机器学习——深度神经网络实践(FCN、CNN、BP)
目录
系列文章目录
一、CNN(卷积神经网络)与FCN(全连接网络)的异同
1.相同点
2.区别
二、神经网络前向后向传播算法的优化迭代公式
三、深度神经网络算法的应用
1.人脸识别
1.1 数据导入
1.2 模型搭建与使用
1.3 结果与分析
2.手写体识别
2.1 基于BP神经网络的手写数字识别代码
2.2 结果与分析
3.图像分类
3.1 模型构建过程与结果
3.2 初次预训练分类
3.3 Fine tune训练
四、创新神经网络算法的设计
五、其他
1. 数据集及资源
2. 参考资料
总结
系列文章目录
本系列博客重点在机器学习的概念原理与代码实践,不包含繁琐的数学推导(有问题欢迎在评论区讨论指出,或直接私信联系我)。
第一章 机器学习——PCA(主成分分析)与人脸识别_@李忆如的博客-CSDN博客
第二章 机器学习——LDA (线性判别分析) 与人脸识别_@李忆如的博客-CSDN博客
第三章 机器学习——LR(线性回归)、LRC(线性回归分类)与人脸识别_@李忆如的博客
第四章 机器学习——SVM(支持向量机)与人脸识别_@李忆如的博客
第五章 机器学习——K-means(聚类)与人脸识别_@李忆如的博客-CSDN博客
第六章 机器学习——深度神经网络实践
梗概
本篇博客主要介绍深度神经网络(FNC、CNN、BP等)算法的概念与原理以及相关分析推导,比较了FCN与CNN的异同,推导了神经网络前向后向传播算法的优化迭代公式。并将将深度神经网络算法运用于解决实际问题(以人脸识别、手写体识别、图像分类为例)。另外,针对经典神经网络的不足,设计了全新深度神经网络算法,从多方面、多角度进行了优化(内附数据集与python代码)。
一、CNN(卷积神经网络)与FCN(全连接网络)的异同
1.相同点
①结构相似:两种神经网络都是通过一层一层的节点组织起来的,每一个节点就是一个神经元,且节点之间都部分或两两存在边相连。
②流程相似:卷积神经网络的输入输出以及训练的流程和全连接神经网络也基本一致,以图像分类为列,卷积神经网络的输入层就是图像的原始图像,而输出层中的每一个节点代表了不同类别的可信度。这和全连接神经网络的输入输出是一致的。类似的,全连接神经网络的损失函数以及参数的优化过程也都适用于卷积神经网络。
2.区别
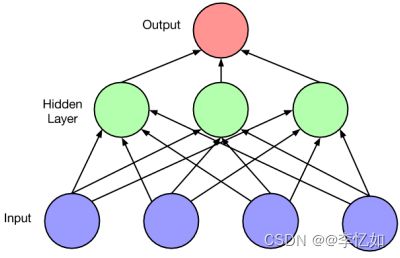
两者之间的主要区别是神经网络相邻两层的连接方式。在全连接神经网络中,每相邻两层之间的节点都有边相连,而对于卷积神经网络,相邻两层之间只有部分节点相连。正因为二者之间的上述区别,导致全连接神经网络无法很好地处理图像数据(随着数据与网络层数的增多,参数数量爆炸,计算速度变慢,容易出现过拟合问题),而卷积神经网络却克服了这一缺点。区别与两算法流程大致如下图:

二、神经网络前向后向传播算法的优化迭代公式
BP图模型:
网络中单个激活单元:
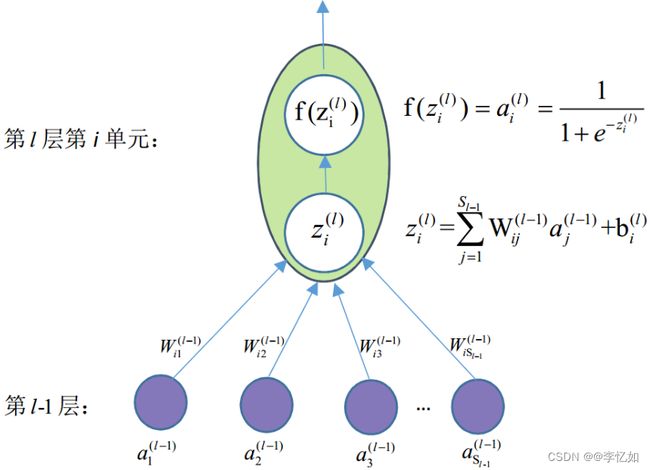
Tips:上图定了隐层中的激活单元,该隐层激活单元中含有一个偏置项b。相关运算如图所示,符号右上角角标为单元在网络中的层好,结合代码实现时,网络激活单元之间的权重一般保存在前一层的单元中。
损失函数定义:
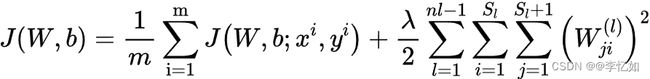
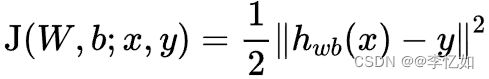
具体前向后向传播算法的优化迭代公式推导可见:
神经网络前向后向传播推导及实现_liangxinGao的博客-CSDN博客
详解神经网络的前向传播和反向传播(从头推导)_Maples丶丶的博客-CSDN博客
三、深度神经网络算法的应用
1.人脸识别
Pycharm中对ORL数据集进行基于CNN的深度神经网络的模型搭建并用于人脸识别,代码如下:
1.1 数据导入
import numpy
import pandas
from PIL import Image
from keras import backend as K
from keras.utils import np_utils
"""
加载图像数据的函数,dataset_path即图像olivettifaces的路径
加载olivettifaces后,划分为train_data,valid_data,test_data三个数据集
函数返回train_data,valid_data,test_data以及对应的label
"""
