梯度下降算法原理以及代码实现---机器学习
梯度下降算法GD--一种经典的优化方法
- 1.批量梯度下降算法BGD
-
- 原理
- 代码实现
- 2.随机梯度下降算法SGD
-
- 原理
- 代码实现
- 3.小批量梯度下降算法MGD
-
- 原理
- 代码实现
梯度下降算法是一种常用的一阶优化方法,是求解无约束优化问题最简单,经典的方法之一,计算过程就是沿梯度下降的方向求解极小值。
1.批量梯度下降算法BGD
原理
多元线性回归模型是: f ( x ^ i ) = x ^ i T ( X T X ) − 1 X T y f(\hat{x}_i)=\hat{x}_{i}^{T}(X^{T}X)^{-1}X^{T}y f(x^i)=x^iT(XTX)−1XTy
使用此线性回归模型的条件是 X T X X^{T}X XTX必须为满秩矩阵或者正定矩阵。而一般现实任务中往往不是满秩矩阵,比如当X的列数多于行数(即特征数超过样例数量)。
这个时候就可以用梯度下降法(迭代寻优)设法找到损失函数的最优解(最低点附近),告诉机器一个准确的方向,让它慢慢对最优解进行逼近。如下图:
(损失函数为: J θ = 1 2 m ∑ i = 1 m ( h θ ( x i ) − y i ) 2 J_{\theta}=\dfrac{1}{2m}\sum\limits_{i=1}^{m}(h_{\theta}(x^{i})-y^{i})^{2} Jθ=2m1i=1∑m(hθ(xi)−yi)2,用来估量模型的预测值 h θ h_{\theta} hθ与真实值y的不一致程度)
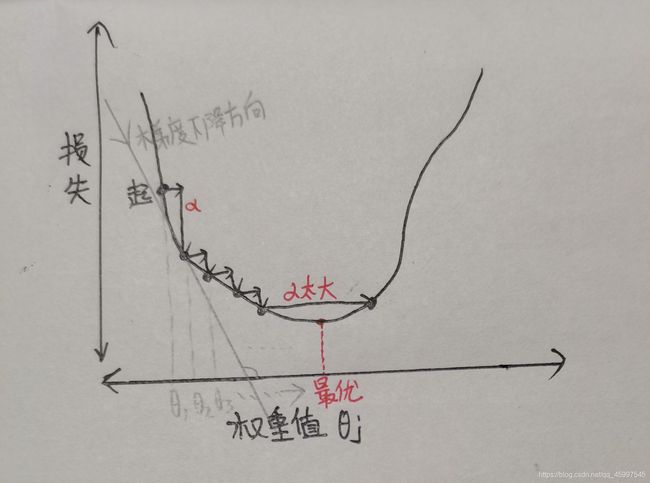
对于上图的迭代下降,还有一个很重要的概念要了解,就是学习率 α \alpha α。学习率就是梯度下降的步长, α \alpha α的大小直接决定着每次更新下降时需要挪动的步伐大小。
α \alpha α不宜太大或太小。太大会导致可能直接越过最低点,太小会影响求解速度。
上图可以看到铅笔写的 θ 1 \theta_{1} θ1, θ 2 \theta_{2} θ2, θ 3 \theta_{3} θ3…直到逼近到最优解 θ j \theta_{j} θj,这个过程就是梯度下降中的 θ \theta θ更新过程,每次下降都是一次 θ \theta θ的更新。更新公式如下:
θ j = θ j − α ∂ ∂ θ j J ( θ ) \theta_{j}=\theta_{j}-\alpha\dfrac{\partial}{\partial\theta_{j}}J(\theta) θj=θj−α∂θj∂J(θ)
代码实现
把上述思想转化为代码进行实现,最核心的是要先对更新公式进行推导,然后把推导的结果进行向量化,实现代码的转换。
由于推导过程敲打繁琐,此处只给出向量化之后的结果以及转为代码是什么样的:(老亚子,想看推导过程的还是私嗷>~<)
向量化之后: θ = θ − α 1 m X T ⋅ ( X ⋅ θ − y ) \theta=\theta-\alpha\dfrac{1}{m}X^{T}\cdot(X\cdot\theta-y) θ=θ−αm1XT⋅(X⋅θ−y)
上述结果代码:
theta=theta-alpha*np.dot(X.T,np.dot(X,theta)-Y)/m
整个批量梯度下降算法代码如下:
1.数据读取
2.数据归一化处理
3.计算损失函数
4.实现BGD算法
5.主函数预测
6.结果可视化
#代码规范化,用函数包装成代码块,不要散着写
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error,mean_squared_error,median_absolute_error,r2_score
#1.首先读取数据,写一个读取数据的函数
def getData():
