用selenium爬取拉勾网职位信息及常见问题处理
初步爬虫框架构造
下面采用selenium进行爬虫,首先构造一下爬虫的框架,将整个程序构造为一个类,其中主要包括:获取每个详细职位信息的链接(parse_page_url)、请求/关闭详细职位信息页面(request_detail_page)、获取详细职位信息(parse_detail_page),程序中更加细致的部分则在具体过程中依据具体问题再行添加,即为如下形式:
class lagouspider():
def __init__(self):
pass
def run(self):
pass
def parse_page_url(self):
pass
def request_detail_page(self):
pass
def parse_detail_page(self):
pass
def main():
lagou = lagouspider()
lagou.run()
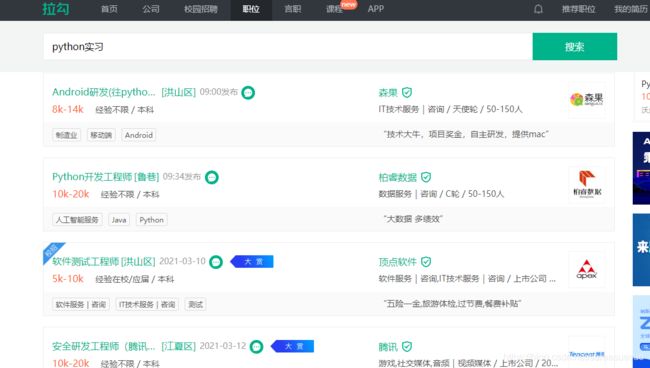
main爬取步骤
通过parse_page_url获取详细职位信息页面的网址。
要获取每个详情页面的链接,即parse_page_url部分,f12检查可以看到具体的链接网址在href属性中,这里选择使用xpath解析(//a[@class=“position_link”]/@href):
完成后则打开具体网址进行详细职位信息的爬取(parse_detail_page):
爬取数据的保存
完成翻页操作后,则考虑数据的保存问题,由于爬取的数据较多,拉勾网在爬取一段时间后容易崩溃,很难一次性爬取完成,故选择每爬取一页内容就保存一次,这里使用xlwings进行保存,单独使用一个save_positions进行保存操作。
import xlwings as xw
import pandas as pd
def save_positions(self):
save_positions = pd.DataFrame(self.positions)
# 重新开始保存下一页
self.positions = []
row = 1 + 16 * self.save_count
self.save_count += 1
print('已保存%d页'%self.save_count)
print('*'*30)
self.sheet.range('A'+str(row)).value = save_positions
self.position_file.save()
源代码
爬取结果如下:
F:\Anaconda3\python.exe E:/pystudy/scraping/lagou.py
正在获取第1页的数据
{'name': 'Python开发工程师', 'address': '武汉光谷保利国际中心', 'advantage': '大数据 多绩效', 'salary': '10k-20k·14薪 ', 'request': '武汉 , 经验不限 ,本科及以上 ,全职', 'job_descript': '\n 岗位职责:\n 1、参与各种大数据产品开发 \n 2、参与虚拟化平台产品开发 \n 3、公司安排的其他工作 \n \n \n 任职资格: \n 1、本科及以上学历,计算机相关专业;\n 2、1-2年以上Unix/Linux下Python开发经验(优秀应届生亦可); \n 3、全面并且扎实的软件知识结构(操作系统、软件工程、设计模式、数据结构、数据库系统、网络安全);\n 4、熟悉Unix/Linux操作系统原理、常用工具; \n 5、好学、责任心强、思维缜密敏捷、良好的对外沟通和团队协作能力; \n \n 对下面各领域其中一项或多项有丰富认识和开发经验的作为加分项: 数据库原理、大数据处理、并发编程、分布式系统、数据结构和算法、JVM原理及调优、编译原理\n \n ', 'company': ['柏睿数据研发部招聘']}
{'name': 'Android研发(往python后端...', 'address': '果蔬批发市场', 'advantage': '技术大牛,项目奖金,自主研发,提供mac', 'salary': '8k-14k ', 'request': '武汉 , 经验不限 ,本科及以上 ,全职', 'job_descript': '\n 公司的安卓开发任务并不会特别重,所以该岗位入职后会以培养后端开发为主,在需要时辅以安卓开发,希望找到对python后端开发有一定经验,想往后端开发发展的同事。\n \n 岗位职责:\n 1. 负责Android平板客户端、Android手机客户端的开发、测试、发布和维护\n 2. 负责在Android平台对接称、小票机等硬件设备\n 3. 配合后端研发工程师,验证和修复App测试中发现的问题\n 4. 配合团队进行相关Android应用功能的预研和研究\n \n 基本要求:\n 1. **本科及以上;\n 2. 1年以上Android开发经验,能够独立完成Android原生应用开发\n 3. 