内存管理(1)物理内存描述
/*尊重知识,谢绝盗版!本博文大量借鉴了linux内核社区的成果,再次归纳,转载烦请以超链接的方式标注来源http://blog.csdn.net/figtingforlove/article/details/20212525*/
(1)物理内存相关概念
1.UMA 和NUMA模型
UMA (uniform memory access,一致内存访问)模型,SMP系统中的内存以连续的方式组织起来(可能物理上有空洞),但所有cpu对内存的访问具有相同的速度。
NUMA (no-uniform memory access,非一致内存访问)模型,SMP系统中的各个cpu都有本地内存,cpu之间通过总线连接,以支持对其他cpu的本地内存的访问。与UMA模型不同,各cpu访问本地内存的速度要快于访问其它cpu的本地内存(要通过cpu互联总线传输)。
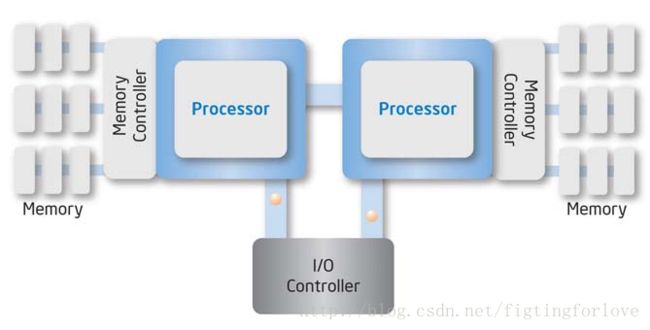
图两个cpu的NUMA视图
图2 两种内存模型视图
2.物理内存的描述
Linux将物理内存按固定大小的页面(一般为4K)划分内存,在内核初始化时,会建立一个全局struct page结构数组mem_map[ ]。如系统中有76G物理内存,则物理内存页面数为76*1024*1024k/4K= 19922944个页面,mem_map[ ]数组大小19922944,即为数组中每个元素和物理内存页面一一对应,整个数组就代表着系统中的全部物理页面。
Linux将NUMA中内存访问速度一致的部分(例如cpu本地内存)称为一个节点(Node),用struct pglist_data数据结构表示,通常使用时用它的typedef定义pg_data_t。系统中的每个结点都通过pgdat_list链表pg_data_t->node_next连接起来,该链接以NULL为结束标志。每个结点又进一步分为许多块,称为区域(zones)。区域表示内存中的一块范围,这是对内存的进一步细化。区域用struct zone_struct数据结构表示,它的typedef定义为zone_t。每个区域(Zone)中有多个页面(Pages)组成。
UMA系统可以当做只使用NUMA的一个节点来管理内存,下面我们看看内核是如何描述这几种数据结构的
3.物理内存内核数据结构
linux/mm_zone.h
结点
723 typedef struct pglist_data {
724 struct zone node_zones[MAX_NR_ZONES];// 节点中的各个内存域,在x86中有,ZONE_HIGHMEM,ZONE_NORMAL,ZONE_DMA;x86_64 CPU中区域有DMA、DMA32和NORMAL三部分。总是有三个项,不足的项填0
725 struct zonelist node_zonelists[MAX_ZONELISTS]; //备用节点及其内存域的链表,NUMA该节点的内存分配完之后,会在备用节点分配内存
726 int nr_zones; //不同内存域的数目,值的范围为1~3;并不是所有的结点都有三个区域;
727 #ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */ /*平坦模型*/
728 struct page *node_mem_map; //该结点的第一页面在全局变量mem_map数组中地址
729 #ifdef CONFIG_MEMCG
730 struct page_cgroup *node_page_cgroup;
731 #endif
732 #endif
733 #ifndef CONFIG_NO_BOOTMEM
734 struct bootmem_data *bdata; //系统启动期间,内存子系统初始化之前,内核也需要内存。在系统启动分配内存时使用,指向自举内存分配器实例结构
735 #endif
/*省略*/
749 unsigned long node_start_pfn; //该结点的起始物理页面号,UMA中为0
750 unsigned long node_present_pages; /* total number of physical pages */ /*以页帧为单位计算*/
751 unsigned long node_spanned_pages; /* total size of physical page
752 range, including holes */ /*实际可用的物理页帧数*/
753 int node_id; //结点ID,从0开始
/*省略*/
773 } pg_data_t;925 /** 926 * for_each_online_pgdat - helper macro to iterate over all online nodes 927 * @pgdat - pointer to a pg_data_t variable 928 */ 929 #define for_each_online_pgdat(pgdat) \ 930 for (pgdat = first_online_pgdat(); \ 931 pgdat; \ 932 pgdat = next_online_pgdat(pgdat))
域
一个节点可以有多个不同类型的域
261 enum zone_type {
262 #ifdef CONFIG_ZONE_DMA
263 /* DMA区,体系结构相关,有限制
278 * i386, x86_64 and multiple other arches
279 * <16M.
