MySQL数据库之索引,事务,与存储引擎
前言:本章要和拐友们介绍一下数据库中的索引,在企业信息化的过程中,数据库中表的数据量越来越大,性能会急剧下降,创建索引对于保持良好的性能非常关键,索引十查询性能优化最有效的手段,能够轻易将查询性能提高几个数量级。Are you ready?
目录
一.索引的简介
1.1索引的概述
1.2索引的作用
1.3索引的副作用
1.4创建索引的依据
1.5.扩展知识:索引能使用的场景
二.索引的分类以及创建
2.1操作前的准备
2.2普通索引
2.2.1直接创建索引
2.2.2修改表方式创建
2.2.3创建表的时候指定索引
2.3.唯一索引
2.3.1直接创建唯一索引
2.3.2修改表方式创建
2.3.3创建表的时候指定
2.4.主键索引
2.4.1 创建表的时候指定
2.4.2修改表方式创建
2.5.组合索引
2.6全文索引
2.6.1直接创建索引
2.6.2修改表方式创建
2.6.3创建表的时候指定索引
2.6.4使用全文索引查询
三.查看索引
四.删除索引
4.1直接删除
4.2.删除主键索引
五.扩展知识
5.1Mysql死锁、悲观锁、乐观锁
5.2锁从类别
5.3MySQL有三种锁的级别:页级、表级、行级。
5.4死锁
5.5产生死锁的原因
5.6产生死锁的四个必要条件
5.7解决方法
如何避免死锁
六.总结
一.索引的简介
1.1索引的概述
- 索引是一个排序的列表,存储着索引值和这个值所对应的物理地址
- 使用索引后无须对整个表进行扫描,通过物理地址就可以找到所需数据
- 索引就好比是一本书的目录,可以根据目录中的页码快速找到所需的内容
- 索引是表中一列或者若干列值排序的方法
- 建立索引的目的是加快对表中记录的查找或排序
1.2索引的作用
- 设置了合适的索引之后,数据库利用各种快速定位技术,能够大大加快查询速度,这时创建索引的主要原因
- 当表很大或查询设计到多个表时,使用索引可以成千上万的提高查询速度
- 可以降低数据库的IO成本,并且索引还可以降低数据库的排序成本
- 通过创建唯一(键)性索引,可以保证数据表中每一行数据的唯一性
- 可以加快表与表之间的连接
- 在使用分组和排序的时候,可以大大减少分组和排序的时间
1.3索引的副作用
- 索引需要占用额外的磁盘的空间(对于MyISAM引擎而言,索引文件和数据文件时分离的,索引文件用于保存数据记录的地址,而InnoDB引擎的表数据文件本身就是索引文件)
- 在插入和修改数据时要花费更多的时间,因为索引也要随之变动
1.4创建索引的依据
