Python爬取豆瓣电影评分Top250(内附源码地址与效果图)
目录
1.先看一眼项目层次结构和最终效果图吧(通过可视化分析得到豆瓣评分Top250平均评分最高的电影类别)
1.1项目层次结构:
1.2 项目效果图(注意url地址)
1.3 实现过程以及步骤
1.3.1爬取数据
1.3.1.1 附爬取数据模块源码
1.3.2 数据处理
1.3.3 可视化分析
1.3.4 结果展示
1.3.5 源码分享
1.先看一眼项目层次结构和最终效果图吧(通过可视化分析得到豆瓣评分Top250平均评分最高的电影类别)
1.1项目层次结构:

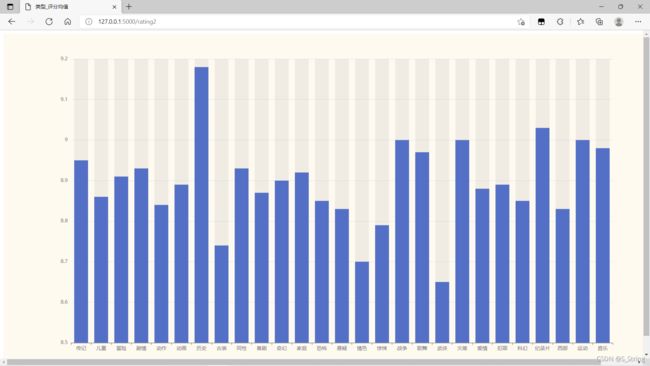
1.2 项目效果图(注意url地址)
1.3 实现过程以及步骤
1.3.1爬取数据
通过Python使用BeautifulSoup库爬取豆瓣电影网址,url地址:豆瓣电影 Top 250 (douban.com)
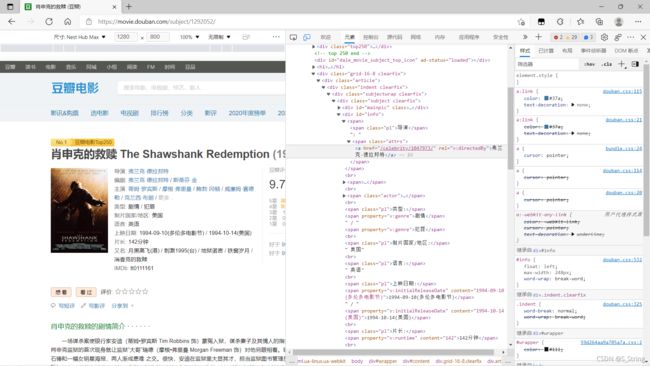
1.3.1.1 附爬取数据模块源码
#1.打开要抓取的网页
#2.查看接口(页面地址的调用顺序)
#3.查看数据的数据结构
start = 0
result = []
header = {
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Mobile Safari/537.36 Edg/95.0.1020.44'
}
f = open("电影榜Top250.csv",mode="w")
for i in range (0,10):
html = requests.get("https://movie.douban.com/top250?start="+str(start) + "&filter=",headers=header)
html.encoding = 'utf-8'
start += 25
soup = BeautifulSoup(html.text,"html.parser")
# print(soup)
for item in soup.find_all('div','info'):
title = item.div.a.span.string
#print(title)
yearline = item.find('div','bd').p.contents[2].string
yearline = yearline.replace(' ','')
yearline = yearline.replace('\n', '')
year = yearline[0:4]
movie_message = item.find('div','bd').p.contents[2].string
movie_message = movie_message.replace(' ','')
movie_message = movie_message.replace('\n','')
movie_message = movie_message.replace('/',",")
movie_message = movie_message.replace(u'\xa0',u'')
#导入re包1,调用findall方法使用正则表达式查找以1/空格开始 以空格/结尾的1字符串
#country = re.findall(r"/ (.+?) /", movie_message2)
#movie_country = country[0]
#type = re.findall(r"\xa0/\xa0(.+)........................", movie_message2)
#print(type)
# 获取评分
rating = item.find('span', {'class': 'rating_num'}).get_text()
f.write(title + "," + movie_message + "," + rating)
f.write("\n")
1.3.2 数据处理
对存储在文件中的数据进行数据处理和清洗
对于爬取到的数据,我们需要进行数据清洗和数据处理,以便去除掉我们不需要的数据以及将数据修正为我们需要的格式。这是我们爬取到的数据:

通过上述截图我们可以发现,该文件中的有的电影类别不只有一个;对此我们要特别对此进行处理(由于最后结果为分析类别与评分之间的关系,故我们仅取出类别与评分两列即可);举个例子:我们要对肖申克的救赎这条电影的类别和评分做以下处理:
犯罪/剧情,9.7 ----> 犯罪 9.7 剧情9.7
即将类别与评分之间的对应关系一一拆分开来,由于具体代码我写的较为繁琐(本人比较菜)先不在这里放啦,如果有需要的可以在下方留言,会分享给大家的。
1.3.3 可视化分析
现在,我们已经将数据处理完毕,剩下的就是可视化分析了。由于我们这里用到的是echarts对数据进行可视化分析,所以会用到html页面以及js的相关知识(对于此项目的前端页面我不多赘述,可能会在其他文章中说到,该项目的前端页面大家可以运行就好)。在编写代码之前,大家需要导入flask的相关库
具体代码如下:
from flask import Flask,render_template
import pandas as pd
# 创建一个app
app = Flask(__name__)
# 准备一个函数,来处理浏览器发送过来的请求
@app.route("/")
def show():
# 读取csv文件中的内容,发送在文件中
data = pd.read_csv("类型-评分均值.csv")
#将csv文件中的内容转化为字典
#按要求读取数据,仅显示评分最高的8个
data = data.loc[data.value >= 8.95]
data = data.to_dict(orient="records")
return render_template("show.html",data = data)
@app.route("/rating")
def showRating():
data = pd.read_csv("类型-评分均值.csv")
data = data.loc[data.value >= 8.95]
data = data.to_dict(orient="records")
return render_template("show2.html", data=data)
@app.route("/rating2")
def showRating2():
data = pd.read_csv("类型-评分均值.csv")
data_name = data.loc[:, 'name'].values.tolist()
data_value = data.loc[:, 'value'].values.tolist()
return render_template("show3.html", data_name=data_name,data_value = data_value)
# 运行这个app
if __name__ == '__main__':
app.run()其中@qpp.route(“ ”)注解为建立url与处理方法之间的对应关系
1.3.4 结果展示
好了,写到这里。大家就可以运行代码打开控制台下方的网址进行数据展示了

大家的默认打开 页面应该是这个,因为此页面对于类型与评分之间的对应关系不是很明显,所以我又新建了页面用柱状图来表示他俩之间的对应关系(注意url地址)
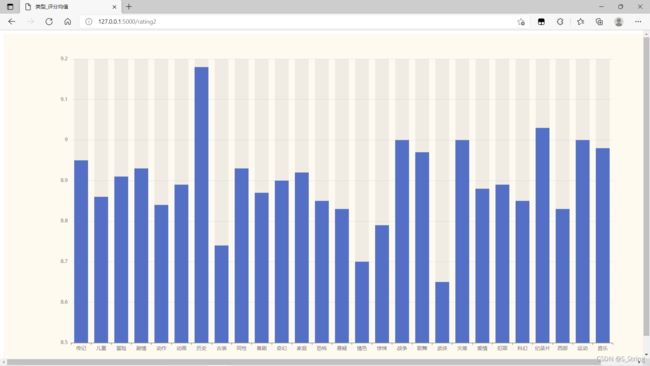
1.3.5 源码分享
需要源码的小伙伴,可以在下方留言。本人看到会尽快回复的,本项目相关问题大家也可以来提问。
礼貌拿码,大家调通代码之后不要忘记三连哦~~~