280 */
281 ZONE_DMA,
282 #endif
283 #ifdef CONFIG_ZONE_DMA32
284 /*32位为0,64位才有效,32位地址可寻址的DMA区,在x86-64架构中,这部分的区域范围为0~4GB*/
289 ZONE_DMA32,
290 #endif
291 /*可内核直接映射到线性地址。这部分区域仅表示可能存在这部分区域,如在64位系统中,若系统只有4GB物理内存,则所有的物理内存都属于ZONE_DMA32,而ZONE_NORMAL区域为空*/
296 ZONE_NORMAL,
297 #ifdef CONFIG_HIGHMEM
298 /*高端内存区,因为内核的地址空间有限,这部分内存无法直接映射到内核,对于该区的每个物理页都要内核来映射去维护一个页表项用于地址访问*/
306 ZONE_HIGHMEM,
307 #endif
308 ZONE_MOVABLE,
309 __MAX_NR_ZONES
310 };地址空间划分时,三种类型的区域如下:
ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~ 结束
4G(内核空间)/4G(用户空间)地址空间划分时,三种类型区域划分为:
ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~3968MB
ZONE_HIGHMEM 3968MB ~ 结束
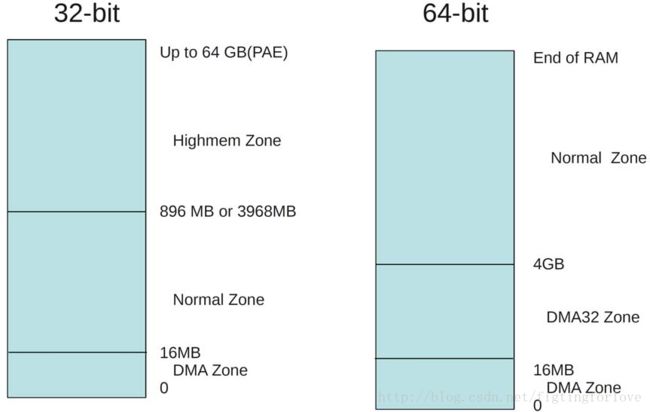
图 32位和64位系统中内存区域划分
在64位Linux系统中,内存只有三个区域DMA、DMA32和NORMAL
ZONE_DMA 内存开始的16MB
ZONE_DMA32 16MB~4GB
ZONE_NORMAL 4GB ~ 结束
314 struct zone {
/*。。。*/
/*用于关键性任务,为该域指定了若干页,保证在任何条件下,申请内存都不会失败;,*/
335 unsigned long lowmem_reserve[MAX_NR_ZONES];
336
/*cpu的冷热页列表,对应的高速缓存状态不同*/
351 struct per_cpu_pageset __percpu *pageset;
352 /*
353 * free areas of different sizes
354 */
355 spinlock_t lock; //spinlock防止对区域的并发访问
/*。。。*/
368 struct free_area free_area[MAX_ORDER];//空闲页管理,用于伙伴系统的实现(buddy分配器使用的空闲区域位图)
369 /*。。。*/
388
389 ZONE_PADDING(_pad1_)
390
391 /* Fields commonly accessed by the page reclaim scanner */
392 spinlock_t lru_lock;
393 struct lruvec lruvec;
394
395 unsigned long pages_scanned; /* since last 回收以来扫描过的页 */
396 unsigned long flags; /* zone flags*/
397
398 /* Zone statistics */
399 atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
400
/*。。。。*/
/*填充字段,保证每个自旋锁处于自身的缓冲行*/
408 ZONE_PADDING(_pad2_)
435 wait_queue_head_t * wait_table; //等待空闲页面的进程等待队列
436 unsigned long wait_table_hash_nr_entries;
437 unsigned long wait_table_bits;
438
439 /*
440 * Discontig memory support fields.
