❀YOLO5学习❀基于yolo5-face结合注意力模型SE的数据实验
2022 04 14 2:27
放轻松,就当漫游地球![]()
- insanena
yolo5-face项目没有实现的朋友们可以参考我的这篇:
❀YOLOv5学习❀yolo5-face论文里代码复现,实现运行_夏天|여름이다的博客-CSDN博客_yolov5人脸识别论文
一般笔记本电脑上实现这个是没有问题的,但是训练的时候,cpu有点太勉强了,我的实验可以借大家参考,但是请注明转载, 。
。
好啦,开始正文啦。。。。。
同样参考很多大佬的博客论文,具体忘记啦,就不列入参考文献啦!(只要是参考的我都会写到参考文献哟*-^)
主要修改三个地方:
common.py添加注意力实现代码
yolo.py中添加判断条件
添加注意力yaml文件,我直接在yolo5s.yaml上加的(yolov5版本不同会有不同,和上一层相似)
如果大家怕出错的话,建议大家保存一份源文件,在源文件的基础上改,错误率会小一点。
第一步:先改common.py文件
具体论文建议大家下载论文看详细内容,本博客主要是实操。先加se模块,
添加了这部分:

我直接放上代码,大家可以直接复制粘贴(贴心少女在线):
# This file contains modules common to various models
import math
import numpy as np
import requests
import torch
import torch.nn as nn
from PIL import Image, ImageDraw
from utils.datasets import letterbox
from utils.general import non_max_suppression, make_divisible, scale_coords, xyxy2xywh
from utils.plots import color_list
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
def DWConv(c1, c2, k=1, s=1, act=True):
# Depthwise convolution
return Conv(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = self.act = nn.LeakyReLU(0.1, inplace=True) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class StemBlock(nn.Module):
def __init__(self, c1, c2, k=3, s=2, p=None, g=1, act=True):
super(StemBlock, self).__init__()
self.stem_1 = Conv(c1, c2, k, s, p, g, act)
self.stem_2a = Conv(c2, c2 // 2, 1, 1, 0)
self.stem_2b = Conv(c2 // 2, c2, 3, 2, 1)
self.stem_2p = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
self.stem_3 = Conv(c2 * 2, c2, 1, 1, 0)
def forward(self, x):
stem_1_out = self.stem_1(x)
stem_2a_out = self.stem_2a(stem_1_out)
stem_2b_out = self.stem_2b(stem_2a_out)
stem_2p_out = self.stem_2p(stem_1_out)
out = self.stem_3(torch.cat((stem_2b_out, stem_2p_out), 1))
return out
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class ShuffleV2Block(nn.Module):
def __init__(self, inp, oup, stride):
super(ShuffleV2Block, self).__init__()
if not (1 <= stride <= 3):
raise ValueError('illegal stride value')
self.stride = stride
branch_features = oup // 2
assert (self.stride != 1) or (inp == branch_features << 1)
if self.stride > 1:
self.branch1 = nn.Sequential(
self.depthwise_conv(inp, inp, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(inp),
nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.SiLU(),
)
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(inp if (self.stride > 1) else branch_features, branch_features, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.SiLU(),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.SiLU(),
)
@staticmethod
def depthwise_conv(i, o, kernel_size, stride=1, padding=0, bias=False):
return nn.Conv2d(i, o, kernel_size, stride, padding, bias=bias, groups=i)
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
class BlazeBlock(nn.Module):
def __init__(self, in_channels, out_channels, mid_channels=None, stride=1):
super(BlazeBlock, self).__init__()
mid_channels = mid_channels or in_channels
assert stride in [1, 2]
if stride > 1:
self.use_pool = True
else:
self.use_pool = False
self.branch1 = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=mid_channels, kernel_size=5, stride=stride, padding=2,
groups=in_channels),
nn.BatchNorm2d(mid_channels),
nn.Conv2d(in_channels=mid_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
)
if self.use_pool:
self.shortcut = nn.Sequential(
nn.MaxPool2d(kernel_size=stride, stride=stride),
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
)
self.relu = nn.SiLU(inplace=True)
def forward(self, x):
branch1 = self.branch1(x)
out = (branch1 + self.shortcut(x)) if self.use_pool else (branch1 + x)
return self.relu(out)
class DoubleBlazeBlock(nn.Module):
def __init__(self, in_channels, out_channels, mid_channels=None, stride=1):
super(DoubleBlazeBlock, self).__init__()
mid_channels = mid_channels or in_channels
assert stride in [1, 2]
if stride > 1:
self.use_pool = True
else:
self.use_pool = False
self.branch1 = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=5, stride=stride, padding=2,
