深度学习推荐系统实战总结
https://time.geekbang.org/column/article/294382
- 推荐系统要处理的问题可以被形式化地定义为:在特定场景C(Context)下,针对海量的“物品”信息构建一个函数 ,预测用户U(User)对特定候选物品I(Item)的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题。
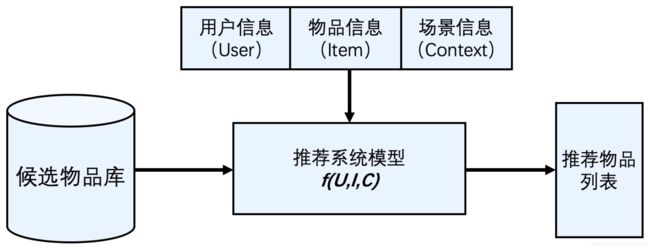
图1 推荐系统逻辑架构
如果说f(U,I,C) 这个推荐函数具有一个最优的表达形式,那传统的机器学习模型只能够拟合出f(U,I,C) 这个推荐函数的近似形式,而深度学习模型则可以最大程度地接近这个最优形式。
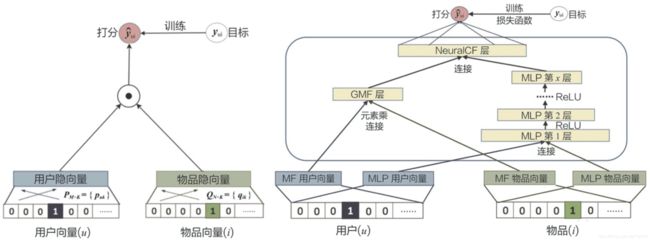
图2 传统的矩阵分解模型和深度学习矩阵分解模型的对比图
在实际的推荐系统中,工程师需要着重解决的问题有两类。
- 一类问题与数据和信息相关,即“用户信息”“物品信息”“场景信息”分别是什么?如何存储、更新和处理数据(特征)
- 另一类问题与推荐系统算法和模型相关,即推荐系统模型如何训练、预测,以及如何达成更好的推荐效果(模型)
一个工业级推荐系统的技术架构其实也是按照这两部分展开的
- “数据和信息”部分逐渐发展为推荐系统中融合了数据离线批处理、实时流处理的数据流框架;
- “算法和模型”部分则进一步细化为推荐系统中,集训练(Training)、评估(Evaluation)、部署(Deployment)、线上推断(Online Inference)为一体的模型框架。
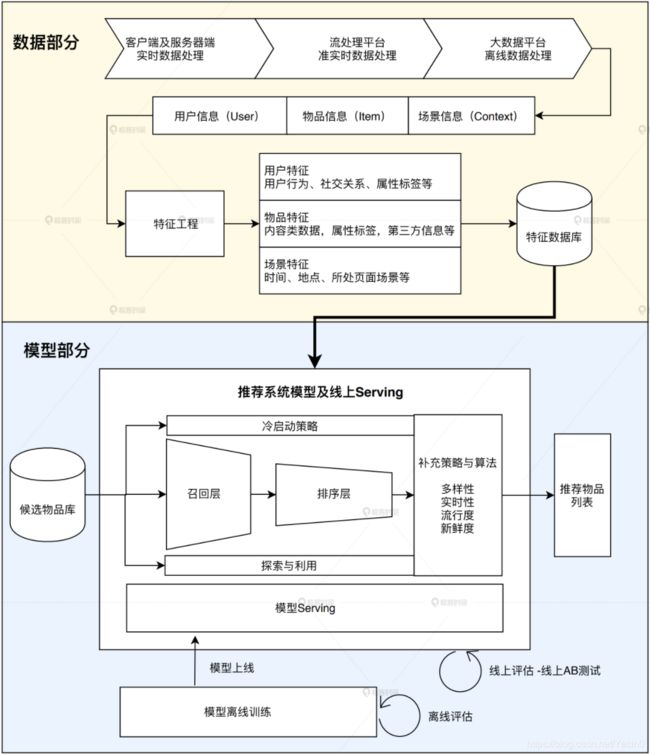
第一部分:推荐系统的数据部分
推荐系统的“数据部分”主要负责的是“用户”“物品”“场景”信息的收集与处理。根据处理数据量和处理实时性的不同,我们会用到三种不同的数据处理方式,按照实时性的强弱排序的话,它们依次是客户端与服务器端实时数据处理、流处理平台准实时数据处理、大数据平台离线数据处理。
在实时性由强到弱递减的同时,三种平台的海量数据处理能力则由弱到强。因此,一个成熟推荐系统的数据流系统会将三者取长补短,配合使用。我们也会在今后的课程中讲到具体的例子,比如使用 Spark 进行离线数据处理,使用 Flink 进行准实时数据处理等等。
大数据计算平台通过对推荐系统日志,物品和用户的元数据等信息的处理,获得了推荐模型的训练数据、特征数据、统计数据等。那这些数据都有什么用呢?具体说来,大数据平台加工后的数据出口主要有 3 个:
- 生成推荐系统模型所需的样本数据,用于算法模型的训练和评估。
- 生成推荐系统模型服务(Model Serving)所需的“用户特征”,“物品特征”和一部分“场景特征”,用于推荐系统的线上推断。
- 生成系统监控、商业智能(Business Intelligence,BI)系统所需的统计型数据。
可以说,推荐系统的数据部分是整个推荐系统的“水源”,我们只有保证“水源”的持续、纯净,才能不断地“滋养”推荐系统,使其高效地运转并准确地输出。在深度学习时代,深度学习模型对于“水源”的要求更高了,首先是水量要大,只有这样才能保证我们训练出的深度学习模型能够尽快收敛;其次是“水流”要快,让数据能够尽快地流到模型更新训练的模块,这样才能够让模型实时的抓住用户兴趣变化的趋势,这就推动了大数据引擎 Spark,以及流计算平台 Flink 的发展和应用。
第二部分:推荐系统的模型部分
推荐系统的“模型部分”是推荐系统的主体。模型的结构一般由“召回层”、“排序层”以及“补充策略与算法层”组成。
其中,“召回层”一般由高效的召回规则、算法或简单的模型组成,这让推荐系统能快速从海量的候选集中召回用户可能感兴趣的物品。“排序层”则是利用排序模型对初筛的候选集进行精排序。而“补充策略与算法层”,也被称为“再排序层”,是在返回给用户推荐列表之前,为兼顾结果的“多样性”“流行度”“新鲜度”等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表。
从推荐系统模型接收到所有候选物品集,到最后产生推荐列表,这一过程一般叫做“模型服务过程”。为了生成模型服务过程所需的模型参数,我们需要通过模型训练(Model Training)确定模型结构、结构中不同参数权重的具体数值,以及模型相关算法和策略中的参数取值。
模型的训练方法根据环境的不同,可以分为“离线训练”和“在线更新”两部分。其中,离线训练的特点是可以利用全量样本和特征,使模型逼近全局最优点,而在线更新则可以准实时地“消化”新的数据样本,更快地反应新的数据变化趋势,满足模型实时性的需求。
除此之外,为了评估推荐系统模型的效果,以及模型的迭代优化,推荐系统的模型部分还包括“离线评估”和“线上 A/B 测试”等多种评估模块,用来得出线下和线上评估指标,指导下一步的模型迭代优化。
我们刚才说过,深度学习对于推荐系统的革命集中在模型部分,那具体都有什么呢?我把最典型的深度学习应用总结成了 3 点:
- 深度学习中 Embedding 技术在召回层的应用。作为深度学习中非常核心的 Embedding 技术,将它应用在推荐系统的召回层中,做相关物品的快速召回,已经是业界非常主流的解决方案了。
- 不同结构的深度学习模型在排序层的应用。排序层(也称精排层)是影响推荐效果的重中之重,也是深度学习模型大展拳脚的领域。深度学习模型的灵活性高,表达能力强的特点,这让它非常适合于大数据量下的精确排序。深度学习排序模型毫无疑问是业界和学界都在不断加大投入,快速迭代的部分。
- 增强学习在模型更新、工程模型一体化方向上的应用。增强学习可以说是与深度学习密切相关的另一机器学习领域,它在推荐系统中的应用,让推荐系统可以在实时性层面更上一层楼。
图6 Netflix架构图示意图
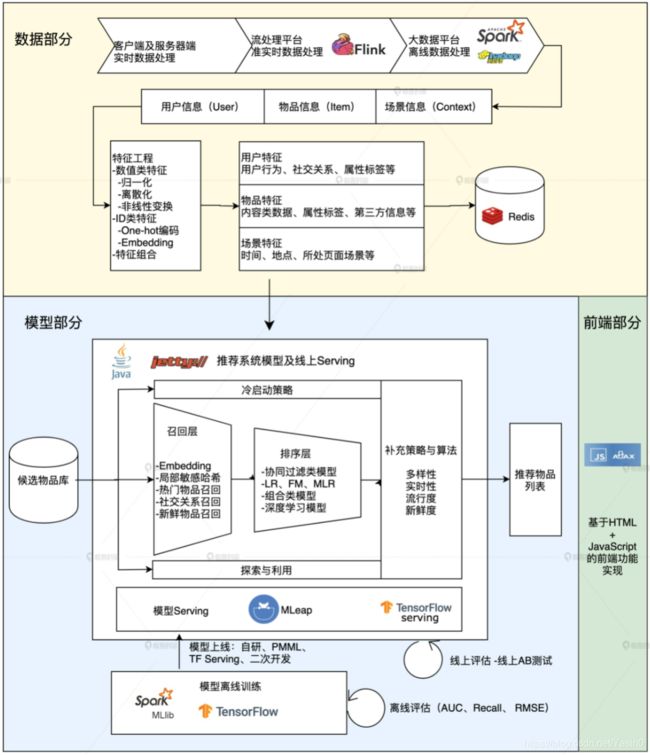
图8 Sparrow Recsys的推荐系统架构
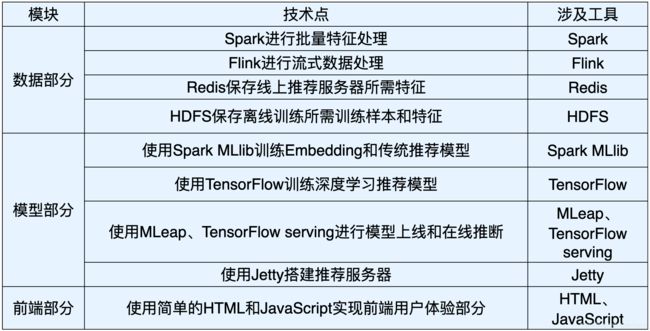
技术点
生物学中的神经元:大致由树突、细胞体(图中细胞核和周围的部分)、轴突、轴突末梢等几部分组成。树突是神经元的输入信号通道,它的功能是将其他神经元的动作电位(可以当作一种信号)传递至细胞体。在接收到其他神经元的信号后,细胞体会根据这些信号改变自己的状态,变成“激活态”还是“未激活态”。具体的状态取决于输入信号,也取决于神经细胞本身的性质(抑制或加强)。当信号量超过某个阈值时,细胞体就会被激活,产生电脉冲。电脉冲会沿着轴突传播,并通过轴突末梢传递到其它神经元。
假设其他神经元通过树突传递过来的信号就是推荐系统用到的特征,有的信号可能是“用户性别是男是女”,有的信号可能是“用户之前有没有点击过这个物品”等等。细胞体在接收到这些信号的时候,会做一个简单的判断,然后通过轴突输出一个信号,这个输出信号大小代表了用户对这个物品的感兴趣程度。
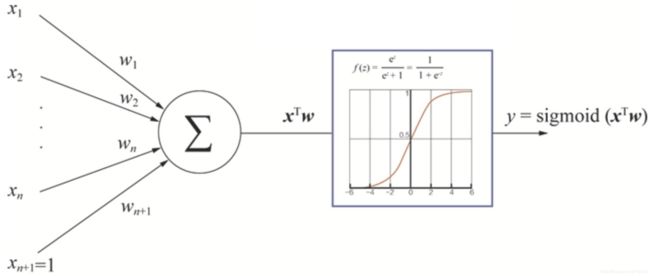
图3 基于Sigmoid激活函数的神经元
神经网络的细胞体主要是做了两件事情:把输入信号 x1、x2各自乘以一个权重 w1、w2;把各自的乘积加起来之后输入到一个叫“激活函数”的结构里。
sigmoid 函数有处处可导的优良数学形式,方便之后的梯度下降学习过程,所以它成为了经常使用的激活函数。
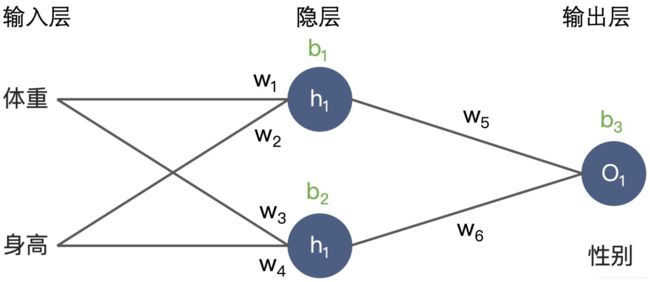
前向传播(Forward Propagation)即模型推断过程,在当前网络参数的基础上得到模型对输入的预估值。比如,要通过一位同学的体重、身高预测 TA 的性别,前向传播的过程就是给定体重值 71,身高值 178,经过神经元 h1、h2和 o1的计算,得到一个性别概率值,比如说 0.87,这就是 TA 可能为男性的概率。
反向传播(Back Propagation)发现了预测值和真实值之间的误差(Loss),使用这个误差来指导权重的更新,让整个神经网络在下次预测时变得更准确。最常见的权重更新方式就是梯度下降法,它是通过求取偏导的形式来更新权重的。梯度的方向是函数增长速度最快的方向,那么梯度的反方向就是函数下降最快的方向,所以让损失函数减小最快的方向就是我们希望梯度 w 更新的方向。
通过链式法则可以解决梯度逐层反向传播的问题。最终的损失函数到权重 w1的梯度是由损失函数o1到神经元 h1输出的偏导,以及神经元 h1输出到权重 w1的偏导相乘而来的。(梯度逐层传导,“指导”权重 w1的更新)
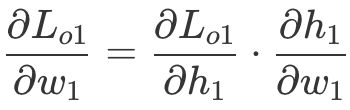
神经元是神经网络中的基础结构,它参照生物学中的神经元构造,抽象出带有输入输出和激活函数的数学结构。而神经网络是通过将多个神经元以串行、并行、全连接等方式连接起来形成的网络,神经网络的训练方法是基于链式法则的梯度反向传播。
特征工程:
如果说整个推荐系统是一个饭馆,那么特征工程就是负责配料和食材的厨师,推荐模型这个大厨做的菜好不好吃,大厨的厨艺肯定很重要,但配料和食材作为美食的基础也同样重要。而且只有充分了解配料和食材的特点,我们才能把它们的作用发挥到极致。
特征其实是对某个行为过程相关信息的抽象表达。因为一个行为过程必须转换成某种数学形式才能被机器学习模型所学习,为了完成这种转换,必须将这些行为过程中的信息以特征的形式抽取出来。
从具体行为信息转化成抽象特征的过程,往往会造成信息的损失。
- 具体的推荐行为和场景中包含大量原始的场景、图片和状态信息,保存所有信息的存储空间过大,我们根本无法实现。
- 具体的推荐场景中包含大量冗余的、无用的信息,把它们都考虑进来甚至会损害模型的泛化能力。比如,电影推荐中包含了大量的影片内容信息,我们没有必要把影片的所有情节都当作特征放进推荐模型中去学习。
构建推荐系统特征工程的原则:尽可能地抽取出的一组特征,能够保留推荐环境及用户行为过程中的所有“有用“信息,并且尽量摒弃冗余信息。(在已有的、可获得的数据基础上,“尽量”保留有用信息是现实中构建特征工程的原则。)
图2 电影推荐的要素和特征化方式
推荐系统中的常用特征
1. 用户行为数据
用户行为数据(User Behavixiaor Data)是推荐系统最常用,也是最关键的数据。用户的潜在兴趣、用户对物品的真实评价都包含在用户的行为历史中。用户行为在推荐系统中一般分为显性反馈行为(Explicit Feedback)和隐性反馈行为(Implicit Feedback)两种,在不同的业务场景中,它们会以不同的形式体现。
在当前的推荐系统特征工程中,隐性反馈行为越来越重要,主要原因是显性反馈行为的收集难度过大,数据量小。在深度学习模型对数据量的要求越来越大的背景下,仅用显性反馈的数据不足以支持推荐系统训练过程的最终收敛。所以,能够反映用户行为特点的隐性反馈是目前特征挖掘的重点。

