基于云ModelArts的PPO算法玩“超级马里奥兄弟”【至简致远】
文章目录
- 一.前言
- 二.PPO算法的基本结构
- 三.进入实操
-
- 3.1 程序初始化
- 3.2 导入相关的库
- 3.3训练参数初始化
- 3.4 创建环境
- 3.5定义神经网络
- 3.6 定义PPO算法
- 3.7 训练模型
- 3.8 使用模型推理游戏
- 四.成果展示
一.前言
我们利用PPO算法来玩“Super Mario Bros”(超级马里奥兄弟)。目前来看,对于绝大部分关卡,智能体都可以在1500个episode内学会过关。
二.PPO算法的基本结构
PPO算法有两种主要形式:PPO-Penalty和PPO-Clip(PPO2)。在这里,我们讨论PPO-Clip(OpenAI使用的主要形式)。 PPO的主要特点如下:
PPO属于on-policy算法
PPO同时适用于离散和连续的动作空间
损失函数 PPO-Clip算法最精髓的地方就是加入了一项比例用以描绘新老策略的差异,通过超参数ϵ限制策略的更新步长:
![]()
更新策略:
![]()
探索策略 PPO采用随机探索策略。
优势函数 表示在状态s下采取动作a,相较于其他动作有多少优势,如果>0,则当前动作比平均动作好,反之,则差
![]()
算法主要流程大致如下:

三.进入实操
我们需要先进入我们的华为云实例网址,使用PPO算法玩超级马里奥兄弟
我们需要登录华为云账号,点击订阅这个实例,然后才能点击Run in ModelArts,进入 JupyterLab 页面。
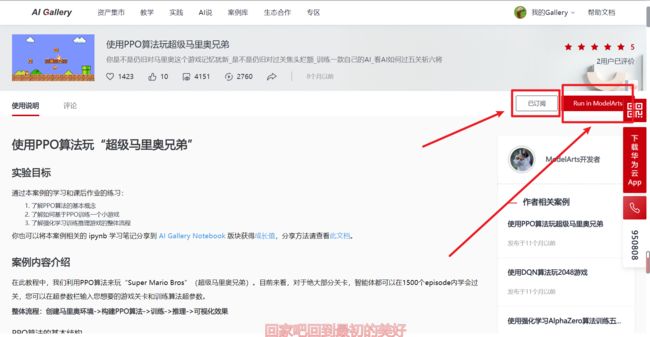
我们进入页面,先需要等待,等待30s之后弹出如下页面,让我们选择合适的运行环境,我们选择免费的就好,点击切换规格。
等待切换规格完成:等待初始化完成…
如下图,等待初始化完成。一切就绪
3.1 程序初始化
安装基础依赖
!pip install -U pip
!pip install gym==0.19.0
!pip install tqdm==4.48.0
!pip install nes-py==8.1.0
!pip install gym-super-mario-bros==7.3.2
3.2 导入相关的库
import os
import shutil
import subprocess as sp
from collections import deque
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.multiprocessing as _mp
from torch.distributions import Categorical
import torch.multiprocessing as mp
from nes_py.wrappers import JoypadSpace
import gym_super_mario_bros
from gym.spaces import Box
from gym import Wrapper
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT, COMPLEX_MOVEMENT, RIGHT_ONLY
import cv2
import matplotlib.pyplot as plt
from IPython import display
import moxing as mox

3.3训练参数初始化
opt={
"world": 1, # 可选大关:1,2,3,4,5,6,7,8
"stage": 1, # 可选小关:1,2,3,4
"action_type": "simple", # 动作类别:"simple","right_only", "complex"
'lr': 1e-4, # 建议学习率:1e-3,1e-4, 1e-5,7e-5
'gamma': 0.9, # 奖励折扣
'tau': 1.0, # GAE参数
'beta': 0.01, # 熵系数
'epsilon': 0.2, # PPO的Clip系数
'batch_size': 16, # 经验回放的batch_size
'max_episode':10, # 最大训练局数
'num_epochs': 10, # 每条经验回放次数
"num_local_steps": 512, # 每局的最大步数
"num_processes": 8, # 训练进程数,一般等于训练机核心数
"save_interval": 5, # 每{}局保存一次模型
"log_path": "./log", # 日志保存路径
"saved_path": "./model", # 训练模型保存路径
"pretrain_model": True, # 是否加载预训练模型,目前只提供1-1关卡的预训练模型,其他需要从零开始训练
"episode":5
}
3.4 创建环境
# 创建环境
def create_train_env(world, stage, actions, output_path=None):
# 创建基础环境
env = gym_super_mario_bros.make("SuperMarioBros-{}-{}-v0".format(world, stage))
env = JoypadSpace(env, actions)
# 对环境自定义
env = CustomReward(env, world, stage, monitor=None)
env = CustomSkipFrame(env)
return env
# 对原始环境进行修改,以获得更好的训练效果
class CustomReward(Wrapper):
def __init__(self, env=None, world=None, stage=None, monitor=None):
