斯坦福大学CS224N-深度学习与自然语言处理:课程1-笔记
课程1-笔记
大纲:
- 讨论课程
- 语言和语意
- Word2Vec介绍
- Word2Vec目标函数梯度
- 优化函数
- Word2Vec的作用
关键:词义的结果可以用一个很大的实数向量很好地表示。
课程
学习目标:
- 将深度学习应用于自然语言处理的基础并有效的方法;
- 基础知识
- NLP中的关键方法:词向量、前向传播神经网络、递归神经网络、注意力机制、编码器-解码器模型、transformers等
- 深入理解人类语言的复杂以及如何通过计算机处理
- 理解并且有能力通过PyTorch解决NLP中一些关键问题
- 语义理解
- 语法分析
- 机器翻译
- 问答系统
语言和语意
Word2Vec介绍
通过离散符号表示单词
传统的NLP将单词视为离散的符号,因为在统计机器学习系统中,这些符号是稀疏的,表示这些符号的标准方法例如统计模型就将其整理成向量,OneHot就是其中一种。
OneHot编码:对应位置值为1,其它位置值为0。假如中文只有三个字:我是谁,那么“我”就表示为[1, 0, 0],“是”就表示为[0, 1, 0],“谁”就表示为[0, 0, 1]。
一个显然的问题就是需要建立一个跟文字库一样大的向量,比如《新华字典》中有13000个汉字,那么相应的OneHot编码向量的长度就是13000。
另外一个问题就是这种向量没有办法表示单词之间的相关性和相似性。OneHot编码向量在数学中是相互正交的,也就是说任何两个词向量之间都不相关,显然跟实际的语意不符。
通过上下文表示单词
分布语意:一个单词的含义是由经常出现在该单词附近的单词决定的。
通过上下文来表示单词的语意是一个重大成功,应用在很多深度学习NLP方法中。
当一个词出现在文本中时,一般是有一个上下文的语境的,而它的含义也由上下文的语境决定。
一般一个单词有两种表示,一种是这个单词作为核心的时候,由它的上下文得到的词向量,另一种是这个单词作为其它单词的上下文时,用于计算其它单词词向量的表示。
词向量(词嵌入)
Word2Vec为每个单词建立一个密集向量,这样语意相近的单词词向量也相近,可以通过向量点积来衡量两个单词的相似性。

Word2Vec
Word2Vec是一种学习词向量的框架。
思想:
- 有一个巨大的语料库
- 每个单词有一个固定长度表达的向量
- 对于每个位置t,都有一个中心单词c和窗口单词组o
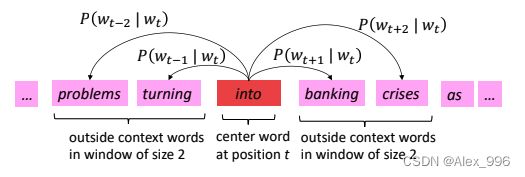
- 基于当前词向量可以计算上下文单词出现的概率,也可以基于上下文单词计算当前词向量出现的概率
- 不断调整词向量,最大化出现概率
Word2Vec
目标函数
对于每一个位置 t = 1, …, T,预测固定窗口大小m的上下文单词
给定中心词 w t w_{t} wt,数据可能性为: L ( θ ) = ∏ ⊂ t = 1 T ∏ ⊂ m ≤ j ≤ m j ≠ 0 P ( w t + j ∣ w t ; θ ) L(\theta)=\prod_{\sub{t=1}}^{T} \prod_{\sub{m \leq j \leq m \\ j \neq 0}} P\left(w_{t+j} \mid w_{t} ; \theta\right) L(θ)=∏⊂t=1T∏⊂m≤j≤mj=0P(wt+j∣wt;θ), θ \theta θ是要优化的模型参数。
目标函数是负的平均对谁似然: J ( θ ) = − 1 T log L ( θ ) = − 1 T ∑ t = 1 T ∑ ⊂ − m ≤ j ≤ m j ≠ 0 log P ( w t + j ∣ w t ; θ ) J(\theta)=-\frac{1}{T} \log L(\theta)=-\frac{1}{T} \sum_{t=1}^{T} \sum_{\sub{-m \leq j \leq m \\ j \neq 0}} \log P\left(w_{t+j} \mid w_{t} ; \theta\right) J(θ)=−T1logL(θ)=−T1∑t=1T∑⊂−m≤j≤mj=0logP(wt+j∣wt;θ)。
之所以做对数转换是因为对于计算机来说加法计算处理起来比乘法计算更容易,最小化目标函数即可最大化预测概率。
那怎么计算在给定中心词 w t w_{t} wt时预测上下文的概率 P ( w t + j ∣ w t ; θ ) P\left(w_{t+j} \mid w_{t} ; \theta\right) P(wt+j∣wt;θ)呢?
