吴恩达机器学习课程-第七周
1.支持向量机SVM
1.1 优化目标
在逻辑回归中,针对一个样本的损失函数如下:
− y ( i ) l o g ( h θ ( x ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) = − y ( i ) l o g ( 1 1 + e − θ T ⋅ x ) + ( 1 − y ( i ) ) l o g ( 1 − 1 1 + e − θ T ⋅ x ) -y^{(i)}log(h_\theta(x^{(i)})+(1-y^{(i)})log(1-h_\theta(x^{(i)})=-y^{(i)}log(\frac{1}{1+e^{-\theta^T·x}})+(1-y^{(i)})log(1-\frac{1}{1+e^{-\theta^T·x}}) −y(i)log(hθ(x(i))+(1−y(i))log(1−hθ(x(i))=−y(i)log(1+e−θT⋅x1)+(1−y(i))log(1−1+e−θT⋅x1)
假设以 z = θ T ⋅ x z=\theta^T·x z=θT⋅x为横坐标,上述损失函数的值为纵坐标,当 y y y取不同值时可以画出不同的图像:

上图中的蓝色曲线为原始的图像,而紫红色的直线是与曲线很相似的直线。如果使用新的代价函数表达紫红色的线,则可以表示为: min θ C ∑ i = 1 m [ y ( i ) cost 1 ( θ T x ( i ) ) + ( 1 − y ( i ) ) cost 0 ( θ T x ( i ) ) ] + 1 2 ∑ i = 1 n θ j 2 \min\limits_{\theta} C \sum_{i=1}^{m}\left[y^{(i)} \operatorname{cost}_{1}\left(\theta^{T} x^{(i)}\right)+\left(1-y^{(i)}\right) \operatorname{cost}_{0}\left(\theta^{T} x^{(i)}\right)\right]+\frac{1}{2} \sum_{i=1}^{n} \theta_{j}^{2} θminC∑i=1m[y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+21∑i=1nθj2
转换后的代价函数即支持向量机的代价函数。其中 c o s t 1 ( θ T x ( i ) ) = − l o g h θ ( x ( i ) ) , c o s t 0 ( θ T x ( i ) ) = − l o g ( 1 − h θ ( x ( i ) ) ) cost_1(\theta^Tx^{(i)})=-logh_{\theta}(x^{(i)}),cost_0(\theta^Tx^{(i)})=-log(1-h_{\theta}(x^{(i)})) cost1(θTx(i))=−loghθ(x(i)),cost0(θTx(i))=−log(1−hθ(x(i))),分别表示两个子图中紫红色的线,且上式中把前后两个部分中的常量 1 m \frac{1}{m} m1以及正则化项中的 λ \lambda λ删除,改为第一项中的 C C C,这是SVM常用表达形式,实际含义并没有改变:原来的式子可以理解为 A + λ B A+\lambda B A+λB,如果 λ \lambda λ值较大说明给 B B B在代价函数的权重较大;现在修改为 C A + B CA+B CA+B,当 C C C的值较小时,变相增加了 B B B在代价函数中的权重,当 C = 1 λ C=\frac{1}{\lambda} C=λ1时,两个式子在梯度更新时会到相同的值
1.2 大边界的直观理解