索引虽然可以提升数据库查询的速度,但并不是任何情况下都适合创建索引,因为索引本身会消耗系统资源,在有索引的情况下,数据库会先进性索引查询,然后定位到具体的数据行,如果索引使用的不当,反而会增加数据库的负担。
- 表的主键,外键必须要有索引,因为主键具有唯一性 ,外键关联的是子表的主键,查询时可以快速定位
- 记录超过300行的表应该有索引,如果没有索引,需要把表遍历一遍,会严重影响数据库的性能
- 经常与其他表进行连接的表,在连接字段上应该能建立索引
- 唯一性太差的字段不适合建立索引
- 更新太频繁地字段不适合创建索引
- 经常出现在where子句中地字段,特别是大表地字段,应该建立索引
- 索引应该建在选择性高地字段上
- 索引应该建在小字段上,对于大的文本字段甚至超长字段,不要键索引。
1.5.扩展知识:索引能使用的场景
- 小字段
- 唯一性强的字段
- 更新不频繁,但查询率高的字段
- 表当中记录超过300+的行
- 主键,外键,唯一键
二.索引的分类以及创建
2.1操作前的准备
在操作索引之前我们需要做些准备,方便在接下来的操作中
mysql -u root -p
create database [数据库名];
use [数据库名];
create table [数据库名] (id int(10),name varchar(10),cardid varchar(18),phone varchar(11),address varchar(50),remark text);
desc [数据库名];
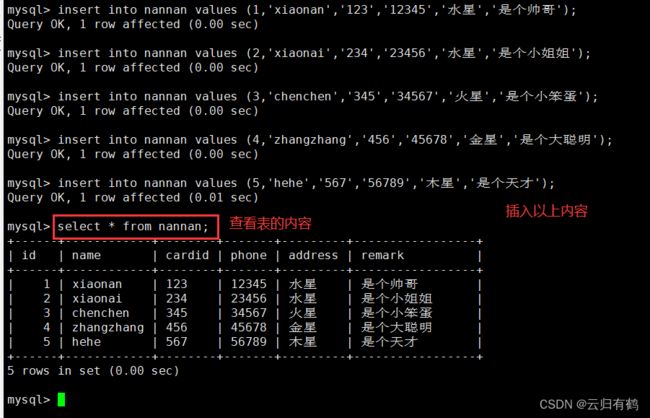
insert into nannan values (1,'zhangsan','123','111111','nanjing','this is vip');
insert into nannan values (4,'lisi','1234','444444','nanjing','this is normal');
insert into nannan values (2,'wangwu','12345','222222','benjing','this is normal');
insert into nannan values (5,'zhaoliu','123456','555555','nanjing','this is vip');
insert into nannan values (3,'qianqi','1234567','333333','shanghai','this is vip');