groups=in_channels),
nn.BatchNorm2d(in_channels),
nn.Conv2d(in_channels=in_channels, out_channels=mid_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(mid_channels),
nn.SiLU(inplace=True),
nn.Conv2d(in_channels=mid_channels, out_channels=mid_channels, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(mid_channels),
nn.Conv2d(in_channels=mid_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
)
if self.use_pool:
self.shortcut = nn.Sequential(
nn.MaxPool2d(kernel_size=stride, stride=stride),
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
)
self.relu = nn.SiLU(inplace=True)
def forward(self, x):
branch1 = self.branch1(x)
out = (branch1 + self.shortcut(x)) if self.use_pool else (branch1 + x)
return self.relu(out)
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
class SE(nn.Module):
def __init__(self, c1, c2, r=16):
super(SE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))
class Contract(nn.Module):
# Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
def __init__(self, gain=2):
super().__init__()
self.gain = gain
def forward(self, x):
N, C, H, W = x.size() # assert (H / s == 0) and (W / s == 0), 'Indivisible gain'
s = self.gain
x = x.view(N, C, H // s, s, W // s, s) # x(1,64,40,2,40,2)
x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
return x.view(N, C * s * s, H // s, W // s) # x(1,256,40,40)
class Expand(nn.Module):
# Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
def __init__(self, gain=2):
super().__init__()
self.gain = gain
def forward(self, x):
N, C, H, W = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
s = self.gain
x = x.view(N, s, s, C // s ** 2, H, W) # x(1,2,2,16,80,80)
x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
return x.view(N, C // s ** 2, H * s, W * s) # x(1,16,160,160)
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super(Concat, self).__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
class NMS(nn.Module):
# Non-Maximum Suppression (NMS) module
conf = 0.25 # confidence threshold
iou = 0.45 # IoU threshold
classes = None # (optional list) filter by class
def __init__(self):
super(NMS, self).__init__()
def forward(self, x):
return non_max_suppression(x[0], conf_thres=self.conf, iou_thres=self.iou, classes=self.classes)
class autoShape(nn.Module):
# input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMS
img_size = 640 # inference size (pixels)
conf = 0.25 # NMS confidence threshold
iou = 0.45 # NMS IoU threshold
classes = None # (optional list) filter by class
def __init__(self, model):
super(autoShape, self).__init__()
self.model = model.eval()
def autoshape(self):
print('autoShape already enabled, skipping... ') # model already converted to model.autoshape()
return self
def forward(self, imgs, size=640, augment=False, profile=False):
# Inference from various sources. For height=720, width=1280, RGB images example inputs are:
# filename: imgs = 'data/samples/zidane.jpg'
# URI: = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/zidane.jpg'
# OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(720,1280,3)
# PIL: = Image.open('image.jpg') # HWC x(720,1280,3)
# numpy: = np.zeros((720,1280,3)) # HWC
# torch: = torch.zeros(16,3,720,1280) # BCHW
# multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
p = next(self.model.parameters()) # for device and type
if isinstance(imgs, torch.Tensor): # torch
return self.model(imgs.to(p.device).type_as(p), augment, profile) # inference
# Pre-process
n, imgs = (len(imgs), imgs) if isinstance(imgs, list) else (1, [imgs]) # number of images, list of images
shape0, shape1 = [], [] # image and inference shapes
for i, im in enumerate(imgs):
if isinstance(im, str): # filename or uri
im = Image.open(requests.get(im, stream=True).raw if im.startswith('http') else im) # open
im = np.array(im) # to numpy
if im.shape[0] < 5: # image in CHW
im = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)
im = im[:, :, :3] if im.ndim == 3 else np.tile(im[:, :, None], 3) # enforce 3ch input