有扎实的Java功底,熟练掌握Android SDK、UI布局与控件的使用\n 4. 能根据设计和交互图完成Android应用界面高保真度开发\n 5. 熟悉Android网络通信、串口通信、蓝牙通信\n 6. 熟悉Android的应用管理、进程管理、内存管理\n 7. 理解常用的设计模式,编写高性能的应用\n 8. 学习能力强,对于新的框架、API或功能需求,可以快速掌握并应用到实际产品中\n \n 加分项:\n 1. 在各大应用市场有独立开发完成的上架App的 加分\n 2. 熟悉前后端开发或iOS开发的 加分\n 3. 对产品细节和用户体验和有较高追求的 加分\n \n 在个人简历中附上github地址或作品地址,会增加您被HR看中的机会~\n \n 注意事项:笔试面试及offer通知都会通过邮箱发放,请密切关注哦~\n \n ', 'company': ['森果技术部招聘']}
{'name': '安全研发工程师(腾讯云全资...', 'address': '腾讯武汉研发中心', 'advantage': '腾讯 西安/武汉', 'salary': '10k-20k·14薪 ', 'request': '武汉 , 经验不限 ,本科及以上 ,全职', 'job_descript': '\n 工作职责\n 1、负责自研业务安全相关工具与系统研发;\n 2、负责现有安全系统策略更新与系统维护;\n 3、参与安全相关研发技术框架和底层开发。\n 工作要求\n 1、至少熟练掌握go或Python,有系统架构能力\n 2、有过至少1-2个成熟相关安全工具、系统研发经验\n 3、了解掌握常见Web安全漏洞原理和自动化检测方法\n 4、熟悉相关开源安全系统或工具,并有一定研究\n 5、具备良好的团队合作精神,善于协调沟通,具备较强的问题定位和推动解决能力\n 6、具备较强的抗压能力,善于学习,勇于承担,主动创新,敢于挑战\n ', 'company': ['腾讯云鼎实验室招聘']}
{'name': '【2021春招】Python研发工程...', 'address': '光谷新世界T1写字楼', 'advantage': '大牛多、双休、涨薪快、行业头部、环境酷、弹性制', 'salary': '12k-20k·13薪 ', 'request': '武汉 , 在校应届 ,本科及以上 ,全职', 'job_descript': '\n 【我们需要这样的你】\n 1、有较好的逻辑思维能力,较强的抽象、概括、总结能力;\n 2、善于主动思考和行动,乐于解决具有挑战性的问题,对技术有强烈兴趣;\n 3、做事认真、严谨,具备较强的学习能力和责任心,能自我激励,善于沟通与团队协作;\n 4、使用过一门或多门编程语言(如 Go 或 Python );\n 5、使用任意框架开发过小型或中型项目;\n 6、使用过常见的互联网技术,包括但不限于数据库,缓存,消息队列。\n \n 【加分项】\n 1、高校技术团队成员;\n 2、有扎实的计算机基础(或有获得大厂 offer 者);\n 3、有过开源项目或者实践项目。\n \n 【你会获得】\n 1、丰厚的实习薪资,特别优秀者直接按正式员工待遇;\n 2、感受名校背景团队,和优秀开发者共事,和上百位优秀的伙伴一起成长;\n 3、不只是小螺丝钉,武汉高速成长公司平台,转正名额充沛,提薪机会多,发展不输大厂。\n \n 【做更好的选择】\n 武汉夜莺科技有限公司是一家专注于智能营销领域的科技公司。\n 于2016年获得知名投资机构真格基金投资;\n 于2018年获得近千万元战略融资;\n 核心业务微伴助手、壹伴助手直接或间影响国内数亿用户。\n 3年内公司估值上涨百倍,除此之外,目前仍在超高速上涨!\n 在夜莺科技=薪资水平高+福利多+氛围好+5A写字楼办公环境+大牛多+管理扁平+双休+涨薪快+弹性工作+零食下午茶+生日庆祝+节日大礼包+学习报销等等!\n 加入我们,在高速增长的企业中高速成长,和优秀的人一起创造更大的价值。\n \n ', 'company': ['夜莺科技核心研发部招聘']}
{'name': '少儿编程老师', 'address': '新发展国际中心', 'advantage': '氛围好,福利好,大牛多', 'salary': '8k-16k ', 'request': '武汉 , 经验不限 ,本科及以上 ,全职', 'job_descript': '\n 岗位职责:\n 1、在线上针对6-16岁的青少年进行编程教学,图形化(kitten)或者Python,能够使用通俗易懂亲和有趣的语言为学员讲解;\n 2、做好备课、授课,熟课、课中记录、课后总结等一系列提高教学质量的教学工作;\n 3、撰写学生培养方案、发起知识共享讲座,与同事共同进步;\n 4、为丰富课程内容制作相关课件资源;\n 5、积极协助教研、技术等部门不断优化和完善产品质量和体验。\n 岗位要求:\n 1、对教育有热情,认同少儿编程理念,愿意在编程教育行业长期发展;\n 2、普通话标准、表达能力强,有耐心,抗压能力强。\n 3、本科及以上学历优先,对编程感兴趣,有计算机/理工科类背景优先(我们有系统的入职培训+专业培训)\n ', 'company': ['编程猫招聘']}