# 400个样本,40个人,每人10张样本图。每张样本图高57*宽47,需要2679个像素点。每个像素点做了归一化处理
def load_data(dataset_path):
img = Image.open(dataset_path)
img_ndarray = numpy.asarray(img, dtype='float64') / 256
print(img_ndarray.shape)
faces = numpy.empty((400,57,47))
for row in range(20):
for column in range(20):
faces[row * 20 + column] = img_ndarray[row * 57:(row + 1) * 57, column * 47:(column + 1) * 47]
# 设置400个样本图的标签
label = numpy.empty(400)
for i in range(40):
label[i * 10:i * 10 + 10] = i
label = label.astype(numpy.int)
label = np_utils.to_categorical(label, 40) # 将40分类类标号转化为one-hot编码
# 分成训练集、验证集、测试集,大小如下
train_data = numpy.empty((320, 57,47)) # 320个训练样本
train_label = numpy.empty((320,40)) # 320个训练样本,每个样本40个输出概率
valid_data = numpy.empty((40, 57,47)) # 40个验证样本
valid_label = numpy.empty((40,40)) # 40个验证样本,每个样本40个输出概率
test_data = numpy.empty((40, 57,47)) # 40个测试样本
test_label = numpy.empty((40,40)) # 40个测试样本,每个样本40个输出概率
for i in range(40):
train_data[i * 8:i * 8 + 8] = faces[i * 10:i * 10 + 8]
train_label[i * 8:i * 8 + 8] = label[i * 10:i * 10 + 8]
valid_data[i] = faces[i * 10 + 8]
valid_label[i] = label[i * 10 + 8]
test_data[i] = faces[i * 10 + 9]
test_label[i] = label[i * 10 + 9]
return [(train_data, train_label), (valid_data, valid_label),(test_data, test_label)]
if __name__ == '__main__':
[(train_data, train_label), (valid_data, valid_label), (test_data, test_label)] = load_data('olivettifaces.gif')
oneimg = train_data[0]*256
print(oneimg)
im = Image.fromarray(oneimg)
im.show()
1.2 模型搭建与使用
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D
from PIL import Image
import FaceData
# 全局变量
batch_size = 128 # 批处理样本数量
nb_classes = 40 # 分类数目
epochs = 23000 # 迭代次数
img_rows, img_cols = 57, 47 # 输入图片样本的宽高
nb_filters = 32 # 卷积核的个数
pool_size = (2, 2) # 池化层的大小
kernel_size = (5, 5) # 卷积核的大小
input_shape = (img_rows, img_cols, 1) # 输入图片的维度
[(X_train, Y_train), (X_valid, Y_valid), (X_test, Y_test)] = FaceData.load_data('olivettifaces.gif')