下图是SVM代价函数的图像。当 y = 1 y=1 y=1时(对应左子图),为了使损失值最小需要 z = θ T x ≥ 1 z=\theta^Tx \ge 1 z=θTx≥1;当 y = 0 y=0 y=0时(对应右子图),为了使损失值最小需要 z = θ T x ≤ − 1 z=\theta^Tx \le -1 z=θTx≤−1。但是在逻辑回归中当 y = 1 y=1 y=1时,仅需要 θ T x ≥ 0 \theta^Tx \ge 0 θTx≥0即可将样本正确归类为正样本;当 y = 0 y=0 y=0时,仅需要 θ T x < 0 \theta^Tx \lt 0 θTx<0即可将样本正确归类为负样本:

从上述分析可以看出SVM的要求更高,需要一个安全间距
当把 C C C值设置的很大时,此时需要找出使得第一项为0的参数 θ \theta θ。假设选择了能使得第一项为0的参数 θ \theta θ,则必然要遵循约束条件,即当 y = 1 y=1 y=1时, θ T x ≥ 1 \theta^Tx \ge 1 θTx≥1以及当 y = 0 y=0 y=0时, θ T x ≤ − 1 \theta^Tx \le -1 θTx≤−1:

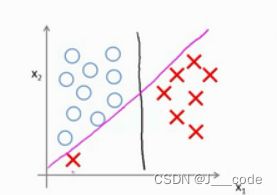
为什么SVM被称为大间距分类器?对于下图中的数据集,可以使用多条直线将正负样本分开,如图中紫红色和绿色的直线。而黑线相较于这两条线直观上把两类样本分开的更好,因为黑线与样本间有着更大的最短距离(离两类样本存在两个距离值,其中较小的值),意味着SVM具有鲁棒性,这个距离被称为SVM的间距:

当将 C C C设置的很大时,异常点会严重影响决策边界。在下图中,当 C C C较大时,黑线是未加入左下角的红色叉(异常点)得到的决策边界。加入了异常点后,为了将样本用最大间距分开,决策边界由黑线变为紫红色的线,这显然不太好(可以理解为过拟合)。所以当 C C C设置的值没有很大时,可以忽略异常点的影响,得到类似黑线这样较好的决策边界:
1.3 大边界分类背后的数学
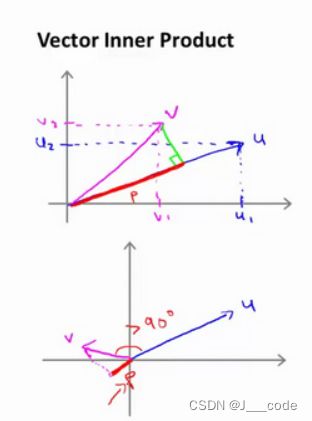
首先回顾向量内积的直观理解,对于两个向量 u = [ u 1 , u 2 ] T , v = [ v 1 , v 2 ] T u=[u_1,u_2]^T,v=[v1,v2]^T u=[u1,u2]T,v=[v1,v2]T, p p p为 v v v在 u u u上的投影( p p p也是有正负值的,但不是向量),则 u T v = p ⋅ ∣ ∣ u ∣ ∣ = u 1 v 1 + u 2 v 2 u^Tv=p·||u||=u_1v_1+u_2v_2 uTv=p⋅∣∣u∣∣=u1v1+u2v2:
下面通过内积性质理解SVM的目标函数:

首先令 θ 0 = 0 \theta_0=0 θ0=0,且将特征数设置为 n = 2 n=2 n=2,于是将目标函数转换为:
min θ 1 2 ∑ j = 1 n θ j 2 = 1 2 ( θ 1 2 + θ 2 2 ) = 1 2 ( θ 1 2 + θ 2 2 ) 2 = 1 2 ∣ ∣ θ ∣ ∣ 2 \min\limits_\theta\frac{1}{2}\sum_{j=1}^n\theta_j^2=\frac{1}{2}(\theta_1^2+\theta_2^2)=\frac{1}{2}(\sqrt{\theta_1^2+\theta_2^2)}^2=\frac{1}{2}||\theta||^2 θmin21∑j=1nθj2=21(θ12+θ22)=21(θ12+θ22)2=21∣∣θ∣∣2
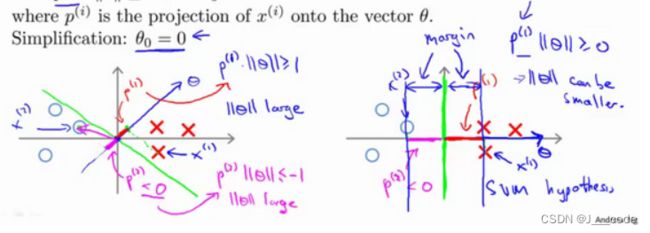
