基于树莓派和opencv实现人脸识别
基于树莓派和opencv实现人脸识别
源码我放在github上了
https://github.com/FjnuThomas/-opencv-
各位哥哥姐姐clone代码别忘了给个小心心哦
前言
一、人脸检测
二、图像采集
三、开始训练
四、人脸识别
总结
前言
我们这学期选修了一门嵌入式Linux,期末选择了基于树莓派和opencv实现人脸识别作为期末作业。为了展示的方便,我将几个主要的功能集成在一个文件中,并通过wxpython写了GUI界面。同时也通过pyinstaller将.py文件打包成了适配windows和Linux的
展现一下我觉得巨帅的GUI 界面

环境
- 树莓派3B V1.2
- 树莓派系统:bullseye
- python 3.9.2
- opencv-python 4.5.3.56
- opencv-contrib-python 4.5.3.56
- numpy 1.21.0
- 摄像头罗技C170
关于树莓派安装opencv的步骤,可以参考我的另一篇博文
树莓派3B安装opencv
关于用opencv实现人脸识别的原理,晚上有很多博客已经写得很详细了,我只是基本理解,就不在这边班门弄斧了,写这篇博文的主要目的是对自己所学的进行归纳,只演示代码运行之后的结果,并在关键处进行解释。完整代码的github链接我放在文章开头了,可以直接使用。
opencv是一个用于图像处理、分析、机器视觉方面的开源函数库,它为我们提供了很多现成的函数和分类器,可以让我们很容易地实现功能。
一、人脸检测
我们实现人脸识别的前提事件是人脸检测,只有检测到人脸,才能够收集到人脸的数据。
我们用的是opencv自带的分类器
haarcascade_frontalface_default.xml
代码实现:
import cv2
faceCascade = cv2.CascadeClassifier('Cascades/haarcascade_frontalface_default.xml')
cap = cv2.VideoCapture(0)
cap.set(3, 640) # set Weight
cap.set(4, 480) # set Height
while True:
ret, img = cap.read()
img = cv2.flip(img, 1) #如果摄像头倒置,将1改成-1
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.2,
minNeighbors=5
,
minSize=(20, 20)
)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
roi_gray = gray[y:y + h, x:x + w]
roi_color = img[y:y + h, x:x + w]
cv2.imshow('video', img)
k = cv2.waitKey(30) & 0xff
if k == 27: # Esc for quit
break
cap.release()
cv2.destroyAllWindows()
在python3下运行如下代码可以完成人脸检测的功能
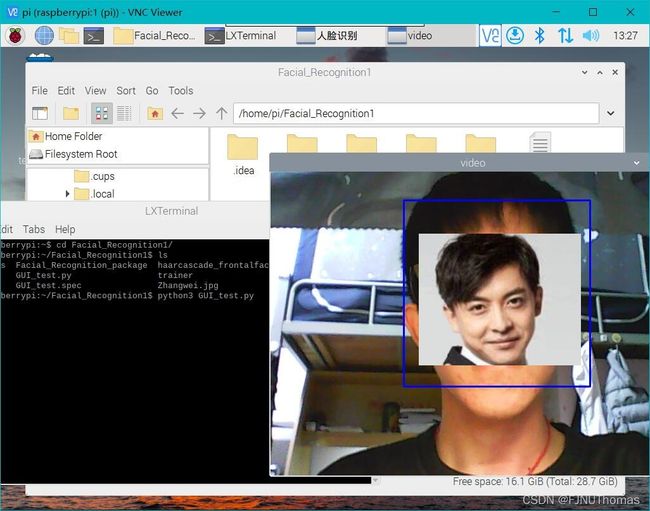
二、图像采集
