YOLOv5模型剪枝压缩
清华开源剪枝:
清华开源ResRep:剪枝SOTA!用结构重参数化实现CNN无损压缩 | ICCV 2021_AI视觉网奇的博客-CSDN博客
yolov5剪枝开源分享_AI视觉网奇的博客-CSDN博客_yolov5剪枝
https://github.com/jinfagang/nb
这个库把一些常用的blocks整合在了一起, 比如CSP, RFB, SPP,等, 接口统一之后构建模型的方法就会很简单. 我们就用这个库, 根据Yolov5的模型结构来构建一个简单版本的Yolov5. 当你熟悉这个构建过程之后, 修改backbone等的操作就会很简单.
好像也可以这么安装:
pip install nbnb
基于yolov5 v5.0分支进行剪枝,采用yolov5s模型,原理为Learning Efficient Convolutional Networks Through Network Slimming(https://arxiv.org/abs/1708.06519)。
yolov5 v5.0转NCNN和安卓移植见https://blog.csdn.net/IEEE_FELLOW/article/details/117190219
yolov5s是非常优秀的轻量级检测网络,但是有时候模型依然比较大,使得我们不得不缩减网络输入大小,但是单纯降低输入来减少运算,例如640降低到320,对检测效果损失很大,同时模型体积依然是14M左右,所以可以通过添加L1正则来约束BN层系数,使得系数稀疏化,通过稀疏训练后,裁剪掉稀疏很小的层,对应激活也很小,所以对后面的影响非常小,反复迭代这个过程,可以获得很compact的模型,步骤基本是这样。
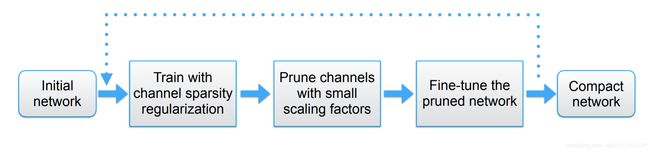
展开讲一下原理:
我们知道BN层的计算是这样的:

所以每个channel激活大小Zout和系数γ(pytorch对应bn层的weights,β对应bias)正相关,如果γ太小接近于0,那么激活值也非常小:
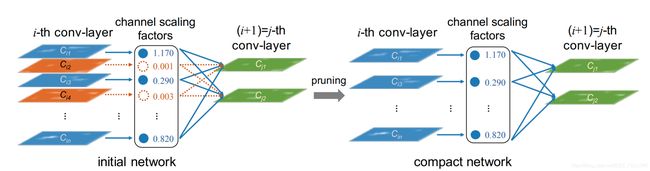
那么拿掉那些γ->0的channel是可以的,但是正常情况下,我们训练一个网络后,bn层的系数是类似正态分布:
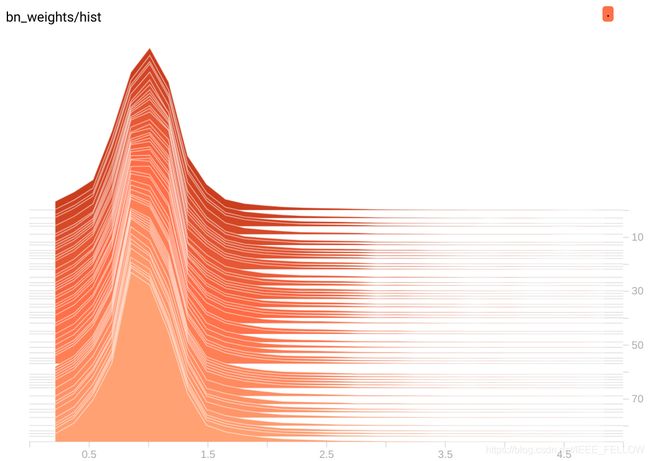
上图就是正常训练时候γ的随着epoch的直方图分布,可以看基本正太分布。0附近的值是很少的,所以没法剪枝。
通过添加L1 正则约束:
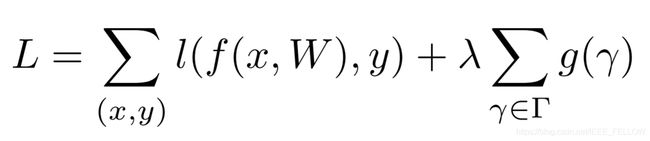
上面第一项是正常训练的loss函数,第二项是约束,其中g(s) = |s|,λ是正则系数,根据数据集调整。可以将参数稀疏化,看看如果添加到训练的损失函数中去,在进行反向传播时候:
′=∑′+∑′()=∑′+∑||′=∑′+∑∗()
上面损失函数L右边第一项是原始的损失函数,第二项是约束,其中g(s) = |s|,λ是正则系数,根据数据集调整
所以,只需要在训练中,反向传播时候,在BN层权重乘以权重的符合函数输出和系数即可,对应添加如下代码:
sr=0.0002
# Backward
loss.backward()