super(CustomReward, self).__init__(env)
self.observation_space = Box(low=0, high=255, shape=(1, 84, 84))
self.curr_score = 0
self.current_x = 40
self.world = world
self.stage = stage
if monitor:
self.monitor = monitor
else:
self.monitor = None
def step(self, action):
state, reward, done, info = self.env.step(action)
if self.monitor:
self.monitor.record(state)
state = process_frame(state)
reward += (info["score"] - self.curr_score) / 40.
self.curr_score = info["score"]
if done:
if info["flag_get"]:
reward += 50
else:
reward -= 50
if self.world == 7 and self.stage == 4:
if (506 <= info["x_pos"] <= 832 and info["y_pos"] > 127) or (
832 < info["x_pos"] <= 1064 and info["y_pos"] < 80) or (
1113 < info["x_pos"] <= 1464 and info["y_pos"] < 191) or (
1579 < info["x_pos"] <= 1943 and info["y_pos"] < 191) or (
1946 < info["x_pos"] <= 1964 and info["y_pos"] >= 191) or (
1984 < info["x_pos"] <= 2060 and (info["y_pos"] >= 191 or info["y_pos"] < 127)) or (
2114 < info["x_pos"] < 2440 and info["y_pos"] < 191) or info["x_pos"] < self.current_x - 500:
reward -= 50
done = True
if self.world == 4 and self.stage == 4:
if (info["x_pos"] <= 1500 and info["y_pos"] < 127) or (
1588 <= info["x_pos"] < 2380 and info["y_pos"] >= 127):
reward = -50
done = True
self.current_x = info["x_pos"]
return state, reward / 10., done, info
def reset(self):
self.curr_score = 0
self.current_x = 40
return process_frame(self.env.reset())
class MultipleEnvironments:
def __init__(self, world, stage, action_type, num_envs, output_path=None):
self.agent_conns, self.env_conns = zip(*[mp.Pipe() for _ in range(num_envs)])
if action_type == "right_only":
actions = RIGHT_ONLY
elif action_type == "simple":
actions = SIMPLE_MOVEMENT
else:
actions = COMPLEX_MOVEMENT
self.envs = [create_train_env(world, stage, actions, output_path=output_path) for _ in range(num_envs)]
self.num_states = self.envs[0].observation_space.shape[0]
self.num_actions = len(actions)
for index in range(num_envs):
process = mp.Process(target=self.run, args=(index,))
process.start()
self.env_conns[index].close()
def run(self, index):
self.agent_conns[index].close()
while True:
request, action = self.env_conns[index].recv()
if request == "step":
self.env_conns[index].send(self.envs[index].step(action.item()))
elif request == "reset":
self.env_conns[index].send(self.envs[index].reset())
else:
raise NotImplementedError
def process_frame(frame):
if frame is not None:
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
frame = cv2.resize(frame, (84, 84))[None, :, :] / 255.