图3 不同业务场景下用户行为数据的例子
2. 用户关系数据
互联网本质上就是人与人、人与信息之间的连接。如果说用户行为数据是人与物之间的“连接”日志,那么用户关系数据(User Relationship Data)就是人与人之间连接的记录。“物以类聚,人以群分”,用户关系数据毫无疑问是非常值得推荐系统利用的有价值信息。
用户关系数据也可以分为“显性”和“隐性”两种,或者称为“强关系”和“弱关系”。用户与用户之间可以通过“关注”“好友关系”等连接建立“强关系”,也可以通过“互相点赞”、“同处一个社区”,甚至“同看一部电影”建立“弱关系”。
在推荐系统中,利用用户关系数据的方式也是多种多样的,比如可以将用户关系作为召回层的一种物品召回方式;也可以通过用户关系建立关系图,使用 Graph Embedding 的方法生成用户和物品的 Embedding;还可以直接利用关系数据,通过“好友”的特征为用户添加新的属性特征;甚至可以利用用户关系数据直接建立社会化推荐系统。
3. 属性、标签类数据
推荐系统中另外一大类特征来源是属性类数据(Attribute Data)和标签类数据(Label Data),它们本质上都是直接描述用户或者物品的特征。属性和标签的主体可以是用户,也可以是物品,大体上包含图 5 中的几类。
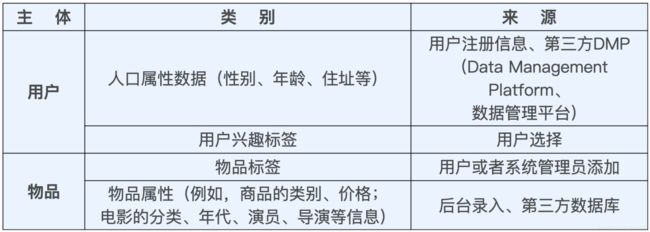
图5 属性、标签类数据的分类和来源
用户、物品的属性、标签类数据是最重要的描述型特征。成熟的公司往往会建立一套用户和物品的标签体系,由专门的团队负责维护,典型的例子就是电商公司的商品分类体系;也可以由用户为需要为收藏对象打上对应的标签。
在推荐系统中使用属性、标签类数据,一般是通过 Multi-hot 编码的方式将其转换成特征向量,一些重要的属性标签类特征也可以先转换成 Embedding,比如业界最新的做法是将标签属性类数据与其描述主体一起构建成知识图谱(Knowledge Graph),在其上施以 Graph Embedding 或者 GNN(Graph Neural Network,图神经网络)生成各节点的 Embedding,再输入推荐模型。
4. 内容类数据
内容类数据(Content Data)可以看作属性标签型特征的延伸,同样是描述物品或用户的数据,但相比标签类特征,内容类数据往往是大段的描述型文字、图片,甚至视频。
一般来说,内容类数据无法直接转换成推荐系统可以“消化”的特征,需要通过自然语言处理、计算机视觉等技术手段提取关键内容特征,再输入推荐系统。例如,在图片类、视频类或是带有图片的信息流推荐场景中,我们往往会利用计算机视觉模型进行目标检测,抽取图片特征;而文字信息则更多是通过自然语言处理的方法提取关键词、主题、分类等信息,一旦这些特征被提取出来,就跟处理属性、标签类特征的方法一样,通过 Multi-hot 编码,Embedding 等方式输入推荐系统进行训练。
5. 场景信息(上下文信息)
场景信息,或称为上下文信息(Context Information),它是描述推荐行为产生的场景的信息。最常用的上下文信息是“时间”和通过 GPS、IP 地址获得的“地点”信息。根据推荐场景的不同,上下文信息的范围极广,除了我们上面提到的时间和地点,还包括“当前所处推荐页面”“季节”“月份”“是否节假日”“天气”“空气质量”“社会大事件”等等。
场景特征描述的是用户所处的客观的推荐环境,广义上来讲,任何影响用户决定的因素都可以当作是场景特征的一部分。但在实际的推荐系统应用中,由于一些特殊场景特征的获取极其困难,我们更多还是利用时间、地点、推荐页面这些易获取的场景特征。
Spark特征处理
Spark 是一个分布式计算平台。所谓分布式,指的是计算节点之间不共享内存,需要通过网络通信的方式交换数据。Spark 最典型的应用方式就是建立在大量廉价的计算节点上,这些节点可以是廉价主机,也可以是虚拟的 Docker Container(Docker 容器)。
Spark 程序由 Manager Node(管理节点)进行调度组织,由 Worker Node(工作节点)进行具体的计算任务执行,最终将结果返回给 Drive Program(驱动程序)。在物理的 Worker Node 上,数据还会分为不同的 partition(数据分片),可以说 partition 是 Spark 的基础数据单元。
Spark 计算集群能够比传统的单机高性能服务器具备更强大的计算能力,就是由这些成百上千,甚至达到万以上规模的工作节点并行工作带来的。
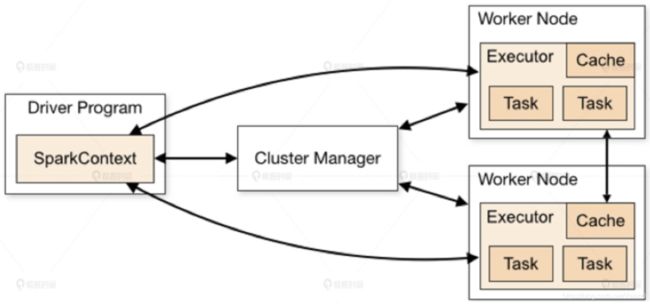
图1 Spark架构图
Embedding基础
Embedding 是用一个数值向量“表示”一个对象(Object)的方法,这个对象可以是一个词、一个物品、一部电影等等。
一个物品能被向量表示,是因为这个向量跟其他物品向量之间的距离反映了这些物品的相似性。即,两个向量间的距离向量甚至能够反映它们之间的关系。
它利用 Word2vec 这个模型把单词映射到了高维空间中,每个单词在这个高维空间中的位置都非常有意思,从 king 到 queen 的向量和从 man 到 woman 的向量,无论从方向还是尺度来说它们都异常接近。这说明词 Embedding 向量间的运算居然能够揭示词之间的性别关系!
比如 woman 这个词的词向量可以用下面的运算得出:Embedding(woman)=Embedding(man)+[Embedding(queen)-Embedding(king)]
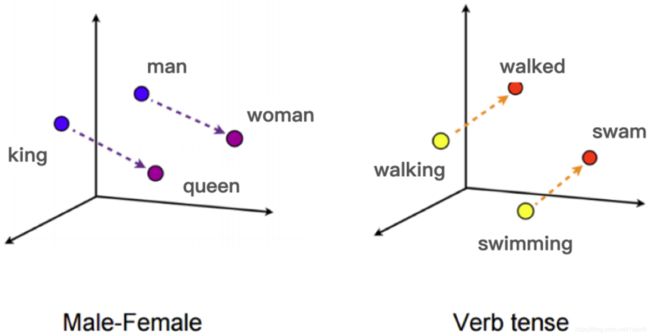
从 walking 到 walked 和从 swimming 到 swam 的向量基本一致,这说明词向量揭示了词之间的时态关系!
Netflix 利用矩阵分解方法生成的电影和用户的 Embedding 向量,可以看出不同的电影和用户分布在一个二维的空间内,由于 Embedding 向量保存了它们之间的相似性关系,因此有了这个 Embedding 空间之后,我们直接找出某个用户向量周围的电影向量,然后把这些电影推荐给这个用户。
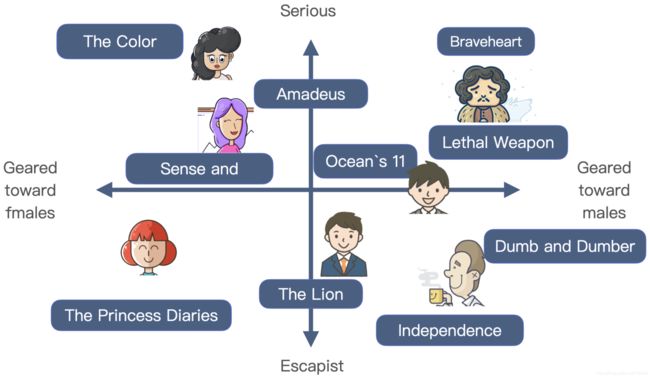
图2 电影-用户向量例子
Embedding 技术对深度学习推荐系统的重要性
首先,Embedding 是处理稀疏特征的利器。 推荐场景中的类别、ID 型特征非常多,大量使用 One-hot 编码会导致样本特征向量极度稀疏,而深度学习的结构特点又不利于稀疏特征向量的处理,因此几乎所有深度学习推荐模型都会由 Embedding 层负责将稀疏高维特征向量转换成稠密低维特征向量。
其次,Embedding 可以融合大量有价值信息。 相比由原始信息直接处理得来的特征向量,Embedding 的表达能力更强,特别是 Graph Embedding 技术被提出后,Embedding 几乎可以引入任何信息进行编码,使其本身就包含大量有价值的信息,所以通过预训练得到的 Embedding 向量本身就是极其重要的特征向量。
Word2vec
Word2vec 是“word to vector”的简称,它是一个生成对“词”的向量表达的模型。
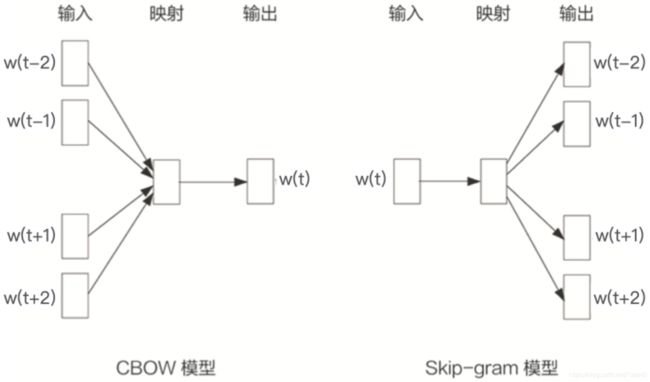
想要训练 Word2vec 模型,需要准备由一组句子组成的语料库。假设其中一个长度为 T 的句子包含的词有 w1,w2……wt,并且假定每个词都跟其相邻词的关系最密切。根据模型假设的不同,Word2vec 模型分为两种形式,CBOW 模型和 Skip-gram 模型。按照一般的经验,Skip-gram 模型的效果会更好一些。
- CBOW 模型假设句子中每个词的选取都由相邻的词决定,所以CBOW 模型的输入是 wt周边的词,预测的输出是 wt。
- Skip-gram 模型假设句子中的每个词都决定了相邻词的选取,所以Skip-gram 模型的输入是 wt,预测的输出是 wt周边的词。
Word2vec 训练样本的生成:从语料库(电商网站中所有物品的描述文字)中抽取一个句子,选取一个长度为 2c+1(目标词前后各选 c 个词)的滑动窗口,将滑动窗口由左至右滑动,每移动一次,窗口中的词组就形成了一个训练样本。Skip-gram 模型是中心词决定了它的相邻词,所以模型的输入是样本的中心词,输出是所有的相邻词。
如,以“Embedding 技术对深度学习推荐系统的重要性”作为句子样本。首先,对它进行分词,去除停用词,生成词序列,再选取大小为 3 的滑动窗口从头到尾依次滑动生成训练样本,然后我们把中心词当输入,边缘词做输出,就得到了训练 Word2vec 模型可用的训练样本。
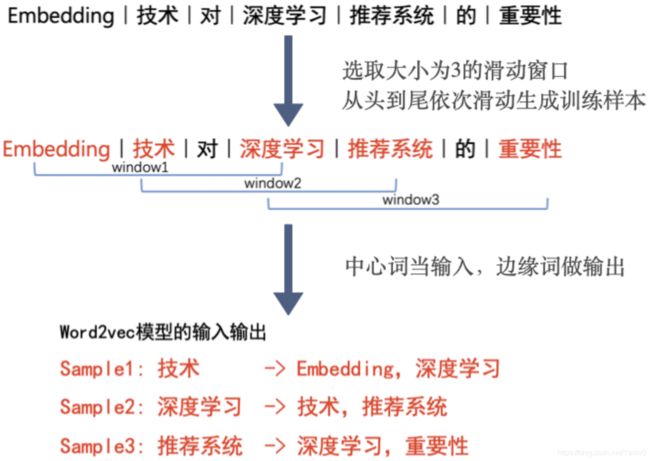
图4 生成Word2vec训练样本的例子
Word2vec的结构本质上是一个三层的神经网络。
- 它的输入层和输出层的维度都是 V,这个 V 其实就是语料库词典的大小。假设语料库一共使用了 10000 个词,那么 V 就等于 10000。根据语料库生成训练样本,这里的输入向量自然就是由输入词转换而来的 One-hot 编码向量,输出向量则是由多个输出词转换而来的 Multi-hot 编码向量,显然,基于 Skip-gram 框架的 Word2vec 模型解决的是一个多分类问题。
- 隐层的维度是 N,N 的选择需要对模型的效果和模型的复杂度进行权衡,来决定 N 的取值,并且最终每个词的 Embedding 向量维度也由 N 来决定。
- 最后是激活函数的问题,需要注意的是,隐层神经元是没有激活函数的,或者说采用了输入即输出的恒等函数作为激活函数,而输出层神经元采用了 softmax 作为激活函数。
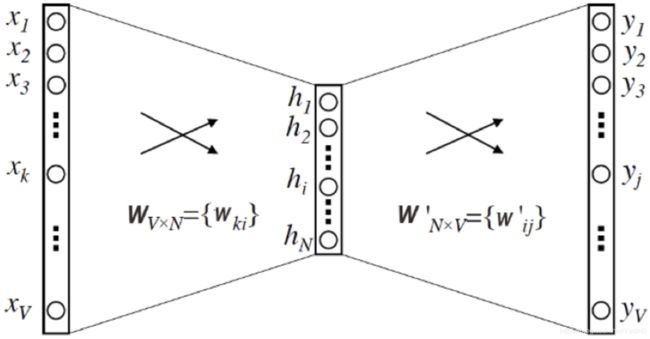
图5 Word2vec模型的结构
为什么要这样设置 Word2vec 的神经网络,为什么要这样选择激活函数呢?是因为这个神经网络其实是为了表达从输入向量到输出向量的这样的一个条件概率关系,我们看下面的式子:
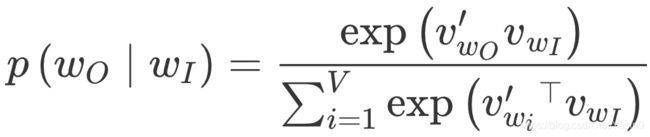
这个由输入词 WI 预测输出词 WO 的条件概率,其实就是 Word2vec 神经网络要表达的东西。通过极大似然的方法去最大化这个条件概率,就能够让相似词的内积距离更接近,这就是我们希望 Word2vec 神经网络学到的。
为了节约训练时间,Word2vec 经常会采用负采样(Negative Sampling)或者分层 softmax(Hierarchical Softmax)的训练方法。
怎样把词向量从 Word2vec 模型中提取出来?
