
- FLOPs:kh×kw×cin×cout×H×Wkh×kw×cin×cout×H×Wk_h\times k_w\times c_{in}\times c_{out}\times H\times W
- 全连接层 fc(主要贡献参数量)
- params:cin×coutcin×coutc_{in}\times c_{out}
- FLOPs:cin×coutcin×coutc_{in}\times c_{out}
- group conv
- params:(kh×kw×cin/g×cout/g)×g=kh×kw×cin×cout/g(kh×kw×cin/g×cout/g)×g=kh×kw×cin×cout/g(k_h\times k_w\times c_{in}/g \times c_{out}/g)\times g=k_h\times k_w\times c_{in}\times c_{out}/g
- FLOPs:kh×kw×cin×cout×H×W/gkh×kw×cin×cout×H×W/gk_h\times k_w\times c_{in}\times c_{out}\times H\times W/g
- depth-wise conv
- params:kh×kw×cin×cout/cin=kh×kw×coutkh×kw×cin×cout/cin=kh×kw×coutk_h\times k_w\times c_{in}\times c_{out}/c_{in}=k_h\times k_w\times c_{out}
- FLOPs:kh×kw×cout×H×Wkh×kw×cout×H×Wk_h\times k_w\times c_{out}\times H\times W
2.SqueezeNet
轻量化网络中一个著名的网络是 SqueezeNet ,它发表于ICLR 2017,它拥有与 AlexNet 相同的精度,但只用了 AlexNet 1/50 的参数量。
SqueezeNet 的核心在于采用不同于常规的卷积方式来降低参数量,具体做法是使用 Fire Module,先用 1×11×11 \times 1 卷积降低通道数目,然后用 1×11×11 \times 1 卷积和 3×33×33 \times 3 卷积提升通道数。
2.1 压缩策略
SqueezeNet 采用如下3个策略:
- ① 将 3×33×33 \times 3 卷积替换为 1×11×11 \times 1 卷积
- ② 减少 3×33×33 \times 3 卷积的通道数
- ③ 将降采样操作延后,这样可以给卷积提供更大的 activation map,从而保留更多的信息,提供更高的分类准确率。
其中,策略1和2可以显著减少模型参数量,策略3可以在模型参数量受限的情况下提高模型的性能。
2.2 Fire Module
Fire Module是SqueezeNet网络的基础模块,设计如下图所示:
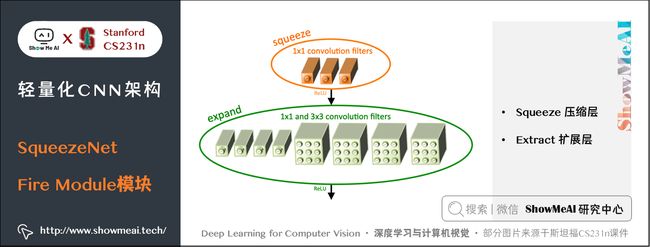