return frame
else:
return np.zeros((1, 84, 84))
class CustomSkipFrame(Wrapper):
def __init__(self, env, skip=4):
super(CustomSkipFrame, self).__init__(env)
self.observation_space = Box(low=0, high=255, shape=(skip, 84, 84))
self.skip = skip
self.states = np.zeros((skip, 84, 84), dtype=np.float32)
def step(self, action):
total_reward = 0
last_states = []
for i in range(self.skip):
state, reward, done, info = self.env.step(action)
total_reward += reward
if i >= self.skip / 2:
last_states.append(state)
if done:
self.reset()
return self.states[None, :, :, :].astype(np.float32), total_reward, done, info
max_state = np.max(np.concatenate(last_states, 0), 0)
self.states[:-1] = self.states[1:]
self.states[-1] = max_state
return self.states[None, :, :, :].astype(np.float32), total_reward, done, info
def reset(self):
state = self.env.reset()
self.states = np.concatenate([state for _ in range(self.skip)], 0)
return self.states[None, :, :, :].astype(np.float32)
3.5定义神经网络
class Net(nn.Module):
def __init__(self, num_inputs, num_actions):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(num_inputs, 32, 3, stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv3 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv4 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.linear = nn.Linear(32 * 6 * 6, 512)
self.critic_linear = nn.Linear(512, 1)
self.actor_linear = nn.Linear(512, num_actions)
self._initialize_weights()
def _initialize_weights(self):
for module in self.modules():
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear):
nn.init.orthogonal_(module.weight, nn.init.calculate_gain('relu'))
nn.init.constant_(module.bias, 0)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = self.linear(x.view(x.size(0), -1))
return self.actor_linear(x), self.critic_linear(x)
3.6 定义PPO算法
def evaluation(opt, global_model, num_states, num_actions,curr_episode):
print('start evalution !')
torch.manual_seed(123)
if opt['action_type'] == "right":
actions = RIGHT_ONLY
elif opt['action_type'] == "simple":
actions = SIMPLE_MOVEMENT
else:
actions = COMPLEX_MOVEMENT
env = create_train_env(opt['world'], opt['stage'], actions)
local_model = Net(num_states, num_actions)
if torch.cuda.is_available():
local_model.cuda()
local_model.eval()
state = torch.from_numpy(env.reset())
if torch.cuda.is_available():
state = state.cuda()
plt.figure(figsize=(10,10))
img = plt.imshow(env.render(mode='rgb_array'))
done=False
local_model.load_state_dict(global_model.state_dict()) #加载网络参数\
while not done:
if torch.cuda.is_available():
state = state.cuda()
logits, value = local_model(state)
policy = F.softmax(logits, dim=1)
action = torch.argmax(policy).item()
state, reward, done, info = env.step(action)
state = torch.from_numpy(state)
img.set_data(env.render(mode='rgb_array')) # just update the data
display.display(plt.gcf())
display.clear_output(wait=True)
if info["flag_get"]:
print("flag getted in episode:{}!".format(curr_episode))
torch.save(local_model.state_dict(),
"{}/ppo_super_mario_bros_{}_{}_{}".format(opt['saved_path'], opt['world'], opt['stage'],curr_episode))