对于每个单词w都有两种表示向量:
- 当w为中心单词时: v w v_{w} vw
- 当w为上下文单词时: u w u_{w} uw
训练两组词向量是为了计算梯度的时候求导更方便,如果只用一个词向量v,那么softmax计算的概率公式里就会出现平方项,求导会很麻烦,如果用两个词向量,求导会很干净。
事实上窗口移动的时候,先前窗口的中心词会变成当前窗口的上下文词,先前窗口的某一个上下文词会变成当前窗口的中心词。所以这两组词向量用来训练的词对其实很相近,训练结果也会很相近。一般做法是取两组向量的平均值作为最后的词向量。
然后对于中心单词c和上下文单词o: P ( o ∣ c ) = exp ( u o T v c ) ∑ w ∈ V exp ( u w T v c ) P(o \mid c)=\frac{\exp \left(u_{o}^{T} v_{c}\right)}{\sum_{w \in V} \exp \left(u_{w}^{T} v_{c}\right)} P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc)
- 点乘 u T v = u . v = ∑ i = 1 n u i v i u^{T} v=u . v=\sum_{i=1}^{n} u_{i} v_{i} uTv=u.v=∑i=1nuivi衡量了单词o和单词c的相似性,点乘结果越大,两个单词越相似
- 幂运算可以保证分子为正数
- 分母对于给定概率分布可以标准化整个词汇表
这是Softmax函数的一个样例, softmax ( x i ) = exp ( x i ) ∑ j = 1 n exp ( x j ) = p i \operatorname{softmax}\left(x_{i}\right)=\frac{\exp \left(x_{i}\right)}{\sum_{j=1}^{n} \exp \left(x_{j}\right)}=p_{i} softmax(xi)=∑j=1nexp(xj)exp(xi)=pi,Softmax函数可以将任意给定值 x i x_{i} xi映射为概率分布 p i p_{i} pi。
- soft:对于比较小的 x i x_{i} xi也会给一个概率
- max:对于最大的 x i x_{i} xi给予最大的概率
怎么训练词向量
为了训练模型,我们逐步调整参数,使损失最小化。 θ \theta θ是一个表示我们模型的所有参数的长向量,也就是词向量,每个单词都有两种表示,并且拥有相同的维度。
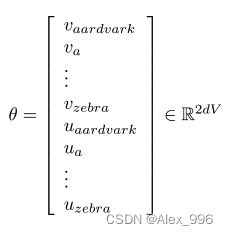
接下来就是通过梯度下降算法计算所有向量的梯度

以上只是对中心单词参数进行求导,还需要对上下文单词参数进行求导,然后才能进行最小化。
优化:梯度下降
我们有一个损失函数 J ( θ ) J(\theta) J(θ),想要最小化它,可以采用梯度下降算法,对于当前参数 θ i \theta_{i} θi,计算 J ( θ ) J(\theta) J(θ)的梯度,然后朝着负梯度的方向重复缓步更新。
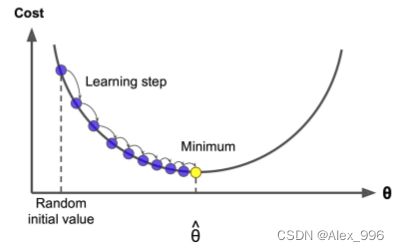
梯度更新公式: θ new = θ o l d − α ∇ θ J ( θ ) \theta^{\text {new }}=\theta^{o l d}-\alpha \nabla_{\theta} J(\theta) θnew =θold−α∇θJ(θ)
随机梯度下降
J ( θ ) J(\theta) J(θ)是语料库中所有窗口的函数(可能有数十亿!),所以 ∇ θ J ( θ ) \nabla_{\theta} J(\theta) ∇θJ(θ)计算成本很高,可以通过随机梯度下降解决,重复采样窗口并更新。
Word2Vec的效果
https://colab.research.google.com/drive/19qBGayk3pVBqsG0RMHz0CduVCdvAj8dw?usp=sharing