在训练完 Word2vec 的神经网络之后,输入层到隐层的权重矩阵 WVxN 就是我们要得到的Embedding向量。
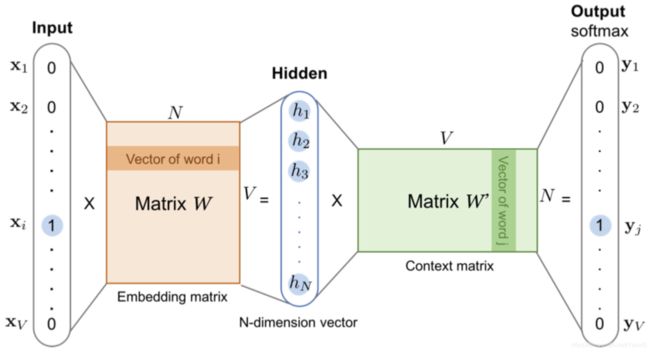
输入向量矩阵 WVxN 的每一个行向量对应的就是我们要找的“词向量”。比如要找词典里第 i 个词对应的 Embedding,因为输入向量是采用 One-hot 编码的,所以输入向量的第 i 维就应该是 1,其余为0,那么输入向量矩阵 WVxN 中第 i 行的行向量自然就是该词的 Embedding 啦。输出向量矩阵 W′ 也遵循这个道理,但一般来说,我们还是习惯于使用输入向量矩阵作为词向量矩阵。
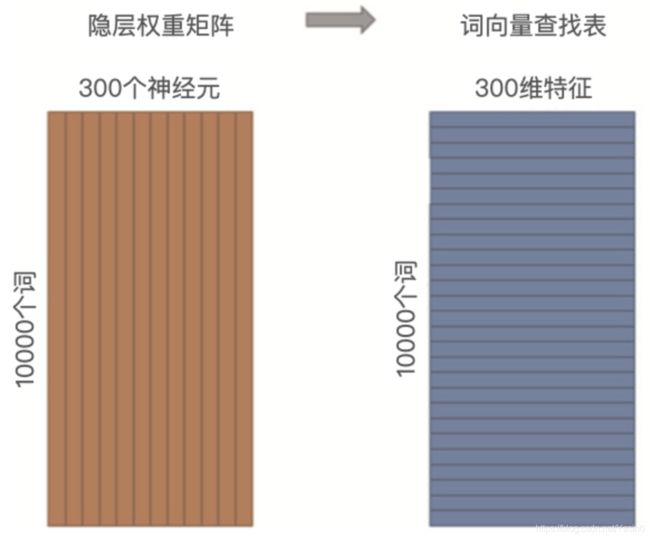
在实际的使用过程中,我们往往会把输入向量矩阵转换成词向量查找表(Lookup table)。例如,输入向量是 10000 个词组成的 One-hot 向量,隐层维度是 300 维,那么输入层到隐层的权重矩阵为 10000x300 维。在转换为词向量 Lookup table 后,每行的权重即成了对应词的 Embedding 向量。如果我们把这个查找表存储到线上的数据库中,就可以轻松地在推荐物品的过程中使用 Embedding 去计算相似性等重要的特征了。
Item2Vec:Word2vec 方法的推广
自然语言处理中 Word2vec 对词“序列”中的词进行 Embedding;推荐系统中对于用户购买“序列”中的一个商品,用户观看“序列”中的一个电影,也存在相应的 Embedding 方法。

Item2Vec 方法对 Word2vec 进行推广,使 Embedding 方法适用于几乎所有的序列数据。只要能够用序列数据的形式把要表达的对象表示出来,再把序列数据“喂”给 Word2vec 模型,就能够得到任意物品的 Embedding。对于推荐系统来说,Item2vec 可以利用物品的 Embedding 直接求得它们的相似性,或者作为重要的特征输入推荐模型进行训练,这些都有助于提升推荐系统的效果。
只要是能够被序列数据表示的物品,都可以通过 Item2vec 方法训练出 Embedding。但是,互联网越来越多的数据以图的形式展现出来,图数据中包含了大量非常有价值的结构信息。Graph Embedding能够基于图结构数据生成 Embedding。
互联网中典型的图结构数据
- 社交网络中,可以发现意见领袖,可以发现社区,再根据这些“社交”特性进行社交化的推荐,如果可以对社交网络中的节点进行 Embedding 编码,社交化推荐的过程将会非常方便。
- 知识图谱中包含了不同类型的知识主体(如人物、地点等),附着在知识主体上的属性(如人物描述,物品特点),以及主体和主体之间、主体和属性之间的关系。如果能够对知识图谱中的主体进行 Embedding 化,就可以发现主体之间的潜在关系,这对于基于内容和知识的推荐系统是非常有帮助的。
- 行为关系类图数据几乎存在于所有互联网应用中,它事实上是由用户和物品组成的“二部图”(也称二分图)。用户和物品之间的相互行为生成了行为关系图。借助这样的关系图,利用 Embedding 技术发掘出物品和物品之间、用户和用户之间,以及用户和物品之间的关系,从而应用于推荐系统的进一步推荐。
基于随机游走的 Graph Embedding 方法:Deep Walk
Deep Walk 的主要思想是在由物品组成的图结构上进行随机游走,产生大量物品序列,然后将这些物品序列作为训练样本输入 Word2vec 进行训练,最终得到物品的 Embedding。因此,DeepWalk 可以被看作连接序列 Embedding 和 Graph Embedding 的一种过渡方法。
上图展示了 DeepWalk 方法的执行过程。
- 首先,基于原始的用户行为序列(用户的购买物品序列、观看视频序列等等)来构建物品关系图。从图中可以看出,因为用户 Ui先后购买了物品 A 和物品 B,所以产生了一条由 A 到 B 的有向边。如果后续产生了多条相同的有向边,则有向边的权重被加强。在将所有用户行为序列都转换成物品相关图中的边之后,全局的物品相关图就建立起来了。
- 然后,采用随机游走的方式随机选择起始点,重新产生物品序列。其中,随机游走采样的次数、长度等都属于超参数,需要根据具体应用进行调整。
- 最后,将这些随机游走生成的物品序列输入 Word2vec 模型,生成最终的物品 Embedding 向量。
DeepWalk 的算法流程中,唯一需要形式化定义的就是随机游走的跳转概率,也就是到达节点 vi后,下一步遍历 vi 的邻接点 vj 的概率。如果物品关系图是有向有权图,那么从节点 vi 跳转到节点 vj 的概率定义如下:
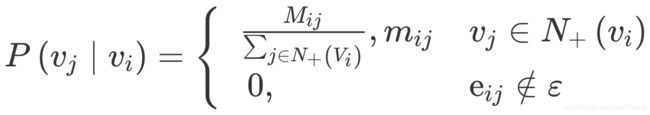
其中,N+(vi) 是节点 vi所有的出边集合,Mij是节点 vi到节点 vj边的权重,即 DeepWalk 的跳转概率就是跳转边的权重占所有相关出边权重之和的比例。如果物品相关图是无向无权重图,那么跳转概率将是上面这个公式的一个特例,即权重 Mij将为常数 1,且 N+(vi) 应是节点 vi所有“边”的集合,而不是所有“出边”的集合。
在同质性和结构性间权衡的方法:Node2vec
Node2vec 通过调整随机游走跳转概率的方法,让 Graph Embedding 的结果在网络的同质性(Homophily)和结构性(Structural Equivalence)中进行权衡,可以进一步把不同的 Embedding 输入推荐模型,让推荐系统学习到不同的网络结构特点。
- 网络的“同质性”指的是距离相近节点的 Embedding 应该尽量近似。如图所示,节点 u 与其相连的节点 s1、s2、s3、s4的 Embedding 表达应该是接近的。在电商网站中,同质性的物品很可能是同品类、同属性,或者经常被一同购买的物品。
- 网络的“结构性”指的是结构上相似节点的 Embedding 应该尽量接近。比如图中节点 u 和节点 s6都是各自局域网络的中心节点,它们在结构上相似,所以它们的 Embedding 表达也应该近似。在电商网站中,结构性相似的物品一般是各品类的爆款、最佳凑单商品等拥有类似趋势或者结构性属性的物品。
图3 网络的BFS和 DFS示意图
- 为了使 Graph Embedding 的结果能够表达网络的“结构性”,在随机游走的过程中,需要让游走的过程更倾向于 BFS(Breadth First Search,宽度优先搜索),因为 BFS 会更多地在当前节点的邻域中进行游走遍历,相当于对当前节点周边的网络结构进行一次“微观扫描”。当前节点是“局部中心节点”,还是“边缘节点”,亦或是“连接性节点”,其生成的序列包含的节点数量和顺序必然是不同的,从而让最终的 Embedding 抓取到更多结构性信息。
- 为了表达“同质性”,随机游走要更倾向于 DFS(Depth First Search,深度优先搜索),因为 DFS 更有可能通过多次跳转,游走到远方的节点上。但无论怎样,DFS 的游走更大概率会在一个大的集团内部进行,这就使得一个集团或者社区内部节点的 Embedding 更为相似,从而更多地表达网络的“同质性”。
Node2vec 算法是怎样控制 BFS 和 DFS 的倾向性的呢?