data=np.loadtxt("F:/comdata/aqi2.csv",delimiter=',',skiprows=1,dtype=np.float32)
X=data[:,1:] #二维矩阵
Y=data[:,0] #打印结果为一行
Y=Y.reshape(-1,1) #将y的一行转为一列二维矩阵,行数由列数自动计算
X=dataNumalize(X) #归一化之后的X
return X,Y
#2.将特征集数据进行归一化处理,处理后的数据也是要进行输出,所以此函数要在读取数据的函数中进行调用
#归一化是对一个矩阵进行归一化,所以此函数有一个参数
#归一化使用(某个值-均值)/标准差
def dataNumalize(X):
mu=X.mean(0) #对X特征集的第一列的均值 X(n)
std=np.std(X) #S(n)
X=(X-mu)/std #将归一化处理结果赋值X
index=np.ones((len(X),1)) #最后一列1
X=np.hstack((X,index)) #进行合并 ,此合并函数只含一个参数,所以将X,index带个括号看成一个参数
return X
#3.下面计算损失函数,在损失函数中有3个参数:theta,X,Y
def lossFuncation(X,Y,theta):
m=X.shape[0] #m是X特征集的样本数,即行数
loss=sum((np.dot(X,theta)-Y)**2)/(2*m)
return loss
#4.下面实现批量下降梯度算法
#此算法的theta更新公式中有四个参数,X,Y,theta,alpha
#另外我们需要定义一个迭代次数num_iters,就是更新多少次(alpha走多少步)才能下降到最低点,每迭代一次,theta就更新一次
def BGD(X,Y,theta,alpha,num_iters):
m=X.shape[0]
loss_all=[] #定义loss值列表,把每次theta更新时跟着变动的loss函数值存入展示
for i in range(num_iters):
theta=theta-alpha*np.dot(X.T,np.dot(X,theta)-Y)/m
loss=lossFuncation(X,Y,theta)
loss_all.append(loss) #吧loss值添加到loss_all列表中去
print("第{}次的loss值为{}".format((i+1),loss))
return theta,loss_all
#5.主函数进行测试
#此测试没有区分text和predict,所有的数据用来做测试集
if __name__=='__main__':
X,Y=getData()
theta=np.ones((X.shape[1],1)) #对theta起点值进行初始化
num_iters=1000 #初始化迭代次数为500
alpha=0.01 #初始化α(下降步长)为0.01
theta,loss_all=BGD(X,Y,theta,alpha,num_iters) #调用BGD函数求theta更新参数,和每次更新后的loss函数值
print(theta)
#做模型预测
y_predict=np.dot(X,theta)
#最后进行一个模型的评价----根据模型评价指标与所的结果进行判定,结果与迭代次数有关
print("平均绝对误差:",mean_absolute_error(Y,y_predict))
print("均方误差:",mean_squared_error(Y,y_predict))
print("中之绝对误差:",median_absolute_error(Y,y_predict))
print('r2',r2_score(Y,y_predict))
#模型测试完毕,模型预测结果进行数据可视化
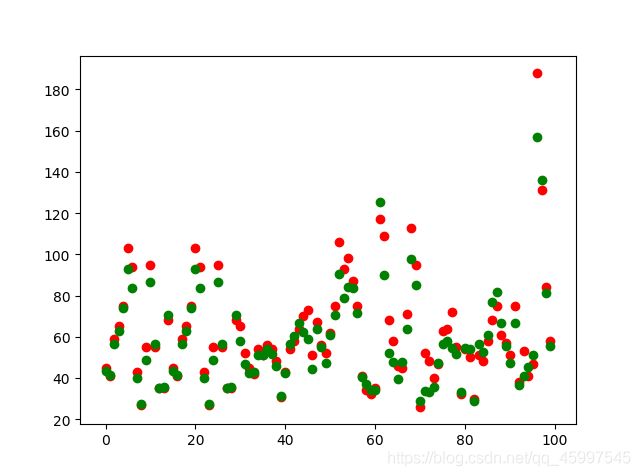
plt.scatter(np.arange(100),Y[:100],c='red') #真实label