select * from nannan;

2.2普通索引
最基本的索引类型,没有唯一性之类的限制2.2.1直接创建索引
CREATE INDEX 索引名 ON 表名 (列名[(length)]); #创建索引
select [列名] from [表名]; #查看表
show create table [表名]; #查看表的细节
#(列名(length)):length是可选项。
如果忽略 length 的值,则使用整个列的值作为索引。
如果指定使用列前的 length 个字符来创建索引,这样有利于减小索引文件的大小。
#索引名建议以“_index”结尾。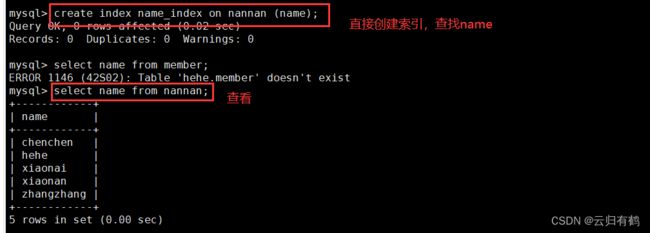
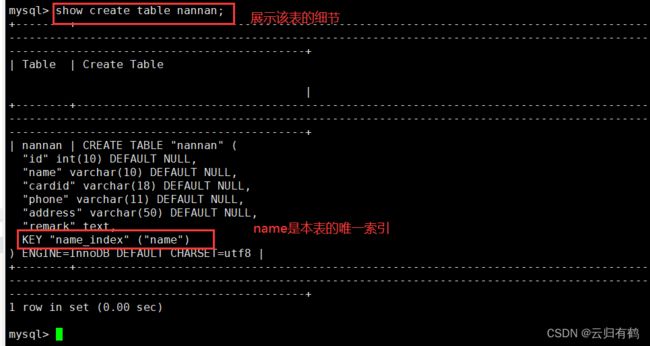
2.2.2修改表方式创建
ALTER TABLE 表名 ADD INDEX 索引名 (列名); #修改表方式创建索引
select [列名] from [表名]; #查看表
show create table [表名]\G; #展示表的细节
2.2.3创建表的时候指定索引
CREATE TABLE 表名 ( 字段1 数据类型,字段2 数据类型[,...],INDEX 索引名 (列名));
例:create table nannan1 (id int(4) not null,name varchar(10) not null,cardid varchar(20) not null,index id_index (id));
show create table nannan1;

2.3.唯一索引
与普通索引类似,但区别是唯一索引列的每个值都唯一。
唯一索引允许有空值(注意和主键不同)。如果是用组合索引创建,则列值的组合必须唯一。添加唯一键将自动创建唯一索引。2.3.1直接创建唯一索引
CREATE UNIQUE INDEX 索引名 ON 表名(列名);
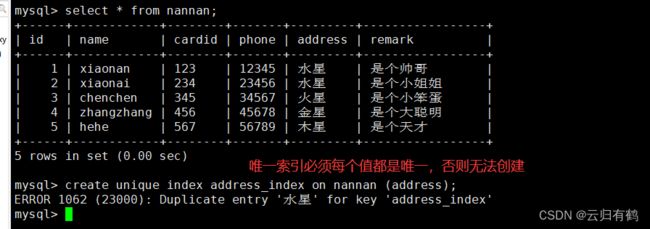
例:select * from member;
create unique index address_index on member (address);
create unique index name_index on member (name);
show create table member;
