LaMDA2|谷歌目前最先进的对话AI发布!
卷友们好,我是rumor。
又到了一年一度的谷歌I/O大会,I/O是Innovation in the Open的缩写,每一年谷歌都会发布一些新的产品以及能力,因此这个大会广受关注。我之前申请GDE(谷歌开发者专家)的motivation之一就是为了免费出国参加I/O大会这个福利,没想到形势一直不好,希望过两年能白嫖上。
话说远了,即使不能到现场,也能在线上参加呀!打开这个网页,你将进入谷歌大礼包的世界:
https://adventure.withgoogle.com/io/在这里不仅能学习,还能开宝箱找各种装备,也能跟人聊天,甚至还能摸鱼:

而且这个地图极其的大,我各种迷路,估计没有个一天是集齐不了所有装备的。
又扯远了,下面就来聊聊我关注的几个点,大会主题演讲可在小破站观看:
https://www.bilibili.com/video/BV1Dr4y1t7akLaMDA 2
经过了Meena、LaMDA之后,谷歌终于跟GPT一样,开始用序号省去命名的麻烦了。谷歌CEO Sundar在演讲中介绍道,LaMDA 2是谷歌目前最先进的对话AI。模型和paper当然是还没放出来,不过有一些demo可以尝尝鲜,给我的感觉是没有太惊喜但也还不错(对,我就是站着说话不腰疼)。
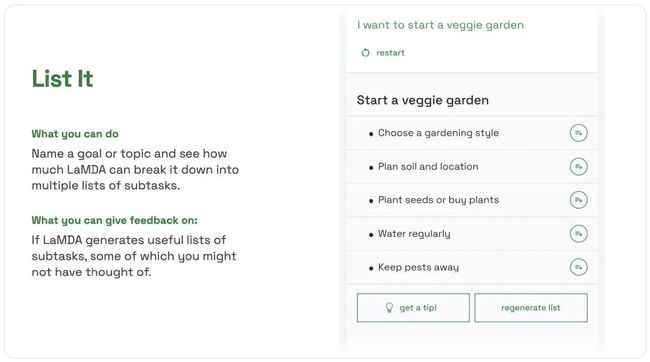
第一个能力,是想象力(Imagine it)。
人类测试者可以输入一个场景,比如「想象我在海里最深处」,之后LaMDA会给出一些关于场景的描述,测试者可以根据模型推荐的问题,或者自己输入,继续往下探索LaMDA想象力的极限。
老实说对于这个能力我没想到啥高价值应用点,难道去辅助魔幻小说写作?
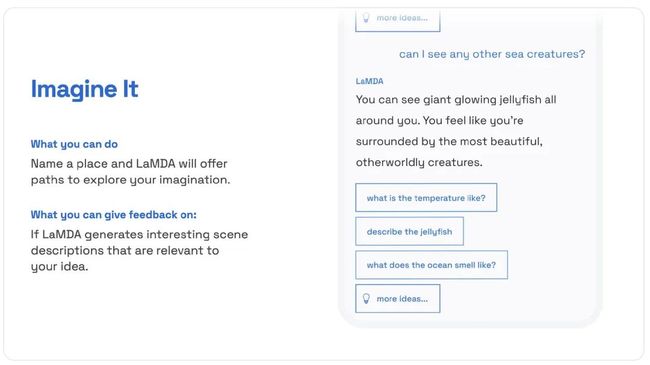
第二个能力,是既开放又不跑题(Talk about it)。
聊天机器人的跑题已经司空见惯了,是一个绝对的痛点。在这个设定里,测试者可以随便问问题,但模型会尽量保持在一个话题上。不过现在只能谈论狗这个话题,看来通用性还不太确定。
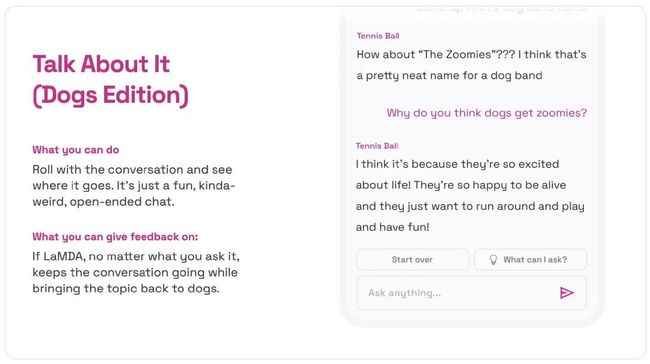
第三个能力,是理解复杂任务并进行拆解(List it)。
这是个从Demo看上去没啥应用点,但细思恐极的能力。测试者发送一个想要做的事儿,LaMDA会把它按顺序拆解成几步,而且有的步骤甚至还能往下拆。
乍一看上去这个能力没啥用,我现在的搜索能力这么强,还用模型教我做事?顶多问个菜谱啥的,但短视频它不香吗?
但what if。。。执行者不是我呢?
WHAT IF跟前段时间这个机器人的工作串起来,你告诉它我要吃西红柿炒鸡蛋,然后他就把任务拆解好去执行了呢?