# scaler.scale(loss).backward()
# # ============================= sparsity training ========================== #
srtmp = opt.sr*(1 - 0.9*epoch/epochs)
if opt.st:
ignore_bn_list = []
for k, m in model.named_modules():
if isinstance(m, Bottleneck):
if m.add:
ignore_bn_list.append(k.rsplit(".", 2)[0] + ".cv1.bn")
ignore_bn_list.append(k + '.cv1.bn')
ignore_bn_list.append(k + '.cv2.bn')
if isinstance(m, nn.BatchNorm2d) and (k not in ignore_bn_list):
m.weight.grad.data.add_(srtmp * torch.sign(m.weight.data)) # L1
m.bias.grad.data.add_(opt.sr*10 * torch.sign(m.bias.data)) # L1
# # ============================= sparsity training ========================== #
optimizer.step()
# scaler.step(optimizer) # optimizer.step
# scaler.update()
optimizer.zero_grad()同时需要注意两点:
1. yolov5会采用自动混合精度训练,这里改成fp32模式;
2. yolov5里面会通过model.fuse()将卷积层和bn层融合,为了对bn层剪枝,训练和保存时候先不要fuse。
ok,我们选用一个较小的22类数据集训练尝试,λ从0.001均匀变化到0.0001训练完成,看看bn层变化:
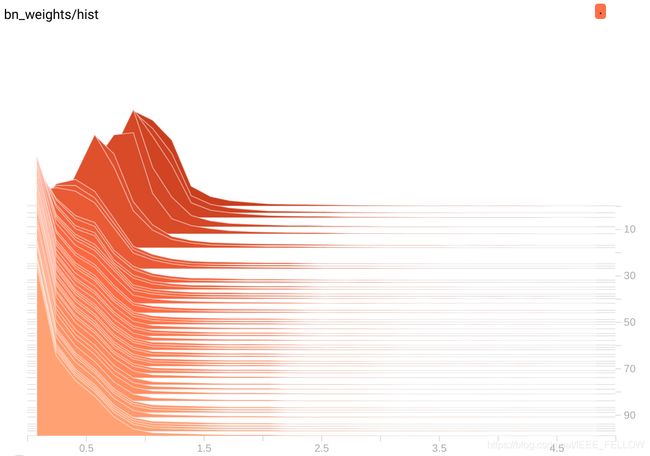
可以明显看到,随着训练进行(纵轴是epoch),BN层参数逐渐从最上面的正太分布趋向于0附近。
这里裁剪48%的参数是试试:
剪枝前:

剪枝后:
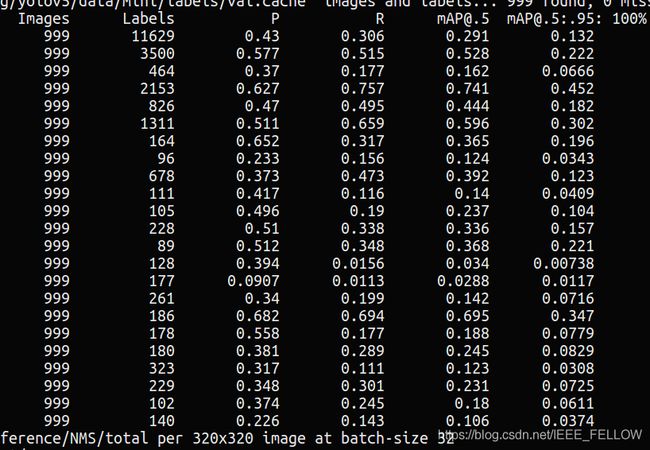
可以看到剪枝48%的通道后,MAP仅仅降低0.1%,通过微调可以很快恢复精度。
反复迭代这个过程,就可以获得一个更加轻量的yolov5s模型。
反复迭代这个过程,就可以获得一个更加轻量的yolov5s模型。
关于yolov5s模型分析和剪枝选择分析见:https://blog.csdn.net/IEEE_FELLOW/article/details/117536808
所有源码和实验见: https://github.com/midasklr/yolov5prune
原文链接:https://blog.csdn.net/IEEE_FELLOW/article/details/117236025