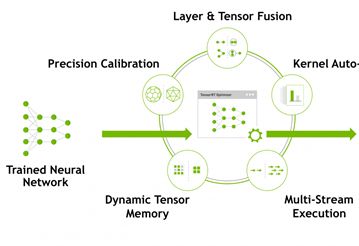
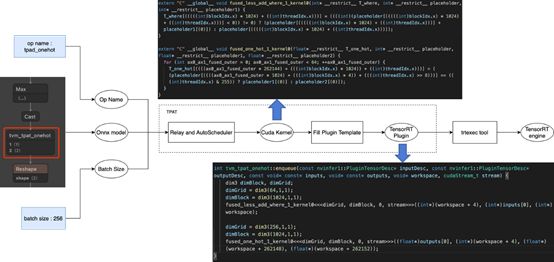
- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 将cmd中命令输出保存为txt文本文件
落难Coder
Windowscmdwindow
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
- 推荐3家毕业AI论文可五分钟一键生成!文末附免费教程!
小猪包333
写论文人工智能AI写作深度学习计算机视觉
在当前的学术研究和写作领域,AI论文生成器已经成为许多研究人员和学生的重要工具。这些工具不仅能够帮助用户快速生成高质量的论文内容,还能进行内容优化、查重和排版等操作。以下是三款值得推荐的AI论文生成器:千笔-AIPassPaper、懒人论文以及AIPaperPass。千笔-AIPassPaper千笔-AIPassPaper是一款基于深度学习和自然语言处理技术的AI写作助手,旨在帮助用户快速生成高质
- AI大模型的架构演进与最新发展
季风泯灭的季节
AI大模型应用技术二人工智能架构
随着深度学习的发展,AI大模型(LargeLanguageModels,LLMs)在自然语言处理、计算机视觉等领域取得了革命性的进展。本文将详细探讨AI大模型的架构演进,包括从Transformer的提出到GPT、BERT、T5等模型的历史演变,并探讨这些模型的技术细节及其在现代人工智能中的核心作用。一、基础模型介绍:Transformer的核心原理Transformer架构的背景在Transfo
- [实践应用] 深度学习之模型性能评估指标
YuanDaima2048
深度学习工具使用深度学习人工智能损失函数性能评估pytorchpython机器学习
文章总览:YuanDaiMa2048博客文章总览深度学习之模型性能评估指标分类任务回归任务排序任务聚类任务生成任务其他介绍在机器学习和深度学习领域,评估模型性能是一项至关重要的任务。不同的学习任务需要不同的性能指标来衡量模型的有效性。以下是对一些常见任务及其相应的性能评估指标的详细解释和总结。分类任务分类任务是指模型需要将输入数据分配到预定义的类别或标签中。以下是分类任务中常用的性能指标:准确率(
- [实践应用] 深度学习之优化器
YuanDaima2048
深度学习工具使用pytorch深度学习人工智能机器学习python优化器
文章总览:YuanDaiMa2048博客文章总览深度学习之优化器1.随机梯度下降(SGD)2.动量优化(Momentum)3.自适应梯度(Adagrad)4.自适应矩估计(Adam)5.RMSprop总结其他介绍在深度学习中,优化器用于更新模型的参数,以最小化损失函数。常见的优化函数有很多种,下面是几种主流的优化器及其特点、原理和PyTorch实现:1.随机梯度下降(SGD)原理:随机梯度下降通过
- 生成式地图制图
Bwywb_3
深度学习机器学习深度学习生成对抗网络
生成式地图制图(GenerativeCartography)是一种利用生成式算法和人工智能技术自动创建地图的技术。它结合了传统的地理信息系统(GIS)技术与现代生成模型(如深度学习、GANs等),能够根据输入的数据自动生成符合需求的地图。这种方法在城市规划、虚拟环境设计、游戏开发等多个领域具有应用前景。主要特点:自动化生成:通过算法和模型,系统能够根据输入的地理或空间数据自动生成地图,而无需人工逐
- 吴恩达深度学习笔记(30)-正则化的解释
极客Array
正则化(Regularization)深度学习可能存在过拟合问题——高方差,有两个解决方法,一个是正则化,另一个是准备更多的数据,这是非常可靠的方法,但你可能无法时时刻刻准备足够多的训练数据或者获取更多数据的成本很高,但正则化通常有助于避免过拟合或减少你的网络误差。如果你怀疑神经网络过度拟合了数据,即存在高方差问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,这也是非常