441 */
442 struct pglist_data *zone_pgdat; //指向所在父亲pg_data_t结构
443 /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
444 unsigned long zone_start_pfn; //该区域结点的起始物理页面号
445
488 unsigned long spanned_pages; //该节点中所有物理页面数,包括内存空洞
489 unsigned long present_pages; //实际该结点中的总共页面数
490 unsigned long managed_pages;
491
492 /*
493 * rarely used fields:
494 */
495 const char *name; //区域的名字,“DMA“,“DMA32”,”Normal“,“HighMem”
496 } ____cacheline_internodealigned_in_smp;//编译器关键字实现最优的缓存行对齐方式页帧(page)
内存由固定的块组成,称为页帧,每个页帧由struct page结构描述。内核在初始化时,会根据内存的大小计算出由多少页帧,每个页帧都会有一个page结构与之对应,这些信息保存在全局数组变量mem_map中。mem_map通常存储在ZONE_NORMAL区域中,在内存较小的机器中,会保存在加载内核镜像后的一片保留空间里。有多少个物理页面,就会有多个struct page结构,如系统安装128GB物理内存,struct page结构体大小为40字节,则mem_map[ ]数组就占用物理内存大小为128*1024*1024k/4k * 40 = 1280MB,即Linux内核要使用1280MB物理内存来保存mem_map[ ]数组,这部分内存是不可被使用的。因此struct page结构体大小不能设计很大。
linux/mm_types.h
44 struct page {
45 /* First double word block */
46 unsigned long flags; /* 描述页面状态的标志,包括PG_locked、PG_error、PG_referenced、PG_active、PG_dirty、PG_lru 等*/
48 union {
49 struct address_space *mapping; /*当文件或者设备映射到内存中时,它们的inode结构就会和address_space相关联。当页面属于一个文件时,mapping就会指向这个地址空间。
*如果这个页面是匿名的且映射开启,则address_space就是swapper_space,swapper_space是管理交换地址空间的。
*/
56 void *s_mem; /* 用于slub分配器 */
57 };
58
59 /* Second double word */
60 struct {
61 union {
62 pgoff_t index; /* 这个值有两个用处,具体用处取决于页面的状态。若页面是属于一个文件的映射,则index是该页面在文件中的偏移量。
*若页面是交换缓冲区的一部分,则index是页面在address_space交换地址空间的偏移量(swapper_space)。
*另外,当一些页面被一个进程回收时,该回收区域的级别(2的幂次方数量回收的页面)保存在index中 */
63 void *freelist; /* 用于slub分配器*/
64 bool pfmemalloc; /**/
73 };
74
75 union {
89 struct {
90
91 union {
108 atomic_t _mapcount; //页面表总共有多少项指向该页面
109 /*用于slub分配器*/
110 struct { /* SLUB */
111 unsigned inuse:16;
112 unsigned objects:15;
113 unsigned frozen:1;
114 };
115 int units; /* SLOB */
116 };
117 atomic_t _count; /* 引用该页面的计数。当该值达到0时,页面可以被回收。当大于0时,意味着有一个或多个进程正在使用该页面 */
118 };
119 unsigned int active; /* SLAB */
120 };
121 };
122
123 /* Third double word block */
124 union {
125 struct list_head lru; /* Pageout list, eg. active_list
126 * protected by zone->lru_lock !