通过前面对内积的直观介绍,约束条件 θ T x ( i ) = p ( i ) ∣ ∣ θ ∣ ∣ \theta^Tx^{(i)}=p^{(i)}||\theta|| θTx(i)=p(i)∣∣θ∣∣, p ( i ) p^{(i)} p(i)表示 x ( i ) x^{(i)} x(i)在 θ \theta θ上的投影。因此目标函数如下所示:

在下面左子图中的两类样本,假设以绿线作为决策边界(即 θ T x = 0 \theta^Tx=0 θTx=0,这里绿线之所以经过原点是因为 θ 0 = 0 \theta_0=0 θ0=0),则蓝色向量 θ \theta θ与绿线正交,所以一个决策边界对应着一个参数 θ \theta θ向量。假设红叉为正样本,蓝圈为负样本,则图中正样本 x ( 1 ) x^{(1)} x(1)和负样本 x ( 2 ) x^{(2)} x(2)在 θ \theta θ上的投影长度十分的短,要满足 p ( i ) ∣ ∣ θ ∣ ∣ ≥ 1 p^{(i)}||\theta|| \ge 1 p(i)∣∣θ∣∣≥1和 p ( i ) ∣ ∣ θ ∣ ∣ ≤ − 1 p^{(i)}||\theta|| \le -1 p(i)∣∣θ∣∣≤−1则需要 ∣ ∣ θ ∣ ∣ ||\theta|| ∣∣θ∣∣的值要很大,但是目标函数是希望 ∣ ∣ θ ∣ ∣ ||\theta|| ∣∣θ∣∣的值尽量的小,所以 θ \theta θ的方向不好(即决策边界的选择不好)。
SVM会根据目标函数选择下面右子图中的决策边界,因为该边界让 ∣ ∣ θ ∣ ∣ ||\theta|| ∣∣θ∣∣变得更小:
1.4 核函数Ⅰ
为了获取下图中的判定边界,模型可能是 h ( θ ) = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 1 x 2 + . . . h(\theta)=\theta_0+\theta_1x_1+\theta_2x_2+\theta_3x_1x_2+... h(θ)=θ0+θ1x1+θ2x2+θ3x1x2+...的形式,此时假设 f 1 = x 1 , f 2 = x 2 , f 3 = x 1 x 2 , . . . f_1=x_1,f_2=x_2,f_3=x_1x_2,... f1=x1,f2=x2,f3=x1x2,...,则 h ( θ ) = θ 0 + θ 1 f 1 + θ 2 f 2 + . . . + θ n f n h(\theta)=\theta_0+\theta_1f_1+\theta_2f_2+...+\theta_nf_n h(θ)=θ0+θ1f1+θ2f2+...+θnfn。除了对原特征进行组合外,是否有更好的方法构造 f 1 , f 2 , . . . f_1,f_2,... f1,f2,...?这就需要核函数
假设给定一个样本 x x x,利用 x x x和预先选定的标记 l ( 1 ) 、 l ( 2 ) 、 l ( 3 ) l^{(1)}、l^{(2)}、l^{(3)} l(1)、l(2)、l(3)的近似程度作为 f 1 、 f 2 、 f 3 f_1、f_2、f_3 f1、f2、f3:

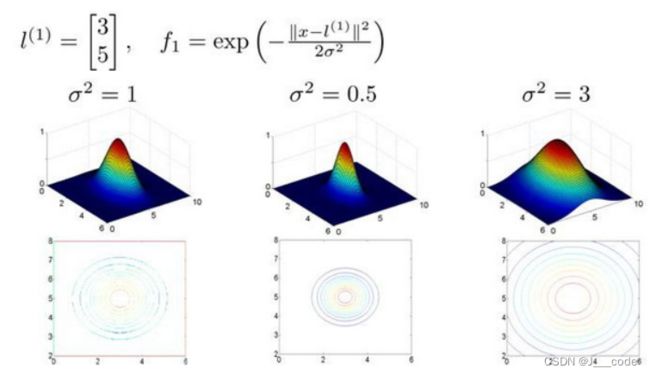
f 1 = similarity ( x , l ( 1 ) ) = e ( − ∥ x − l ( 1 ) ∥ 2 2 σ 2 ) f_{1}=\operatorname{similarity}\left(x, l^{(1)}\right)=e\left(-\frac{\left\|x-l^{(1)}\right\|^{2}}{2 \sigma^{2}}\right) f1=similarity(x,l(1))=e(−2σ2∥x−l(1)∥2)