- 个人学习笔记7-6:动手学深度学习pytorch版-李沐
浪子L
深度学习深度学习笔记计算机视觉python人工智能神经网络pytorch
#人工智能##深度学习##语义分割##计算机视觉##神经网络#计算机视觉13.11全卷积网络全卷积网络(fullyconvolutionalnetwork,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换。引入l转置卷积(transposedconvolution)实现的,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即该位置对应像素的类别预测。13.11.1构造模型下
- 深度学习-点击率预估-研究论文2024-09-14速读
sp_fyf_2024
深度学习人工智能
深度学习-点击率预估-研究论文2024-09-14速读1.DeepTargetSessionInterestNetworkforClick-ThroughRatePredictionHZhong,JMa,XDuan,SGu,JYao-2024InternationalJointConferenceonNeuralNetworks,2024深度目标会话兴趣网络用于点击率预测摘要:这篇文章提出了一种新
- 损失函数与反向传播
Star_.
PyTorchpytorch深度学习python
损失函数定义与作用损失函数(lossfunction)在深度学习领域是用来计算搭建模型预测的输出值和真实值之间的误差。1.损失函数越小越好2.计算实际输出与目标之间的差距3.为更新输出提供依据(反向传播)常见的损失函数回归常见的损失函数有:均方差(MeanSquaredError,MSE)、平均绝对误差(MeanAbsoluteErrorLoss,MAE)、HuberLoss是一种将MSE与MAE
- 【深度学习】训练过程中一个OOM的问题,太难查了
weixin_40293999
深度学习深度学习人工智能
现象:各位大佬又遇到过ubuntu的这个问题么?现象是在训练过程中,ssh上不去了,能ping通,没死机,但是ubunutu的pc侧的显示器,鼠标啥都不好用了。只能重启。问题原因:OOM了95G,尼玛!!!!pytorch爆内存了,然后journald假死了,在journald被watchdog干掉之后,系统就崩溃了。这种规模的爆内存一般,即使被oomkill了,也要卡半天的,确实会这样,能不能配
- 云服务业界动态简报-20180128
Captain7
一、青云青云QingCloud推出深度学习平台DeepLearningonQingCloud,包含了主流的深度学习框架及数据科学工具包,通过QingCloudAppCenter一键部署交付,可以让算法工程师和数据科学家快速构建深度学习开发环境,将更多的精力放在模型和算法调优。二、腾讯云1.腾讯云正式发布腾讯专有云TCE(TencentCloudEnterprise)矩阵,涵盖企业版、大数据版、AI
- 机器学习VS深度学习
nfgo
机器学习
机器学习(MachineLearning,ML)和深度学习(DeepLearning,DL)是人工智能(AI)的两个子领域,它们有许多相似之处,但在技术实现和应用范围上也有显著区别。下面从几个方面对两者进行区分:1.概念层面机器学习:是让计算机通过算法从数据中自动学习和改进的技术。它依赖于手动设计的特征和数学模型来进行学习,常用的模型有决策树、支持向量机、线性回归等。深度学习:是机器学习的一个子领