{'name': '软件测试工程师', 'address': '关山大道光谷软件园F3栋7楼', 'advantage': '五险一金,旅游体检,过节费,餐费补贴', 'salary': '5k-10k ', 'request': '武汉 , 在校应届 ,本科及以上 ,全职', 'job_descript': '\n \n \n \n ', 'company': ['顶点软件招聘']}
{'name': '后端开发实习生', 'address': '关山大道322号保利国际中心6层', 'advantage': '免费三餐,租房补贴,带薪休假,下午茶', 'salary': '3k-6k ', 'request': '武汉 , 在校应届 ,本科及以上 ,实习', 'job_descript': '\n 职位职责:\n 1、协助开发公司核心业务系统;\n 2、根据产品需求,承担部分方案设计和编码工作。\n 职位要求:\n 1、扎实的计算机理论基础; \n 2、编程语言不限,若有 Golang 或 Python 经验更佳; \n 3、积极乐观,认真负责,乐于协作;\n 4、每周工作至少 3 天以上,能保证实习时间 3 个月以上。\n ', 'company': ['字节跳动招聘']}
{'name': '客户服务', 'address': '东湖高新技术开发区凌家山南路1号武汉光谷企业天地1号楼5层', 'advantage': '团队氛围好,晋升空间大,带薪休假', 'salary': '4k-8k ', 'request': '武汉 , 经验不限 ,大专及以上 ,全职', 'job_descript': '\n 职位职责:\n 1、维护项目多服务平台,及时解答客户及内部咨询的各类问题。\n 2、及时并妥善解决客户的诉求,维护客户的权益,与业务紧密协作,确保客户合理诉求被快速圆满解决。\n 3、执行运营侧布置的活动策划和社群运营的相关任务,辅助完成各类服务需求。\n 4、 管理和维护订单管理系统,执行退费等工单任务。\n 5、解决咨询技术侧问题及相关建议反馈,对接产品提出优化改进,提供远程服务;\n 职位要求:\n 1、大专及以上学历;\n 2、普通话标准,英语CET4;\n 3、较强的抗压能力,善于沟通,良好的服务意识和同理心;\n 4、擅长数据分析,思维清晰敏捷,熟练使用Office办公软件,掌握Python优先;\n 5、技术背景,掌握远程调试,在线教育及技术相关工作经验优先;\n ', 'company': ['字节跳动招聘']}
{'name': '测试工程师', 'address': '高新大道999号未来科技城F3栋', 'advantage': '五险一金 带薪年假 周末双休', 'salary': '8k-16k ', 'request': '武汉 , 经验不限 ,本科及以上 ,全职', 'job_descript': '\n 方向一:\n 1、本科以上学历,计算机相关专业;\n 2、一年及以上软件功能测试经验;\n 3、熟悉测试流程和规范,测试用例输出能力。\n 4、具备1年以上PC测试相关经验,有终端产品(手机、平板、PC等)测试相关工作经验者优先考虑;\n 5、具备高度的责任心和严谨的工作作风,良好的理解学习能力、团队合作精神、专业精神和质量意识。\n \n 方向二:\n 1、本科以上学历,1年以上软件测试经验;\n 2、掌握基本的软件测试理论,熟悉软件测试的基本方法、流程和规范; \n 3、能够开发测试工具或框架,进行测试需求分析、测试策略制定和自动化框架设计;\n 4、熟悉至少一门开发或者脚本语言,如python、java/javascript、go等;\n 5、具备良好的沟通能力,善于发现、分析和总结问题,有强烈的责任心,能承担较大的工作压力。\n \n 方向三:安全测试\n 1年以上软件测试经验\n 2.熟悉linux系统包括文件目录结构,基本操作命令,熟悉mysql基本的表结构、操作命令\n 3.熟悉安卓系统基本结构以及请求响应机制,有相关开发/测试经验\n 4.了解常用的安全测试技术和方法论\n 具备以下条件者优先考虑:\n 1.熟悉主流的安全测试工具:burpsuite,nmap,nessus,appscan等\n 2.有java/c/python等语言基础\n 3.了解GDPR隐私合规,并有实施经验者,有华为产品安全测试经验\n \n \n ', 'company': ['软通招聘']}