f 2 = similarity ( x , l ( 2 ) ) = e ( − ∥ x − l ( 2 ) ∥ 2 2 σ 2 ) f_{2}=\operatorname{similarity}\left(x, l^{(2)}\right)=e\left(-\frac{\left\|x-l^{(2)}\right\|^{2}}{2 \sigma^{2}}\right) f2=similarity(x,l(2))=e(−2σ2∥x−l(2)∥2)
f 3 = similarity ( x , l ( 3 ) ) = e ( − ∥ x − l ( 3 ) ∥ 2 2 σ 2 ) f_{3}=\operatorname{similarity}\left(x, l^{(3)}\right)=e\left(-\frac{\left\|x-l^{(3)}\right\|^{2}}{2 \sigma^{2}}\right) f3=similarity(x,l(3))=e(−2σ2∥x−l(3)∥2)
其中, similarity ( x , l ( i ) ) \operatorname{similarity}\left(x, l^{(i)}\right) similarity(x,l(i))就是核函数(该函数是高斯核函数),通常采用 k ( x , l ( i ) ) k(x,l^{(i)}) k(x,l(i))表示。当 x x x与标记 l ( i ) l^{(i)} l(i)的距离越近,则特征 f i f_i fi近似于 e − 0 = 1 e^{-0}=1 e−0=1;当 x x x与标记 l ( i ) l^{(i)} l(i)的距离越远,则特征 f i f_i fi近似于 e − b i g n u m = 0 e^{-bignum}=0 e−bignum=0。从下图中可以直观理解,当 l ( 1 ) = [ 3 , 5 ] T l^{(1)}=[3,5]^T l(1)=[3,5]T时,如果 x = [ 3 , 5 ] T x=[3,5]^T x=[3,5]T,则 z z z轴最高( z z z轴表示 f 1 f_1 f1的值, x x x和 y y y轴分别表示 x 1 x_1 x1和 x 2 x_2 x2)。另外 σ \sigma σ的值会控制 f 1 f_1 f1的值随 x x x的改变而改变的速率:
那么核函数如何确定决策边界?假设在 h θ ( x ) = θ 0 + θ 1 f 1 + θ 2 f 2 + θ 3 f 3 h_\theta(x)=\theta_0+\theta_1f_1+\theta_2f_2+\theta_3f_3 hθ(x)=θ0+θ1f1+θ2f2+θ3f3,此时参数已知,分别为 θ 0 = 0.5 , θ 1 = θ 2 = 1 , θ 3 = 0 \theta_0=0.5,\theta_1=\theta_2=1,\theta_3=0 θ0=0.5,θ1=θ2=1,θ3=0。对于下图中的紫红色样本点,可以看出它离 l ( 1 ) l^{(1)} l(1)较近,离 l ( 2 ) l^{(2)} l(2)和 l ( 3 ) l^{(3)} l(3)较远,所以 f 1 ≈ 1 , f 2 ≈ 0 , f 3 ≈ 0 f_1 \approx 1,f_2 \approx 0,f_3 \approx 0 f1≈1,f2≈0,f3≈0,所以 h θ ( x ) > 0 h_\theta(x)>0 hθ(x)>0,即预测该样本点为正样本点。同理预测绿色样本点为正样本点,青蓝色样本点为负样本点,最终得出红色的决策边界。可以看出在上述计算中并没有使用到样本的特性值 x 1 、 x 2 、 x 3 x_1、x_2、x_3 x1、x2、x3,而是使用核函数计算出的新特征 f 1 、 f 2 、 f 3 f_1、f_2、f_3 f1、f2、f3:
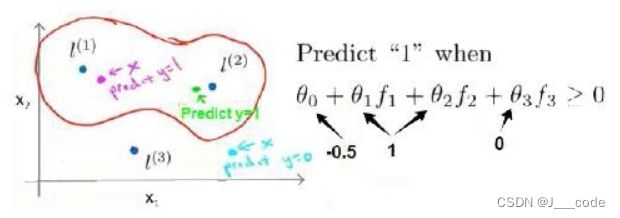
1.5 核函数Ⅱ
在1.4节中只是直观介绍了核函数的概念和作用,但是还不知道如何选取标记 l ( i ) l^{(i)} l(i)。通常是根据训练集的数量选择标记数,假设有 m m m个样本,则选取 m m m个标记,这样得到的新特征是建立在单个样本点和其他所有样本点间的距离上的。假如将每一个样本点作为一个标记,则新特性可以表示为:

所以SVM的目标函数转换为 min θ C ∑ i = 1 m [ y ( i ) cost 1 ( θ T f ( i ) ) + ( 1 − y ( i ) ) cost 0 ( θ T f ( i ) ) ] + 1 2 ∑ i = 1 n = m θ j 2 \min\limits_{\theta} C \sum_{i=1}^{m}\left[y^{(i)} \operatorname{cost}_{1}\left(\theta^{T} f^{(i)}\right)+\left(1-y^{(i)}\right) \operatorname{cost}_{0}\left(\theta^{T} f^{(i)}\right)\right]+\frac{1}{2} \sum_{i=1}^{n=m} \theta_{j}^{2} θminC∑i=1m[y(i)cost1(θTf(i))+(1−y(i))cost0(θTf(i))]+21∑i=1n=mθj2,并且在计算 ∑ i = 1 n = m θ j 2 = θ T θ \sum_{i=1}^{n=m} \theta_{j}^{2}=\theta^T\theta ∑i=1n=mθj2=θTθ时会使用 θ T M θ \theta^T M \theta θTMθ进行代替,由于简化计算,其中 M M M随着核函数的不同而变化
注意:当SVM不使用核函数时,称为线性核函数,即目标函数还是 θ T x \theta^Tx θTx
下面来看下 C = 1 λ C=\frac{1}{\lambda} C=λ1和 σ \sigma σ对SVM的影响:
- 当 C C C较大时,相当于 λ \lambda λ较小,可能会导致过拟合,高方差
- 当 C C C较小时,相当于 λ \lambda λ较大,可能会导致欠拟合,高偏差
- 当 σ \sigma σ较大时,特征 f i f_i fi的变化较平滑,可能会导致低方差,高偏差
- 当 σ \sigma σ较小时,特征 f i f_i fi的变化较剧烈,可能会导致低偏差,高方差
1.6 SVM的使用
要使用SVM,必须做以下几件事:
- 选择合适的 C C C值
- 选择核函数(也可以不使用核函数),核函数除了高斯核函数,还有多项式核函数等,但是目标都是根据样本和标记间的距离构建新特征
- 选择合适的 σ \sigma σ值
对于SVM的使用是存在普遍准则的, m m m为样本数, n n n为特征数:
-
如果 n n n相较于 m m m要大许多,即训练集数据量不够支持训练一个复杂的非线性模型,则选用逻辑回归模型或者不带核函数的SVM
-
如果 n n n较小, m m m大小适中,则使用高斯核函数的SVM
-
如果 n n n较小, m m m较大,则使用SVM会非常慢,此时需要创造更多的特征,然后使用逻辑回归或不带核函数的SVM
神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢,选择支持向量机的原因主要在于它的代价函数是凸函数,不存在局部最小值
2.参考
https://www.bilibili.com/video/BV164411b7dx?p=70-75
http://www.ai-start.com/ml2014/html/week7.html