- 大数据毕业设计hadoop+spark+hive知识图谱租房数据分析可视化大屏 租房推荐系统 58同城租房爬虫 房源推荐系统 房价预测系统 计算机毕业设计 机器学习 深度学习 人工智能
2401_84572577
程序员大数据hadoop人工智能
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。我先来介绍一下这些东西怎么用,文末抱走。(1)Python所有方向的学习路线(
- 深度学习-13-小语言模型之SmolLM的使用
皮皮冰燃
深度学习深度学习
文章附录1SmolLM概述1.1SmolLM简介1.2下载模型2运行2.1在CPU/GPU/多GPU上运行模型2.2使用torch.bfloat162.3通过位和字节的量化版本3应用示例4问题及解决4.1attention_mask和pad_token_id报错4.2max_new_tokens=205参考附录1SmolLM概述1.1SmolLM简介SmolLM是一系列尖端小型语言模型,提供三种规
- 基于深度学习的农作物病害检测
SEU-WYL
深度学习dnn深度学习人工智能
基于深度学习的农作物病害检测利用卷积神经网络(CNN)、生成对抗网络(GAN)、Transformer等深度学习技术,自动识别和分类农作物的病害,帮助农业工作者提高作物管理效率、减少损失。1.农作物病害检测的挑战病害种类繁多:农作物病害的类型多样,不同病害在同一作物上的表现差异很大,同时同一种病害在不同生长阶段的症状也可能不同。环境影响:天气、光照、湿度等外部环境因素会影响农作物的表现,使得病害检
- 基于深度学习的文本引导的图像编辑
SEU-WYL
深度学习dnn深度学习人工智能
基于深度学习的文本引导的图像编辑(Text-GuidedImageEditing)是一种通过自然语言文本指令对图像进行编辑或修改的技术。它结合了图像生成和自然语言处理(NLP)的最新进展,使用户能够通过描述性文本对图像内容进行精确的调整和操控。1.文本引导的图像编辑的挑战文本和图像之间的对齐:如何将文本中的语义信息准确地映射到图像中的特定区域或元素是一个关键挑战。这涉及到多模态数据的对齐和理解。编
- 深度学习--对抗生成网络(GAN, Generative Adversarial Network)
Ambition_LAO
深度学习生成对抗网络
对抗生成网络(GAN,GenerativeAdversarialNetwork)是一种深度学习模型,由IanGoodfellow等人在2014年提出。GAN主要用于生成数据,通过两个神经网络相互对抗,来生成以假乱真的新数据。以下是对GAN的详细阐述,包括其概念、作用、核心要点、实现过程、代码实现和适用场景。1.概念GAN由两个神经网络组成:生成器(Generator)和判别器(Discrimina
- 深度学习:怎么看pth文件的参数
奥利给少年
深度学习人工智能
.pth文件是PyTorch模型的权重文件,它通常包含了训练好的模型的参数。要查看或使用这个文件,你可以按照以下步骤操作:1.确保你有模型的定义你需要有创建这个.pth文件时所用的模型的代码。这意味着你需要有模型的类定义和架构。2.加载模型权重使用PyTorch的load_state_dict方法来加载权重。这里是如何操作的:importtorchimporttorch.nnasnn#定义模型结构
- chatgpt赋能python:如何在Python中安装Keras库?
turensu
ChatGptpythonchatgptkeras计算机
如何在Python中安装Keras库?Keras是一个简单易用的神经网络库,由FrançoisChollet编写。它在Python编程语言中实现了深度学习的功能,可以使您更轻松地构建和试验不同类型的神经网络。如果您是一名Python开发人员,肯定会想知道如何在您的Python项目中安装Keras库。在本文中,我们将向您展示如何安装和配置Keras库。步骤1:安装Python要使用Keras库,您需