X_train = X_train[:, :, :, np.newaxis] # 添加一个维度,代表图片通道。这样数据集共4个维度,样本个数、宽度、高度、通道数
X_valid = X_valid[:, :, :, np.newaxis] # 添加一个维度,代表图片通道。这样数据集共4个维度,样本个数、宽度、高度、通道数
X_test = X_test[:, :, :, np.newaxis] # 添加一个维度,代表图片通道。这样数据集共4个维度,样本个数、宽度、高度、通道数
print('样本数据集的维度:', X_train.shape, Y_train.shape)
print('测试数据集的维度:', X_test.shape, Y_test.shape)
# 构建模型
model = Sequential()
model.add(Conv2D(6, kernel_size, input_shape=input_shape, strides=1)) # 卷积层1
model.add(AveragePooling2D(pool_size=pool_size, strides=2)) # 池化层
model.add(Conv2D(12, kernel_size, strides=1)) # 卷积层2
model.add(AveragePooling2D(pool_size=pool_size, strides=2)) # 池化层
model.add(Flatten()) # 拉成一维数据
model.add(Dense(nb_classes)) # 全连接层2
model.add(Activation('sigmoid')) # sigmoid评分
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
# 训练模型
model.fit(X_train, Y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_valid, Y_valid))
# 评估模型
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])
y_pred = model.predict(X_test)
y_pred = y_pred.argmax(axis=1) # 获取概率最大的分类,获取每行最大值所在的列
for i in range(len(y_pred)):
oneimg = X_test[i, :, :, 0] * 256
im = Image.fromarray(oneimg)
# im.show()
print('第%d个人识别为第%d个人' % (i, y_pred[i]))
1.3 结果与分析
在Pycharm中对ORL数据集进行基于CNN的深度神经网络的模型搭建并用于人脸识别,分别记录损失与人脸识别率随迭代次数epoch的变化关系,结果如下列图表:

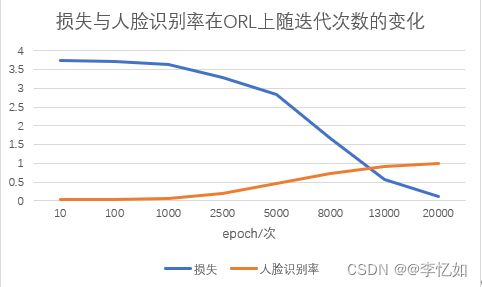
分析:在ORL数据集下,随着迭代次数的增加,CNN深度神经网络模型效果逐渐变好,表现为损失率不断下降,人脸识别率不断升高(在20000次迭代后高达99.37%),优于大部分算法。
2.手写体识别
Pycharm中对Mnist数据集进行基于BP的深度神经网络的模型搭建用于手写数字识别,代码如下:
2.1 基于BP神经网络的手写数字识别代码
import numpy as np
from sklearn.datasets import load_digits
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
# 载入数据
digits = load_digits()
# 显示图片
for i in range(min(digits.images.shape[0], 2)):
plt.imshow(digits.images[i], cmap='gray')
plt.show()
# 数据
X = digits.data
# 标签
y = digits.target
# 定义一个神经网络,结构,64-100-
# 定义输入层到隐藏层之间的权值矩阵
V = np.random.random((64, 100)) * 2 - 1
# 定义隐藏层到输出层之间的权值矩阵
W = np.random.random((100, 10)) * 2 - 1