上面这些Demo之后都会开放在AI Test Kitchen这个APP中,目前已经对数千名谷歌员工开放测试了,大家可以帮忙反馈更多LaMDA的问题,或者提供更好的监督数据。
其他AI的落地
除了LaMDA 2之外,演讲中还提到了很多其他场景下AI的落地。
540B 参数的PaLM
PaLM是Pathways架构下公布的第一个语言模型,除了虐了一下GPT-3之外,他还有两个突出能力。
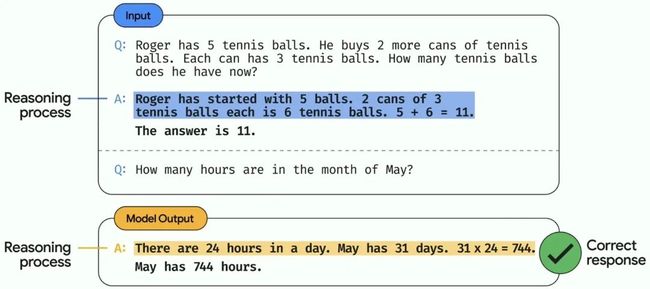
第一是谷歌提出的Chain-of-thought prompting,通过给PaLM输入解题过程,让模型具备更好的推理能力。
第二是跨语言问答,说实话当初看论文时我没太注意,PaLM在从没见过孟加拉语和英语的平行预料的情况下,居然能用孟加拉语回答问题,作者们也surprise了一下。

更自然的语言交互
自然语言交互一直是我很期待的一个落地点。智能音箱在市场上的整体反响也不错,不过用过的人都知道,真正跟那个音响自然交互太难了。谷歌提出了以下三点改进:
Look and talk:模拟人之间的对话发起方式,先眼神交互,然后就能直接说话了
Quick phrases:一些定义好的快捷短语,可以直接出发指令(怎么觉得是个机器反向训练人类的案例
为了保护隐私和性能,开发了更轻量的语音识别和NLU模型,直接部署在机器上
单语翻译训练
谷歌翻译真是很良心了,由于一些小语种没有足够的平行语料,谷歌提出了单语训练的翻译模型,增加了24种新语言。
文档&对话摘要
工作后才知道,有太多的群聊和文档需要看了,谷歌在办公应用中引入了摘要能力,为大家节省时间。
3D建模整个世界
谷歌地图马上就可以利用图片来构建整个世界的3D地图了,甚至连餐馆都可以,CV太可怕了。

Multi Search
目前我们的多模态搜索,一般都是照个照片搜索里面的一个物体。而谷歌的Multi Search可以同时识别画面中所有能理解的东西,并且根据知识图谱给出更多信息。

总结
今天没什么可总结的,谷歌tql,这个强一方面是research,另一方面是工程落地能力,我们也要加油吖。

我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「FLAG:明年我要去!」