一个 Fire Module 由 Squeeze 和 Extract 两部分组成:
- Squeeze 部分包括了一系列连续的 1×11×11 \times 1 卷积
- Extract 部分包括了一系列连续的 1×11×11 \times 1 卷积和一系列连续的 3×33×33 \times 3 卷积,然后将 1×11×11 \times 1 和 3×33×33 \times 3 的卷积结果进行concat。
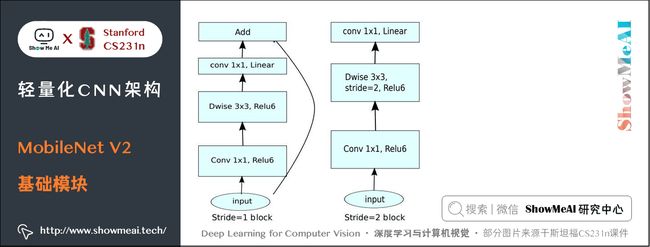
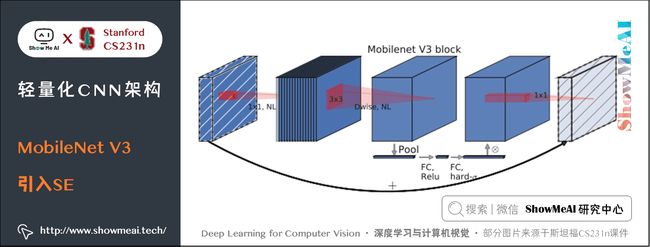
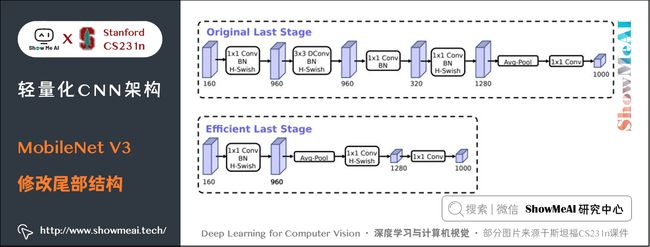
记 Squeeze 部分的通道数为 Cs1×1Cs1×1C_{s{1\times 1}},Extract部分 1×11×11 \times 1 和 3×33×33 \times 3 的通道数分别为 Ce1×1Ce1×1C_{e{1\times 1}} 和 Ce3×3Ce3×3C_{e{3\times 3}},作者建议 Cs1×1 在Fire Module的基础上搭建SqueezeNet神经网络。它以卷积层开始,后面是 8 个 Fire Module,最后以卷积层结束,每个 Fire Module 中的通道数目逐渐增加。另外网络在 conv1,fire4,fire8,conv10的后面使用了 max-pooling。 SqueezeNet 结构如下图所示,左侧是不加 shortcut 的版本,中间是加了 shortcut 的版本,右侧是在不同通道的特征图之间加入 shortcut 的版本。 SqueezeNet的性能类似于AlenNet,然而参数量只有后者的1/50,使用Deep Compression可以进一步将模型大小压缩到仅仅有0.5M。 SqueezeNet 缺点如下: 另一个需要提到的典型网络是 Xception,它的基本思想是,在 Inception V3 的基础上,引入沿着通道维度的解耦合,基本不增加网络复杂度的前提下提高了模型的效果,使用Depthwise Seperable Convolution实现。 Xception虽然不是出于轻量级的考虑而设计的模型,但是由于使用了pointwise convolution和depthwise convolution的结合,实际上也起到了降低参数量的效果,我们也放在轻量模型里做个介绍。 卷积在 HWC(高 ××\times 宽 ××\times 通道数)这3个维度上进行学习,既考虑空间相关性,又考虑通道相关性,可以考虑这两种相关性解耦分开。 Xception 的做法是使用 point-wise convolution 考虑 cross-channel correlation,使用 depthwise convolution 考虑 spatial correlation。 