- 如何理解深度学习的训练过程
奋斗的草莓熊
深度学习人工智能pythonscikit-learnvirtualenvnumpypandas
文章目录1.训练是干什么?2.预训练模型进行训练,主要更改的是预训练模型的什么东西?1.训练是干什么?以yolov5为例子,训练的目的是把一组输入猫狗图像放到神经网络中,得到一个输出模型,这个模型下次可以直接用来识别哪个是猫,哪个是狗2.预训练模型进行训练,主要更改的是预训练模型的什么东西?超参数(Hyperparameters):这是模型结构中定义的参数,比如:卷积核大小(kernel_size
- Keras深度学习框架入门及实战指南
司莹嫣Maude
Keras深度学习框架入门及实战指南keraskeras-team/keras:是一个基于Python的深度学习库,它没有使用数据库。适合用于深度学习任务的开发和实现,特别是对于需要使用Python深度学习库的场景。特点是深度学习库、Python、无数据库。项目地址:https://gitcode.com/gh_mirrors/ke/keras一、项目介绍Keras简介Keras是一款高级神经网络
- 深度学习驱动的车牌识别:技术演进与未来挑战
逼子歌
深度学习车牌识别神经网络字符识别YOLO卷积神经网络
一、引言1.1研究背景在当今社会,智能交通系统的发展日益重要,而车牌识别作为其关键组成部分,发挥着至关重要的作用。车牌识别技术广泛应用于交通管理、停车场管理、安防监控等领域。在交通管理中,它可以用于车辆识别、交通违法监控和车流统计等,提高交通管理的效率和准确性。在停车场管理中,实现车辆的自动识别和收费,提升管理和服务水平。在安防监控领域,可用于追踪嫌疑人及犯罪行为。深度学习的出现为车牌识别带来了重
- 每天五分钟玩转深度学习PyTorch:模型参数优化器torch.optim
幻风_huanfeng
深度学习框架pytorch深度学习pytorch人工智能神经网络机器学习优化算法
本文重点在机器学习或者深度学习中,我们需要通过修改参数使得损失函数最小化(或最大化),优化算法就是一种调整模型参数更新的策略。在pytorch中定义了优化器optim,我们可以使用它调用封装好的优化算法,然后传递给它神经网络模型参数,就可以对模型进行优化。本文是学习第6步(优化器),参考链接pytorch的学习路线随机梯度下降算法在深度学习和机器学习中,梯度下降算法是最常用的参数更新方法,它的公式
- 什么是AIGC?有哪些免费工具?
chent_某位
AIGC
AIGC(AIGeneratedContent),即“人工智能生成内容”,是指通过人工智能技术自动生成各种类型的数字内容。AIGC让机器能够根据输入的信息或数据生成符合人类需求的文本、图像、音频、视频等内容,极大提高了内容创作的效率。AIGC的背景与起源随着深度学习和自然语言处理技术的快速发展,人工智能已经不再局限于简单的任务,如分类、预测和数据分析,而是具备了生成内容的能力。生成式AI模型,如O
- transformer架构(Transformer Architecture)原理与代码实战案例讲解
AI架构设计之禅
大数据AI人工智能Python入门实战计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
transformer架构(TransformerArchitecture)原理与代码实战案例讲解关键词:Transformer,自注意力机制,编码器-解码器,预训练,微调,NLP,机器翻译作者:禅与计算机程序设计艺术/ZenandtheArtofComputerProgramming1.背景介绍1.1问题的由来自然语言处理(NLP)领域的发展经历了从规则驱动到统计驱动再到深度学习驱动的三个阶段。
- 如何有效的学习AI大模型?