ps:唯一索引必须每个值都是唯一,不然没法创建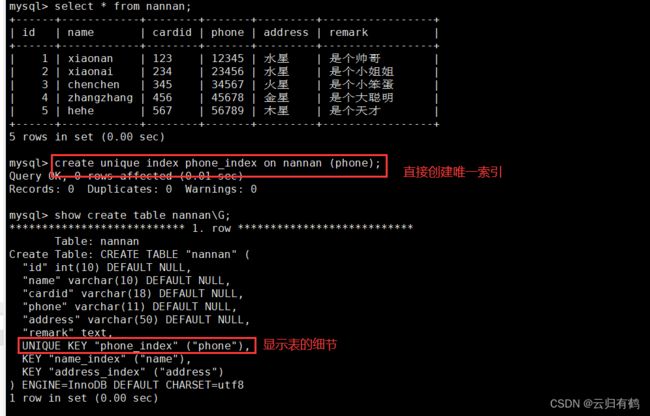
2.3.2修改表方式创建
ALTER TABLE 表名 ADD UNIQUE 索引名 (列名);
例:alter table hehe add unique id_index (id);
2.3.3创建表的时候指定
CREATE TABLE 表名 (字段1 数据类型,字段2 数据类型[,...],UNIQUE 索引名 (列名));
例:create table nannan2 (id int,name varchar(20),unique id_index (id));
show creat table nannan2;
2.4.主键索引
是一种特殊的唯一索引,必须指定为“PRIMARY KEY”。
一个表只能有一个主键,不允许有空值。 添加主键将自动创建主键索引。2.4.1 创建表的时候指定
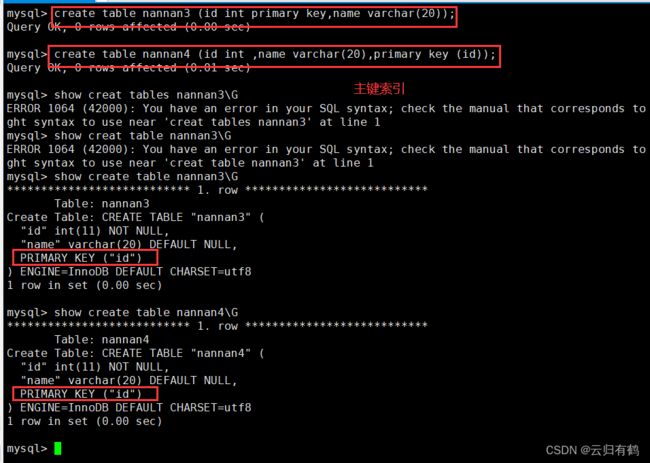
2.4.2修改表方式创建
ALTER TABLE 表名 ADD PRIMARY KEY (列名);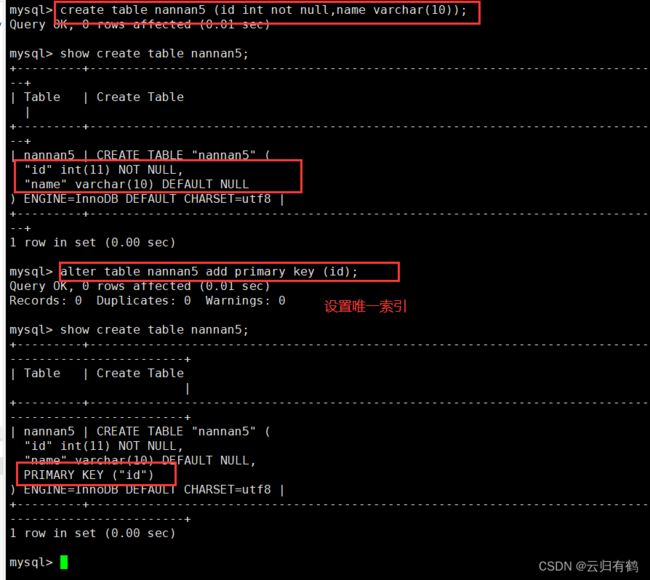
2.5.组合索引
可以是单列上创建的索引,也可以是在多列上创建的索引。CREATE TABLE 表名 (列名1 数据类型,列名2 数据类型,列名3 数据类型,INDEX 索引名 (列名1,列名2,列名3));
select * from 表名 where 列名1='...' AND 列名2='...' AND 列名3='...';
例:create table nannan6 (id int not null,name varchar(20),cardid varchar(20),index index_amd (id,name));
show create table nannan6;
insert into nannan6 values(1,'nainai','123456');
select * from nannan6 where name='nainai' and id=1;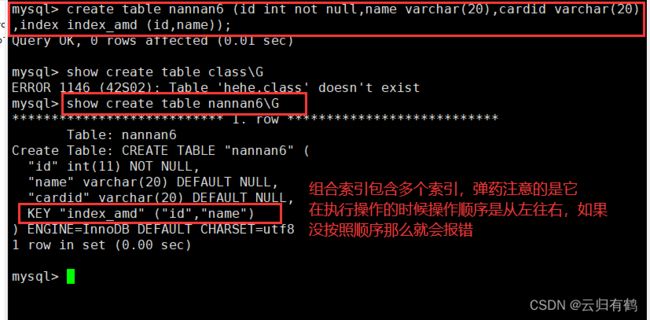

2.6全文索引
适合在进行模糊查询的时候使用,可用于在一篇文章中检索文本信息。
在 MySQL5.6 版本以前FULLTEXT 索引仅可用于 MyISAM 引擎,
在 5.6 版本之后 innodb 引擎也支持 FULLTEXT 索引。