# 数据切分
# 1/4为测试集,3/4为训练集
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 标签二值化
# 0 -> 1000000000
# 3 -> 0003000000
# 9 -> 0000000001
labels_train = LabelBinarizer().fit_transform(y_train)
# 激活函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 激活函数的导数
def dsigmoid(x):
return x * (1 - x)
# 训练模型
def train(X, y, steps=10000, lr=0.011):
global V, W
for n in range(steps + 1):
# 随机选取一个数据
i = np.random.randint(X.shape[0])
# 获取一个数据
x = X[i]
x = np.atleast_2d(x)
# BP算法公式
# 计算隐藏层的输出
L1 = sigmoid(np.dot(x, V))
# 计算输出层的输出
L2 = sigmoid(np.dot(L1, W))
# 计算L2_delta,L1_delta
L2_delta = (y[i] - L2) * dsigmoid(L2)
L1_delta = L2_delta.dot(W.T) * dsigmoid(L1)
# 更新权值
W += lr * L1.T.dot(L2_delta)
V += lr * x.T.dot(L1_delta)
# 每训练1000次预测一次准确率
if n % 1000 == 0:
output = predict(X_test)
predictions = np.argmax(output, axis=1)
acc = np.mean(np.equal(predictions, y_test))
dW = L1.T.dot(L2_delta)
dV = x.T.dot(L1_delta)
gradient = np.sum([np.sqrt(np.sum(np.square(j))) for j in [dW, dV]])
print('steps', n, 'accuracy', acc, 'gradient', gradient)
# print(classification_report(predictions,y_test))
def predict(x):
# 计算隐藏层的输出
L1 = sigmoid(np.dot(x, V))
# 计算输出层的输出
L2 = sigmoid(np.dot(L1, W))
return L2
# 开始训练
train(X_train, labels_train, 20000, lr=0.11)
train(X_train, labels_train, 20000, lr=0.011)
# 训练后结果对比
output = predict(X_test)
predictions = np.argmax(output, axis=1)
acc = np.mean(np.equal(predictions, y_test))
print('accuracy', acc)
print(classification_report(predictions, y_test, digits=4))
2.2 结果与分析
在Pycharm中对Mnist数据集进行基于BP的深度神经网络的模型搭建并用于手写数字识别,记录识别率随迭代次数epoch的变化关系,结果如下列图表:
![]()

分析:在Mnist数据集下,随着迭代次数的增加,BP深度神经网络模型效果逐渐变好,表现为识别率不断升高(在10000次迭代后基本稳定在96%左右)。
3.图像分类
本部分主要是使用MindSpore(CPU)版通过Fine-Tuning训练一个猫狗分类模型(华为云实验),整体实验流程如下:
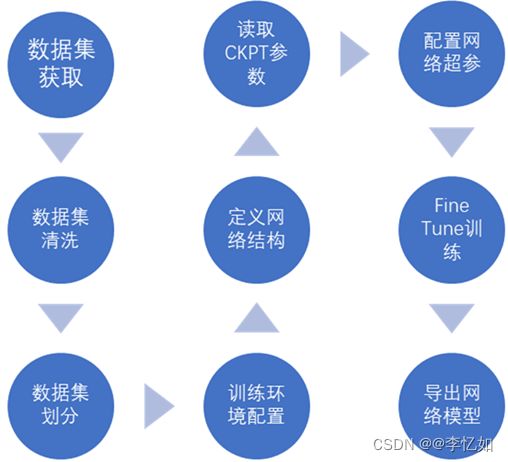
3.1 模型构建过程与结果
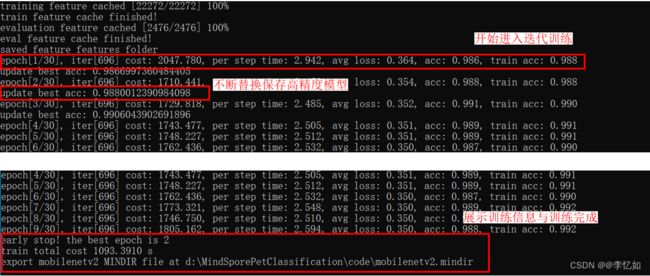
模型构建的过程与结果如图所示:
3.2 初次预训练分类
初次预训练分类结果如下:

分析:context_device_init函数初始化了训练环境,后续定义了网络结构,读取了CKPT参数、配置了网络超参。但在预训练中读取了backbone的参数之后就直接进行了预测,并展示了结果,从结果中可以发现预测精度不足。
