dolphinscheduler涉及HDFS功能测试(三)spark task
目录
- 基础环境
-
- 环境信息
- 安装包下载地址
- 环境部署
-
- dolphinscheduler
-
- 解压配置
- 启动验证
-
- 资源中心验证
- 配置spark任务
- 验证spark任务
-
- 报错:py4j-0.10.9.3-src.zip does not exist
- 报错:2.2 GB of 2.1 GB virtual memory used
- 报错:Stack trace: ExitCodeException exitCode=1:
- hadoop
-
- 报错记录
-
- 配置免密,验证报错
- 验证
- spark(on yarn)
-
- 其它
- python3(非必须)
- pyspark(非必须)
-
- 配置变量(SPARK_PYTHON)
- 验证
-
- 本地验证
-
- 报错
-
- : ExitCodeException exitCode=1:
-
- 解决办法,增大虚拟机内存
- 其它
-
- 测试文件
基础环境
之前有测试过HDFS相关功能(dolphinscheduler涉及HDFS功能测试(一)环境准备、dolphinscheduler涉及HDFS功能测试(二)资源中心、SQOOP、MR(MapReduce)),唯独把spark给漏掉了,这次补上。在这次测试过程中,公司电脑还出了问题,硬盘竟然坏了,可能最近太卷吧,没让电脑休息,主要虚拟机也一直开着,所以今天就从头来一遍,环境部署到测试。
环境信息
- 由于电脑配置一般,就一台虚拟机(centos7),所以部署全部单机,具体版本如下
| 组件 | 版本 | 备注 |
|---|---|---|
| dolphinscheduler | 2.0.5 | hdfs相关测试采用的都是该版本 |
| hadoop | 2.7.3 | |
| spark | 3.2.1 | |
| pyspark | 3.2.1 | |
| jdk | 1.8+ | |
| python | 3.x | 今天测试spark执行python脚本 |
安装包下载地址
- CSND,直接全部下载,没有积分的话,只能去官方找了,资源都有的,就是下载比较慢

环境部署
dolphinscheduler
本地之前安装过dolphinscheduler1.3.6,这次升级为2.0.5,所以jdk、zookeeper、mysql不需要再安装了,没有的自行安装
- dolphinscheduler2.0.5部署包下载

先装其它组件吧
解压配置
- 数据库初始化
sql/sql/dolphinscheduler_mysql.sql - 配置数据库
conf/application-mysql.yaml
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.56.10:3306/dolphin_db?useUnicode=true&characterEncoding=UTF-8
username: dolphin
password: Test2021@
hikari:
connection-test-query: select 1
minimum-idle: 5
auto-commit: true
validation-timeout: 3000
pool-name: DolphinScheduler
maximum-pool-size: 50
connection-timeout: 30000
idle-timeout: 600000
leak-detection-threshold: 0
initialization-fail-timeout: 1
- 配置zookeeper地址
conf/registry.properties
registry.plugin.name=zookeeper
registry.servers=192.168.56.10:2181
registry.namespace=dolphinscheduler
registry.base.sleep.time.ms=60
registry.max.sleep.ms=300
registry.max.retries=5
registry.session.timeout.ms=30000
registry.connection.timeout.ms=7500
registry.block.until.connected.wait=600
registry.digest=
- 配置hadoop
conf/common.properties
resource.storage.type=HDFS
hdfs.root.user=dolphinscheduler
fs.defaultFS=hdfs://host1:8020
- 启动脚本指定mysql

启动验证

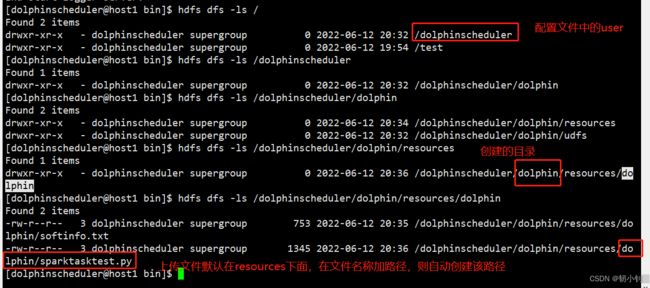
资源中心验证
- 每个用户绑定租户,admin用户直接初始化,未绑定

- 创建租户,修改admin用户


- 再次验证

配置spark任务

- 配置环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
export SPARK_HOME2=/home/dolphinscheduler/app/spark-3.2.1-bin-hadoop2.7

- 定义spark任务(环境名称一定要指定上面配置的spark环境)

验证spark任务
任务不执行,因为内存已经满了…继续扩大虚拟机内存(我决定今年而立的时候换一台高配的1W+起步的)