s = im.shape[:2] # HWC
shape0.append(s) # image shape
g = (size / max(s)) # gain
shape1.append([y * g for y in s])
imgs[i] = im # update
shape1 = [make_divisible(x, int(self.stride.max())) for x in np.stack(shape1, 0).max(0)] # inference shape
x = [letterbox(im, new_shape=shape1, auto=False)[0] for im in imgs] # pad
x = np.stack(x, 0) if n > 1 else x[0][None] # stack
x = np.ascontiguousarray(x.transpose((0, 3, 1, 2))) # BHWC to BCHW
x = torch.from_numpy(x).to(p.device).type_as(p) / 255. # uint8 to fp16/32
# Inference
with torch.no_grad():
y = self.model(x, augment, profile)[0] # forward
y = non_max_suppression(y, conf_thres=self.conf, iou_thres=self.iou, classes=self.classes) # NMS
# Post-process
for i in range(n):
scale_coords(shape1, y[i][:, :4], shape0[i])
return Detections(imgs, y, self.names)
class Detections:
# detections class for YOLOv5 inference results
def __init__(self, imgs, pred, names=None):
super(Detections, self).__init__()
d = pred[0].device # device
gn = [torch.tensor([*[im.shape[i] for i in [1, 0, 1, 0]], 1., 1.], device=d) for im in imgs] # normalizations
self.imgs = imgs # list of images as numpy arrays
self.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)
self.names = names # class names
self.xyxy = pred # xyxy pixels
self.xywh = [xyxy2xywh(x) for x in pred] # xywh pixels
self.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalized
self.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalized
self.n = len(self.pred)
def display(self, pprint=False, show=False, save=False, render=False):
colors = color_list()
for i, (img, pred) in enumerate(zip(self.imgs, self.pred)):
str = f'Image {i + 1}/{len(self.pred)}: {img.shape[0]}x{img.shape[1]} '
if pred is not None:
for c in pred[:, -1].unique():
n = (pred[:, -1] == c).sum() # detections per class
str += f'{n} {self.names[int(c)]}s, ' # add to string
if show or save or render:
img = Image.fromarray(img.astype(np.uint8)) if isinstance(img, np.ndarray) else img # from np
for *box, conf, cls in pred: # xyxy, confidence, class
# str += '%s %.2f, ' % (names[int(cls)], conf) # label
ImageDraw.Draw(img).rectangle(box, width=4, outline=colors[int(cls) % 10]) # plot
if pprint:
print(str)
if show:
img.show(f'Image {i}') # show
if save:
f = f'results{i}.jpg'
str += f"saved to '{f}'"
img.save(f) # save
if render:
self.imgs[i] = np.asarray(img)
def print(self):
self.display(pprint=True) # print results
def show(self):
self.display(show=True) # show results
def save(self):
self.display(save=True) # save results
def render(self):
self.display(render=True) # render results
return self.imgs
def __len__(self):
return self.n
def tolist(self):
# return a list of Detections objects, i.e. 'for result in results.tolist():'
x = [Detections([self.imgs[i]], [self.pred[i]], self.names) for i in range(self.n)]
for d in x:
for k in ['imgs', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:
setattr(d, k, getattr(d, k)[0]) # pop out of list
return x
class Classify(nn.Module):
# Classification head, i.e. x(b,c1,20,20) to x(b,c2)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
super(Classify, self).__init__()
self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g) # to x(b,c2,1,1)
self.flat = nn.Flatten()
def forward(self, x):
z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if list
return self.flat(self.conv(z)) # flatten to x(b,c2)
第二步:yolo.py中添加判断条件

只是单纯加了SE,(如果自己写的话,一般是大写,注意大小写哟,)直接贴代码。
import argparse
import logging
import math
import sys
from copy import deepcopy
from pathlib import Path
import torch
import torch.nn as nn
from modify_folder.common_se import SE
sys.path.append('./') # to run '$ python *.py' files in subdirectories
logger = logging.getLogger(__name__)
from models.common import Conv, Bottleneck, SPP, DWConv, Focus, BottleneckCSP, C3, ShuffleV2Block, Concat, NMS, \
autoShape, StemBlock, BlazeBlock, DoubleBlazeBlock
from models.experimental import MixConv2d, CrossConv
from utils.autoanchor import check_anchor_order