主要是通过节点间的跳转概率来控制跳转的倾向性。下图所示为 Node2vec 算法从节点 t 跳转到节点 v 后,再从节点 v 跳转到周围各点的跳转概率。这里要注意这几个节点的特点。
比如,节点 t 是随机游走上一步访问的节点,节点 v 是当前访问的节点,节点 x1、x2、x3是与 v 相连的非 t 节点,但节点 x1还与节点 t 相连,这些不同的特点决定了随机游走时下一次跳转的概率。
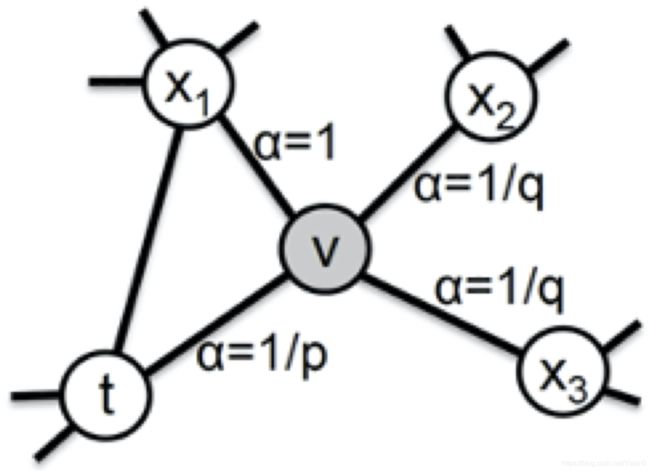
图4 Node2vec的跳转概率
这些概率还可以用具体的公式来表示,从当前节点 v 跳转到下一个节点 x 的概率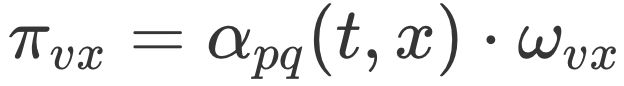 ,其中 wvx 是边 vx 的原始权重,
,其中 wvx 是边 vx 的原始权重,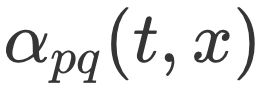 是 Node2vec 定义的一个跳转权重。到底是倾向于 DFS 还是 BFS,主要就与这个跳转权重的定义有关了。
是 Node2vec 定义的一个跳转权重。到底是倾向于 DFS 还是 BFS,主要就与这个跳转权重的定义有关了。
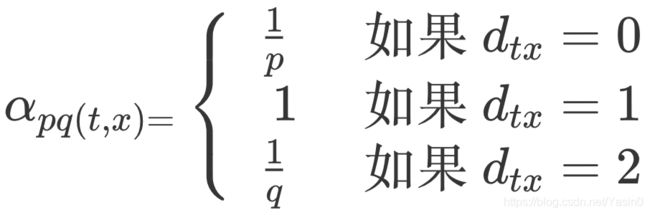
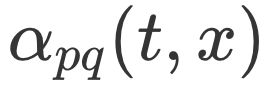 里的 dtx是指节点 t 到节点 x 的距离,比如节点 x1其实是与节点 t 直接相连的,所以这个距离 dtx就是 1,节点 t 到节点 t 自己的距离 dtt就是 0,而 x2、x3这些不与 t 相连的节点,dtx就是 2。
里的 dtx是指节点 t 到节点 x 的距离,比如节点 x1其实是与节点 t 直接相连的,所以这个距离 dtx就是 1,节点 t 到节点 t 自己的距离 dtt就是 0,而 x2、x3这些不与 t 相连的节点,dtx就是 2。
 中的参数 p 和 q 共同控制着随机游走的倾向性。参数 p 被称为返回参数(Return Parameter),p 越小,随机游走回节点 t 的可能性越大,Node2vec 就更注重表达网络的结构性。参数 q 被称为进出参数(In-out Parameter),q 越小,随机游走到远方节点的可能性越大,Node2vec 更注重表达网络的同质性。反之,当前节点更可能在附近节点游走。
中的参数 p 和 q 共同控制着随机游走的倾向性。参数 p 被称为返回参数(Return Parameter),p 越小,随机游走回节点 t 的可能性越大,Node2vec 就更注重表达网络的结构性。参数 q 被称为进出参数(In-out Parameter),q 越小,随机游走到远方节点的可能性越大,Node2vec 更注重表达网络的同质性。反之,当前节点更可能在附近节点游走。
可以通过调整 p 和 q 参数让它产生表达同质性和结构性不同的 Embedding 结果。
Node2vec 更注重同质性时,距离相近的节点颜色更为接近;更注重结构性时,结构特点相近的节点的颜色更为接近。
Node2vec 所体现的网络的同质性和结构性,在推荐系统中都是非常重要的特征表达。由于 Node2vec 的这种灵活性,以及发掘不同图特征的能力,我们甚至可以把不同 Node2vec 生成的偏向“结构性”的 Embedding 结果,以及偏向“同质性”的 Embedding 结果共同输入后续深度学习网络,以保留物品的不同图特征信息。
Embedding 的产出是一个数值型特征向量,与 One-hot 编码等方式不同,Embedding 是一种更高阶的特征处理方法,它具备了把序列结构、网络结构、甚至其他特征融合到一个特征向量中的能力。
Embedding 在推荐系统中的应用方式大致有三种:
- 直接应用:得到 Embedding 向量后,直接利用 Embedding 向量的相似性实现某些推荐系统的功能。典型的功能有,利用物品 Embedding 间的相似性实现相似物品推荐,利用物品 Embedding 和用户 Embedding 的相似性实现“猜你喜欢”,利用物品 Embedding 实现推荐系统中的召回层等。
- 预训练应用:在预先训练好物品和用户的 Embedding 之后,不直接应用,而是把这些 Embedding 向量作为特征向量的一部分,跟其余的特征向量拼接起来,作为推荐模型的输入参与训练。这样做能够更好地把其他特征引入进来,让推荐模型作出更为全面且准确的预测。
- End2End 应用(End to End Training,端到端训练):不预先训练 Embedding,而是把 Embedding 的训练与深度学习推荐模型结合起来,采用统一的、端到端的方式一起训练,直接得到包含 Embedding 层的推荐模型。如图展示了三个包含 Embedding 层的经典模型,分别是微软的 Deep Crossing,UCL 提出的 FNN 和 Google 的 Wide&Deep。
图6 带有Embedding层的深度学习模型
协同过滤算法是推荐系统自诞生以来最经典的算法,且没有之一。
协同过滤算法是一种完全依赖用户和物品之间行为关系的推荐算法。也就是 “协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出用户可能感兴趣的信息”。
电商推荐系统从得到原始数据到生成最终推荐分数,全过程一共可以总结为 6 个步骤,如下所示。
图1 协同过滤的过程
- 电商网站的商品库里一共有 4 件商品:一个游戏机、一本小说、一本杂志,以及一台电视机。假设,现在有一名用户 X 访问了这个电商网站,电商网站的推荐系统需要决定是否推荐电视机给用户 X。
- 为了进行这项预测,推荐系统可以利用的数据有用户 X 对其他商品的历史评价数据,以及其他用户对这些商品的历史评价数据。用绿色“点赞”的标志表示好评,用红色“踩”的标志表示了差评,那么用户、商品和评价记录就构成了带有标识的有向图。
- 为了方便计算,将有向图转换成矩阵的形式。这个矩阵表示了物品共同出现的情况,因此被称为“共现矩阵”。其中,用户作为矩阵行坐标,物品作为列坐标,把“点赞”和“踩”的用户行为数据转换为矩阵中相应的元素值。将“点赞”的值设为 1,将“踩”的值设为 -1,“没有数据”置为 0(如果用户对物品有具体的评分,那么共现矩阵中的元素值可以取具体的评分值,没有数据时的默认评分也可以取评分的均值)。生成共现矩阵之后,推荐问题就转换成了预测矩阵中问号元素的值的问题。
- 在“协同”过滤算法中,推荐的原理是让用户考虑与自己兴趣相似用户的意见。因此,我们预测的第一步就是找到与用户 X 兴趣最相似的 n(Top n 用户,这里的 n 是一个超参数)个用户,然后综合相似用户对“电视机”的评价,得出用户 X 对“电视机”评价的预测。从共现矩阵中可以知道,用户 B 和用户 C 由于跟用户 X 的行向量近似,被选为 Top n(这里假设 n 取 2)相似用户,
- 用户 B 和用户 C 对“电视机”的评价均是负面的。因为相似用户对“电视机”的评价是负面的,所以可以预测出用户 X 对“电视机”的评价也是负面的。
- 在实际的推荐过程中,推荐系统不会向用户 X 推荐“电视机”这一物品。
这个过程中有两点不严谨的地方,一是用户相似度到底该怎么定义,二是最后我们预测用户 X 对“电视机”的评价也是负面的,这个负面程度应该有一个什么样的推荐分数来衡量呢?
计算用户相似度
在共现矩阵中,每个用户对应的行向量其实就可以当作一个用户的 Embedding 向量。可以根据Embedding 相似度的计算方法,计算基于共现矩阵的用户相似度。如:余弦相似度、欧式距离、皮尔逊相关系数等等。
余弦相似度:衡量了用户向量 i 和用户向量 j 之间的向量夹角大小。夹角越小,余弦相似度越大,两个用户越相似,它的定义如下:
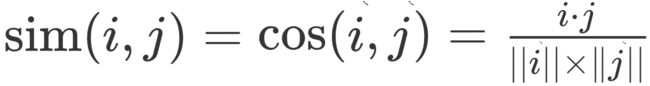
用户评分的预测(推荐分数的计算)
假设“目标用户与其相似用户的喜好是相似的”,利用 Top n 个相似用户的已有评价,对目标用户 u 对物品 p 的偏好进行预测。最常用的方式是,利用用户相似度和相似用户评价的加权平均值,来获得目标用户的评价预测,公式如下所示。
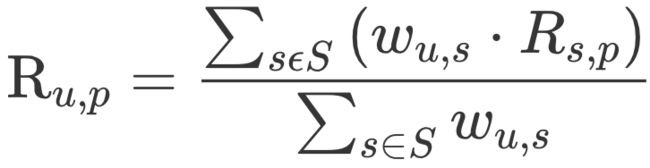
其中,权重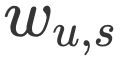 是用户 u 和用户 s 的相似度,
是用户 u 和用户 s 的相似度,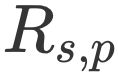 是用户 s 对物品 p 的评分。
是用户 s 对物品 p 的评分。
在获得用户 u 对不同物品的评价预测后,最终的推荐列表根据评价预测得分进行排序即可得到。
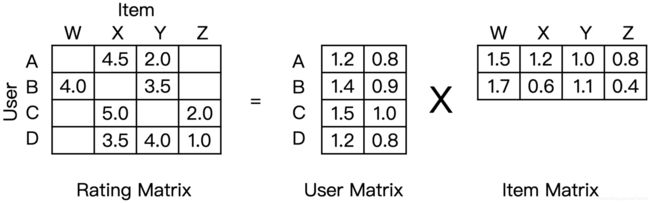
矩阵分解算法的原理
协同过滤虽然经典,但有共现矩阵往往比较稀疏的缺点,在用户历史行为很少的情况下,寻找相似用户的过程并不准确。矩阵分解算法对协同过滤算法进行了改进,加强了模型处理稀疏矩阵的能力。
图2 “协同过滤(左a)”和“矩阵分解(右b)”的原理图
- 协同过滤算法找到用户可能喜欢的视频的方式是利用用户的观看历史,找到跟目标用户 Joe 看过同样视频的相似用户,然后找到这些相似用户喜欢看的其他视频,推荐给目标用户 Joe。
- 矩阵分解算法是为每一个用户和视频生成一个隐向量,将用户和视频定位到隐向量的表示空间上,距离相近的用户和视频表明兴趣特点接近,在推荐时,可以把距离相近的视频推荐给目标用户。例如,如果希望为用户 Dave 推荐视频,可以找到离 Dave 的用户向量最近的两个视频向量,它们分别是《Ocean’s 11》和《The Lion King》,然后可以根据向量距离由近到远的顺序生成 Dave 的推荐列表。
矩阵分解相当于一种 Embedding 方法,先分解协同过滤生成的共现矩阵,生成用户和物品的隐向量,再通过用户和物品隐向量间的相似性进行推荐。
其实,矩阵分解算法就是为了解决协同过滤“泛化能力”不强而诞生的。因为协同过滤只会“死板”地使用用户的原始行为特征,而矩阵分解因为生成了用户和物品的隐向量,所以就可以计算任意两个用户和物品之间的相似度了。
如何分解共现矩阵?