Python程序员罗宾
学习人工智能语言模型自然语言处理架构
学习AI大模型是一个系统性的过程,涉及到多个学科的知识。以下是一些建议,帮助你更有效地学习AI大模型:基础知识储备:数学基础:学习线性代数、概率论、统计学和微积分等,这些是理解机器学习算法的数学基础。编程技能:掌握至少一种编程语言,如Python,因为大多数AI模型都是用Python实现的。理论学习:机器学习基础:了解监督学习、非监督学习、强化学习等基本概念。深度学习:学习神经网络的基本结构,如卷
- 【深度学习】【OnnxRuntime】【Python】模型转化、环境搭建以及模型部署的详细教程
牙牙要健康
深度学习onnxonnxruntime深度学习python人工智能
【深度学习】【OnnxRuntime】【Python】模型转化、环境搭建以及模型部署的详细教程提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论文章目录【深度学习】【OnnxRuntime】【Python】模型转化、环境搭建以及模型部署的详细教程前言模型转换--pytorch转onnxWindows平台搭建依赖环境onnxruntime调用onnx模型ONNXRuntime推理核
- 基于深度学习的多模态信息检索
SEU-WYL
深度学习dnn深度学习人工智能
基于深度学习的多模态信息检索(MultimodalInformationRetrieval,MMIR)是指利用深度学习技术,从包含多种模态(如文本、图像、视频、音频等)的数据集中检索出满足用户查询意图的相关信息。这种方法不仅可以处理单一模态的数据,还可以在多种模态之间建立关联,从而更准确地满足用户需求。1.多模态信息检索的挑战异构数据表示:多模态数据通常具有不同的特征和表示形式(如文本的词嵌入与图
- ASM系列六 利用TreeApi 添加和移除类成员
lijingyao8206
jvm动态代理ASM字节码技术TreeAPI
同生成的做法一样,添加和移除类成员只要去修改fields和methods中的元素即可。这里我们拿一个简单的类做例子,下面这个Task类,我们来移除isNeedRemove方法,并且添加一个int 类型的addedField属性。
package asm.core;
/**
* Created by yunshen.ljy on 2015/6/
- Springmvc-权限设计
bee1314
springWebjsp
万丈高楼平地起。
权限管理对于管理系统而言已经是标配中的标配了吧,对于我等俗人更是不能免俗。同时就目前的项目状况而言,我们还不需要那么高大上的开源的解决方案,如Spring Security,Shiro。小伙伴一致决定我们还是从基本的功能迭代起来吧。
目标:
1.实现权限的管理(CRUD)
2.实现部门管理 (CRUD)
3.实现人员的管理 (CRUD)
4.实现部门和权限
- 算法竞赛入门经典(第二版)第2章习题
CrazyMizzz
c算法
2.4.1 输出技巧
#include <stdio.h>
int
main()
{
int i, n;
scanf("%d", &n);
for (i = 1; i <= n; i++)
printf("%d\n", i);
return 0;
}
习题2-2 水仙花数(daffodil
- struts2中jsp自动跳转到Action
麦田的设计者
jspwebxmlstruts2自动跳转
1、在struts2的开发中,经常需要用户点击网页后就直接跳转到一个Action,执行Action里面的方法,利用mvc分层思想执行相应操作在界面上得到动态数据。毕竟用户不可能在地址栏里输入一个Action(不是专业人士)
2、<jsp:forward page="xxx.action" /> ,这个标签可以实现跳转,page的路径是相对地址,不同与jsp和j
- php 操作webservice实例
IT独行者
PHPwebservice
首先大家要简单了解了何谓webservice,接下来就做两个非常简单的例子,webservice还是逃不开server端与client端。我测试的环境为:apache2.2.11 php5.2.10做这个测试之前,要确认你的php配置文件中已经将soap扩展打开,即extension=php_soap.dll;
OK 现在我们来体验webservice
//server端 serve
- Windows下使用Vagrant安装linux系统
_wy_
windowsvagrant
准备工作:
下载安装 VirtualBox :https://www.virtualbox.org/
下载安装 Vagrant :http://www.vagrantup.com/
下载需要使用的 box :
官方提供的范例:http://files.vagrantup.com/precise32.box
还可以在 http://www.vagrantbox.es/
- 更改linux的文件拥有者及用户组(chown和chgrp)
无量
clinuxchgrpchown
本文(转)
http://blog.163.com/yanenshun@126/blog/static/128388169201203011157308/
http://ydlmlh.iteye.com/blog/1435157
一、基本使用:
使用chown命令可以修改文件或目录所属的用户:
命令
- linux下抓包工具
矮蛋蛋
linux
原文地址:
http://blog.chinaunix.net/uid-23670869-id-2610683.html