opt.update({'episode':curr_episode})
env.close()
return True
return False
def train(opt):
#判断cuda是否可用
if torch.cuda.is_available():
torch.cuda.manual_seed(123)
else:
torch.manual_seed(123)
if os.path.isdir(opt['log_path']):
shutil.rmtree(opt['log_path'])
os.makedirs(opt['log_path'])
if not os.path.isdir(opt['saved_path']):
os.makedirs(opt['saved_path'])
mp = _mp.get_context("spawn")
#创建环境
envs = MultipleEnvironments(opt['world'], opt['stage'], opt['action_type'], opt['num_processes'])
#创建模型
model = Net(envs.num_states, envs.num_actions)
if opt['pretrain_model']:
print('加载预训练模型')
if not os.path.exists("ppo_super_mario_bros_1_1_0"):
mox.file.copy_parallel(
"obs://modelarts-labs-bj4/course/modelarts/zjc_team/reinforcement_learning/ppo_mario/ppo_super_mario_bros_1_1_0",
"ppo_super_mario_bros_1_1_0")
if torch.cuda.is_available():
model.load_state_dict(torch.load("ppo_super_mario_bros_1_1_0"))
model.cuda()
else:
model.load_state_dict(torch.load("ppo_super_mario_bros_1_1_0",torch.device('cpu')))
else:
model.cuda()
model.share_memory()
optimizer = torch.optim.Adam(model.parameters(), lr=opt['lr'])
#环境重置
[agent_conn.send(("reset", None)) for agent_conn in envs.agent_conns]
#接收当前状态
curr_states = [agent_conn.recv() for agent_conn in envs.agent_conns]
curr_states = torch.from_numpy(np.concatenate(curr_states, 0))
if torch.cuda.is_available():
curr_states = curr_states.cuda()
curr_episode = 0
#在最大局数内训练
while curr_episode 0:
torch.save(model.state_dict(),
"{}/ppo_super_mario_bros_{}_{}_{}".format(opt['saved_path'], opt['world'], opt['stage'], curr_episode))
curr_episode += 1
old_log_policies = []
actions = []
values = []
states = []
rewards = []
dones = []
#一局内最大步数
for _ in range(opt['num_local_steps']):
states.append(curr_states)
logits, value = model(curr_states)
values.append(value.squeeze())
policy = F.softmax(logits, dim=1)
old_m = Categorical(policy)
action = old_m.sample()
actions.append(action)
old_log_policy = old_m.log_prob(action)
old_log_policies.append(old_log_policy)
#执行action
if torch.cuda.is_available():
[agent_conn.send(("step", act)) for agent_conn, act in zip(envs.agent_conns, action.cpu())]
else:
[agent_conn.send(("step", act)) for agent_conn, act in zip(envs.agent_conns, action)]
state, reward, done, info = zip(*[agent_conn.recv() for agent_conn in envs.agent_conns])
state = torch.from_numpy(np.concatenate(state, 0))
if torch.cuda.is_available():
state = state.cuda()
reward = torch.cuda.FloatTensor(reward)
done = torch.cuda.FloatTensor(done)
else:
reward = torch.FloatTensor(reward)
done = torch.FloatTensor(done)
rewards.append(reward)
dones.append(done)
curr_states = state
_, next_value, = model(curr_states)
next_value = next_value.squeeze()
old_log_policies = torch.cat(old_log_policies).detach()
actions = torch.cat(actions)
values = torch.cat(values).detach()
states = torch.cat(states)
gae = 0
R = []
#gae计算
for value, reward, done in list(zip(values, rewards, dones))[::-1]:
gae = gae * opt['gamma'] * opt['tau']