plt.scatter(np.arange(100),y_predict[:100],c='green') #预测的label
plt.show()
#绘制损失函数随着迭代次数改变所进行变化曲线
plt.plot(np.arange(num_iters),loss_all,c='black')
#plt.show()
运行结果如图:
2.随机梯度下降算法SGD
原理
SGD与BGD的处理过程是一样的,它与批量梯度下降算法(BGD)的唯一不同是样本数的选取,BGD是用的整个样本,而SGD是随机选取某个样本进行训练预测。
它的优点就是训练速度快,缺点是准确度下降,不一定是最优解。
代码实现
#随机算法代码SGD有两种写法,
#1.步骤和批量梯度一样,只需要把数据集改为某一个数据就可以
#2.用sklearn库实现随机梯度下降算法,此代码我们使用sklearn实现
import numpy as np
from sklearn.linear_model import SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler #sklearn库中用来归一化的
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error,mean_squared_error,median_absolute_error
#1.也是要一开始读入数据
data=np.loadtxt("F:/comdata/aqi2.csv",delimiter=',',skiprows=1,dtype=np.float32)
#分片,切割数据
X=data[:,1:]
Y=data[:,0]
#数据分为测试集和训练集
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.8,random_state=42)
#2.数据预处理,把数据归一化
scaler=StandardScaler()
scaler.fit(X_train) #将训练集归一化,计算均值和方差
X=scaler.transform(X_train) #将归一化结果赋值给X
#3.计算损失函数,sklearn库会自动计算该函数
#4.训练模型:使用sklearn中的SGD随机算法更新参数,训练模型
sgd=SGDRegressor()
sgd.fit(X_train,Y_train) #使用训练集进行训练
y_predict=sgd.predict(X_test) #使用训练好的模型进行预测
print(y_predict)
#5.模型可视化
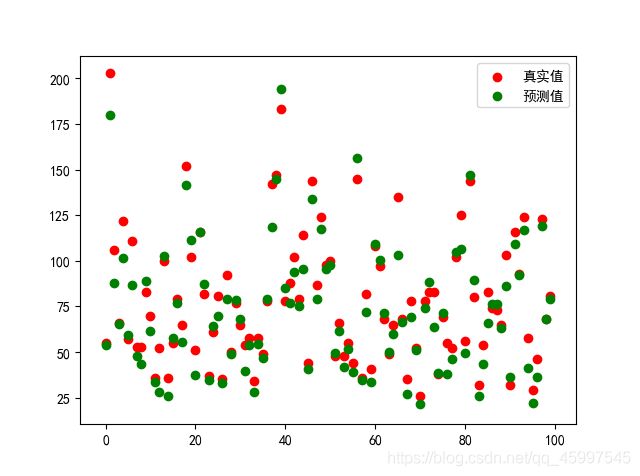
plt.scatter(np.arange(100),Y[:100],c='red')
plt.scatter(np.arange(100),y_predict[:100],c='black')
plt.show()
#6.模型的评价,评价方法解析解和sklearn都是一样的
print("平均绝对误差:",mean_absolute_error(Y_test,y_predict))
print("均方误差:",mean_squared_error(Y_test,y_predict))
print("中之绝对误差:",median_absolute_error(Y_test,y_predict))
#SGD算法速度快但准确性低,
运行结果如下图:
3.小批量梯度下降算法MGD
原理
原理同上。上面两个一个用全样本,若数据量过大会导致训练速度慢。另一个是随机选取样本,虽然训练速度快,但是准确值下降很多。
而MGD嘞,就是介于他俩之间的,训练速度即快结果也较准确。
MGD的不同也是样本数量选取不同。
MGD是在整个样本中选取小批量的样本数去进行训练。