tcpdump -nn -vv -X udp port 8888
上面命令是抓取udp包、端口为8888
netstat -tln 命令是用来查看linux的端口使用情况
13 . 列出所有的网络连接
lsof -i
14. 列出所有tcp 网络连接信息
l
- 我觉得mybatis是垃圾!:“每一个用mybatis的男纸,你伤不起”
alafqq
mybatis
最近看了
每一个用mybatis的男纸,你伤不起
原文地址 :http://www.iteye.com/topic/1073938
发表一下个人看法。欢迎大神拍砖;
个人一直使用的是Ibatis框架,公司对其进行过小小的改良;
最近换了公司,要使用新的框架。听说mybatis不错;就对其进行了部分的研究;
发现多了一个mapper层;个人感觉就是个dao;
- 解决java数据交换之谜
百合不是茶
数据交换
交换两个数字的方法有以下三种 ,其中第一种最常用
/*
输出最小的一个数
*/
public class jiaohuan1 {
public static void main(String[] args) {
int a =4;
int b = 3;
if(a<b){
// 第一种交换方式
int tmep =
- 渐变显示
bijian1013
JavaScript
<style type="text/css">
#wxf {
FILTER: progid:DXImageTransform.Microsoft.Gradient(GradientType=0, StartColorStr=#ffffff, EndColorStr=#97FF98);
height: 25px;
}
</style>
- 探索JUnit4扩展:断言语法assertThat
bijian1013
java单元测试assertThat
一.概述
JUnit 设计的目的就是有效地抓住编程人员写代码的意图,然后快速检查他们的代码是否与他们的意图相匹配。 JUnit 发展至今,版本不停的翻新,但是所有版本都一致致力于解决一个问题,那就是如何发现编程人员的代码意图,并且如何使得编程人员更加容易地表达他们的代码意图。JUnit 4.4 也是为了如何能够
- 【Gson三】Gson解析{"data":{"IM":["MSN","QQ","Gtalk"]}}
bit1129
gson
如何把如下简单的JSON字符串反序列化为Java的POJO对象?
{"data":{"IM":["MSN","QQ","Gtalk"]}}
下面的POJO类Model无法完成正确的解析:
import com.google.gson.Gson;
- 【Kafka九】Kafka High Level API vs. Low Level API
bit1129
kafka
1. Kafka提供了两种Consumer API
High Level Consumer API
Low Level Consumer API(Kafka诡异的称之为Simple Consumer API,实际上非常复杂)
在选用哪种Consumer API时,首先要弄清楚这两种API的工作原理,能做什么不能做什么,能做的话怎么做的以及用的时候,有哪些可能的问题
- 在nginx中集成lua脚本:添加自定义Http头,封IP等
ronin47
nginx lua
Lua是一个可以嵌入到Nginx配置文件中的动态脚本语言,从而可以在Nginx请求处理的任何阶段执行各种Lua代码。刚开始我们只是用Lua 把请求路由到后端服务器,但是它对我们架构的作用超出了我们的预期。下面就讲讲我们所做的工作。 强制搜索引擎只索引mixlr.com
Google把子域名当作完全独立的网站,我们不希望爬虫抓取子域名的页面,降低我们的Page rank。
location /{
- java-归并排序
bylijinnan
java
import java.util.Arrays;
public class MergeSort {
public static void main(String[] args) {
int[] a={20,1,3,8,5,9,4,25};
mergeSort(a,0,a.length-1);
System.out.println(Arrays.to
- Netty源码学习-CompositeChannelBuffer
bylijinnan
javanetty
CompositeChannelBuffer体现了Netty的“Transparent Zero Copy”
查看API(
http://docs.jboss.org/netty/3.2/api/org/jboss/netty/buffer/package-summary.html#package_description)
可以看到,所谓“Transparent Zero Copy”是通
- Android中给Activity添加返回键
hotsunshine
Activity
// this need android:minSdkVersion="11"
getActionBar().setDisplayHomeAsUpEnabled(true);
@Override
public boolean onOptionsItemSelected(MenuItem item) {
- 静态页面传参
ctrain
静态
$(document).ready(function () {
var request = {
QueryString :
function (val) {