from utils.general import make_divisible, check_file, set_logging
from utils.torch_utils import time_synchronized, fuse_conv_and_bn, model_info, scale_img, initialize_weights, \
select_device, copy_attr
try:
import thop # for FLOPS computation
except ImportError:
thop = None
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes
# self.no = nc + 5 # number of outputs per anchor
self.no = nc + 5 + 10 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
# self.training |= self.export
if self.export:
for i in range(self.nl):
x[i] = self.m[i](x[i])
bs, _, ny, nx = x[i].shape # x(bs,48,20,20) to x(bs,3,20,20,16)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
return x
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = torch.full_like(x[i], 0)
class_range = list(range(5)) + list(range(15, 15 + self.nc))
y[..., class_range] = x[i][..., class_range].sigmoid()
y[..., 5:15] = x[i][..., 5:15]
# y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
# y[..., 5:15] = y[..., 5:15] * 8 - 4
y[..., 5:7] = y[..., 5:7] * self.anchor_grid[i] + self.grid[i].to(x[i].device) * self.stride[
i] # landmark x1 y1
y[..., 7:9] = y[..., 7:9] * self.anchor_grid[i] + self.grid[i].to(x[i].device) * self.stride[
i] # landmark x2 y2
y[..., 9:11] = y[..., 9:11] * self.anchor_grid[i] + self.grid[i].to(x[i].device) * self.stride[
i] # landmark x3 y3
y[..., 11:13] = y[..., 11:13] * self.anchor_grid[i] + self.grid[i].to(x[i].device) * self.stride[
i] # landmark x4 y4
y[..., 13:15] = y[..., 13:15] * self.anchor_grid[i] + self.grid[i].to(x[i].device) * self.stride[
i] # landmark x5 y5
# y[..., 5:7] = (y[..., 5:7] * 2 -1) * self.anchor_grid[i] # landmark x1 y1
# y[..., 7:9] = (y[..., 7:9] * 2 -1) * self.anchor_grid[i] # landmark x2 y2
# y[..., 9:11] = (y[..., 9:11] * 2 -1) * self.anchor_grid[i] # landmark x3 y3
# y[..., 11:13] = (y[..., 11:13] * 2 -1) * self.anchor_grid[i] # landmark x4 y4
# y[..., 13:15] = (y[..., 13:15] * 2 -1) * self.anchor_grid[i] # landmark x5 y5
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None): # model, input channels, number of classes
super(Model, self).__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg) as f:
self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
logger.info('Overriding model.yaml nc=%g with nc=%g' % (self.yaml['nc'], nc))
self.yaml['nc'] = nc # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
# print([x.shape for x in self.forward(torch.zeros(1, ch, 64, 64))])
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 128 # 2x min stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once
# print('Strides: %s' % m.stride.tolist())
# Init weights, biases
initialize_weights(self)
self.info()
logger.info('')
def forward(self, x, augment=False, profile=False):
if augment:
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si)
yi = self.forward_once(xi)[0] # forward
# cv2.imwrite('img%g.jpg' % s, 255 * xi[0].numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi[..., :4] /= si # de-scale
if fi == 2:
yi[..., 1] = img_size[0] - yi[..., 1] # de-flip ud
elif fi == 3:
yi[..., 0] = img_size[1] - yi[..., 0] # de-flip lr
y.append(yi)
return torch.cat(y, 1), None # augmented inference, train
else:
return self.forward_once(x, profile) # single-scale inference, train
def forward_once(self, x, profile=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
o = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPS
t = time_synchronized()
for _ in range(10):
_ = m(x)
dt.append((time_synchronized() - t) * 100)
print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if profile:
print('%.1fms total' % sum(dt))
return x
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def _print_biases(self):
m = self.model[-1] # Detect() module
for mi in m.m: # from
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
print(('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
# def _print_weights(self):
# for m in self.model.modules():
# if type(m) is Bottleneck:
# print('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
print('Fusing layers... ')