下图是一个 Inception V3 的基础模块,分别用 1×11×11 \times 1 卷积和 3×33×33 \times 3 卷积考虑通道相关性和空间相关性,基本结构是用 1×11×11 \times 1 卷积降维,用 3×33×33 \times 3 卷积提取特征: 如果将上述结构简化,则可以得到如下的结构,可见每一个分支都包含了一个 1×11×11 \times 1 卷积和一个 3×33×33 \times 3 卷积: 从上图中可见,对于每一个分支,该模块使用 1×11×11 \times 1 卷积对输入特征图进行处理,然后使用 3×33×33 \times 3 卷积提取特征。 如果考虑空间相关性和通道相关性的解耦合,即用同一个 1×11×11 \times 1 卷积进行通道处理,将处理结果沿着通道维度拆解为若干部分,对于每一部分使用不同的 3×33×33 \times 3 卷积提取特征,则得到如下图所示的模块: 考虑一种更为极端的情况,在使用 1×11×11 \times 1 卷积之后,沿着通道维度进行最为极端的拆解,对于拆解后的每一个部分使用 3×33×33 \times 3 卷积提取特征,这一步可以使用 depthwise convolution 实现,最后将这些提取到的特征图进行 concat,这就是 Xception 的基础模块,如下图所示: 通过上图可以看到,该模块将输入数据在「通道维度」上解耦,我们称之为 extreme version of inception module。这点与 depthwise seperable convolution 很相似。 这一操作与 Depthwise Seperable Convolution 十分相似,后者包含 Depthwise Convolution 和 Pointwise Convolution 两部分。 上图所示的基础模块与 Depthwise Seperable Convolution 有如下两点不同: 在 Xception 中,作者直接使用了 Depthwise Seperable Convolution 作为基础模块。 最后将这一基础模块叠加,并结合残差连接,就得到了Xception网络结构: ShuffleNet 是由旷世科技提出的轻量化CNN网络,论文名称《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices》,目标是改造网络架构使其能应用在移动设备上。 ShuffleNet的动机在于大量的 1×11×11 \times 1 卷积会耗费很多计算资源,而 Group Conv 难以实现不同分组之间的信息交流;ShuffleNet 的解决方式是:使用 Group Conv 降低参数量;使用Channel Shuffle实现不同组之间的信息交流,进而对ResNet进行改进,可以看作ResNet的压缩版本。 我们再来看看Group Conv这个结构,它的基本思想是对输入层的不同特征图进行分组,再使用不同的卷积核对不同组的特征图进行卷积,通过分组降低卷积的计算量。 