{'name': '算法工程师', 'address': '关南园四路alpha land 创意园四楼', 'advantage': '五险一金 全额公积金 每日下午茶 年度旅游', 'salary': '8k-16k·13薪 ', 'request': '武汉 , 经验不限 ,本科及以上 ,全职', 'job_descript': '\n 岗位职责:\n 1、CV、NLP等AI算法研发、论文结果复现与算法移植;\n 2、理解业务需求、分析业务数据,收集整合公开数据集及自研数据完成业务算法开发与测试;\n 3、业务算法持续优化迭代;\n 4、跟进前沿技术论文,学术与工程相结合解决实际业务问题。\n 任职要求:\n 1、本科及以上学历,计算机、数学、电子信息等理工科相关专业;\n 2、有良好数据结构/算法基础,熟练掌握python/C++/shell等编程语言,具备一定的coding基础;\n 3、良好的沟通合作能力,自我驱动力强;\n 4、有CV/NLP/ML基础,有参加过ACMICPC, NOI/IOI,Top coder,kaggle比赛优先,有ICML, NIPS, KDD, ACL, EMNLP, CVPR, ICCV, ECCV等论文优先;\n 5、有并行计算、分布式系统基础优先。\n \n ', 'company': ['轻度科技招聘']}
{'name': 'JavaScript 工程师', 'address': '光谷金融港A3栋8层', 'advantage': '六险一金', 'salary': '8k-15k ', 'request': '武汉 , 经验不限 ,本科及以上 ,全职', 'job_descript': '\n \n ', 'company': ['北京尖峰武汉分公司招聘']}
{'name': '前端开发-数据(武汉校招)', 'address': '武汉市洪山区花城大道9号软件新城A1栋3楼', 'advantage': '大平台 年终奖', 'salary': '7k-13k·15薪 ', 'request': '武汉 , 经验不限 ,本科及以上 ,全职', 'job_descript': '\n 工作职责: \n 1、协助负责本公司数据平台产品的前端开发工作。\n 2、与UI设计及后端工程师协作,高效优质完成产品界面和功能的实现。\n \n \n 任职要求: \n 1、2021届*****本科毕业,计算机相关专业,985,211院校优先\n 2、熟练掌握JavaScript、HTML、CSS;熟悉前端常用js框架及打包工具(react 、webpack),了解Mysql数据库\n 3、计算机基础扎实,对前端有浓厚的热情、熟悉常见的数据结构、算法和设计模式\n 4、沟通能力好、学习能力强、工作踏实、积极主动,有团队合作精神\n 5、加分项:在校成绩优异、有过互联网公司前端开发实习经验、熟悉其他开发语言(python、java)、可长期稳定实习\n ', 'company': ['招银云创研发交付部招聘']}
{'name': '机器学习实习工程师', 'address': '关山大道355号光谷新世界T1写字楼1105室', 'advantage': '大数据平台、专业培训、技术牛人', 'salary': '4k-5k ', 'request': '武汉 , 在校应届 ,本科及以上 ,实习', 'job_descript': '\n 工作职责:\n 1、阅读认知智能专业文献并了解其主要思想及技术路线;\n 2、在算法工程师指导下复现算法;\n 3、配合算法工程师完成数据预处理和算法网络服务封装工作;\n 4、配合算法工程师参加业内NLP算法竞赛。\n \n 任职资格:\n 1、***2022届毕业生,计算机相关专业,能够实习半年以上优先;\n 2、熟练使用Python编程语言、会使用numpy、pandas等常用库;\n 3、熟悉常见数据结构及算法,能用Python将数据库中的表格数据转化为需要的数据格式;\n 4、有结构化数据机器学习或者深度学习(计算机视觉、自然语言处理)项目经历优先;\n 5、渴望知识、热爱技术、对算法性能有执着追求,面对技术困难不怕挫折。\n ', 'company': ['百分点招聘']}
{'name': '技术美术', 'address': '金融港B24栋', 'advantage': '优秀团队、双休', 'salary': '4k-8k ', 'request': '武汉 , 在校应届 ,本科及以上 ,实习', 'job_descript': '\n \n ', 'company': ['金山世游招聘']}
{'name': '执行策划', 'address': '光谷新世界T1写字楼1211', 'advantage': '项目奖金 扁平化管理', 'salary': '4k-8k·13薪 ', 'request': '武汉 , 经验不限 ,本科及以上 ,全职', 'job_descript': '\n 岗位职责:\n 1、 配合主策搭建游戏的整体数值模型,负责游戏中各个系统及玩法的数值设定;\n 2、 负责各个系统相关的数值推演、模拟、分配与公式给出等,并根据用户需求修正和转化;\n 3、负责收集其他游戏数据,分析数值设计思路;\n 4、分析游戏数据,调节游戏数值平衡,保障游戏的稳定性。\n 任职要求:\n 1、本科及以上学历,数学相关专业,应届毕业可考虑;\n 2、对常见的手机游戏有深入了解,对欧美休闲游戏了解更佳;\n 2、熟练使用Excel,有一定Python基础,具备优秀的数学功底;\n 3、具备严密的逻辑思维能力,对游戏的数值及公式比较敏感,有足够的分析和设计能力。\n 福利待遇:\n 1、缴纳五险一金,法定节假日,带薪年假;\n 2、弹性工作时间,餐补,下午茶;\n 3、生日礼金,部门聚餐、团建;\n 4、全天候的零食小吃水果。\n ', 'company': ['易趣科技招聘']}