for m in self.model.modules():
if type(m) is Conv and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.fuseforward # update forward
self.info()
return self
def nms(self, mode=True): # add or remove NMS module
present = type(self.model[-1]) is NMS # last layer is NMS
if mode and not present:
print('Adding NMS... ')
m = NMS() # module
m.f = -1 # from
m.i = self.model[-1].i + 1 # index
self.model.add_module(name='%s' % m.i, module=m) # add
self.eval()
elif not mode and present:
print('Removing NMS... ')
self.model = self.model[:-1] # remove
return self
def autoshape(self): # add autoShape module
print('Adding autoShape... ')
m = autoShape(self) # wrap model
copy_attr(m, self, include=('yaml', 'nc', 'hyp', 'names', 'stride'), exclude=()) # copy attributes
return m
def info(self, verbose=False, img_size=640): # print model information
model_info(self, verbose, img_size)
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
n = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, Bottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3, ShuffleV2Block,
StemBlock, BlazeBlock, DoubleBlazeBlock,SE]:
c1, c2 = ch[f], args[0]
# Normal
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1.75 # exponential (default 2.0)
# e = math.log(c2 / ch[1]) / math.log(2)
# c2 = int(ch[1] * ex ** e)
# if m != Focus:
c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
# Experimental
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1 + gw # exponential (default 2.0)
# ch1 = 32 # ch[1]
# e = math.log(c2 / ch1) / math.log(2) # level 1-n
# c2 = int(ch1 * ex ** e)
# if m != Focus:
# c2 = make_divisible(c2, 8) if c2 != no else c2
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3]:
args.insert(2, n)
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[-1 if x == -1 else x + 1] for x in f])
elif m is Detect:
args.append([ch[x + 1] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
else:
c2 = ch[f]
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
from thop import profile
from thop import clever_format
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
opt = parser.parse_args()
opt.cfg = check_file(opt.cfg) # check file
set_logging()
device = select_device(opt.device)
# Create model
model = Model(opt.cfg).to(device)
stride = model.stride.max()
if stride == 32:
input = torch.Tensor(1, 3, 480, 640).to(device)
else:
input = torch.Tensor(1, 3, 512, 640).to(device)
model.train()
print(model)
flops, params = profile(model, inputs=(input,))
flops, params = clever_format([flops, params], "%.3f")
print('Flops:', flops, ',Params:', params)
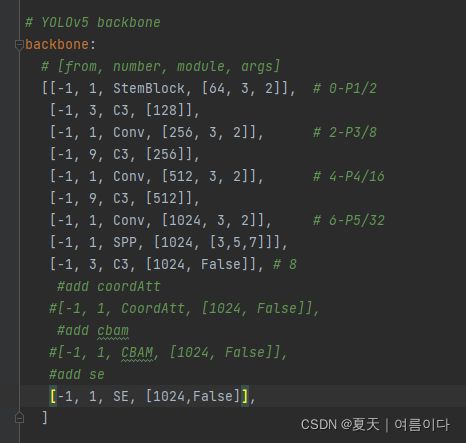
第三步:修改yolo5s.yaml文件
只修改backbone部分,版本虽然有不同,和上一层输出输入尺寸大小一样就可以。
(因为自己淋过雨,所以想给别人打把伞。)
# parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.5 # layer channel multiple
# anchors
anchors:
- [4,5, 8,10, 13,16] # P3/8
- [23,29, 43,55, 73,105] # P4/16
- [146,217, 231,300, 335,433] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, StemBlock, [64, 3, 2]], # 0-P1/2
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 2-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 4-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 6-P5/32
[-1, 1, SPP, [1024, [3,5,7]]],
[-1, 3, C3, [1024, False]], # 8
#add coordAtt
#[-1, 1, CoordAtt, [1024, False]],
#add cbam
#[-1, 1, CBAM, [1024, False]],
#add se
[-1, 1, SE, [1024, False]],
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 12
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 16 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 13], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 19 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 9], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 22 (P5/32-large)
[[16, 19, 22], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
这时候就改完了,可以直接训练啦。
加SE模块的训练结果:
修改训练权重train.py。修改epoch=100,batch_size=16。
显卡GPU如图:



100个epochs花了13个多小时呢。

这就是yolo5-face添加了se的全过程啦!
以后添加CBAM,corrdAtt.并且与没有添加注意力机制的对比!