全文索引可以在 CHAR、VARCHAR 或者 TEXT 类型的列上创建。每个表只允许有一个全文索引。2.6.1直接创建索引
CREATE FULLTEXT INDEX 索引名 ON 表名 (列名);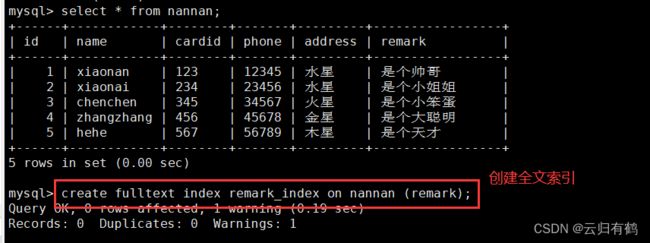
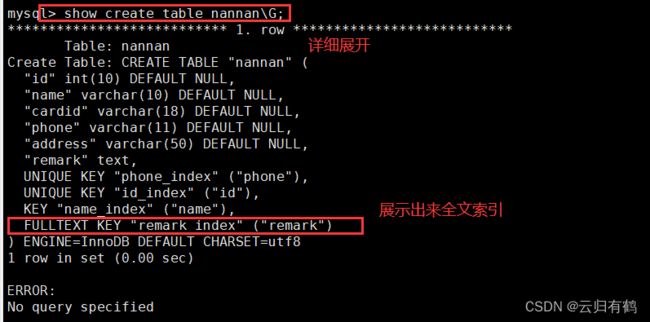
2.6.2修改表方式创建
ALTER TABLE 表名 ADD FULLTEXT 索引名 (列名);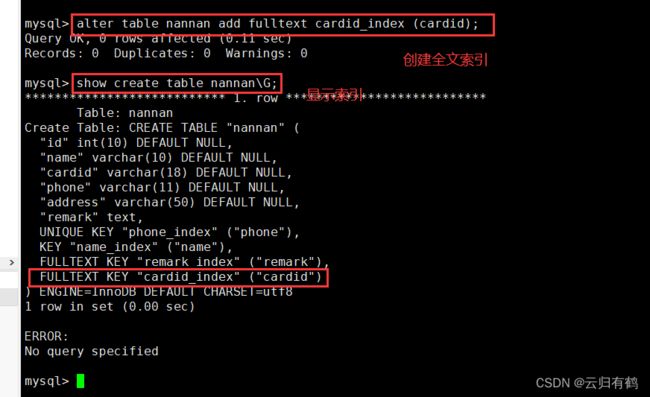
2.6.3创建表的时候指定索引
CREATE TABLE 表名 (字段1 数据类型[,...],FULLTEXT 索引名 (列名));
1
#数据类型可以为 CHAR、VARCHAR 或者 TEXT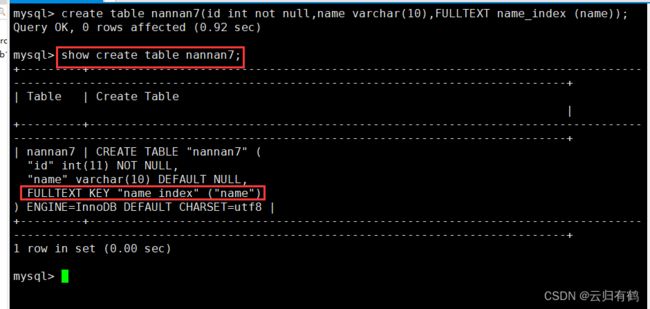
2.6.4使用全文索引查询
SELECT * FROM 表名 WHERE MATCH(列名) AGAINST('查询内容');
例:select * from member where match(cardid) against('123');
or
select * from member where remark='123';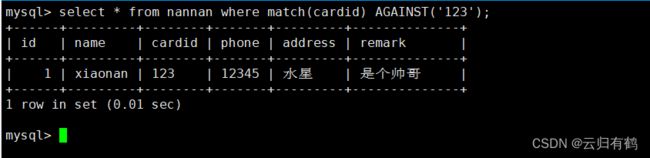
三.查看索引
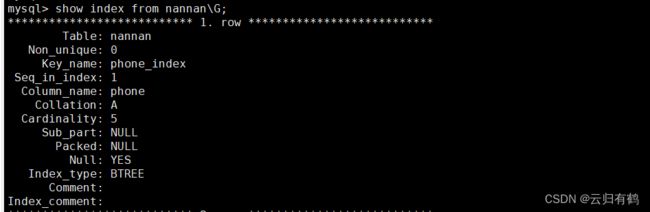
show index from 表名;
show index from 表名\G; 竖向显示表索引信息
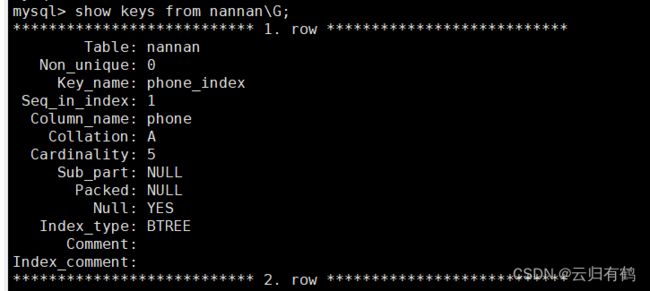
show keys from 表名;
show keys from 表名\G;
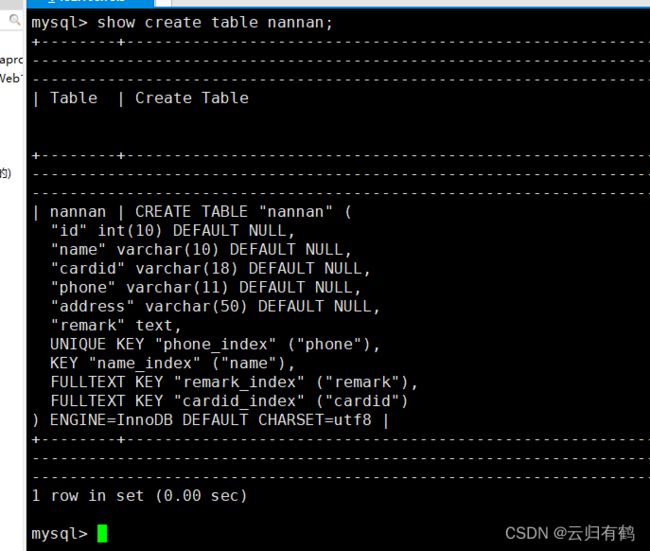
show create table 表名;第一种:
第二种:
第三种:
各字段含义如下:
| Table | 表的名称 |
| Non_unique | 如果索引内容唯一,则为 0;如果可以不唯一,则为 1。 |
| Key_name | 索引的名称。 |
| Seq_in_index | 索引中的列序号,从 1 开始。 limit 2,3 |
| Column_name | 列名称。 |
| Collation | 列以什么方式存储在索引中。在 MySQL 中,有值‘A’(升序)或 NULL(无分类)。 |