而Depthwise Convolution可以视作Group Conv的一种特殊情形。 假设输入通道为 CiCiC_i,输出通道为 CoCoC_o,分组数目为 ggg,Group Conv的操作如下: Group Conv 的一个缺点在于不同组之间难以实现通信。一个可能的解决方式是使用 1×11×11 \times 1 卷积进行通信,但是这样会引入很大的计算量。 文中提出的思路是对 Group Conv 之后的特征图沿着通道维度进行重组,这样信息就可以在不同组之间流转,即 Channel Shuffle,如下图©所示。 其实现过程如下: 结合 Group Conv 和 Channel Shuffle,对ResNet的基础模块bottleneck(下图(a))进行改进,就得到了 ShuffleNet 的基础模块(下图(b)和©) 在 ShuffleNet 之后又有改进的版本 ShuffleNet V2,改进了上述提到的 ShuffleNet 缺点,减少其耗时。 ShuffleNet的轻量级网络设计,FLOPs 减少了很多,但实际的时间消耗并不短。原因是网络训练或者推理的过程中,FLOPs 仅仅是其耗时的一部分,其他操作(如内存读写、外部数据 IO 等)也会占用时间。 ShuffleNet V2 的作者分析了几种网络结构在 GPU/ARM 这两种平台上的计算性能指标,并提出了4条移动端卷积网络设计的准则,根据这些准则改进 ShuffleNet 得到了 ShuffleNet V2。 我们先来看看这4条移动端网络设计准则: 使用的指标是内存访问时间(Memory Access Cost, MAC)。用理论和实验说明了以下几条准则。 理论推导:假设 1×11×11 \times 1 卷积的输入通道数目为 c1c1c_1,输出通道数目为 c2c2c_2,特征图大小为 h×wh×wh\times w,则这样一个 1×11×11 \times 1 卷积的 FLOPs 为: B=hwc1c2B=hwc1c2B=hwc_1 c_2 MAC=hw(c1+c2+c1c2)MAC=hw(c1+c2+c1c2)MAC = hw(c_1 + c_2 + c_1 c_2) MAC≥2hwB−−−−√+BhwMAC≥2hwB+BhwMAC \ge 2 \sqrt {hwB} + \frac {B}{hw} 理论推导:带 group 的 1×11×11 \times 1 卷积的FLOPs如下,其中 ggg 表示分组数目: B=hwc1c2gB=hwc1c2gB = \frac{hwc_1c_2}{g} MAC=hw(c1+c2+c1c2g)MAC=hw(c1+c2+c1c2g)MAC = hw(c_1 + c_2 + \frac {c_1c_2}{g} ) MAC=hw(c1+c2+c1c2g=hwc1+Bgc1+BhwMAC=hw(c1+c2+c1c2g=hwc1+Bgc1+Bhw\begin{aligned} 实验证明:在FLOPs基本不变的操作下,group越大,速度越慢,如下图所示。 