矩阵分解的过程是把一个 mxn 的共现矩阵,分解成一个 mxk 的用户矩阵和 kxn 的物品矩阵相乘的形式。用户隐向量就是用户矩阵相应的行向量,物品隐向量就是物品矩阵相应的列向量。
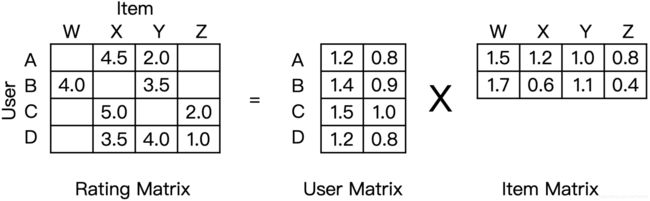
图3 矩阵分解示意图
该通过什么方法把共现矩阵分解开呢?最常用的方法就是梯度下降。梯度下降的原理就是通过求取偏导的形式来更新权重。梯度更新的公式是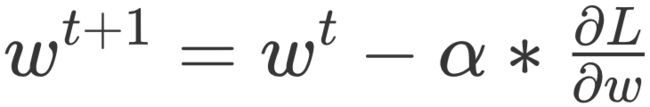 。为了实现梯度下降,需要定义损失函数 L,通过求导的方式找到梯度方向,矩阵分解损失函数的定义如下:
。为了实现梯度下降,需要定义损失函数 L,通过求导的方式找到梯度方向,矩阵分解损失函数的定义如下:
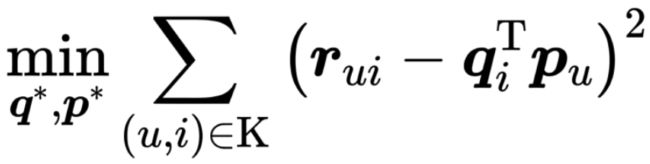
这个目标函数里面,rui 是共现矩阵里面用户 u 对物品 i 的评分,qi 是物品向量,pu 是用户向量,K 是所有用户评分物品的全体集合。通过目标函数的定义我们可以看到,我们要求的物品向量和用户向量,是希望让物品向量和用户向量之积跟原始的评分之差的平方尽量小。简单来说就是,我们希望用户矩阵和物品矩阵的乘积尽量接近原来的共现矩阵。
深度学习给推荐系统带来了革命性的影响,能够显著提升推荐系统的效果,原因主要有两点,一是深度学习极大地增强了推荐模型的拟合能力,二是深度学习模型可以利用模型结构模拟用户兴趣的变迁、用户注意力机制等不同的用户行为过程。
1. 深度学习模型的强拟合能力
在矩阵分解模型的结构(图 1 左)中,用户 One-hot 向量和物品 One-hot 向量分居两侧,它们会先通过隐向量层转换成用户和物品隐向量,再通过点积的方式交叉生成最终的打分预测。但是,点积这种特征向量交叉的方式过于简单,在数据模式比较复杂的情况下,往往存在欠拟合的情况。
深度学习模型有非常强的拟合能力,比如在 NeuralCF(神经网络协同过滤)模型中,点积层被替换为多层神经网络,理论上多层神经网络具备拟合任意函数的能力,所以我们通过增加神经网络层的方式就能解决模型欠拟合的问题了。
图1 矩阵分解模型示意图
DIN(深度兴趣网络)和 DIEN(深度兴趣进化网络)通过在模型结构中引入注意力机制和模拟兴趣进化的序列模型,来更好地模拟用户的行为。
图4 DIN模型(左)和DIEN的模型(右)示意图
为了模拟人类的注意力机制,DIN 模型在神经网络中增加了“激活单元“的结构。一个典型的注意力机制是,我们在购买电子产品时,更容易拿之前购买其他电子产品的经验来指导当前的购买行为,很少会借鉴购买衣服和鞋子的经验,因为我们只会注意到相关度更高的历史购买行为。
DIN 模型的改进版 DIEN 模型不仅引入了注意力机制,还模拟了用户兴趣随时间的演化过程。我们来看那些彩色的层,这一层层的序列结构模拟的正是用户兴趣变迁的历史,通过模拟变迁的历史,DIEN 模型可以更好地预测下一步用户会喜欢什么。
很多重要的深度学习模型的改进动机是通过改变模型结构来模拟用户行为。正是因为深度模型的灵活性,让它能够更轻松地模拟人们的思考过程和行为过程,让推荐模型像一个无所不知的超级大脑一样,把用户猜得更透。
深度学习推荐模型的演化关系图
深度学习模型 5 年内的发展过程图,图中的每一个节点都是一个重要的模型结构,节点之间的连线也揭示了不同模型间的联系。
“多层神经网络”或者“多层感知机”,简称 MLP(MultiLayer Perceptron)会对输入的特征进行深度地组合交叉,然后输出对兴趣值的预测。它是深度学习最基础的结构,其他的深度推荐模型全都是在多层感知机的基础上,进行结构上的改进而生成的,所以MLP是整个演化图的核心。
图中,MLP上方的是Deep Crossing,相比于 MLP,Deep Crossing 在原始特征和 MLP 之间加入了 Embedding 层。通过将输入的稀疏特征先转换成稠密 Embedding 向量,再参与到 MLP 中进行训练,解决了 MLP 不善于处理稀疏特征的问题。
从 MLP 向下,Wide&Deep 模型把深层的 MLP 和单层的神经网络结合起来,希望同时让网络具备很好的“泛化性”和“记忆性”。由于 Wide&Deep 有“易实现”、“易落地”、“易改造”的特点,衍生出了诸多变种,比如,通过改造 Wide 部分提出的 Deep&Cross 和 DeepFM,通过改造 Deep 部分提出的 AFM、NFM 等等。
模型改进的四个方向:
- 改变神经网络的复杂程度。 从最简单的单层神经网络模型 AutoRec,到经典的深度神经网络结构 Deep Crossing,它们主要的进化方式在于增加了深度神经网络的层数和结构复杂度。
- 改变特征交叉方式。比如,改变用户向量和物品向量互操作方式的 NeuralCF,定义了多种特征向量交叉操作的 PNN 等等,提高深度学习网络中特征交叉的能力。
- 把多种模型组合应用。 组合模型主要指的就是以 Wide&Deep 模型为代表的一系列把不同结构组合在一起的改进思路。它通过组合两种甚至多种不同特点、优势互补的深度学习网络,来提升模型的综合能力。
- 让深度推荐模型和其他领域进行交叉。一般来说,自然语言处理、图像处理、强化学习这些领域汲取新知识。深度学习和注意力机制的结合(深度兴趣网络 DIN、AFM 等等);把序列模型引入 MLP+Embedding (深度兴趣进化网络 DIEN);把深度学习和强化学习结合在一起(深度强化学习网络 DRN)
TensorFlow 直译为“张量流动”,它的基本原理是根据深度学习的模型架构构建一个由点和边组成的有向图,让数据以张量的形式在其中流动起来。
- 张量(Tensor)是指向量的高维扩展,比如向量可以看作是张量的一维形式,矩阵可以看作张量在二维空间上的特例,在深度学习中大部分数据是以矩阵甚至更高维的张量表达的。
- 图里面的点代表着某种操作,比如某个激活函数、某种矩阵运算等等,而边就定义了张量流动的方向。
一个简单 TensorFlow 任务的有向图:向量 b、矩阵 W 和向量 x 是模型的输入,紫色的节点 MatMul、Add 和 ReLU 是操作节点,分别代表了矩阵乘法、向量加法、ReLU 激活函数这样的操作。模型的输入张量 W、b、x 经过操作节点的变形处理之后,在点之间传递,这就是 TensorFlow 名字里所谓的张量流动。
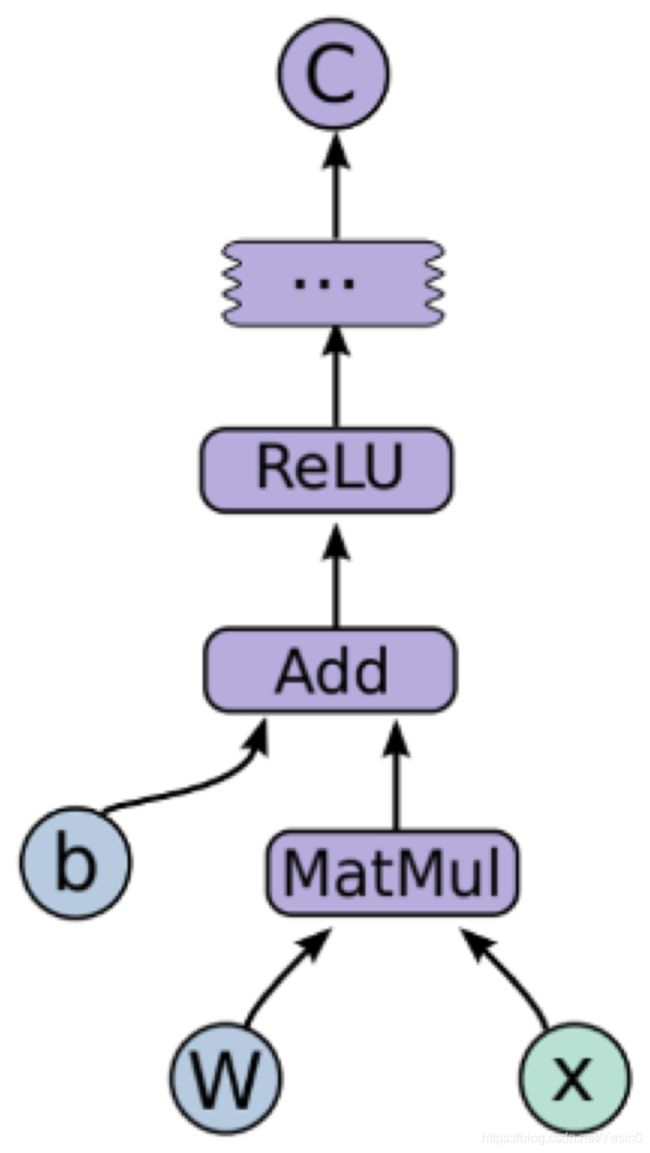
图1 一个简单的TensorFlow有向图
事实上,任何复杂模型都可以抽象为操作有向图的形式。这样做不仅有利于操作的模块化,还可以厘清各操作间的依赖关系,有利于我们判定哪些操作可以并行执行,哪些操作只能串行执行,为并行平台能够最大程度地提升训练速度打下基础。
Embedding+MLP 模型的结构
Deep Crossing是一个经典的 Embedding+MLP 的模型结构,它从下到上可以分为 5 层,分别是 Feature 层、Embedding 层、Stacking 层、MLP 层和 Scoring 层。
一句话总结它的结构重点:对于类别特征,先利用 Embedding 层进行特征稠密化,再利用 Stacking 层连接其他特征,输入 MLP 的多层结构,最后用 Scoring 层预估结果。
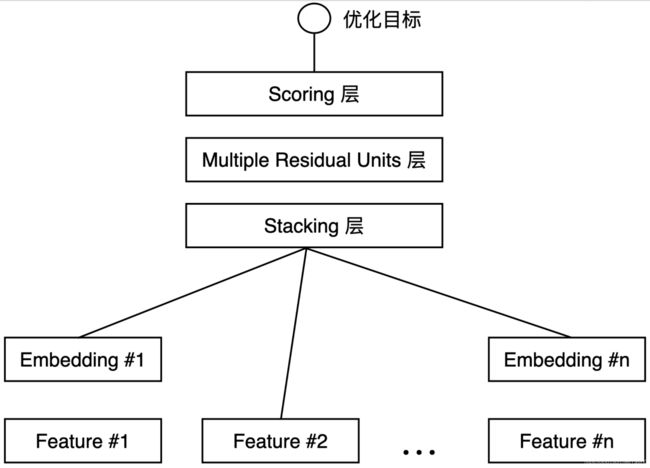
图 经典的Embedding+MLP模型结构Deep Crossing
- Feature 层也叫做输入特征层,它作为整个模型的输入,处于 Deep Crossing 的最底部。需要注意的是,不同特征在处理细节上有一些区别,比如 Feature#1 代表的是类别型特征经过 One-hot 编码后生成的特征向量,它向上连接到了 Embedding 层,而 Feature#2 代表的是数值型特征,直接连接到了更上方的 Stacking 层。
- Embedding 层的作用是:把不适合直接输入到神经网络中训练的稀疏One-hot 向量转换成稠密的 Embedding 向量。但Embedding 层并不是全部连接起来的,而是每一个特征对应一个 Embedding 层,不同 Embedding 层之间互不干涉。Embeding 层的结构就是 Word2vec 模型中从输入神经元到隐层神经元的部分(如图红框内的部分),它是一个从输入层到隐层之间的全连接网络。一般来说,Embedding 向量的维度为几十到上百维就能够满足需求。
- Stacking 层(堆叠层,Concatenate连接层)的作用是把不同的 Embedding 特征和数值型特征拼接在一起,形成新的包含全部特征的特征向量。
- MLP 层是多层神经网络层,它的特点是不同层的神经元两两之间都有连接,全连接的权重会在梯度反向传播的学习过程中发生改变。它的作用是让特征向量不同维度之间做充分的交叉,让模型能够抓取到更多的非线性特征和组合特征的信息,使深度学习模型在表达能力上较传统机器学习模型大为增强。Deep Crossing 针对特定的问题选择了Multiple Residual Units 层(多层残差网络),但神经元的选择有非常多种,如以 Sigmoid、tanh、ReLU 等激活函数的神经元。一般来说,ReLU 最经常使用在隐层神经元上,Sigmoid 则多使用在输出神经元。
- Scoring 层为输出层。我们要预测的目标往往是一个分类的概率。如果是二分类问题,可以采用逻辑回归作为输出层神经元;如果是多分类问题,可以在输出层采用 softmax 作为输出神经元的激活函数。
Wide&Deep 模型的结构
Wide&Deep 模型是由左侧的 Wide 部分的线性模型和右侧的 Deep 部分神经网络组成的混合式模型结构。Wide 部分是把输入层直接连接到输出层,中间没有做任何处理,它的主要作用是让模型具有较强的“记忆能力”(Memorization),让模型记住大量的直接且重要的规则,这正是单层的线性模型所擅长的。Deep 部分是 Embedding+MLP 的模型结构,它的主要作用是让模型具有“泛化能力”(Generalization)。这种混合式模型结构的特点,可以让模型兼具逻辑回归和深度神经网络的优点,既能快速处理和记忆大量历史行为特征,又具有强大的表达能力。
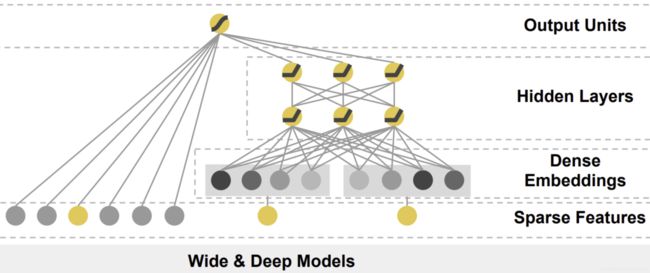
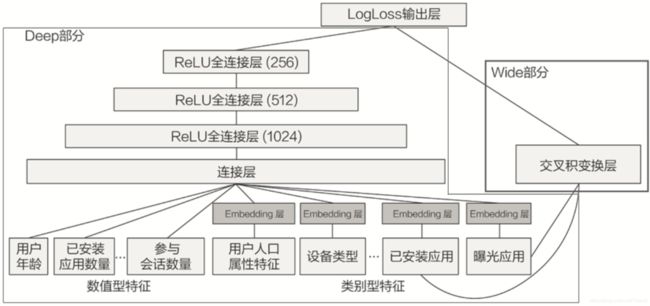
Wide 部分的记忆能力
模型的记忆能力可以被宽泛地理解为模型直接学习历史数据中物品或者特征的“共现频率”,并且把它们直接作为推荐依据的能力 。
如在电影推荐中,大部分看了 A 电影的用户都喜欢看电影 B,这种“因为 A 所以 B”式的规则,非常直接也非常有价值。但这类规则有两个特点:(1)数量非常多,“记性不好”的推荐模型很难把它们都记住;(2)没办法推而广之,因为这类规则非常具体,没办法或者说也没必要跟其他特征做进一步的组合。因为看了电影 A 的用户 80% 都喜欢看电影 B,这个特征已经非常强了,没必要把它跟其他特征再组合在一起。
Wide&Deep 模型是应用在 Google Play 为用户推荐 APP 的场景下,它的推荐目标是推荐那些用户可能喜欢,愿意安装的应用。其Wide 部分的特征只利用了两个特征的交叉,这两个特征是“已安装应用”和“当前曝光应用”。Wide 部分想学到的知识就是希望模型记住“如果用户已经安装了应用 A,是否会安装 B”这样的规则。
Deep 部分的泛化能力
模型的泛化能力是指模型对于新鲜样本、以及从未出现过的特征组合的预测能力。
假设,我们知道 ① 25 岁的男性用户喜欢看电影 A,② 35 岁的女性用户也喜欢看电影 A 这两个条件,对于“35 岁的男性喜不喜欢看电影 A”这样的问题。只有记忆能力的模型会“说”,我从来没学过这样的知识啊,没法回答你;有泛化能力模型的思考逻辑可能是这样的:从第一条知识,可以学到男性用户是喜欢看电影 A 的。从第二条知识,可以学到 35 岁的用户是喜欢看电影 A 的。那在没有其他知识的前提下,35 岁的男性同时包含了合适的年龄和性别这两个特征,所以他大概率也是喜欢电影 A 的。