gae = gae + reward + opt['gamma'] * next_value.detach() * (1 - done) - value.detach()
next_value = value
R.append(gae + value)
R = R[::-1]
R = torch.cat(R).detach()
advantages = R - values
#策略更新
for i in range(opt['num_epochs']):
indice = torch.randperm(opt['num_local_steps'] * opt['num_processes'])
for j in range(opt['batch_size']):
batch_indices = indice[
int(j * (opt['num_local_steps'] * opt['num_processes'] / opt['batch_size'])): int((j + 1) * (
opt['num_local_steps'] * opt['num_processes'] / opt['batch_size']))]
logits, value = model(states[batch_indices])
new_policy = F.softmax(logits, dim=1)
new_m = Categorical(new_policy)
new_log_policy = new_m.log_prob(actions[batch_indices])
ratio = torch.exp(new_log_policy - old_log_policies[batch_indices])
actor_loss = -torch.mean(torch.min(ratio * advantages[batch_indices],
torch.clamp(ratio, 1.0 - opt['epsilon'], 1.0 + opt['epsilon']) *
advantages[
batch_indices]))
critic_loss = F.smooth_l1_loss(R[batch_indices], value.squeeze())
entropy_loss = torch.mean(new_m.entropy())
#损失函数包含三个部分:actor损失,critic损失,和动作entropy损失
total_loss = actor_loss + critic_loss - opt['beta'] * entropy_loss
optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
print("Episode: {}. Total loss: {}".format(curr_episode, total_loss))
finish=False
for i in range(opt["num_processes"]):
if info[i]["flag_get"]:
finish=evaluation(opt, model,envs.num_states, envs.num_actions,curr_episode)
if finish:
break
if finish:
break
3.7 训练模型
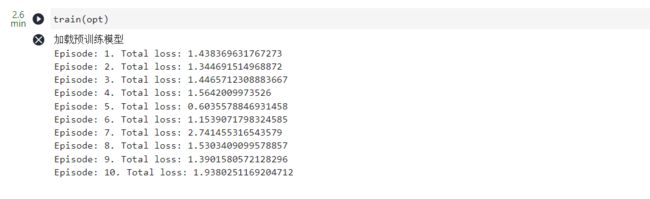
训练10 Episode,耗时约5分钟
train(opt)
这里比较费时间哈,多等待,正在训练模型中…
我这里花了2.6分钟哈,还是比较快的,如图:
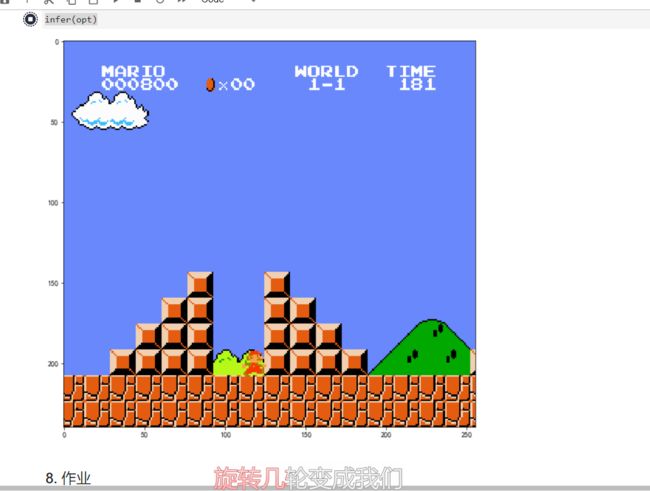
3.8 使用模型推理游戏
定义推理函数
def infer(opt):
if torch.cuda.is_available():
torch.cuda.manual_seed(123)
else:
torch.manual_seed(123)
if opt['action_type'] == "right":
actions = RIGHT_ONLY
elif opt['action_type'] == "simple":
actions = SIMPLE_MOVEMENT
else:
actions = COMPLEX_MOVEMENT
env = create_train_env(opt['world'], opt['stage'], actions)
model = Net(env.observation_space.shape[0], len(actions))
if torch.cuda.is_available():
model.load_state_dict(torch.load("{}/ppo_super_mario_bros_{}_{}_{}".format(opt['saved_path'],opt['world'], opt['stage'],opt['episode'])))
model.cuda()
else:
model.load_state_dict(torch.load("{}/ppo_super_mario_bros_{}_{}_{}".format(opt['saved_path'], opt['world'], opt['stage'],opt['episode']),
map_location=torch.device('cpu')))
model.eval()
state = torch.from_numpy(env.reset())
plt.figure(figsize=(10,10))
img = plt.imshow(env.render(mode='rgb_array'))
while True:
if torch.cuda.is_available():
state = state.cuda()
logits, value = model(state)
policy = F.softmax(logits, dim=1)
action = torch.argmax(policy).item()
state, reward, done, info = env.step(action)
state = torch.from_numpy(state)
img.set_data(env.render(mode='rgb_array')) # just update the data
display.display(plt.gcf())
display.clear_output(wait=True)
if info["flag_get"]:
print("World {} stage {} completed".format(opt['world'], opt['stage']))
break
if done and info["flag_get"] is False:
print('Game Failed')
break
运行
infer(opt)