实验证明:fragment 表示碎片化程度的量化,serious 表示串行,即几个卷积层的叠加,parallel 表示并行,即类似于 Inception 的设计。可见在 FLOPs 不变的情况下,分支数量越多,网络的实际耗时越大。 element-wise 操作虽然基本不增加 FLOPs,但是在 ShuffleNet V1 和 MobileNet V2 中,其耗时是十分可观的,如下图: 实验证明:基于 ResNet 的 bottleneck 进行了实验,short-cut 是一种 element-wise 操作。实验证明short-cut 操作会带来耗时的增加。 基于前面提到的4条准则,对 ShuffleNet 的基础模块(下图(a)(b))进行修改,得到 ShuffleNet V2 的基础模块(下图中©(d)): 图中 © 和 (a) 相比,有如下不同之处: (b)、(d) 之间的区别也类似,另外(d) 的两个分支都进行了降采样,且最初没有 Channel Split 操作,因此 Concat 之后的通道数目翻倍。 上述 ShuffleNet V2 基础模块级联,配合卷积、池化等衔接,就得到了如下图的 ShuffleNet V2 结构: 另外一个非常有名的轻量化移动端网络是 MobileNet,它是专用于移动和嵌入式视觉应用的卷积神经网络,是基于一个流线型的架构,使用深度可分离的卷积来构建轻量级的深层神经网络。 MobileNet 凭借其优秀的性能,广泛应用于各种场景中,包括物体检测、细粒度分类、人脸属性和大规模地理定位。 MobileNet有 V1 到 V3 不同的版本,也逐步做了一些优化和效果提升,下面我们来分别看看它的细节。 MobileNet V1 的核心是将卷积拆分成 Depthwise Conv 和 Pointwise Conv 两部分,我们来对比一下普通网络和MobileNet的基础模块 MobileNet V2 针对 MobileNet 的上述2个问题,引入了 Inverted Residual 和 Linear Bottleneck对其进行改造,网络为全卷积,使用 RELU6(最高输出为6)激活函数。下面我们展开介绍一下核心结构: 我们对比一下普通残差模块和Inverted Residual的差别 先使用 1×11×11 \times 1 卷积降低通道数量,然后使用 3×33×33 \times 3 卷积提取特征,之后使用 1×11×11 \times 1 卷积提升通道数量,最后加上残差连接。整个过程是「压缩-卷积-扩张」。 先使用 1×11×11 \times 1 卷积提升通道数量,然后使用 3×33×33 \times 3 卷积提取特征,之后使用 1×11×11 \times 1 卷积降低通道数量,最后加上残差连接。整个过程是「扩张-卷积-压缩」。 对比两个结构块如下图所示: 相比于 MobileNet 的基础模块,MobileNet V2 在 Depthwise Convolution 的前面加了一个 1×11×11 \times 1 卷积,使用 ReLU6 代替 ReLU,且去掉了第二个 1×11×11 \times 1 卷积的激活函数(即使用线性的激活函数),防止 ReLU 对特征的破坏。 