人脸识别的本质其实就是构建一个人脸信息的数据库,电脑比对摄像头采集到的人脸信息和数据库中存放的数据,从而得到一个比对的结果
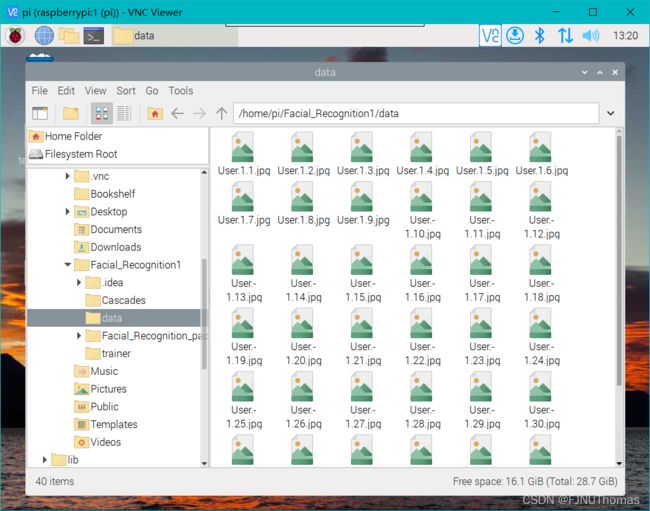
图像采集需要我们在.py文件同目录下新建一个文件夹,用于存放采集得到的图片
mkdir data
采集得到的图片越多,构建的数据库越完善,判断成功的概率也越高,但图片太多同样会降低比对时的速度。
我这里是设置了每0.2s拍一张照片,按ecs或拍满40张照片时退出
k = cv2.waitKey(200) & 0xff # ESC退出and每0.2s拍一张
if k == 27:
break
elif count >= 40: # 拍40张照片
break
图像采集示例
(这边需要我们在终端输入id号,我这边输入4)
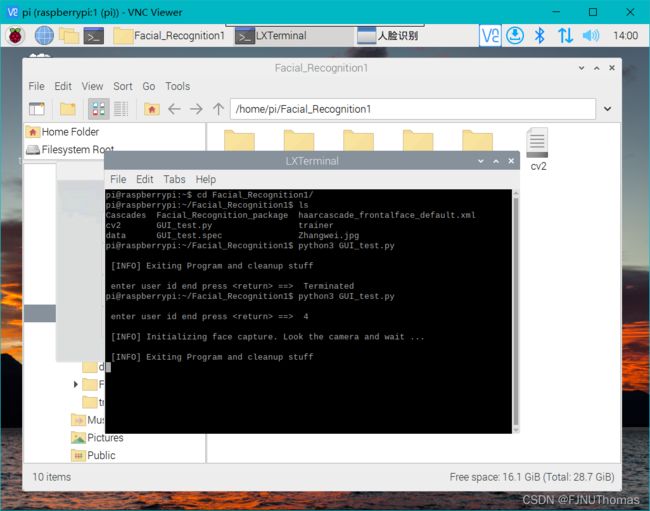
采集得到的图片
三、开始训练
训练是opencv人脸识别的重中之重
opencv为我们提供了多个内置函数,调用这些函数能够帮助我们训练得到自己的训练集这边我采用的是
recognizer.train()
在开始训练之前,我们需要新建一个空目录用于存放得到的模型
mkdir trainer
模型保存为.xml文件,要注意我们的代码是在树莓派下跑的,在树莓派下recognizer.write()是不能够使用的,因此我们用
recognizer.write('trainer/trainer.yml')
进行保存
训练成功实例

四、人脸识别
通过了前三个步骤,我们已经有了一个在data文件夹中保存采集到的图像、在trainer文件夹中保存自己训练的trainer.xml模型的文件了,我们就进入到了最后一步,也就是传说中的人脸识别了
人脸识别实例
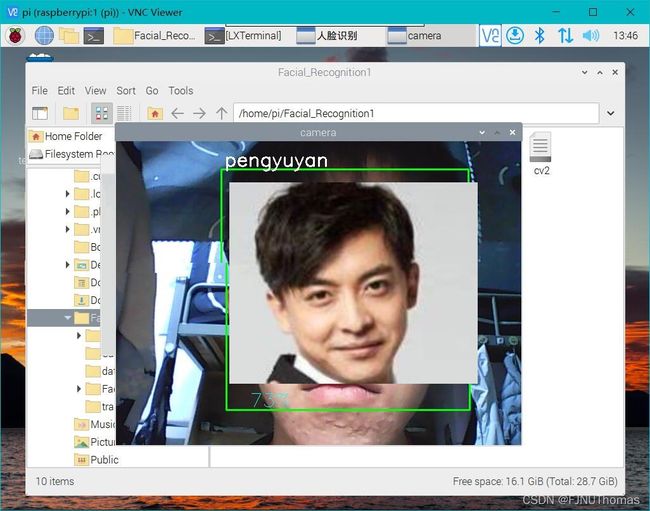
可以看到,系统识别出我有73%的概率是彭于晏,识别的成功率还是很高的
关于输出名字的问题,在代码的这个部分
id = 0
names = ['None', 'pengyuyan', 'xsy', 'rhy']
我们可以在这里修改成自己想要的名字,在代码中还有这样的部分
id, confidence = recognizer.predict(gray[y:y + h, x:x + w])
# 判断成功概率>45时,输出id,否则输出unknow
if (confidence < 55):
id = names[id]
confidence = " {0}%".format(round(100 - confidence))
else:
id = "unknown"
confidence = " {0}%".format(round(100 - confidence))
用于修改自己想要的判断概率。
到这里我们的人脸识别就基本完成了
总结
经过这一次的项目经历,我有了如下的收获
- 学会了树莓派的配置,并在树莓派上配置了环境
- 对opencv库有了个基本的了解,熟悉几个内置函数的功能和使用
- 对Linux有了更深刻的理解
- 增加了python能力
不足之处:
在调试的过程中,我发现在树莓派上运行项目还是有比较明显的卡顿的,因此我有对代码进行优化的想法,查阅资料以后了解到了有一个东西叫做pypy,尝试过用pypy对文件进行编码,奈何我写的代码是基于python3.9,和当前的pypy版本不太匹配,只好暂时作罢。在之后应该会尝试进行一次重新编译。