- 扩展后,启动验证

- 调度拼接后的命令
${SPARK_HOME2}/bin/spark-submit --master yarn --deploy-mode cluster --driver-cores 1 --driver-memory 512M --num-executors 2 --executor-cores 2 --executor-memory 2G --queue dolphin sparktasktest.py hdfs:///test/softinfo.txt hdfs:///test/softresult


- 上面的队列dolphin是不存在,修改spark任务再次验证

报错:py4j-0.10.9.3-src.zip does not exist
Diagnostics: File file:/home/dolphin/.sparkStaging/application_1655041548398_0003/py4j-0.10.9.3-src.zip does not exist
java.io.FileNotFoundException: File file:/home/dolphin/.sparkStaging/application_1655041548398_0003/py4j-0.10.9.3-src.zip does not exist

报错原因怀疑是超级用户组的原因,先将租户改为hadoop部署用户尝试验证

错误改变,说明上面错误和用户权限有关,后续再研究HDFS如何添加用户到超级用户组
报错:2.2 GB of 2.1 GB virtual memory used
Diagnostics: Container [pid=6691,containerID=container_1655041548398_0008_02_000001] is running beyond virtual memory limits. Current usage: 142.2 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container.

该错误网上百度一大堆,全是修改配置yarn-site.xml完全没用呀,后来通过增大任务内存参数(512M改为1G),解决该问题
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>

报错:Stack trace: ExitCodeException exitCode=1:
目前总算和之前本地验证的错同步了,今天就到这来了,这个错已经卡一下午了,


查看yarn-dolphinscheduler-resourcemanager-host1.log
ster appattempt_1655046296554_0001_000002
2022-06-12 23:07:09,572 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler: Null container completed...
2022-06-12 23:07:10,575 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler: Null container completed...
hadoop
直接参照之前写的dolphinscheduler涉及HDFS功能测试(一)环境准备,不再做重复工作!(写博客其实就是作为笔记使用)
报错记录
配置免密,验证报错
[dolphinscheduler@host1 .ssh]$ ssh localhost
/etc/ssh/ssh_config: line 69: Bad configuration option: permitrootlogin
/etc/ssh/ssh_config: terminating, 1 bad configuration options
- 解决:编辑
/etc/ssh/ssh_config,注释掉PermitRootLogin,重启ssh服务

验证
登录监控页面

namenode监控

无法查看页面可能原因:虚拟机防火墙未关闭(sudo systemctl stop firewalld)
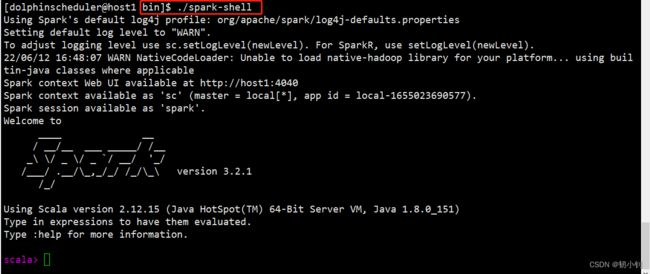
spark(on yarn)
依赖hadoop部署,直接解压即可
- 解压

- 启动shell验证
- 查看spark job监控页面

其它
- bin目录下面可以执行各种命令:
spark-submitspark-shellspark-sql等 - conf目录下面,配置环境变量,JAVA_HOME、HADOOP_CONF_DIR等
[dolphinscheduler@host1 conf]$ cp spark-env.sh.template spark-env.sh
[dolphinscheduler@host1 conf]$ vi spark-env.sh
[dolphinscheduler@host1 conf]$ cat spark-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_15
export HADOOP_CONF_DIR=/home/dolphinscheduler/app/hadoop-2.7.3
[dolphinscheduler@host1 conf]$
python3(非必须)
环境一般自带的都是python2,因为测试提供的脚本是3写的,所以需要升级
- 解压
[dolphinscheduler@host1 app]$ tar xf Python-3.9.11.tgz
[dolphinscheduler@host1 app]$ cd Python-3.9.11
[dolphinscheduler@host1 Python-3.9.11]$
- 指定目录编译安装
sudo ./configure --prefix=/usr/local/python3
sudo make
sudo make install
- 验证