| Cardinality | 索引中唯一值数目的估计值。 |
| Sub_part | 如果列只是被部分地编入索引,则为被编入索引的字符的数目(zhangsan)。如果整列被编入索引,则为 NULL。 |
| Packed | 指示关键字如何被压缩。如果没有被压缩,则为 NULL。 |
| Null | 如果列含有 NULL,则含有 YES。如果没有,则该列含有 NO。 |
| Index_type | 用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。 |
| Comment | 备注 |
四.删除索引
4.1直接删除
DROP INDEX 索引名 ON 表名;
例:drop index remark_index on nannan;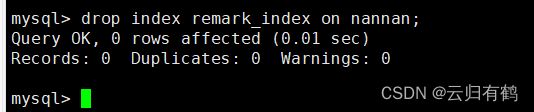
4.2.删除主键索引
ALTER TABLE 表名 DROP PRIMARY KEY;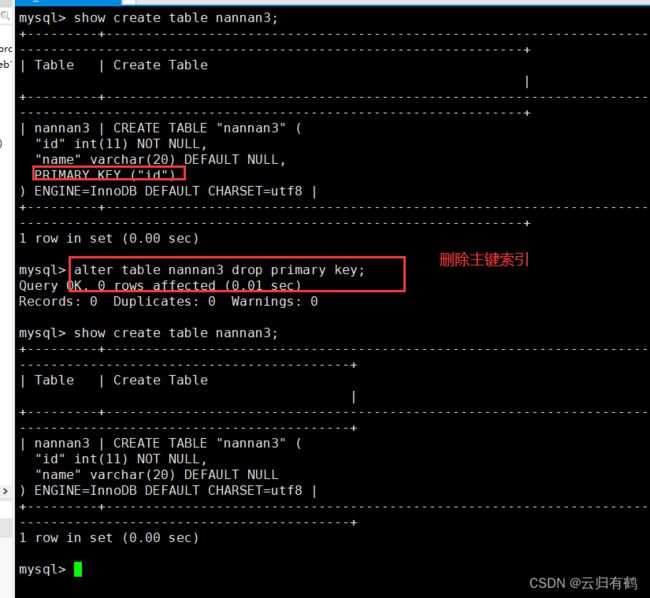
五.扩展知识
5.1Mysql死锁、悲观锁、乐观锁
锁机制是为了避免,在数据库有并发事务的时候,可能会产生数据的不一致而诞生的的一个机制。
5.2锁从类别
| 共享锁 | 又叫做读锁,当用户要进行数据的读取时,对数据加上共享锁,共享锁可以同时加上多个。 |
| 排他锁 | 又叫做写锁,当用户要进行数据的写入时,对数据加上排他锁,排他锁只可以加一个,他和其他的排他锁,共享锁都相斥。 |
5.3MySQL有三种锁的级别:页级、表级、行级。
| 表级锁 | 开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。 |
| 行级锁 | 开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。 |
| 页面锁 | 开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度 |
5.4死锁
- MyISAM中是不会产生死锁的,因为MyISAM总是一次性获得所需的全部锁,要么全部满足,要么全部等待。而在InnoDB中,锁是逐步获得的,就造成了死锁的可能。
- 两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
5.5产生死锁的原因
(1)系统资源不足。
(2)进程运行推进的顺序不合适。
(3)资源分配不当等。