var uri = window.location.search;
var re = new RegExp("" + val + "=([^&?]*)", &
- Windows中查找某个目录下的所有文件中包含某个字符串的命令
daizj
windows查找某个目录下的所有文件包含某个字符串
findstr可以完成这个工作。
[html]
view plain
copy
>findstr /s /i "string" *.*
上面的命令表示,当前目录以及当前目录的所有子目录下的所有文件中查找"string&qu
- 改善程序代码质量的一些技巧
dcj3sjt126com
编程PHP重构
有很多理由都能说明为什么我们应该写出清晰、可读性好的程序。最重要的一点,程序你只写一次,但以后会无数次的阅读。当你第二天回头来看你的代码 时,你就要开始阅读它了。当你把代码拿给其他人看时,他必须阅读你的代码。因此,在编写时多花一点时间,你会在阅读它时节省大量的时间。让我们看一些基本的编程技巧: 尽量保持方法简短 尽管很多人都遵
- SharedPreferences对数据的存储
dcj3sjt126com
SharedPreferences简介: &nbs
- linux复习笔记之bash shell (2) bash基础
eksliang
bashbash shell
转载请出自出处:
http://eksliang.iteye.com/blog/2104329
1.影响显示结果的语系变量(locale)
1.1locale这个命令就是查看当前系统支持多少种语系,命令使用如下:
[root@localhost shell]# locale
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
- Android零碎知识总结
gqdy365
android
1、CopyOnWriteArrayList add(E) 和remove(int index)都是对新的数组进行修改和新增。所以在多线程操作时不会出现java.util.ConcurrentModificationException错误。
所以最后得出结论:CopyOnWriteArrayList适合使用在读操作远远大于写操作的场景里,比如缓存。发生修改时候做copy,新老版本分离,保证读的高
- HoverTree.Model.ArticleSelect类的作用
hvt
Web.netC#hovertreeasp.net
ArticleSelect类在命名空间HoverTree.Model中可以认为是文章查询条件类,用于存放查询文章时的条件,例如HvtId就是文章的id。HvtIsShow就是文章的显示属性,当为-1是,该条件不产生作用,当为0时,查询不公开显示的文章,当为1时查询公开显示的文章。HvtIsHome则为是否在首页显示。HoverTree系统源码完全开放,开发环境为Visual Studio 2013
- PHP 判断是否使用代理 PHP Proxy Detector
天梯梦
proxy
1. php 类
I found this class looking for something else actually but I remembered I needed some while ago something similar and I never found one. I'm sure it will help a lot of developers who try to
- apache的math库中的回归——regression(翻译)
lvdccyb
Mathapache
这个Math库,虽然不向weka那样专业的ML库,但是用户友好,易用。
多元线性回归,协方差和相关性(皮尔逊和斯皮尔曼),分布测试(假设检验,t,卡方,G),统计。
数学库中还包含,Cholesky,LU,SVD,QR,特征根分解,真不错。
基本覆盖了:线代,统计,矩阵,
最优化理论
曲线拟合
常微分方程
遗传算法(GA),
还有3维的运算。。。
- 基础数据结构和算法十三:Undirected Graphs (2)
sunwinner
Algorithm
Design pattern for graph processing.
Since we consider a large number of graph-processing algorithms, our initial design goal is to decouple our implementations from the graph representation
- 云计算平台最重要的五项技术
sumapp
云计算云平台智城云
云计算平台最重要的五项技术
1、云服务器
云服务器提供简单高效,处理能力可弹性伸缩的计算服务,支持国内领先的云计算技术和大规模分布存储技术,使您的系统更稳定、数据更安全、传输更快速、部署更灵活。
特性
机型丰富
通过高性能服务器虚拟化为云服务器,提供丰富配置类型虚拟机,极大简化数据存储、数据库搭建、web服务器搭建等工作;
仅需要几分钟,根据CP
- 《京东技术解密》有奖试读获奖名单公布
ITeye管理员
活动
ITeye携手博文视点举办的12月技术图书有奖试读活动已圆满结束,非常感谢广大用户对本次活动的关注与参与。
12月试读活动回顾:
http://webmaster.iteye.com/blog/2164754
本次技术图书试读活动获奖名单及相应作品如下:
一等奖(两名)
Microhardest:http://microhardest.ite