深度学习模型有很强的数据拟合能力,在多层神经网络中,特征可以得到充分的交叉,让模型学习到新的知识。因此,Wide&Deep 模型的 Deep 部分,使用 Embedding+MLP 的模型结构,来增强模型的泛化能力。模型有了很强的泛化能力之后,可以对一些非常稀疏的,甚至从未出现过的情况作出尽量“靠谱”的预测。
在 Google Play 的场景下,Deep 部分的输入特征很多,有用户年龄、属性特征、设备类型,还有已安装应用的 Embedding 等等。把这些特征一股脑地放进多层神经网络里面去学习之后,它们互相之间会发生多重的交叉组合,这最终会让模型具备很强的泛化能力。比如说,我们把用户年龄、人口属性和已安装应用组合起来。假设,样本中有 25 岁男性安装抖音的记录,也有 35 岁女性安装抖音的记录,那我们该怎么预测 25 岁女性安装抖音的概率呢?这就需要用到已有特征的交叉来实现了。虽然我们没有 25 岁女性安装抖音的样本,但模型也能通过对已有知识的泛化,经过多层神经网络的学习,来推测出这个概率。
协同过滤的深度学习进化版本:NeuralCF(神经网络协同过滤)
协同过滤是利用用户和物品之间的交互行为历史,构建出一个共现矩阵。在共现矩阵的基础上,利用每一行的用户向量相似性,找到相似用户,再利用相似用户喜欢的物品进行推荐。但由于它是直接利用非常稀疏的共现矩阵进行预测的,模型的泛化能力非常弱,遇到历史行为非常少的用户,就没法产生准确的推荐结果了。
矩阵分解加强了协同过滤的泛化能力,它把协同过滤中的共现矩阵分解成了用户矩阵和物品矩阵,从用户矩阵中提取出用户隐向量,从物品矩阵中提取出物品隐向量,再利用它们之间的内积相似性进行推荐排序。但因为矩阵分解是利用非常简单的内积方式来处理用户向量和物品向量的交叉问题,它的拟合能力也比较弱。
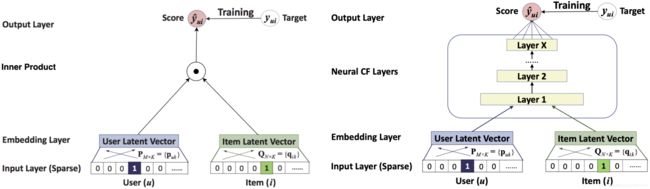
如果用神经网络的思路来理解矩阵分解,它的结构图就是图这样的。图中的输入层是由用户 ID 和物品 ID 生成的 One-hot 向量,Embedding 层是把 One-hot 向量转化成稠密的 Embedding 向量表达,这部分就是矩阵分解中的用户隐向量和物品隐向量。输出层使用了用户隐向量和物品隐向量的内积作为最终预测得分,之后通过跟目标得分对比,进行反向梯度传播,更新整个网络。
把矩阵分解神经网络化之后,把它跟 Embedding+MLP 以及 Wide&Deep 模型做对比,矩阵分解在 Embedding 层之上的操作过于简单,就是直接利用内积得出最终结果。这会导致特征之间还没有充分交叉就直接输出结果,模型会有欠拟合的风险。
深度学习模型的拟合能力都很强,可以利用深度学习来改进协同过滤和矩阵分解算法,它可以大大提高协同过滤算法的泛化能力和拟合能力。
NeuralCF 模型用一个多层的神经网络替代掉了原来简单的点积操作, 可以让用户和物品隐向量之间进行充分的交叉,提高模型整体的拟合能力。
NeuralCF 模型的扩展:双塔模型
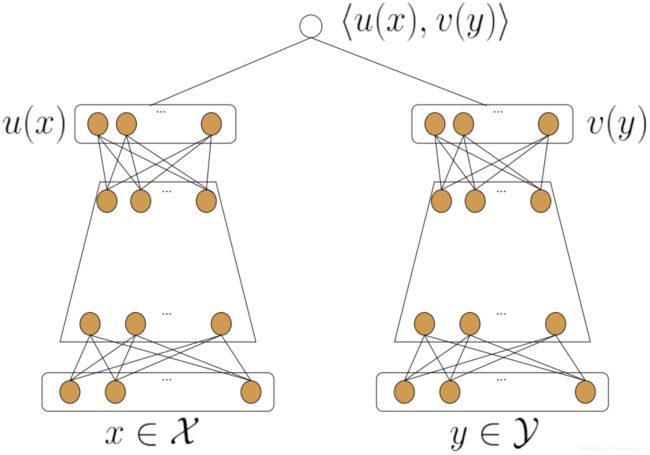
NeuralCF 模型蕴含了一个非常有价值的思想:可以把模型分成用户侧模型和物品侧模型两部分,然后用互操作层把这两部分联合起来,产生最后的预测得分。
这里的用户侧模型结构和物品侧模型结构,可以是简单的 Embedding 层,也可以是复杂的神经网络结构,最后的互操作层可以是简单的点积操作,也可以是比较复杂的网络结构。这种物品侧模型 + 用户侧模型 + 互操作层的模型结构,我们把它统称为“双塔模型”结构。
左图是一个典型“双塔模型”的抽象结构。它的名字形象地解释了它的结构组成,两侧的模型结构就像两个高塔一样,而最上面的互操作层则像两个塔尖搭建起的空中走廊,负责两侧信息的沟通。
对于 NerualCF 来说,它只利用了用户 ID 作为“用户塔”的输入特征,用物品 ID 作为“物品塔”的输入特征。事实上,我们完全可以把其他用户和物品相关的特征也分别放入用户塔和物品塔,让模型能够学到的信息更全面。
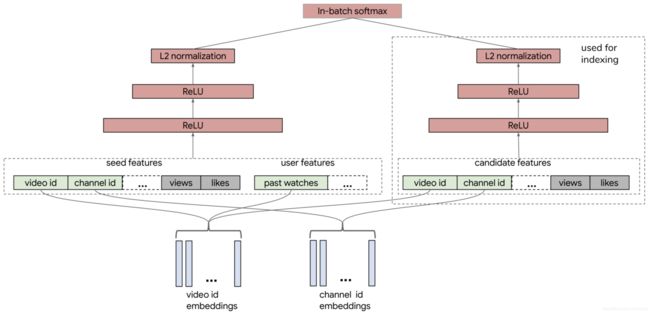
YouTube 在构建用于召回层的双塔模型时,就分别在用户侧和物品侧输入了多种不同的特征。用户侧特征包括了用户正在观看的视频 ID、频道 ID(图中的 seed features)、该视频的观看数、被喜欢的次数,以及用户历史观看过的视频 ID 等等。物品侧的特征包括了候选视频的 ID、频道 ID、被观看次数、被喜欢次数等等。
在经过了多层 ReLU 神经网络的学习之后,双塔模型最终通过 softmax 输出层连接两部分,输出最终预测分数。
双塔模型相比 Embedding MLP 和 Wide&Deep 有什么优势呢?
双塔模型最重要的优势就在于它易上线、易服务。
因为物品塔和用户塔最顶端那层神经元的输出其实就是一个全新的物品 Embedding 和用户 Embedding。如物品塔的输入特征向量是 x,经过物品塔的一系列变换,生成了向量 u(x),那么这个 u(x) 就是这个物品的 Embedding 向量。同理,v(y) 是用户 y 的 Embedding 向量。
这时,我们就可以把 u(x) 和 v(y) 存入特征数据库,线上服务的时候,只要把 u(x) 和 v(y) 取出来,再做简单的互操作层运算就可以得出最后的模型预估结果了!
所以使用双塔模型,我们不用把整个模型都部署上线,只需要预存物品塔和用户塔的输出,在线上实现互操作层就可以了。
DeepFM:让模型更好地处理特征交叉
Embedding MLP、Wide&Deep、NerualCF 等几种不同的模型结构都是怎么处理特征交叉这个问题的?
比如说,模型的输入有性别、年龄、电影风格这几个特征,在训练样本中我们发现有 25 岁男生喜欢科幻电影的样本,有 35 岁女生喜欢看恐怖电影的样本,那你觉得模型应该怎么推测“25 岁”的女生喜欢看的电影风格呢?
事实上,这类特征组合和特征交叉问题非常常见,而且在实际应用中,特征的种类还要多得多,特征交叉的复杂程度也要大得多。解决这类问题的关键,就是模型对于特征组合和特征交叉的学习能力,因为它决定了模型对于未知特征组合样本的预测能力,而这对于复杂的推荐问题来说,是决定其推荐效果的关键点之一。
但无论是 Embedding MLP,还是 Wide&Deep 其实都没有对特征交叉进行特别的处理,而是直接把独立的特征扔进神经网络,让它们在网络里面进行自由组合,就算是 NeuralCF 也只在最后才把物品侧和用户侧的特征交叉起来。这样的特征交叉方法是低效的。
为什么深度学习模型需要加强处理特征交叉的能力?
Embedding MLP 和 Wide&Deep 模型都没有针对性的处理特征交叉问题,有的同学可能就会有疑问了,我们之前不是一直说,多层神经网络有很强的拟合能力,能够在网络内部任意地组合特征吗?这两个说法是不是矛盾了?
MLP 有拟合任意函数的能力,是建立在 MLP 有任意多层网络,以及任意多个神经元的前提下的。
在训练资源有限,调参时间有限的现实情况下,MLP 对于特征交叉的处理其实还比较低效。因为 MLP 是通过 concatenate 层把所有特征连接在一起成为一个特征向量的,这里面没有特征交叉,两两特征之间没有发生任何关系。
这个时候,在我们有先验知识的情况下,人为地加入一些负责特征交叉的模型结构,其实对提升模型效果会非常有帮助。比如,有两个这样的特征,一个是用户喜欢的电影风格,一个是电影本身的风格,这两个特征明显具有很强的相关性。如果我们能让模型利用起这样的相关性,肯定会对最后的推荐效果有正向的影响。
既然这样,那我们不如去设计一些特定的特征交叉结构,来把这些相关性强的特征,交叉组合在一起,这就是深度学习模型要加强特征交叉能力的原因了。
善于处理特征交叉的机器学习模型 FM
传统的机器学习模型是怎么解决特征交叉问题的,看看深度学习模型能不能从中汲取到“养分”。
说到解决特征交叉问题的传统机器学习模型,我们就不得不提一下,曾经红极一时的机器学习模型因子分解机模型(Factorization Machine)了,我们可以简称它为 FM。
图1 FM的神经网络化结构
首先,我们看上图中模型的最下面,它的输入是由类别型特征转换成的 One-hot 向量,往上就是深度学习的常规操作,也就是把 One-hot 特征通过 Embedding 层转换成稠密 Embedding 向量。到这里,FM 跟其他深度学习模型其实并没有区别,但再往上区别就明显了。
FM 会使用一个独特的层 FM Layer 来专门处理特征之间的交叉问题。你可以看到,FM 层中有多个内积操作单元对不同特征向量进行两两组合,这些操作单元会把不同特征的内积操作的结果输入最后的输出神经元,以此来完成最后的预测。
这样一来,如果我们有两个特征是用户喜爱的风格和电影本身的风格,通过 FM 层的两两特征的内积操作,这两个特征就可以完成充分的组合,不至于像 Embedding MLP 模型一样,还要 MLP 内部像黑盒子一样进行低效的交叉。
深度学习模型和 FM 模型的结合 DeepFM
这个时候问题又来了,FM 是一个善于进行特征交叉的模型,但是我们之前也讲过,深度学习模型的拟合能力强啊,那二者之间能结合吗?
学习过 Wide&Deep 结构之后,我们一定可以快速给出答案,我们当然可以把 FM 跟其他深度学习模型组合起来,生成一个全新的既有强特征组合能力,又有强拟合能力的模型。基于这样的思想,DeepFM 模型就诞生了。
DeepFM 是由哈工大和华为公司联合提出的深度学习模型,我把它的架构示意图放在了下面。
图2 DeepFM模型架构图
结合模型结构图,我们可以看到,DeepFM 利用了 Wide&Deep 组合模型的思想,用 FM 替换了 Wide&Deep 左边的 Wide 部分,加强了浅层网络部分特征组合的能力,而右边的部分跟 Wide&Deep 的 Deep 部分一样,主要利用多层神经网络进行所有特征的深层处理,最后的输出层是把 FM 部分的输出和 Deep 部分的输出综合起来,产生最后的预估结果。这就是 DeepFM 的结构。
特征交叉新方法:元素积操作
FM 和 DeepFM 中进行特征交叉的方式,都是进行 Embedding 向量的点积操作,事实上还有很多向量间的运算方式可以进行特征的交叉,比如模型 NFM(Neural Factorization Machines,神经网络因子分解机),它就使用了新的特征交叉方法。
图 3 就是 NFM 的模型架构图,它跟其他模型的区别,也就是 Bi-Interaction Pooling 层。那这个夹在 Embedding 层和 MLP 之间的层到底做了什么呢?

图3 NFM的模型架构图 (出自论文Neural Factorization Machines for Sparse Predictive Analytics)
Bi-Interaction Pooling Layer 翻译成中文就是“两两特征交叉池化层”。假设 Vx 是所有特征域的 Embedding 集合,那么特征交叉池化层的具体操作如下所示。
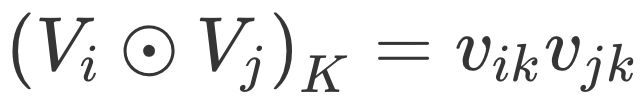
其中 ⊙ 运算代表两个向量的元素积(Element-wise Product)操作,即两个长度相同的向量对应维相乘得到元素积向量。其中,第 k 维的操作如下所示。
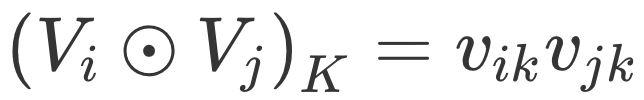
在进行两两特征 Embedding 向量的元素积操作后,再求取所有交叉特征向量之和,我们就得到了池化层的输出向量。接着,我们再把该向量输入上层的多层全连接神经网络,就能得出最后的预测得分。
总的来说,NFM 并没有使用内积操作来进行特征 Embedding 向量的交叉,而是使用元素积的操作。在得到交叉特征向量之后,也没有使用 concatenate 操作把它们连接起来,而是采用了求和的池化操作,把它们叠加起来。
看到这儿,你肯定又想问,元素积操作和点积操作到底哪个更好呢?还是那句老话,我希望我们能够尽量多地储备深度学习模型的相关知识,先不去关注哪个方法的效果会更好,至于真实的效果怎么样,交给你去在具体的业务场景的实践中验证。
注意力机制、兴趣演化:推荐系统如何抓住用户的心?