如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则就会因争夺有限的资源而陷入死锁。其次,进程运行推进顺序与速度不同,也可能产生死锁。
5.6产生死锁的四个必要条件
死锁4大要素:互斥,持有并请求,不可剥夺,持续等待
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
5.7解决方法
1、撤消陷于死锁的全部进程;
2、逐个撤消陷于死锁的进程,直到死锁不存在;
3、从陷于死锁的进程中逐个强迫放弃所占用的资源,直至死锁消失。
4、从另外一些进程那里强行剥夺足够数量的资源分配给死锁进程,以解除死锁状态
5.8如何避免死锁
1.使用事务时,尽量缩短事务的逻辑处理过程,及早提交或回滚事务;
2.设置死锁超时参数为合理范围,如:3分钟-10分种;超过时间,自动放弃本次操作,避免进程悬挂;
3.优化程序,检查并避免死锁现象出现;
4.对所有的脚本和SP都要仔细测试,在正式版本之前;
5.所有的SP都要有错误处理(通过@error);
6.一般不要修改SQL SERVER事务的默认级别。不推荐强行加锁。
7. 以固定的顺序访问表和行。
分为两种情景:
对于不同事务访问不同的表,尽量做到访问表的顺序一致;
对于不同事务访问相同的表,尽量对记录的id做好排序,执行顺序一致;
8. 大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小。
9. 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率。
10. 降低隔离级别。如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为gap锁造成的死锁。
11. 为表添加合理的索引。可以看到如果不走索引将会为表的每一行记录添加上锁,死锁的概率大大增大
六.总结
本章主要讲了索引的分类以及如何创建索引
索引的分类:
① 普通索引 :针对所有字段,没有特殊的需求/规则
② 唯一索引 : 针对唯一性的字段,仅允许出现一次空值
③ 组合索引 (多列/多字段组合形式的索引)
④ 全文索引(varchar char text)
⑤ 主键索引 :针对唯一性字段、且不可为空,同时一张表只允许包含一个主键索引
索引的创建:
① 在创建表的时候,直接指定index
② alter修改表结构的时候,进行add 添加index
③ 直接创建索引index
PS:主键索引——》直接创建主键即可