127 */
128 struct { /* slub per cpu partial pages */
129 struct page *next; /* Next partial slab */
130 #ifdef CONFIG_64BIT
131 int pages; /* Nr of partial slabs left */
132 int pobjects; /* Approximate # of objects */
133 #else
134 short int pages;
135 short int pobjects;
136 #endif
137 };
138
139 struct list_head list; /* slobs list of pages */
140 struct slab *slab_page; /* slab fields */
141 struct rcu_head rcu_head; /* Used by SLAB
142 * when destroying via RCU
143 */
148
149 /* Remainder is not double word aligned */
150 union {
151 unsigned long private;
164 #endif
165 struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
166 struct page *first_page; /* Compound tail pages */
167 };
179 #if defined(WANT_PAGE_VIRTUAL)
180 void *virtual; /* Kernel virtual address (NULL if
181 not kmapped, ie. highmem) */
/*...*/
198 }1.高端内存的由来
当内核模块代码或线程访问内存时,代码中的内存地址都为逻辑地址,而对应到真正的物理内存地址,需要地址一对一的映射,如逻辑地址0xc0000003对应的物理地址为0×3,0xc0000004对应的物理地址为0×4,… …,逻辑地址与物理地址对应的关系为
物理地址 = 逻辑地址 – 0xC0000000
假设按照上述简单的地址映射关系,那么内核逻辑地址空间访问为0xc0000000 ~ 0xffffffff,那么对应的物理内存范围就为0×0 ~ 0×40000000,即只能访问1G物理内存。若机器中安装8G物理内存,那么内核就只能访问前1G物理内存,后面7G物理内存将会无法访问,因为内核的地址空间已经全部映射到物理内存地址范围0×0 ~ 0×40000000。即使安装了8G物理内存,那么物理地址为0×40000001的内存,内核该怎么去访问呢?代码中必须要有内存逻辑地址的,0xc0000000 ~ 0xffffffff的地址空间已经被用完了,所以无法访问物理地址0×40000000以后的内存。
显然不能将内核地址空间0xc0000000 ~ 0xfffffff全部用来简单的地址映射。因此x86架构中将内核地址空间划分三部分:ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM。ZONE_HIGHMEM即为高端内存,这就是内存高端内存概念的由来。
在x86结构中,三种类型的区域如下:ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~ 结束
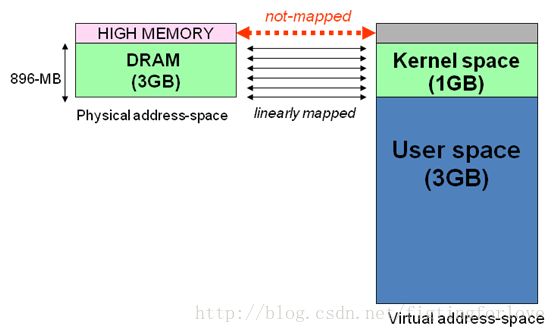
2.高端内存的理解
前面我们解释了高端内存的由来。 Linux将内核地址空间划分为三部分ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,高端内存HIGH_MEM地址空间范围为0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)。那么如内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存?