正在获取第2页的数据
{'name': '执行策划', 'address': '光谷新世界T1写字楼1211', 'advantage': '项目奖金 扁平化管理', 'salary': '4k-8k·13薪 ', 'request': '武汉 , 经验不限 ,本科及以上 ,全职', 'job_descript': '\n 岗位职责:\n 1、 配合主策搭建游戏的整体数值模型,负责游戏中各个系统及玩法的数值设定;\n 2、 负责各个系统相关的数值推演、模拟、分配与公式给出等,并根据用户需求修正和转化;\n 3、负责收集其他游戏数据,分析数值设计思路;\n 4、分析游戏数据,调节游戏数值平衡,保障游戏的稳定性。\n 任职要求:\n 1、本科及以上学历,数学相关专业,应届毕业可考虑;\n 2、对常见的手机游戏有深入了解,对欧美休闲游戏了解更佳;\n 2、熟练使用Excel,有一定Python基础,具备优秀的数学功底;\n 3、具备严密的逻辑思维能力,对游戏的数值及公式比较敏感,有足够的分析和设计能力。\n 福利待遇:\n 1、缴纳五险一金,法定节假日,带薪年假;\n 2、弹性工作时间,餐补,下午茶;\n 3、生日礼金,部门聚餐、团建;\n 4、全天候的零食小吃水果。\n ', 'company': ['易趣科技招聘']}
{'name': '初级大数据开发工程师', 'address': '光谷软件园F3', 'advantage': '产品靠谱 福利完善', 'salary': '9k-13k ', 'request': '武汉 , 在校应届 ,本科及以上 ,全职', 'job_descript': '\n 岗位职责:\n 1、 根据业务或数据部门所制定的数据处理任务进行ETL开发,脚本优化和数据质量检测。\n 2、负责从数据集取、转换、清洗数据到数据仓库,以及数据处理自动化功能的开发。 3、负责其他日常数据处理任务。\n \n 岗位描述:\n 1、 2021年本科及以上学历应届毕业生,计算机或软件相关专业 。 \n 2、 根据业务需求,负责日常运营报表和核心管报的数据层开发、迭代,保证数据及时、准确产出。 \n 3、 熟悉Hive/Hadoop/Spark等分布式计算框架技术,熟练编写Hive Sql并具有一定的性能优化能力; \n 4、 有Java/Python/Shell等编程经验。 \n 5、工作认真负责,逻辑思维好, 对数据敏感, 学习能力强\n \n ', 'company': ['多比特招聘']}
{'name': '数据开发(WHY1106校招)', 'address': '武汉市洪山区花城大道9号软件新城A1栋3楼', 'advantage': '大平台 年终奖', 'salary': '8k-13k·15薪 ', 'request': '武汉 , 在校应届 ,本科及以上 ,全职', 'job_descript': '\n 岗位要求:\n 1. ***本科以上学历,计算机相关专业,具备必须的数据开发理论和开发技能;\n 2. 熟练Java/python开发,有大数据相关的组件及框架应用和开发经验\n 3. 熟悉Linux操作系统,熟练shell脚本;\n 4. 熟悉主流数据库如Mysql、Oracle等,熟悉Hive及Hive SQL;\n 5. 具备良好沟通及团队协作能力,具备一定抗压能力,责任心强;\n \n \n 岗位职责:\n 1.负责数据类软件系统代码的实现,编写代码和开发文档\n 2.参与数据平台的架构设计,实时与离线数据处理服务开发\n 3.负责数据仓库日常的ETL作业开发,响应业务部门的数据提取需求\n ', 'company': ['招银云创研发交付部招聘']}
{'name': '后端开发工程师(Java、C#,Py...', 'address': '保利时代', 'advantage': '外企背景 追求技术卓越 扁平化管理 不加班', 'salary': '12k-24k ', 'request': '武汉 , 经验不限 ,本科及以上 ,全职', 'job_descript': '\n 职位描述:\n \n 岗位职责\n 1、参与系统的需求调研和需求分析;\n 2、搭建系统开发环境,完成系统框架和核心代码的实现;\n 3、负责java性能分析软件的开发;\n 4、系统开发测试、部署和集成;\n 5、负责解决开发过程中的技术问题;\n 6、参与代码维护与备份。\n \n 我们的要求\n 1. 2年以上的java/C#/C++/Ruby/Python等语言开发经验\u2028;\n 2.熟悉OO;\n 3.熟悉SQL、NoSQL等主流数据库;\n 4.有良好的编程风格,能够书写规范、优质的代码\u2028 \u2028;\n 5.良好的团队协作能力;\n \n 如果你还具备以下技能那就更好了:\n 1.喜欢阅读源代码;\n 2.热爱阅读各类技术、非技术书籍;\n 3.喜欢学习,拥有持续学习的能力,认为学习本身就是一种乐趣;\n 4.喜欢开源软件,乐于知识分享;\n 5.拥有自我管理能力,自我驱动,做自己的老板。\n \n ', 'company': ['ThoughtWorks招聘']}