代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error,mean_squared_error,median_absolute_error,r2_score
#读数据
def getData():
data=np.loadtxt("F:/comdata/Concrete_Data.csv",delimiter=',',skiprows=1,dtype=np.float32)
X=data[:,1:]
Y=data[:,0]
Y=Y.reshape(-1,1)
X=dataNumalize(X)
return X,Y
#数据归一化处理
def dataNumalize(X):
mu=X.mean(0)
std=np.std(X)
X=(X-mu)/std
index=np.ones((X.shape[0],1))
X=np.hstack((X,index))
return X
#计算损失函数---3个参数
def lossFunction(X,Y,theta):
m=X.shape[0]
loss=sum((np.dot(X,theta)-Y)**2)/(2*m)
return loss
#实现MGD更新theta--五个参数--要进行测试的X,Y,theta,alpha,还有迭代次数
#值得注意的是,这里我们用的测试数据是从X中随机抽取的500个小批量样本
def MGD(X,Y,theta,alpha,num_iters):
m=X.shape[0]
loss_all=[]
for i in range(num_iters):
index = np.random.choice(a=np.arange(0,m), size=1000, replace=False)
x_new = X[index]
y_new = Y[index]
theta = theta - alpha * np.dot(x_new.T, (np.dot(x_new, theta) - y_new)) / m
#theta=theta-alpha*np.dot(x_new.T,(np.dot(x_new,theta)-y_new))/m
loss=lossFunction(x_new,y_new,theta)
loss_all.append(loss)
print("第{}次的loss值为{}".format(i+1,loss))
return theta,loss_all
#主函数测试
if __name__=='__main__':
X,Y=getData()
theta=np.ones((X.shape[1],1)) #???
num_iters=1000
alpha=0.01
theta,loss_all=MGD(X,Y,theta,alpha,num_iters)
print(theta)
#模型进行数据预测
y_predict=np.dot(X,theta)
#模型的评价
print("均值误差:",mean_absolute_error(Y,y_predict))
print("mse", mean_squared_error(Y, y_predict))
print("median-ae", median_absolute_error(Y, y_predict))
print("r2", r2_score(Y, y_predict))
#数据结果可视化
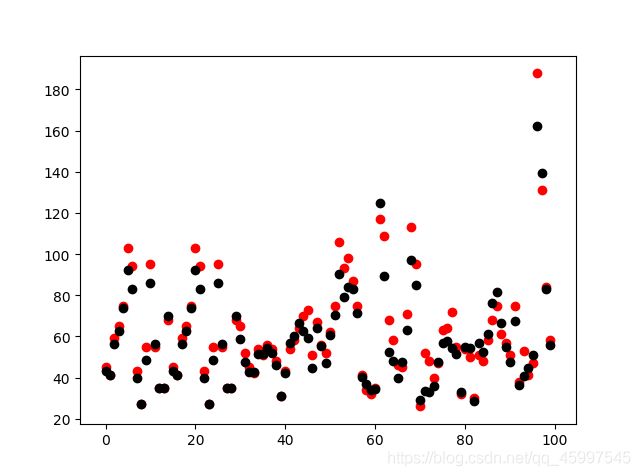
plt.scatter(np.arange(100),Y[:100],c='red')
plt.scatter(np.arange(100),y_predict[:100],c='black')
#plt.plot(np.arange(num_iters),loss_all,c='black')
plt.show()
运行结果如下:
(若有误,敬请纠错。)