近几年来,注意力机制、兴趣演化序列模型和强化学习,都在推荐系统领域得到了广泛的应用。它们是深度学习推荐模型的发展趋势,也是我们必须要储备的前沿知识。
作为一名算法工程师,足够的知识储备是非常重要的,因为在掌握了当下主流的深度学习模型架构(Embedding MLP 架构、Wide&Deep 和 DeepFM 等等)之后,要想再进一步提高推荐系统的效果,就需要清楚地知道业界有哪些新的思路可以借鉴,学术界有哪些新的思想可以尝试,这些都是我们取得持续成功的关键。
所以,我会用两节课的时间,带你一起学习这几种新的模型改进思路。今天我们先重点关注注意力机制和兴趣演化序列模型,下节课我们再学习强化学习。
什么是“注意力机制”?
“注意力机制”来源于人类天生的“选择性注意”的习惯。最典型的例子是用户在浏览网页时,会有选择性地注意页面的特定区域,而忽视其他区域。
比如,图 1 是 Google 对大量用户进行眼球追踪实验后,得出的页面注意力热度图。我们可以看到,用户对页面不同区域的注意力区别非常大,他们的大部分注意力就集中在左上角的几条搜索结果上。
那么,“注意力机制”对我们构建推荐模型到底有什么价值呢?
图1 Google搜索结果的注意力热度图
价值是非常大的。比如说,我们要做一个新闻推荐的模型,让这个模型根据用户已经看过的新闻做推荐。那我们在分析用户已浏览新闻的时候,是把标题、首段、全文的重要性设置成完全一样比较好,还是应该根据用户的注意力不同给予不同的权重呢?当然,肯定是后者比较合理,因为用户很可能都没有注意到正文最后的几段,如果你分析内容的时候把最后几段跟标题、首段一视同仁,那肯定就把最重要的信息给淹没了。
事实上,近年来,注意力机制已经成功应用在各种场景下的推荐系统中了。其中最知名的,要数阿里巴巴的深度推荐模型,DIN(Deep Interest Network,深度兴趣网络)。接下来,我们就一起来学习一下 DIN 的原理和模型结构。
注意力机制在深度兴趣网络 DIN 上的应用
DIN 模型的应用场景是阿里最典型的电商广告推荐。对于付了广告费的商品,阿里会根据模型预测的点击率高低,把合适的广告商品推荐给合适的用户,所以 DIN 模型本质上是一个点击率预估模型。
注意力机制是怎么应用在 DIN 模型里的呢?回答这个问题之前,我们得先看一看 DIN 在应用注意力机制之前的基础模型是什么样的,才能搞清楚注意力机制能应用在哪,能起到什么作用。
下面的图 2 就是 DIN 的基础模型 Base Model。我们可以看到,Base Model 是一个典型的 Embedding MLP 的结构。它的输入特征有用户属性特征(User Proflie Features)、用户行为特征(User Behaviors)、候选广告特征(Candidate Ad)和场景特征(Context Features)。
用户属性特征和场景特征我们之前也已经讲过很多次了,这里我们重点关注用户的行为特征和候选广告特征,也就是图 2 中彩色的部分。
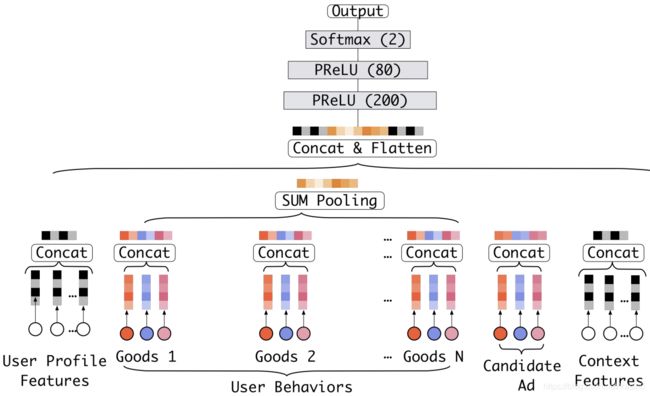
图2 阿里Base模型的架构图 (出自论文 Deep Interest Network for Click-Through Rate Prediction)
我们可以清楚地看到,用户行为特征是由一系列用户购买过的商品组成的,也就是图上的 Goods 1 到 Goods N,而每个商品又包含了三个子特征,也就是图中的三个彩色点,其中红色代表商品 ID,蓝色是商铺 ID,粉色是商品类别 ID。同时,候选广告特征也包含了这三个 ID 型的子特征,因为这里的候选广告也是一个阿里平台上的商品。
我们之前讲过,在深度学习中,只要遇到 ID 型特征,我们就构建它的 Embedding,然后把 Embedding 跟其他特征连接起来,输入后续的 MLP。阿里的 Base Model 也是这么做的,它把三个 ID 转换成了对应的 Embedding,然后把这些 Embedding 连接起来组成了当前商品的 Embedding。
完成了这一步,下一步就比较关键了,因为用户的行为序列其实是一组商品的序列,这个序列可长可短,但是神经网络的输入向量的维度必须是固定的,那我们应该怎么把这一组商品的 Embedding 处理成一个长度固定的 Embedding 呢?图 2 中的 SUM Pooling 层的结构就给出了答案,就是直接把这些商品的 Embedding 叠加起来,然后再把叠加后的 Embedding 跟其他所有特征的连接结果输入 MLP。
但这个时候问题又来了,SUM Pooling 的 Embedding 叠加操作其实是把所有历史行为一视同仁,没有任何重点地加起来,这其实并不符合我们购物的习惯。
举个例子来说,候选广告对应的商品是“键盘”,与此同时,用户的历史行为序列中有这样几个商品 ID,分别是“鼠标”“T 恤”和“洗面奶”。从我们的购物常识出发,“鼠标”这个历史商品 ID 对预测“键盘”广告点击率的重要程度应该远大于后两者。从注意力机制的角度出发,我们在购买键盘的时候,会把注意力更多地投向购买“鼠标”这类相关商品的历史上,因为这些购买经验更有利于我们做出更好的决策。
好了,现在我们终于看到了应用注意力机制的地方,那就是用户的历史行为序列。阿里正是在 Base Model 的基础上,把注意力机制应用在了用户的历史行为序列的处理上,从而形成了 DIN 模型。那么,DIN 模型中应用注意力机制的方法到底是什么呢?
我们可以从下面的 DIN 模型架构图中看到,与 Base Model 相比,DIN 为每个用户的历史购买商品加上了一个激活单元(Activation Unit),这个激活单元生成了一个权重,这个权重就是用户对这个历史商品的注意力得分,权重的大小对应用户注意力的高低。
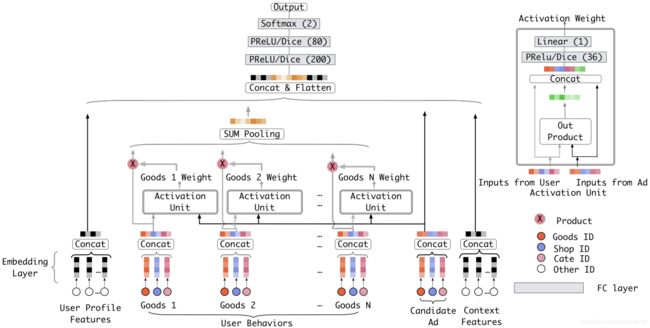
图3 阿里DIN模型的架构图 (出自论文 Deep Interest Network for Click-Through Rate Prediction)
那现在问题就只剩下一个了,这个所谓的激活单元,到底是怎么计算出最后的注意力权重的呢?为了搞清楚这个问题,我们需要深入到激活单元的内部结构里面去,一起来看看图 3 右上角激活单元的详细结构。
它的输入是当前这个历史行为商品的 Embedding,以及候选广告商品的 Embedding。我们把这两个输入 Embedding,与它们的外积结果连接起来形成一个向量,再输入给激活单元的 MLP 层,最终会生成一个注意力权重,这就是激活单元的结构。简单来说,激活单元就相当于一个小的深度学习模型,它利用两个商品的 Embedding,生成了代表它们关联程度的注意力权重。
到这里,我们终于抽丝剥茧地讲完了整个 DIN 模型的结构细节。如果你第一遍没理解清楚,没关系,对照着 DIN 模型的结构图,反复再看几遍我刚才讲的细节,相信你就能彻底消化吸收它。
注意力机制对推荐系统的启发
注意力机制的引入对于推荐系统的意义是非常重大的,它模拟了人类最自然,最发自内心的注意力行为特点,使得推荐系统更加接近用户真实的思考过程,从而达到提升推荐效果的目的。
从“注意力机制”开始,越来越多对深度学习模型结构的改进是基于对用户行为的深刻观察而得出的。由此,我也想再次强调一下,一名优秀的算法工程师应该具备的能力,就是基于对业务的精确理解,对用户行为的深刻观察,得出改进模型的动机,进而设计出最合适你的场景和用户的推荐模型。
沿着这条思路,阿里的同学们在提出 DIN 模型之后,并没有停止推荐模型演化的进程,他们又在 2019 年提出了 DIN 模型的演化版本,也就是深度兴趣进化网络 DIEN(Deep Interest Evolution Network)。这个 DIEN 到底在 DIN 的基础上做了哪些改进呢?
兴趣进化序列模型
无论是电商购买行为,还是视频网站的观看行为,或是新闻应用的阅读行为,特定用户的历史行为都是一个随时间排序的序列。既然是和时间相关的序列,就一定存在前后行为的依赖关系,这样的序列信息对于推荐过程是非常有价值的。为什么这么说呢?