{'name': '【2021春招】Golang研发工程...', 'address': '光谷新世界T1写字楼', 'advantage': '大牛多、双休、涨薪快、行业头部、环境酷、弹性制', 'salary': '10k-20k·13薪 ', 'request': '武汉 , 在校应届 ,本科及以上 ,全职', 'job_descript': '\n 【我们需要这样的你】\n 1、有较好的逻辑思维能力,较强的抽象、概括、总结能力;\n 2、善于主动思考和行动,乐于解决具有挑战性的问题,对技术有强烈兴趣;\n 3、做事认真、严谨,具备较强的学习能力和责任心,能自我激励,善于沟通与团队协作;\n 4、使用过一门或多门编程语言(如 Go 或 Python );\n 5、使用任意框架开发过小型或中型项目;\n 6、使用过常见的互联网技术,包括但不限于数据库,缓存,消息队列。\n \n 【加分项】\n 1、高校技术团队成员;\n 2、有扎实的计算机基础(或有获得大厂 offer 者);\n 3、有过开源项目或者实践项目。\n \n 【你会获得】\n 1、丰厚的实习薪资,特别优秀者直接按正式员工待遇;\n 2、感受名校背景团队,和优秀开发者共事,和上百位优秀的伙伴一起成长;\n 3、不只是小螺丝钉,武汉高速成长公司平台,转正名额充沛,提薪机会多,发展不输大厂。\n \n 【做更好的选择】\n 武汉夜莺科技有限公司是一家专注于智能营销领域的科技公司。\n 于2016年获得知名投资机构真格基金投资;\n 于2018年获得近千万元战略融资;\n 核心业务微伴助手、壹伴助手直接或间影响国内数亿用户。\n 3年内公司估值上涨百倍,除此之外,目前仍在超高速上涨!\n 在夜莺科技=薪资水平高+福利多+氛围好+5A写字楼办公环境+大牛多+管理扁平+双休+涨薪快+弹性工作+零食下午茶+生日庆祝+节日大礼包+学习报销等等!\n 加入我们,在高速增长的企业中高速成长,和优秀的人一起创造更大的价值。\n \n ', 'company': ['夜莺科技核心技术部招聘']}
Traceback (most recent call last):
File "E:/pystudy/scraping/lagou.py", line 84, in
spider.run()
File "E:/pystudy/scraping/lagou.py", line 22, in run
self.parse_detail_page(self.driver.page_source)
File "E:/pystudy/scraping/lagou.py", line 40, in parse_detail_page
name = re.findall(r'([^<]*)',self.driver.page_source)[0] # 得到职位名称
IndexError: list index out of range
Process finished with exit code 1
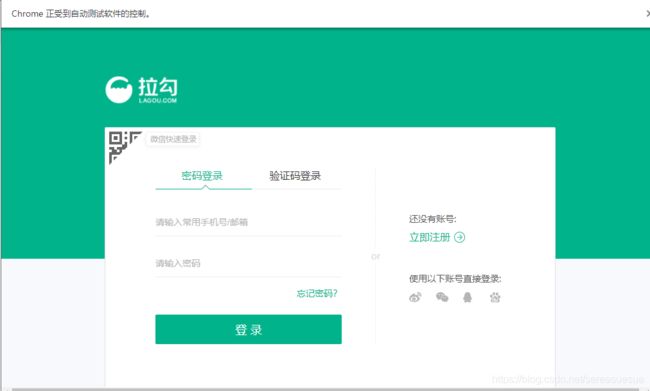
出现原因拉 出现登录页面 也有其他的出现了输入验证码阶段
常见问题及解决方法
见https://blog.csdn.net/wang_zuel/article/details/94884354
爬取过程中出现需要登录的处理
在爬取过程中,出现了需要登录,那么这里选择在爬取操作前登录账号,则可避免爬取过程中出现需要登录而中断爬取的情况,添加如下函数,这里需要注意的是在登录过程中会出现验证码,这里设置了15秒的时间输入一般是够了的,快一点输入就行(注意代码中账号密码要修改成自己的):
from selenium.webdriver.common.action_chains import ActionChains
def login(self):
loginTag = self.driver.find_element_by_css_selector('.login')
usernameTag = self.driver.find_element_by_xpath("//input[@type='text']")
passwordTag = self.driver.find_element_by_xpath("//input[@type='password']")