使用上述的方法对 MobileNet 的基础模块进行改进,得到如下所示的 MobileNet V2 基础模块: 在 MobileNet V2 的基础上,又提出了MobileNet V3,它的优化之处包括:引入了 SE、尾部结构改进、通道数目调整、h-swish 激活函数应用,NAS 网络结构搜索等。我们来逐个看一下: MobileNet V3 在 bottleneck 中引入了 SE 结构,放在 Depthwise Convolution 之后,并且将 Expansion Layer 的通道数目变为原来的 1/41/41/4 ,在提升精度的同时基本不增加时间消耗。 MobileNet V3对尾部结构做了2处修改,从下图中「上方结构」修改为「下方结构」: 相比于 MobileNet V2,MobileNet V3 对头部卷积通道数目进行了进一步的降低。 MobileNet V3 采用了 h−swishh−swish\mathbf{h-swish} 激活函数,对应的 swishswish\mathbf{swish} 和 h−swishh−swish\mathbf{h-swish} 激活函数计算公式如下: swish[x]=x⋅σ(x)swish[x]=x⋅σ(x)\mathbf{swish}[x] = x \cdot \sigma(x) MobileNet V3 先用 NAS 搜索各个模块,得到大致的网络结构,相当于整体结构搜索;然后用NASAdapt得到每个卷积层的通道数目,相当于局部搜索。2.3 网络结构
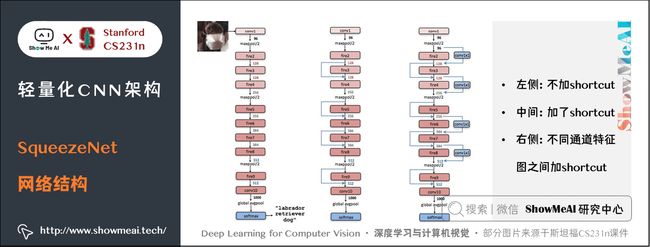
2.4 SqueezeNet缺点
3.Xception
3.1 设计动机
3.2 从Inception到Extreme version of Inception
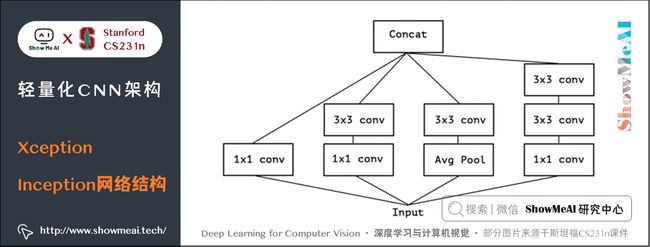
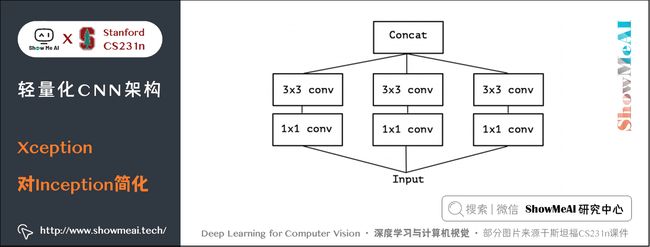
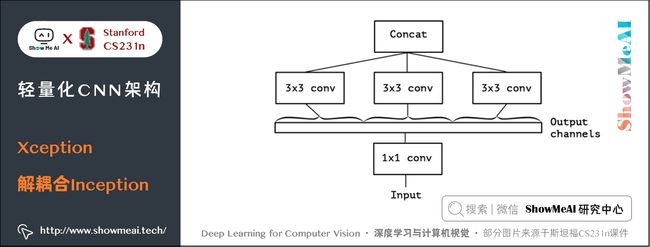
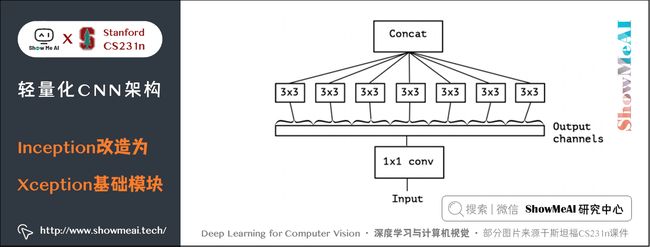
3.3 Extreme version of Inception与Depthwise Seperable Convolution
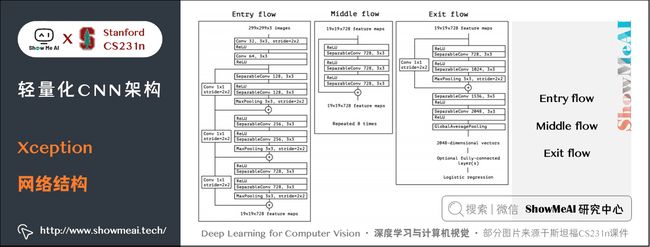
3.4 Xception网络结构
4.ShuffleNet
4.1 设计动机
4.2 Group Conv
4.3 Channel Shuffle
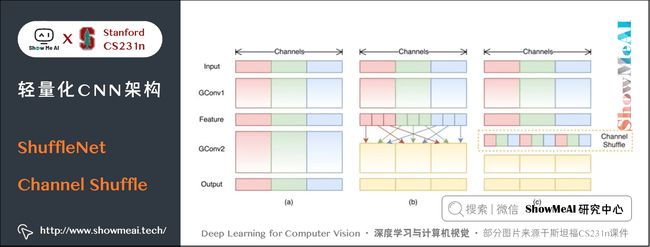
4.4 ShuffleNet基础模块
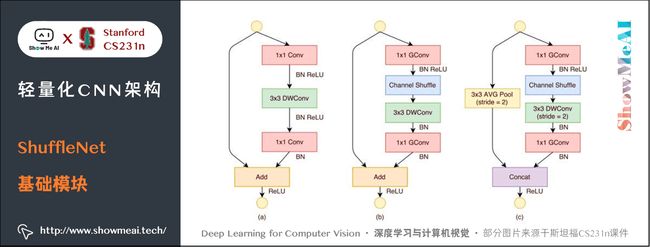