- 创建软连接(系统命令)
sudo ln -s /usr/local/python3/bin/python3.9 /usr/bin/python3

pyspark(非必须)
python脚本如果没用到该模块,可以不安装
配置变量(SPARK_PYTHON)
[dolphinscheduler@host1 spark-3.2.1-bin-hadoop2.7]$ pwd
/home/dolphinscheduler/app/spark-3.2.1-bin-hadoop2.7
[dolphinscheduler@host1 spark-3.2.1-bin-hadoop2.7]$ ll conf/spark-env.sh
-rwxr-xr-x. 1 dolphinscheduler dolphin 4580 6月 12 17:44 conf/spark-env.sh
[dolphinscheduler@host1 spark-3.2.1-bin-hadoop2.7]$ cat conf/spark-env.sh|grep -v "#"|grep -v "^$"
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
export HADOOP_CONF_DIR=/home/dolphinscheduler/app/hadoop-2.7.3
export SPARK_PYTHON=/usr/local/bin/python3
[dolphinscheduler@host1 spark-3.2.1-bin-hadoop2.7]$
- 验证
bin/pyspark

注意:如果报模块不存在错,涉及到pyspark,则需要安装pyspark,安装步骤
验证
本地验证
bin/spark-submit --master yarn --deploy-mode cluster --queue default --driver-memory 1g --executor-memory 1g --executor-cores 1 --num-executors 1 /tmp/sparktasktest.py hdfs:///test/softinfo.txt hdfs:///test/softresult
参数说明:
- sparktasktest.py测试脚本
- softinfo.txt 测试脚本解析文件,需要上传到hdfs(sparktasktest.py会统计出该文本中符合条件的数据)
- softresult 输出目录,不指定,默认会创建(
hdfs dfs -ls可以看到)
报错

: ExitCodeException exitCode=1:

解决办法,增大虚拟机内存
- 关闭hadoop进程
[dolphinscheduler@host1 app]$ cd hadoop-2.7.3
[dolphinscheduler@host1 hadoop-2.7.3]$ cd sbin/
[dolphinscheduler@host1 sbin]$ ./stop-all.sh

- 关闭虚拟机,增大内存

- 启动hadoop,再次验证

依然报exitCode=1:错,先安装dolphin2.0.5吧…
其它
- 建议hadoop也用3.X版本
- Exit code: 1 多半还是和电脑配置有关(一天之后再次验证,无关!!! 还是粗心阿,都是泪,点击详情查看吧)
测试文件
- softinfo.txt
12341234123412342|asefr-3423|[{'name':'spark','score':'65'},{'name':'airlow','score':'70'},{'name':'flume','score':'55'},{'name':'python','score':'33'},{'name':'scala','score':'44'},{'name':'java','score':'70'},{'name':'hdfs','score':'66'},{'name':'hbase','score':'77'},{'name':'qq','score':'70'},{'name':'sun','score':'88'},{'name':'mysql','score':'96'},{'name':'php','score':'88'},{'name':'hive','score':'97'},{'name':'oozie','score':'45'},{'name':'meizu','score':'70'},{'name':'hw','score':'32'},{'name':'sql','score':'75'},{'name':'r','score':'64'},{'name':'mr','score':'83'},{'name':'kafka','score':'64'},{'name':'mo','score':'75'},{'name':'apple','score':'70'},{'name':'jquery','score':'86'},{'name':'js','score':'95'},{'name':'pig','score':'70'}]
- sparktasktest.py
逻辑注释掉可以成功运行,难道 Exit code: 1 是测试脚本的问题?概率不大,因为在公司电脑上成功运行过spark任务
#-*- coding:utf-8 –*-
from __future__ import print_function
from pyspark import SparkContext
from pyspark.sql import SQLContext
from pyspark.sql.types import Row, StructField, StructType, StringType, IntegerType
import importlib, sys
importlib.reload(sys)
import json
if __name__ == "__main__":
sc = SparkContext(appName="PythonSQL")
sqlContext = SQLContext(sc)
fileName = sys.argv[1]
lines = sc.textFile(fileName)
sc.setLogLevel("WARN")
def parse_line(line):
fields=line.split("|", -1)
keyword=fields[2]
return keyword
def parse_json(keyword):
return keyword.replace("[", "").replace("]", "").replace("},{", "}|{")
keywordRDD = lines.map(parse_line)
#print(keywordRDD.take(1))
#print("---------------")
jsonlistRDD = keywordRDD.map(parse_json)
#print(jsonlistRDD.take(1))
jsonRDD = jsonlistRDD.flatMap(lambda jsonlist:jsonlist.split("|"))
schema = StructType([StructField("name", StringType()), StructField("score", IntegerType())])
df = sqlContext.read.schema(schema).json(jsonRDD)
# df.printSchema()
# df.show()
df.registerTempTable("json")
df_result = sqlContext.sql("SELECT name,score FROM json WHERE score > 70")
df_result.coalesce(1).write.json(sys.argv[2])
sc.stop()