login = self.driver.find_element_by_xpath("//div[@class='login-btn login-password sense_login_password btn-green']")
actions = ActionChains(self.driver)
actions.move_to_element(loginTag)
actions.click(loginTag)
actions.send_keys_to_element(usernameTag,'账号')
actions.send_keys_to_element(passwordTag,'密码')
actions.move_to_element(login)
actions.click(login)
actions.perform()
# 15秒内输入验证码
time.sleep(15)爬取过程中网页崩溃的处理
同时在爬取过程中若网页崩溃,重新爬取不现实,那么这里再添加一个爬取前选择从第几页开始爬取的函数,保存后显示保存了几页的数据,方便在网页崩溃后继续爬取,
def continue_spider(self,num):
self.count_num = 15*num + 1
self.save_count = num - 1
# 当前页面页码
current_page = 1
# 循环-翻页操作
while True:
if current_page == num:
break
else:
# 下一页按钮
next_page_Btn = self.driver.find_element_by_xpath("//div[@class='pager_container']/span[last()]")
actions = ActionChains(self.driver)
actions.move_to_element(next_page_Btn)
actions.click(next_page_Btn)
actions.perform()
current_page += 1
time.sleep(1)import re
from lxml import etree
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
import time
import csv
import pandas as pd
from selenium.webdriver import Chrome
import xlwings as xw
class LagouSpider(object):
def __init__(self):
self.driver =Chrome()
self.url = 'https://www.lagou.com/jobs/list_python%E5%AE%9E%E4%B9%A0'
self.positions = []
self.count_num = 1
self.save_count = 0
self.app = xw.App(visible=True, add_book=False)
self.position_file = self.app.books.open('lagou_positions.xlsx')
self.sheet = self.position_file.sheets[0]
def run(self):
# 打开网页
self.driver.get(self.url)
# 登录操作
self.login()
# 输入从第几页开始爬取
spider_page = int(input("输入从第几页开始爬取,输入整数:"))
if spider_page > 1:
# 翻页操作(爬取中断后输入页码继续爬取操作,从第一页开始爬则输入1,从第二页开始爬则输入2)
self.continue_spider(spider_page)
# 数据爬取部分
while True:
# 等待网页加载完毕再返回源码(下一页按钮)
WebDriverWait(self.driver, timeout=10).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="pager_container"]/span[last()]')))
# 获取网页源代码
source = self.driver.page_source
# 获取详细职位信息网址
self.parse_page_url(source)
nextpage_btn = self.driver.find_element_by_xpath('//div[@class="pager_container"]/span[@action="next"]')
# 若没有下一页则跳出循环,完成爬取
if re.search(r'action="next" class="pager_next pager_next_disabled"',self.driver.page_source):
print("爬取完成!")