4.5 ShuffleNet缺点
5.ShuffleNet V2
5.1 设计动机
5.2 高效CNN设计的几个准则
1) 输入输出通道数目相同时,卷积层所需的MAC最小。
所需的存储空间如下,其中 hwc1hwc1hwc_1 表示输入特征图所需空间, hwc2hwc2hwc_2 表示输出特征图所需空间, c1c2c1c2c_1c_2 表示卷积核所需空间:
根据均值不等式可得:
等式成立的条件是 c1=c2c1=c2c_1 = c_2,即在给定 FLOPs,输入特征通道数和输出特征通道数相等时,MAC 达到取值的下界。 实验证明:c1c1c_1和c2c2c_2越接近、速度越快,如下表。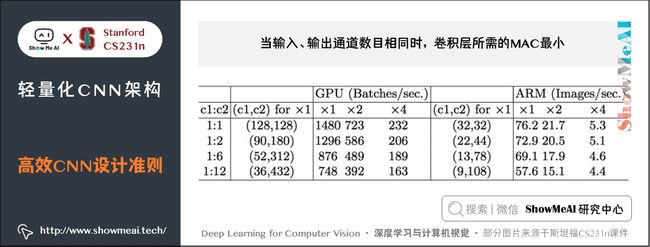
2) 过多的group操作会增大MAC
MAC 如下:
因此:
MAC &= hw(c_1 + c_2 + \frac {c_1c_2}{g} \
& =hwc_1 + \frac {Bg} {c_1} + \frac {B} {hw}
\end{aligned}
可见,在一定 FLOPs 的情况下,分组数目 ggg 越大,MAC 也越大。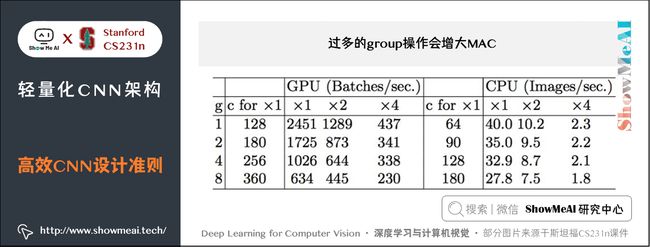
3) 模型的碎片化程度越低,模型速度越快
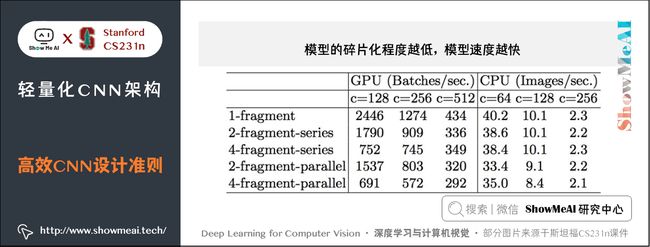
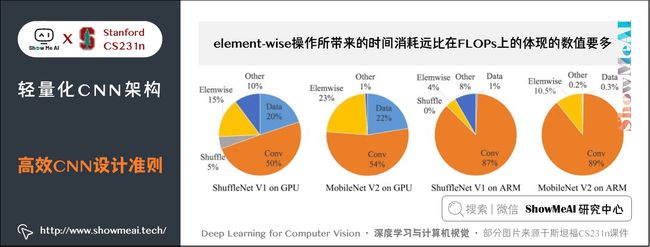
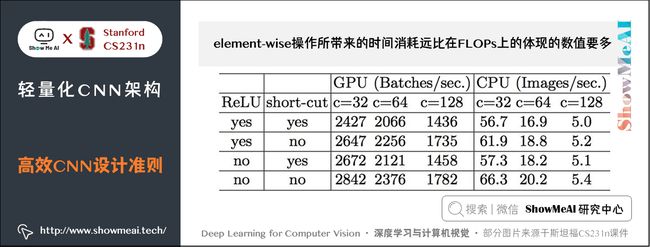
4) element-wise操作所带来的时间消耗远比在FLOPs上的体现的数值要多。
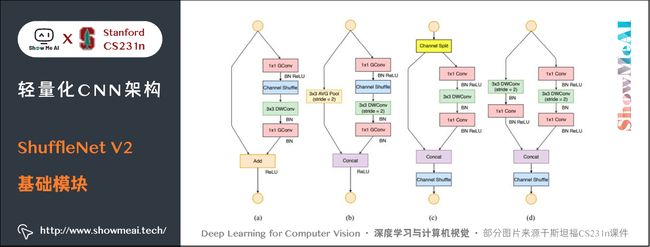
5.3 ShuffleNet V2基础模块
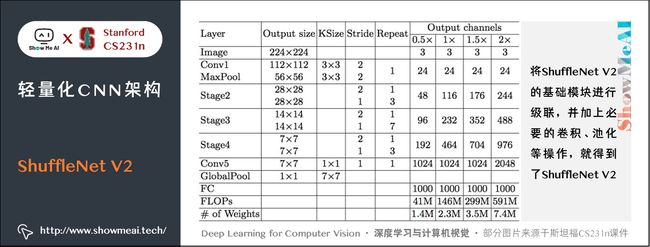
5.4 ShuffleNet V2整体结构
6.MobileNet
6.1 MobileNet核心思想

6.2 MobileNet缺点
7.MobileNet V2
7.1 Inverted Residual
1) 普通残差模块
2) Inverted Residual
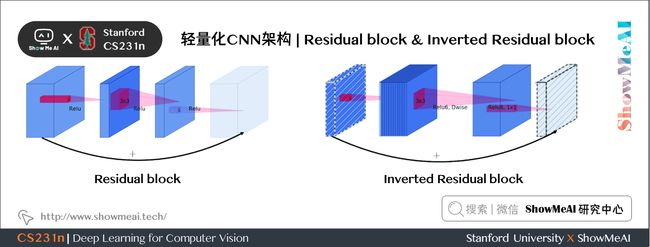
7.2 Linear Bottleneck
7.3 MobileNet V2基础模块
8.MobileNet V3
8.1 SE结构
8.2 尾部结构改进
8.3 通道数目调整
8.4 h-swish激活函数
h−swish[x]=xReLU6(x+3)6h−swish[x]=xReLU6(x+3)6\mathbf{h-swish}[x] = x \frac {\mathbf{ReLU6}(x + 3)}{6}8.5 NAS网络结构搜索
9.参考资料
10.要点总结
斯坦福 CS231n 全套解读
ShowMeAI 系列教程推荐