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。如下图。
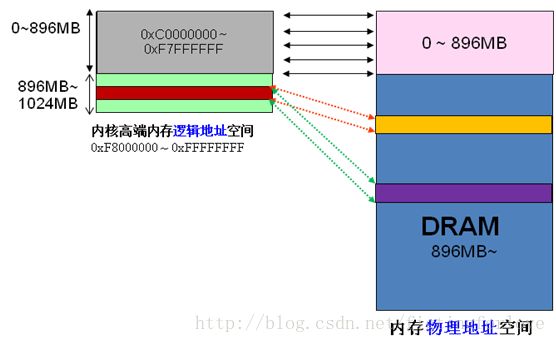
例如内核想访问2G开始的一段大小为1MB的物理内存,即物理地址范围为0×80000000 ~ 0x800FFFFF。访问之前先找到一段1MB大小的空闲地址空间,假设找到的空闲地址空间为0xF8700000 ~ 0xF87FFFFF,用这1MB的逻辑地址空间映射到物理地址空间0×80000000 ~ 0x800FFFFF的内存。映射关系如下:
逻辑地址 物理内存地址
0xF8700000 0×80000000
0xF8700001 0×80000001
0xF8700002 0×80000002
… …
0xF87FFFFF 0x800FFFFF
当内核访问完0×80000000 ~ 0x800FFFFF物理内存后,就将0xF8700000 ~ 0xF87FFFFF内核线性空间释放。这样其他进程或代码也可以使用0xF8700000 ~ 0xF87FFFFF这段地址访问其他物理内存。
从上面的描述,我们可以知道高端内存的最基本思想:借一段地址空间,建立临时地址映射,用完后释放,达到这段地址空间可以循环使用,访问所有物理内存。
内核将高端内存划分为3部分:VMALLOC_START~VMALLOC_END、KMAP_BASE~FIXADDR_START和FIXADDR_START~4G。
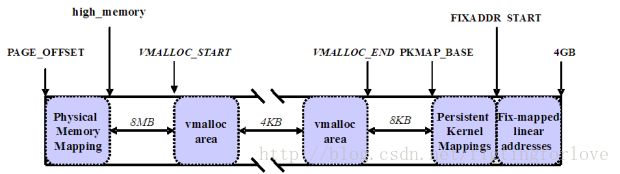
对于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行(为什么?想想 MMU 是如何访问物理内存的),也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射。
对应高端内存的3部分,高端内存映射有三种方式:
映射到”内核动态映射空间”(noncontiguous memory allocation)
这种方式很简单,因为通过 vmalloc(),在”内核动态映射空间”申请内存的时候(也就向前面讲的借用一段区域),就可能从高端内存获得页面(参看 vmalloc 的实现,后面有时间的话会分析)。
持久内核映射(permanent kernel mapping)
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。在 2.6内核上,这个地址范围是 4G-8M 到 4G-4M 之间。这个空间叫”内核永久映射空间”或者”永久内核映射空间”。这个空间和其它空间使用同样的页目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可,内核通过来 pkmap_page_table 寻找这个页表。通过kmap(),可以把一个 page 映射到这个空间来。由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page对应的线性地址从这个空间释放出来。
临时映射(temporary kernel mapping)
内核在 FIXADDR_START 到 FIXADDR_STOP 之间保留了一些线性空间用于特殊需求。这个空间称为”固定映射空间”在这个空间中,有一部分用于高端内存的临时映射。
这块空间具有如下特点:
(1)每个 CPU 占用一块空间
(2)在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的 km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。通过 kmap_atomic() 可实现临时映射。
常见问题:
1、用户空间(进程)是否有高端内存概念?
用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
2、64位内核中有高端内存吗?
目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存。
3、用户进程能访问多少物理内存?内核代码能访问多少物理内存?
32位系统用户进程最大可以访问3GB,内核代码可以访问所有物理内存。
64位系统用户进程最大可以访问超过512GB,内核代码可以访问所有物理内存。
4、高端内存和物理地址、逻辑地址、线性地址的关系?
高端内存只和物理地址有关系,和线性地址、逻辑地址没有直接关系。
5、为什么不把所有的地址空间都分配给内核?
若把所有地址空间都给内存,那么用户进程怎么使用内存?怎么保证内核使用内存和用户进程不起冲突?
磕磕绊绊,凑成了一篇四不像~~~~~~~~~~~~~~~