break
else:
nextpage_btn.click()
time.sleep(1)
def login(self):
loginTag = self.driver.find_element_by_css_selector('.login')
usernameTag = self.driver.find_element_by_xpath("//input[@type='text']")
passwordTag = self.driver.find_element_by_xpath("//input[@type='password']")
login = self.driver.find_element_by_xpath(
"//div[@class='login-btn login-password sense_login_password btn-green']")
actions = ActionChains(self.driver)
actions.move_to_element(loginTag)
actions.click(loginTag)
actions.send_keys_to_element(usernameTag, '13163203690')
actions.send_keys_to_element(passwordTag, '13163203690Aa')
actions.move_to_element(login)
actions.click(login)
actions.perform()
# 15秒内输入验证码
time.sleep(15)
def continue_spider(self, num):
self.count_num = 15 * (num - 1) + 1
self.save_count = num - 1
# 当前页面页码
current_page = 1
# 循环-翻页操作
while True:
if current_page == num:
break
else:
# 下一页按钮
next_page_Btn = self.driver.find_element_by_xpath("//div[@class='pager_container']/span[last()]")
actions = ActionChains(self.driver)
actions.move_to_element(next_page_Btn)
actions.click(next_page_Btn)
actions.perform()
current_page += 1
time.sleep(1)
def parse_page_url(self, source):
html = etree.HTML(source)
detail_links = html.xpath('//a[@class="position_link"]/@href')
for link in detail_links:
# 打开详细职位信息网址
self.request_detail_page(link)
# 暂停一秒,以免爬取过快
time.sleep(1)
def request_detail_page(self, url):
# 新建一个窗口,打开详细页面
self.driver.execute_script("window.open('%s')" % url)
# 切换到详情页面窗口
self.driver.switch_to.window(self.driver.window_handles[1])
# 等待页面加载完毕再返回源码
WebDriverWait(self.driver, timeout=20).until(
EC.presence_of_element_located((By.XPATH, '//span[@class="position-head-wrap-name"]')))
page_source = self.driver.page_source
self.parse_detail_page(page_source)
# 暂停一秒,防止爬取过快
time.sleep(1)
# 关闭挡墙详情页面,并回到上一个页面窗口
self.driver.close()
self.driver.switch_to.window(self.driver.window_handles[0])
def parse_detail_page(self,source):
detail_url = etree.HTML(source) # 解析详情页
name = re.findall(r'([^<]*)', self.driver.page_source)[0] # 得到职位名称
advantage = re.findall(r'职位诱惑:.*?([^<]*)', self.driver.page_source, re.DOTALL)[0] # 得到职位诱惑内容
job_request = detail_url.xpath('//dd[@class="job_request"]//span/text()')
salary = job_request[0] # 获取薪资
request = re.sub('[/]', '', ','.join(job_request[1:]))
job_descript = detail_url.xpath('//div[@class="job-detail"]/text()') # 获取职位描述
job_descript = ' '.join(job_descript)
address = re.findall(r'
运行出错
参考网上代码也是一样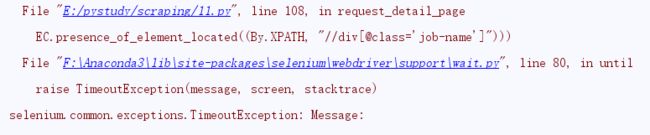
原因一 有一个页面是单独空白data原因,导致你当前窗口识别问题
运行过程中出现问题,大概爬取到30多条数据后
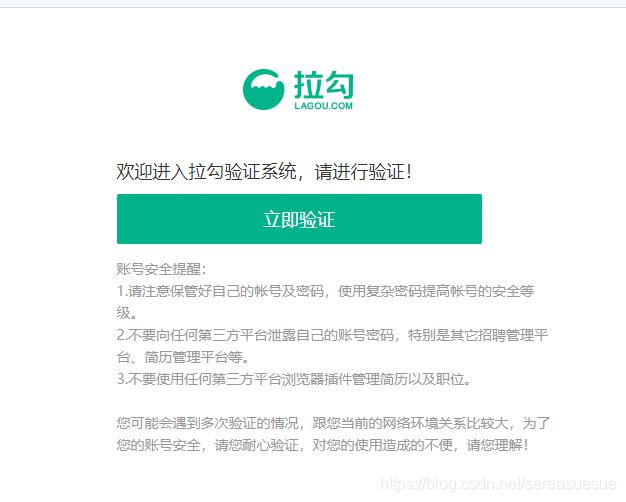
之前没有登录也是爬到30页数据让登录