3.3 Fine tune训练
Fine tune训练过后,结果如下:
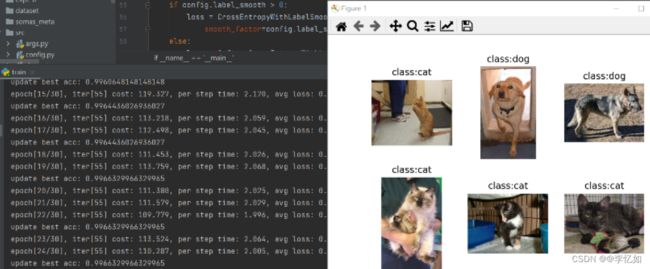
分析:预训练后又定义了优化器、学习率、损失函数。正式Fine tune训练过后,原数据集文件中会产生几个npy文件,该问卷主要保存训练过程中的相关变量与标签,后续,网络完成了本地训练并成功获取了MindIR模型,从上图可知,Fine tune训练后正确率提高,分类准确,模型搭建成功。
四、创新神经网络算法的设计
① 经典CNN的不足:结果过拟合、在有监督问题中表现不佳、特征理解较差、可解释性差
② 可优化方向:数据处理、卷积方式设计、架构设计、激活函数选取原则、优化器选择等
③ 优化指标:模型准确率、训练速度、内存消耗
④ 创新神经网络算法流程简述:
一.数据的清洗与增强:对于数据的选择与清洗不到位,得到的结果往往会出现过拟合。根据应用场景使用不同的数据增强方法提升数据质量,同时针对数据偏斜/不均衡的情况,可以加入过采样、降采样、SMOTE、集成学习、类别权重、改变学习方法等,或直接使用数据加载器批训练。
二.精妙的卷积设计:在卷积设计中加入一些能够在没有太多的准确率损失的情况下加速 CNN 的运行,并减少内存消耗的方法,如MobileNets(深度分离卷积)、XNOR-Net(二进制卷积)、ShuffleNet(使用点组卷积和通道随机化)、Network Pruning(删除 CNN 的部分权重)
三.卷积核因素(选择加入):通常来说,更大的卷积核准确率越高,但训练速度会变慢消耗内存也会更多,并且较大的卷积核会导致网络泛化能力很差,扩张卷积样例如下:

Tips:在卷积核的权重之间使用空格。使得网络不用增加参数量就能够扩展感受野,意味着没有增加内存消耗。该方法已经被证明可以在微小的速度权衡下就能增加网络准确率。
四.网络规模(宽度/深度)的合理扩充:因为GPU是并行处理的,增加宽度相对于增加深度对GPU更加友好,许多研究也表明加宽网络比加深网络也更加容易训练。但宽度与深度带来的好处受制于边际效应,增加的每层的宽度越大,通过增加层宽而带来的模型性能提升也会越少,因此要合理选择。
五.激活函数选取优化:根据工程经验,通常使用 ReLU 会在开始的时立即得到一些好的结果,但如果当ReLU得不到好的结果的适合,可以换成Sigmoid函数,如果还是不行则调整模型其它的部分,以尝试对准确率做提升。都得不到好结果的情况下,可以试着使用ELU、PReLU 、Sigmoid或者LeakyReLU等激活函数。
六.优化器选择优化:应用于图片分类问题的简单CNN,使用不同优化器的训练增速效果如下:
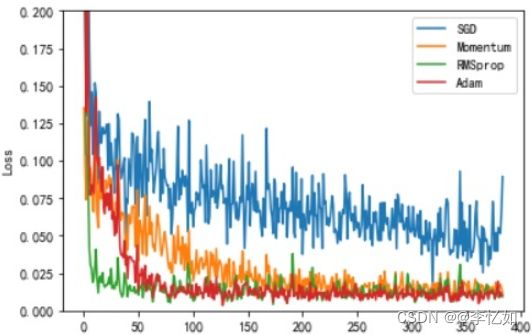
分析:合理选择优化器,如果得到还不错的结果则对模型进行其他超参数的调优。切记学习率不要设置太高。甚至可以组合使用,在前面使用快速的优化器设置较低学习效率,在训练的后半程选择较慢的优化器,进行组合优化器。
五、其他
1. 数据集及资源
本实验所用数据集:ORL5646、Mnist、猫狗数据集。
常用人脸数据集如下(不要白嫖哈哈哈)
链接:https://pan.baidu.com/s/12Le0mKEquGMgh5fhNagZGw
提取码:yrnb
深度神经网络应用完整代码与所需数据集:李忆如/忆如的机器学习 - Gitee.com
2. 参考资料
1.全卷积神经网络(FCN)和卷积神经网络(CNN)的主要区别_偶尔躺平的咸鱼的博客-CSDN
2.神经网络前向后向传播推导及实现_liangxinGao的博客-CSDN博客
3.keras/Face_Recognition at master · data-infra/keras · GitHub
4.神经网络实现手写字体识别_myourdream2的博客-CSDN博客_神经网络字体识别
5.《人工智能导论》深度学习实验手册
6.CNN(卷积神经网络)-优化指南 - 知乎 (zhihu.com)
总结
深度神经网络作为深度学习中热门且重要的研究领域,其中大多数算法(CNN、BP等)在机器学习与模式识别领域的实际任务中都有着超越各种经典算法的优异表现。且深度神经网络处理大数据任务有着不俗表现,发展潜力巨大。但同时其仍然存在大量不足,首当其冲就是模型的选择与构建,以及深度学习方法的通病——可解释性差与鲁棒性挑战。这都会大大影响实验结果,所以如何用好深度神经网络,如何选择模型、优化算法是深度学习领域一个很重要的问题。