我们还拿阿里的电商场景举个例子。对于一个综合电商来说,用户兴趣的迁移其实是非常快的。比如,上一周一位用户在挑选一双篮球鞋,这位用户上周的行为序列都会集中在篮球鞋这个品类的各个商品上,但在他完成这一购物目标后,这一周他的购物兴趣就可能变成买一个机械键盘,那这周他所有的购买行为都会围绕机械键盘这个品类展开。
因此,如果我们能让模型预测出用户购买商品的趋势,肯定会对提升推荐效果有益。而 DIEN 模型正好弥补了 DIN 模型没有对行为序列进行建模的缺陷,它围绕兴趣进化这个点进一步对 DIN 模型做了改进。
图 4 就是 DIEN 模型的架构图,这个模型整体上仍然是一个 Embedding MLP 的模型结构。与 DIN 不同的是,DIEN 用“兴趣进化网络”也就是图中的彩色部分替换掉了原来带有激活单元的用户历史行为部分。这部分虽然复杂,但它的输出只是一个 h'(T) 的 Embedding 向量,它代表了用户当前的兴趣向量。有了这个兴趣向量之后,再把它与其他特征连接在一起,DIEN 就能通过 MLP 作出最后的预测了。
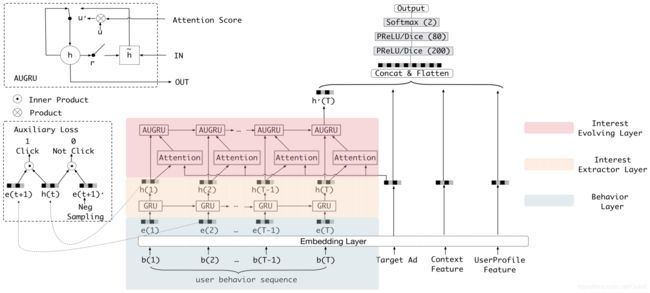
好了,现在问题的焦点就在,DIEN 模型是如何生成这个兴趣向量的。关键就在于 DIEN 模型中彩色部分的三层兴趣进化网络,下面,我就按照从下到上的顺序,给你讲讲它们的名称和作用。
最下面一层是行为序列层(Behavior Layer,浅绿色部分)。它的主要作用和一个普通的 Embedding 层是一样的,负责把原始的 ID 类行为序列转换成 Embedding 行为序列。
再上一层是兴趣抽取层(Interest Extractor Layer,浅黄色部分)。它的主要作用是利用 GRU 组成的序列模型,来模拟用户兴趣迁移过程,抽取出每个商品节点对应的用户兴趣。
最上面一层是兴趣进化层(Interest Evolving Layer,浅红色部分)。它的主要作用是利用 AUGRU(GRU with Attention Update Gate) 组成的序列模型,在兴趣抽取层基础上加入注意力机制,模拟与当前目标广告(Target Ad)相关的兴趣进化过程,兴趣进化层的最后一个状态的输出就是用户当前的兴趣向量 h'(T)。
你发现了吗,兴趣抽取层和兴趣进化层都用到了序列模型的结构,那什么是序列模型呢?直观地说,图 5 就是一个典型的序列模型的结构,它和我们之前看到的多层神经网络的结构不同,序列模型是“一串神经元”,其中每个神经元对应了一个输入和输出。
在 DIEN 模型中,神经元的输入就是商品 ID 或者前一层序列模型的 Embedding 向量,而输出就是商品的 Embedding 或者兴趣 Embedding,除此之外,每个神经元还会与后续神经元进行连接,用于预测下一个状态,放到 DIEN 里就是为了预测用户的下一个兴趣。这就是序列模型的结构和作用。
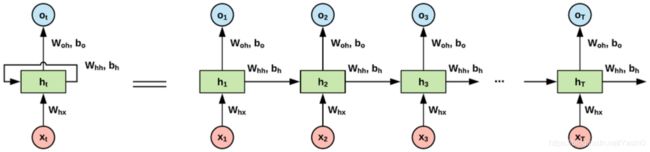
至于上面提到过的 GRU 序列模型,它其实是序列模型的一种,根据序列模型神经元结构的不同,最经典的有RNN、LSTM、GRU这 3 种。这里我们就不展开讲了,对理论感兴趣的同学,可以点击我给出的超链接,参考这几篇论文做更深入的研究。
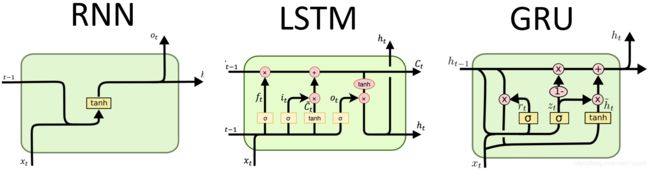
图6 序列模型中的不同单元结构
事实上,序列模型已经不仅在电商场景下,成功应用于推测用户的下次购买行为,在 YouTube、Netflix 等视频流媒体公司的视频推荐模型中,序列模型也用来推测用户的下次观看行为(Next Watch)。除此之外,音乐类应用也非常适合使用序列模型来预测用户的音乐兴趣变化。所以,掌握 DIEN 模型的架构对于拓宽我们的技术视野非常有帮助。
强化学习:让推荐系统像智能机器人一样自主学习
这节课我们继续来讲深度推荐模型发展的前沿趋势,来学习强化学习(Reinforcement Learning)与深度推荐模型的结合。
强化学习也被称为增强学习,它在模型实时更新、用户行为快速反馈等方向上拥有巨大的优势。自从 2018 年开始,它就被大量应用在了推荐系统中,短短几年时间内,微软、美团、阿里等多家一线公司都已经有了强化学习的成功应用案例。
虽然,强化学习在推荐系统中的应用是一个很复杂的工程问题,我们自己很难在单机环境下模拟,但理解它在推荐系统中的应用方法,是我们进一步改进推荐系统的关键点之一,也是推荐系统发展的趋势之一。
所以这节课,我会带你重点学习这三点内容:一是强化学习的基本概念;二是,我会以微软的 DRN 模型为例,帮你厘清强化学习在推荐系统的应用细节;三是帮助你搞清楚深度学习和强化学习的结合点究竟在哪。
强化学习的基本概念强化学习的基本原理,简单来说,就是一个智能体通过与环境进行交互,不断学习强化自己的智力,来指导自己的下一步行动,以取得最大化的预期利益。
事实上,任何一个有智力的个体,它的学习过程都遵循强化学习所描述的原理。比如说,婴儿学走路就是通过与环境交互,不断从失败中学习,来改进自己的下一步的动作才最终成功的。再比如说,在机器人领域,一个智能机器人控制机械臂来完成一个指定的任务,或者协调全身的动作来学习跑步,本质上都符合强化学习的过程。
为了把强化学习技术落地,只清楚它的基本原理显然是不够的,我们需要清晰地定义出强化学习中的每个关键变量,形成一套通用的技术框架。对于一个通用的强化学习框架来说,有这么六个元素是必须要有的:
智能体(Agent):强化学习的主体也就是作出决定的“大脑”;
环境(Environment):智能体所在的环境,智能体交互的对象;
行动(Action):由智能体做出的行动;
奖励(Reward):智能体作出行动后,该行动带来的奖励;
状态(State):智能体自身当前所处的状态;
目标(Objective):指智能体希望达成的目标。
为了方便记忆,我们可以用一段话把强化学习的六大要素串起来:一个智能体身处在不断变化的环境之中,为了达成某个目标,它需要不断作出行动,行动会带来好或者不好的奖励,智能体收集起这些奖励反馈进行自我学习,改变自己所处的状态,再进行下一步的行动,然后智能体会持续这个“行动 - 奖励 - 更新状态”的循环,不断优化自身,直到达成设定的目标。
这就是强化学习通用过程的描述,那么,对于推荐系统而言,我们能不能创造这样一个会自我学习、自我调整的智能体,为用户进行推荐呢?事实上,微软的 DRN 模型已经实现这个想法了。下面,我就以 DRN 模型为例,来给你讲一讲在推荐系统中,强化学习的六大要素都是什么,强化学习具体又是怎样应用在推荐系统中的。
强化学习推荐系统框架
强化学习推荐模型 DRN(Deep Reinforcement Learning Network,深度强化学习网络)是微软在 2018 年提出的,它被应用在了新闻推荐的场景上,下图 1 是 DRN 的框架图。事实上,它不仅是微软 DRN 的框架图,也是一个经典的强化学习推荐系统技术框图。
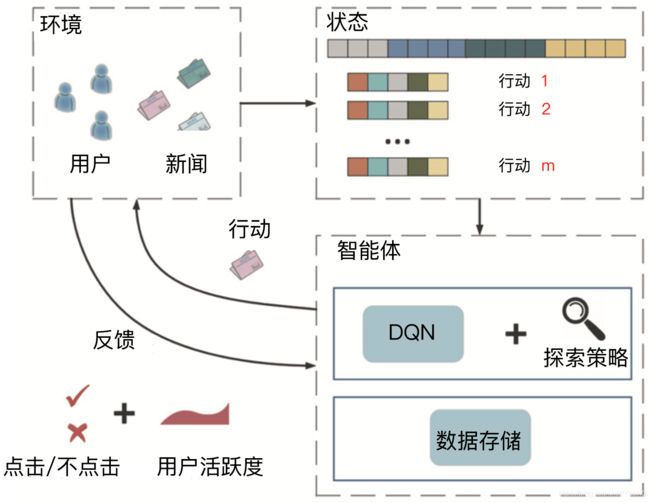
图1 深度强化学习推荐系统框架
从这个技术框图中,我们可以清楚地看到强化学习的六大要素。接下来,我就以 DRN 模型的学习过程串联起所有要素,来和你详细说说这六大要素在推荐系统场景下分别指的是什么,以及每个要素的位置和作用。
在新闻的推荐系统场景下,DRN 模型的第一步是初始化推荐系统,主要初始化的是推荐模型,我们可以利用离线训练好的模型作为初始化模型,其他的还包括我们之前讲过的特征存储、推荐服务器等等。
接下来,推荐系统作为智能体会根据当前已收集的用户行为数据,也就是当前的状态,对新闻进行排序这样的行动,并在新闻网站或者 App 这些环境中推送给用户。
用户收到新闻推荐列表之后,可能会产生点击或者忽略推荐结果的反馈。这些反馈都会作为正向或者负向奖励再反馈给推荐系统。
推荐系统收到奖励之后,会根据它改变、更新当前的状态,并进行模型训练来更新模型。接着,就是推荐系统不断重复“排序 - 推送 - 反馈”的步骤,直到达成提高新闻的整体点击率或者用户留存等目的为止。
为了方便你进行对比,我也把这六大要素在推荐系统场景下的定义整理在了下面,你可以看一看。

到这里,你有没有发现强化学习推荐系统跟传统推荐系统相比,它的主要特点是什么?其实,就在于强化学习推荐系统始终在强调“持续学习”和“实时训练”。它不断利用新学到的知识更新自己,做出最及时的调整,这也正是将强化学习应用于推荐系统的收益所在。
我们现在已经熟悉了强化学习推荐系统的框架,但其中最关键的部分“智能体”到底长什么样呢?微软又是怎么实现“实时训练”的呢?接下来,就让我们深入 DRN 的细节中去看一看。
深度强化学习推荐模型 DRN
智能体是强化学习框架的核心,作为推荐系统这一智能体来说,推荐模型就是推荐系统的“大脑”。在 DRN 框架中,扮演“大脑”角色的是 Deep Q-Network (深度 Q 网络,DQN)。其中,Q 是 Quality 的简称,指通过对行动进行质量评估,得到行动的效用得分,来进行行动决策。
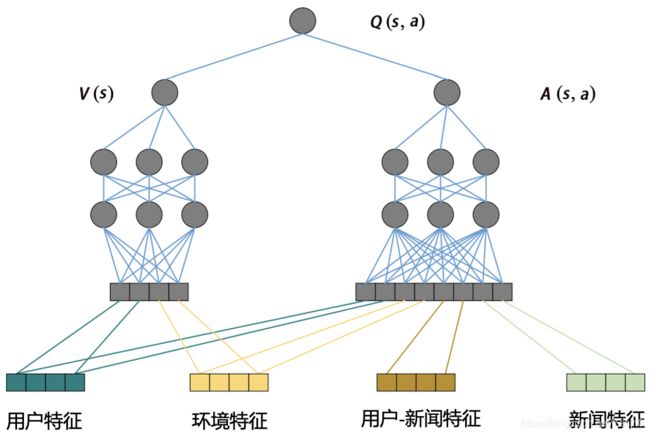
图2 DQN的模型架构图
DQN 的网络结构如图 2 所示,它就是一个典型的双塔结构。其中,用户塔的输入特征是用户特征和场景特征,物品塔的输入向量是所有的用户、环境、用户 - 新闻交叉特征和新闻特征。
在强化学习的框架下,用户塔特征向量因为代表了用户当前所处的状态,所以也可被视为状态向量。物品塔特征向量则代表了系统下一步要选择的新闻,我们刚才说了,这个选择新闻的过程就是智能体的“行动”,所以物品塔特征向量也被称为行动向量。
双塔模型通过对状态向量和行动向量分别进行 MLP 处理,再用互操作层生成了最终的行动质量得分 Q(s,a),智能体正是通过这一得分的高低,来选择到底做出哪些行动,也就是推荐哪些新闻给用户的。
其实到这里为止,我们并没有看到强化学习的优势,貌似就是套用了强化学习的概念把深度推荐模型又解释了一遍。别着急,下面我要讲的 DRN 学习过程才是强化学习的精髓。
DRN 的学习过程
DRN 的学习过程是整个强化学习推荐系统框架的重点,正是因为可以在线更新,才使得强化学习模型相比其他“静态”深度学习模型有了更多实时性上的优势。下面,我们就按照下图中从左至右的时间轴,来描绘一下 DRN 学习过程中的重要步骤。
图3 DRN的学习过程
我们先来看离线部分。DRN 根据历史数据训练好 DQN 模型,作为智能体的初始化模型。
而在线部分根据模型更新的间隔分成 n 个时间段,这里以 t1 到 t5 时间段为例。首先在 t1 到 t2 阶段,DRN 利用初始化模型进行一段时间的推送服务,积累反馈数据。接着是在 t2 时间点,DRN 利用 t1 到 t2 阶段积累的用户点击数据,进行模型微更新(Minor update)。
最后在 t4 时间点,DRN 利用 t1 到 t4 阶段的用户点击数据及用户活跃度数据,进行模型的主更新(Major update)。时间线不断延长,我们就不断重复 t1 到 t4 这 3 个阶段的操作。
这其中,我要重点强调两个操作,一个是在 t4 的时间点出现的模型主更新操作,我们可以理解为利用历史数据的重新训练,用训练好的模型来替代现有模型。另一个是 t2、t3 时间点提到的模型微更新操作,想要搞清楚它到底是怎么回事,还真不容易,必须要牵扯到 DRN 使用的一种新的在线训练方法,Dueling Bandit Gradient Descent algorithm(竞争梯度下降算法)。
DRN 的在线学习方法:竞争梯度下降算法
我先把竞争梯度下降算法的流程图放在了下面。接下来,我就结合这个流程图,来给你详细讲讲它的过程和它会涉及的模型微更新操作。
图4 DRN的在线学习过程
DRN 的在线学习过程主要包括三步,我带你一起来看一下。
第一步,对于已经训练好的当前网络 Q,对其模型参数 W 添加一个较小的随机扰动,得到一个新的模型参数,这里我们称对应的网络为探索网络 Q~。
在这一步中,由当前网络 Q 生成探索网络 ,产生随机扰动的公式 1 如下:
![]()
其中,α 是一个探索因子,决定探索力度的大小。rand(-1,1) 产生的是一个[-1,1]之间的随机数。
第二步,对于当前网络 Q 和探索网络 Q~,分别生成推荐列表 L 和 L~,再将两个推荐列表用间隔穿插(Interleaving)的方式融合,组合成一个推荐列表后推送给用户。
最后一步是实时收集用户反馈。如果探索网络 Q~生成内容的效果好于当前网络 Q,我们就用探索网络代替当前网络,进入下一轮迭代。反之,我们就保留当前网络。
总的来说,DRN 的在线学习过程利用了“探索”的思想,其调整模型的粒度可以精细到每次获得反馈之后,这一点很像随机梯度下降的思路:虽然一次样本的结果可能产生随机扰动,但只要总的下降趋势是正确的,我们就能够通过海量的尝试最终达到最优点。DRN 正是通过这种方式,让模型时刻与最“新鲜”的数据保持同步,实时地把最新的奖励信息融合进模型中。模型的每次“探索”和更新也就是我们之前提到的模型“微更新”。
到这里,我们就讲完了微软的深度强化学习模型 DRN。我们可以想这样一个问题:这个模型本质上到底改进了什么?从我的角度来说,它最大的改进就是把模型推断、模型更新、推荐系统工程整个一体化了,让整个模型学习的过程变得更高效,能根据用户的实时奖励学到新知识,做出最实时的反馈。但同时,也正是因为工程和模型紧紧地耦合在一起,让强化学习在推荐系统中的落地并不容易。
既然,说到了强化学习的落地,这里我还想再多说几句。因为涉及到了模型训练、线上服务、数据收集、实时模型更新等几乎推荐系统的所有工程环节,所以强化学习整个落地过程的工程量非常大。这不像我们之前学过的深度学习模型,只要重新训练一下它,我们就可以改进一个模型结构,强化学习模型需要工程和研究部门通力合作才能实现。
在这个过程中,能不能有一个架构师一样的角色来通盘协调,就成为了整个落地过程的关键点。有一个环节出错,比如说模型在做完实时训练后,模型参数更新得不及时,那整个强化学习的流程就被打乱了,整体的效果就会受到影响。
所以对我们个人来说,掌握强化学习模型的框架,也就多了一个发展的方向。那对于团队来说,如果强化学习能够成功落地,也一定证明了这个团队有着极强的合作能力,在工程和研究方向上都有着过硬的实践能力。